|
Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #82
|

|
|
|
|
Ja, ne,
nicht
was ihr denkt. Nix mit Silberteller. Höchstens mit handgedengeltem pflanzenfreiem Gebäck drauf. Unser heutiger Titel referenziert - natürlich - die Lister der
kommerziell erfolgreichsten Weihnachtslieder auf Wikipedia
. Mit Klassikern wie
Heintje
, den
Fischerchören
und eben auch unser aller
Lieblingskrokodil
. In Zeiten von Log4J-geplagten Fröschen muss man sich eben an seine anderen
tierischen SEO-Kumpels
erinnern.
Wenn diese Newsletter-Ausgabe in Deinen Posteingang geflattert ist, sind es keine 3 Tage mehr bis Weihnachten. Auch wenn hier nach und nach die meisten Weihnachtswichtel in die wohlverdienten Winterferien entschwinden, haben wir Dir eine bunte Mischung an saftig-süßen SEO-Plätzchen zusammengestellt:
-
Johan berichtet von einem Weiterleitungs-Chaos auf Bundesebene
-
Andreas schickt Dir eine Postkarte aus Curaçao und fühlt sich von 503-Fehlern gestört
-
Anita sichtet außergewöhnlich-abenteuerliche robots.txt in freier Wildbahn
-
Lars hat das neue Erscheinungsbild der Google-Sucheingabe im Gepäck
-
Nora erzählt Dir, warum sie leere ALT-Attribute problematisch findet
Außerdem haben wir einen kleinen Weihnachtswunsch an Dich. Wenn Du magst, klick Dich in unsere
kleine Umfrage zu diesem Newsletter
und lass uns Deine Meinung da! Vielen Dank 😊
Wir wünschen Dir und Deinen Lieben zauberhafte Feiertage!
Deine Wingmen
|
|
|
Demokratische Machtübergabe mit Reibungsverlusten
|
|
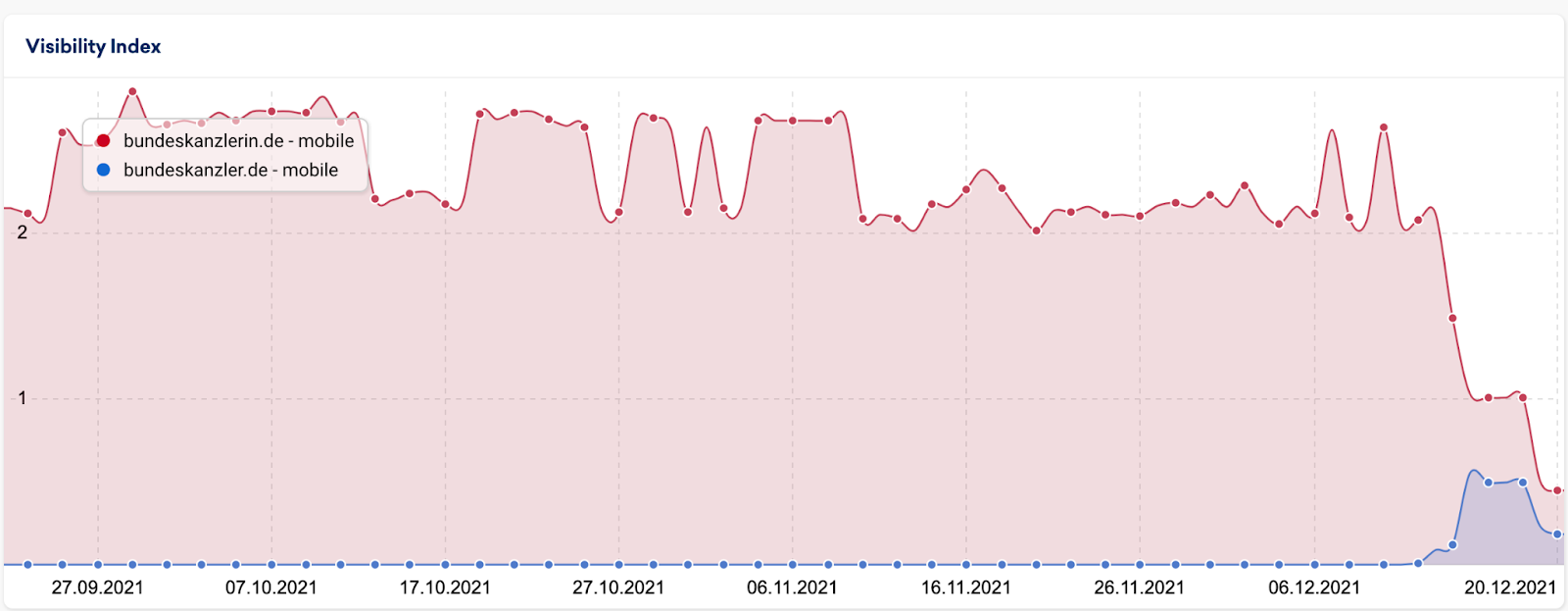
Ich bin mir sicher, Du hast es mitbekommen: Angela Merkel hat am 08.12.2021 ihr Amt an Olaf Scholz übergeben. 6 Tage später ist dann die Domain
bundeskanzlerin.de
auf
bundeskanzler.de
umgezogen.
Was erst nach einer reibungslosen Übergabe aussah geriet schnell ins Stocken
:
Nachdem ich das
getwittert hatte
meldete sich
Alex Breitenbach
bei mir: Er habe sich die Redirects angesehen. Holy Moly:
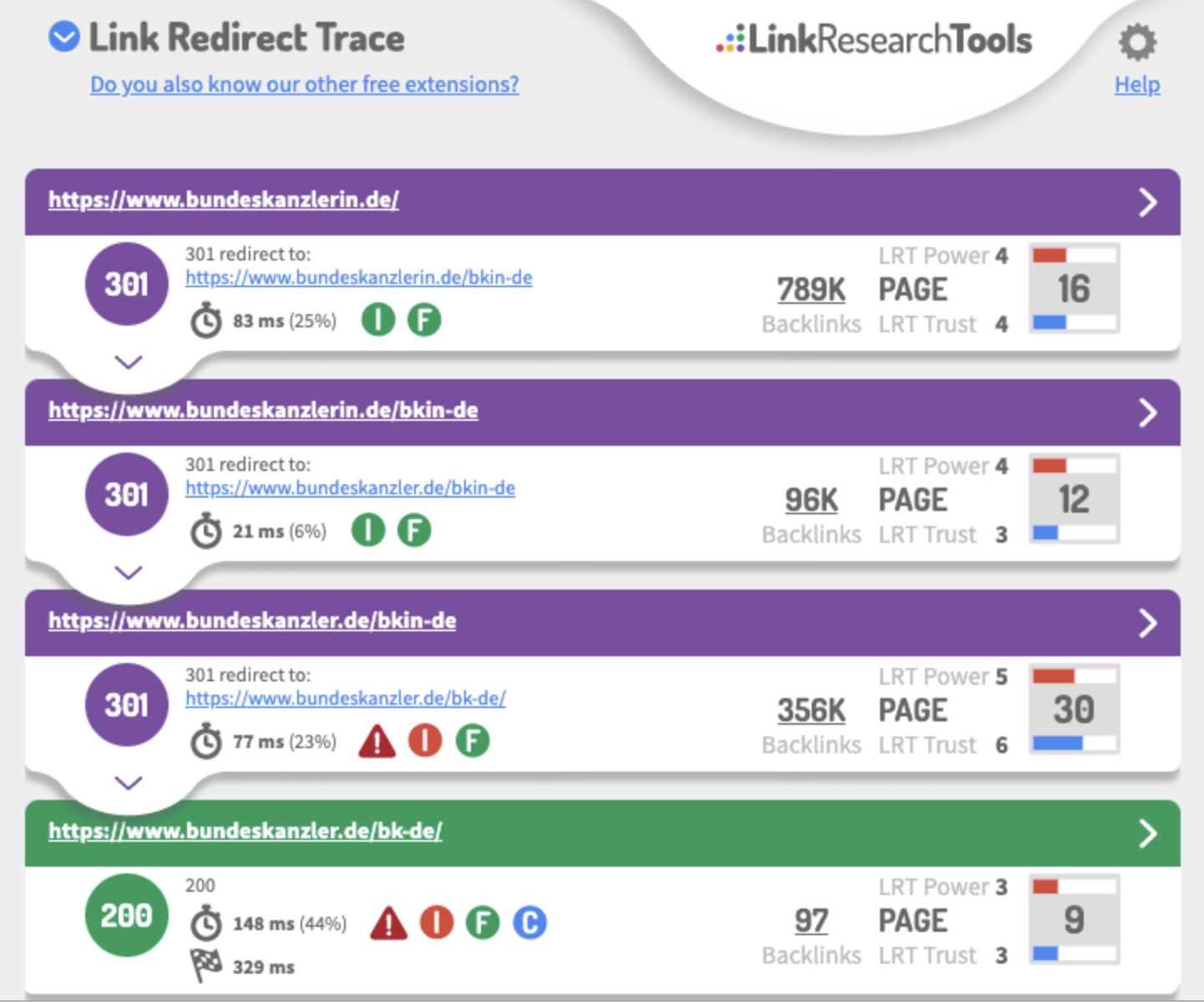
Das kann natürlich die Schwierigkeiten in der Übertragung der Rankings erklären, wenn hier so viele Sprünge enthalten sind.
Aber wir können uns hier noch mehr ansehen.
Der erste Schritt (nicht auf dem Screenshot) führt von
bundeskanzlerin.de
auf
www.bundeskanzlerin.de
und von dort auf /bkin-de. Anhand der Backlinks erkennen wir, dass die Startseite vermutlich schon immer dort gelegen hat.
Wahrscheinlich steht "-de" für die Sprache und es gibt einen GEO-Redirect.
Aus SEO-Sicht sind GEO-Redirects auf Basis der Location des Users immer schwierig
. Denn Google kommt immer aus den USA. Und natürlich sollte ein Vary-Header gesetzt werden. Das ist hier nicht der Fall.
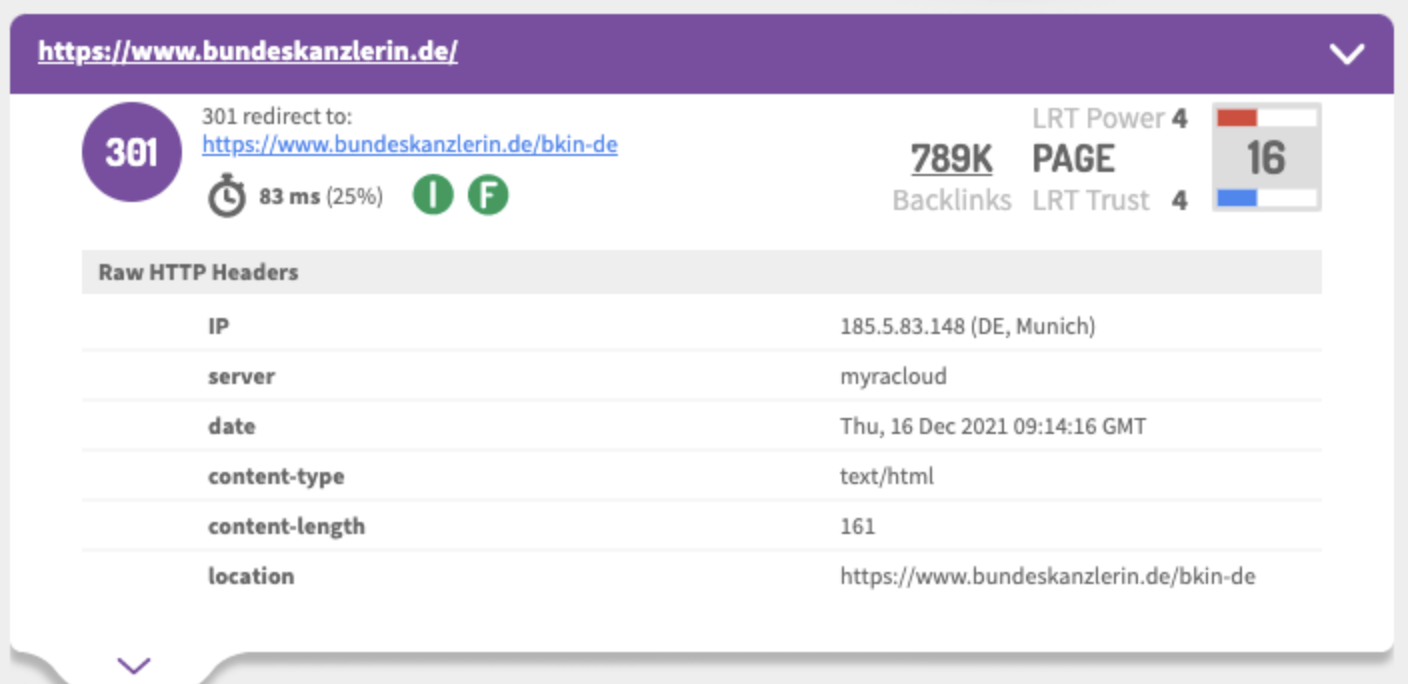
Der nächste Redirect zeigt dann von
bundeskanzlerin.de/bkin-de
auf
https://www.bundeskanzler.de/bkin-de
. Von hier werden wir weitergeleitet auf
https://www.bundeskanzler.de/bk-de/
, also BK statt BKIN und mit Trailing-Slash. Diese Zielseite liefert dann einen Status 200.
Damit ist die Reise aber noch nicht zu Ende. Das Canonical der letzten URL zeigt auf /bk-de (ohne Trailing-Slash):
https://www.bundeskanzler.de/bkin-de
Hier ist dann die Reise tatsächlich zu Ende und das finale Ziel erreicht.
Für Google bedeutet das: Um die Weiterleitung von
bundeskanzlerin.de
zum korrekten Ziel zu verarbeiten müssen insgesamt 6 URLs aufgerufen werden. Diese Weiterleitungen muss Google alle korrekt verarbeiten, um die korrekte Zielseite zu identifizieren.
Allein die Redirects kosten fast 200ms Ladezeit für User und gleichzeitig fallen uns schon an dieser Stelle mit den GEO-Redirects (falscher Status Code, fehlender Vary-Header) und dem Trailing-Slash Redirect/Canonical-Widerspruch 2 mittlere technische Probleme auf.
Bei der ersten URL die wir testen.

Aus diesen (oder auch anderen) Gründen
empfiehlt John Mu von Google eindeutig weniger als 5 Redirects
.
Es gibt allerdings noch mehr zu sehen: Die Seite des Bundeskanzlers schließt nicht nur Baiduspider und YandexBot per Robots.txt aus. Dafür könnte man eine geopolitische Motivation möglicherweise herleiten. Aber Seznam?
Glückwunsch aber an ungefähr alle SEO-Tool-Hersteller: Der Bundeskanzler hat Euch auf dem Schirm. Die
Google Dokumentation zu Redirects
hat er sich aber wahrscheinlich nicht angeguckt.
|
|
|
Warum 503 Fehler auf Deiner Website Dich in Deinem Urlaub stören sollten
|
|
Das Jahresende neigt sich dem Ende und manche Menschen, so wie ich, versuchen dann dem kalten und tristen Wetter in Deutschland zu entkommen. An alles hast Du gedacht: Dreifach geimpft, PCR-Test negativ, alle Unterkünfte, Auto und ein fettes Tauchpaket gebucht sitzt Du im Flieger und kaum bist Du angekommen und Du schaltest Dein Handy an begrüßt Dich eine E-Mail in Deinem Posteingang. Deine liebe Search Console von Google schickt Dir eine Nachricht die so beginnt: "Neues Problem mit Abdeckung auf der Website...". Danke Google! Du liest die Mail in Ruhe weiter und stellst fest, ok der Hauptfehler ist ein "Serverfehler (5xx)". Und dann geht die Fehlersuche los.
Wieso ich so etwas im Urlaub mache und nicht damit warte bis ich wieder im Büro bin? Ganz einfach: Ein 500er Fehler sollte nur für kurze Zeiten ausgespielt werden. Zum Beispiel wenn ein Update Deines CMS durchgeführt wird und dies dadurch kurzfristig nicht anders möglich ist.
Diese Fehler sollten auf keinen Fall länger als 1 Tag von einer Website ausgegeben werden, da Google bei einem längeren Andauern davon ausgeht, dass der Fehler dauerhaft auf Deiner Seite auftritt. In diesem Fall deindexiert Google langsam die betroffenen URLs, weil sie als Suchergebnis nicht geeignet sind. John Müller von Google kann auch nicht garantieren, dass nach einer Fehlerbehebung alle Rankings einer solchen betroffenen URLs wieder ihre alten Positionen erreichen.
Das hat er noch einmal in seinem Google Hangout am 10.12.2021 beschrieben.
Dort wurde John Müller noch einmal zum Handling von Seiten gefragt, die zum Zeitpunkt des Besuchs durch Google mit einem 500er Fehler antworten:
"I don't think you'll be able to do it for that time, regardless of whatever you set up. For an outage of maybe a day or so, using a 503 result code is a great way to tell us that we should check back. But after a couple of days we think this is a permanent result code, and we think your pages are just gone, and we will drop them from the index.
And when the pages come back we will crawl them again and we will try to index them again. But it's essentially during that time we will probably drop a lot of the pages from the website from our index, and there's a pretty good chance that it'll come back in a similar way but it's not always guaranteed."
Deshalb sollte Dir der Crawling Report in der Google Search Console auf keinen Fall egal sein und Du solltest Dir diese Berichte in regelmäßigen Abständen anschauen um Probleme beim Crawling Deiner Website frühzeitig erkennen zu können.
Einstellungen → "Crawl Statistik" Bericht öffnen

Mit einem Klick auf diesen Eintrag erhältst Du weitere Details:
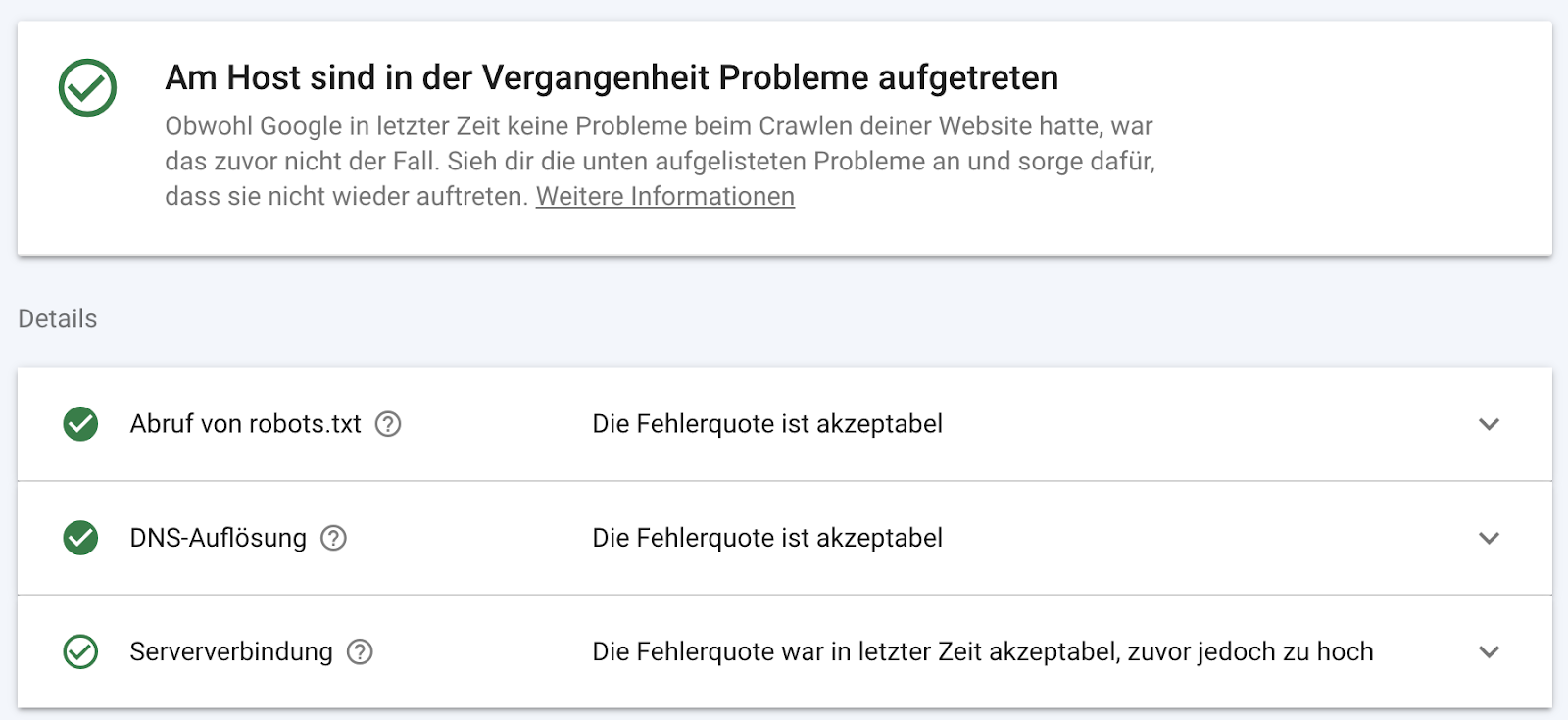 \
Wir sehen also, dass es mit der Erreichbarkeit der robots.txt und mit der Namensauflösung der Domain kein Problem gab. Aber bei der Erreichbarkeit der Website an sich. Klicken wir auf einen dieser Punkte bekommen wir auch hier mehr Details zu diesem Punkt:\
\
Wir sehen also, dass es mit der Erreichbarkeit der robots.txt und mit der Namensauflösung der Domain kein Problem gab. Aber bei der Erreichbarkeit der Website an sich. Klicken wir auf einen dieser Punkte bekommen wir auch hier mehr Details zu diesem Punkt:\
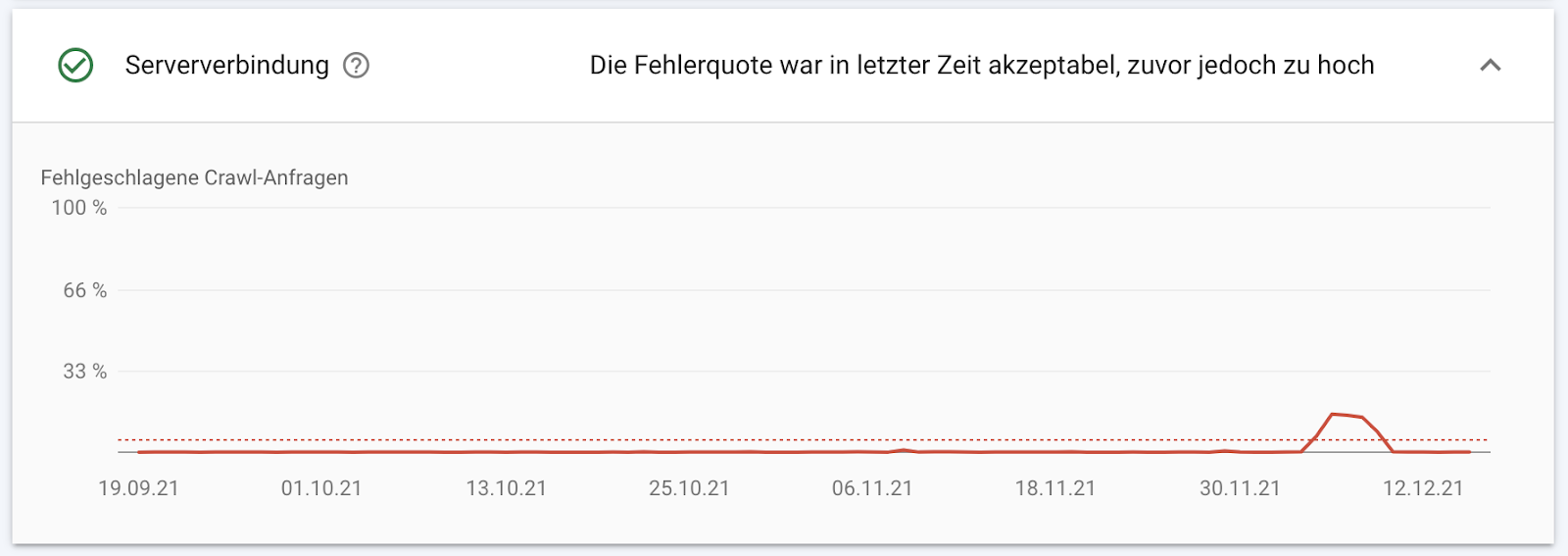
Und wir sehen, dass Google im Zeitraum vom 10.12. bis zum 12.12. Probleme mit der Serververbindung hatte. Seit dem 12.12. scheinen die Probleme behoben zu sein. Sollten diese aber noch weiter anhalten, so sollte man diesem Problem auf den Grund gehen.
Die gestrichelte rote Linie zeigt den Toleranzwert, bis zu dem Google bereit ist ein Auge zuzudrücken. Darüber hinaus wird es für Deine Seite jedoch schnell eng. Diese Grenze liegt bei ca. 4 bzw. 5% aller Anfragen des Googlebots.
Spätestens wenn Du eine Mail aus der Search Console bekommst solltest Du also tätig werden. Dir nützt es auch nicht, wenn Du in bei dem Aufruf der im Fehlerbericht aufgeführten URLs keine Fehlermeldung erhälst. Oft liegt in so einem Fall ein Performance Problem des Servers vor. Der Server könnte in so einem Fall also Probleme haben sehr viele Anfragen zeitgleich zu verarbeiten oder schlecht geschriebene Scripte benötigen einfach zu viel Ressourcen.
In so einem Fall können Dir gegebenenfalls Auswertungen der Logfiles helfen um weiterhin auftretende Fehler und deren Quellen zu identifizieren. Wichtig ist in so einem Fall, dass der Googlebot diese Fehlermeldungen erhält und Dir nicht viel Zeit bleibt, bis Google anfängt die fehlerhaften URLs aus dem Index zu nehmen. Damit wirst Du natürlich die Rankings verlieren, die Du mit diesen URLs erzielst. Kümmere Dich also rechtzeitig um interne Fehlermeldungen, nimm sie ernst und beseitige sie so schnell wie möglich.
|
|
|
robots.txt from hell
|
|
Vielleicht hast Du
diesen Tweet von Jens Fauldrath
neulich auch entdeckt und nichts Böses ahnend drauf geklickt. Von wegen besinnliche Weihnachtszeit - da fällt einem der Lebkuchen aus Schreck doch glatt auf die Tastatur!
In der freien Wildbahn begegnen einem im SEO-Leben immer wieder Dinge, die durchaus kurios anmuten. Natürlich ist es in der Aussensicht immer einfach aufzuzählen, was da alles falsch ist. Das ist nicht immer fair, denn auf der anderen Seite sitzen womöglich Menschen, die ihr möglichstes tun - trotz teils eher widriger Voraussetzungen.
Die außergewöhnlich-abenteuerliche robots.txt aus dem Tweet möchte ich daher gerne zum Anlass nehmen, ein paar generelle Tipps und Hinweise zu diesem Thema loszuwerden und in Erinnerung zu rufen. Los geht's!
-
Keep it simple
: Die Restriktionen für den Crawler sollten so gering wie möglich ausfallen. Bei allem, was nicht gecrawlt werden darf, solltest Du Dir die Frage stellen, ob Du es a) wirklich brauchst oder b) anders als auf diesem Wege regeln kannst / solltest. Erfahrungsgemäß sind umfangreiche Listen in der robots.txt ein Zeichen für andere, strukturell-technisch besser lösbare Herausforderungen. Das reduziert auch die Gefahr, Dich in widersprüchlichen Angaben zu verstricken und am Ende doch etwas zu sperren, dass Du eigentlich gar nicht sperren wolltest.
-
Zeig dem Crawler alles was er benötigt
: Bei umfassenden robots.txt Dateien kommt es gerne mal vor, dass man zu restriktiv ist und teilweise auch essentielle Ressourcen, die es beispielsweise zum Rendern braucht, vor dem Zugriff der Crawler "schützt". Das solltest Du besser vermeiden.
-
Mach es nicht zu kompliziert
: So lange Du anhand von Logfiles oder anderen Quellen keine expliziten Gründe hast, einzelne Crawler unterschiedlich zu behandeln und spezifische Anweisungen zu formulieren, kannst Du mit User-agent: * arbeiten. Das macht die Erstellung und Wartung und möglicherweise erforderliches Debugging deutlich leichter!
-
Keep it small
: Auch wenn eine robots.txt Datei in Theorie maximal 500KB umfassen darf heißt das nicht, dass Du diese Vorgabe bis aufs letzte ausreizen musst. Oder um es deutlicher zu sagen: Deine robots.txt sollte nicht im Entferntesten an dieses Limit herankommen.
-
Steuerung des Crawlers != Steuerung der Indexierung
: Man kann es nicht oft genug erwähnen - mit der robots.txt wird nur gesteuert, was der Crawler crawlen darf und was nicht. Wenn ein Inhalt, der über Verlinkungen erschließbar ist, relevant genug erscheint, wird er im Index landen - auch wenn der Crawler ihn sich nicht anschauen durfte (und eine Angabe wie "noindex" entsprechend auch nie gesehen hat). Also: Vorsicht ist geboten! Daher ist einer meiner ersten Checks beim Untersuchen einer Domain auch, die in der robots.txt gesperrten Verzeichnisse und Inhalte einmal in eine site: Abfrage zu verpacken und zu schauen, ob und was da zurück kommt.
-
Verweis auf die XML-Sitemap
: Je nach Umfang Deiner Domain solltest Du eine XML-Sitemap oder gar eine XML-Index-Sitemap haben. Und damit Google - und andere Crawler - die auch garantiert sehen, gehört sie nicht nur in der GSC hinterlegt, sondern ebenfalls in der robots.txt referenziert.
-
Immer im Root
: Während eine XML-Sitemap nicht zwingend im Root der Domain liegen muss, ist das bei der robots.txt zwingende Voraussetzung. Die Crawler schauen an genau einem Ort nach der robots.txt, bevor sie sich ans Werk machen. Gilt übrigens auch für Subdomains!
-
Testing Tool ist Dein Freund
: Auch wenn es mittlerweile ziemlich gut versteckt ist, gibt es in der GSC ein robots.txt Testing Tool. Da kannst Du nach Lust und Laune rumspielen und schauen, ob alles so funktioniert wie Du es Dir vorgestellt hast.
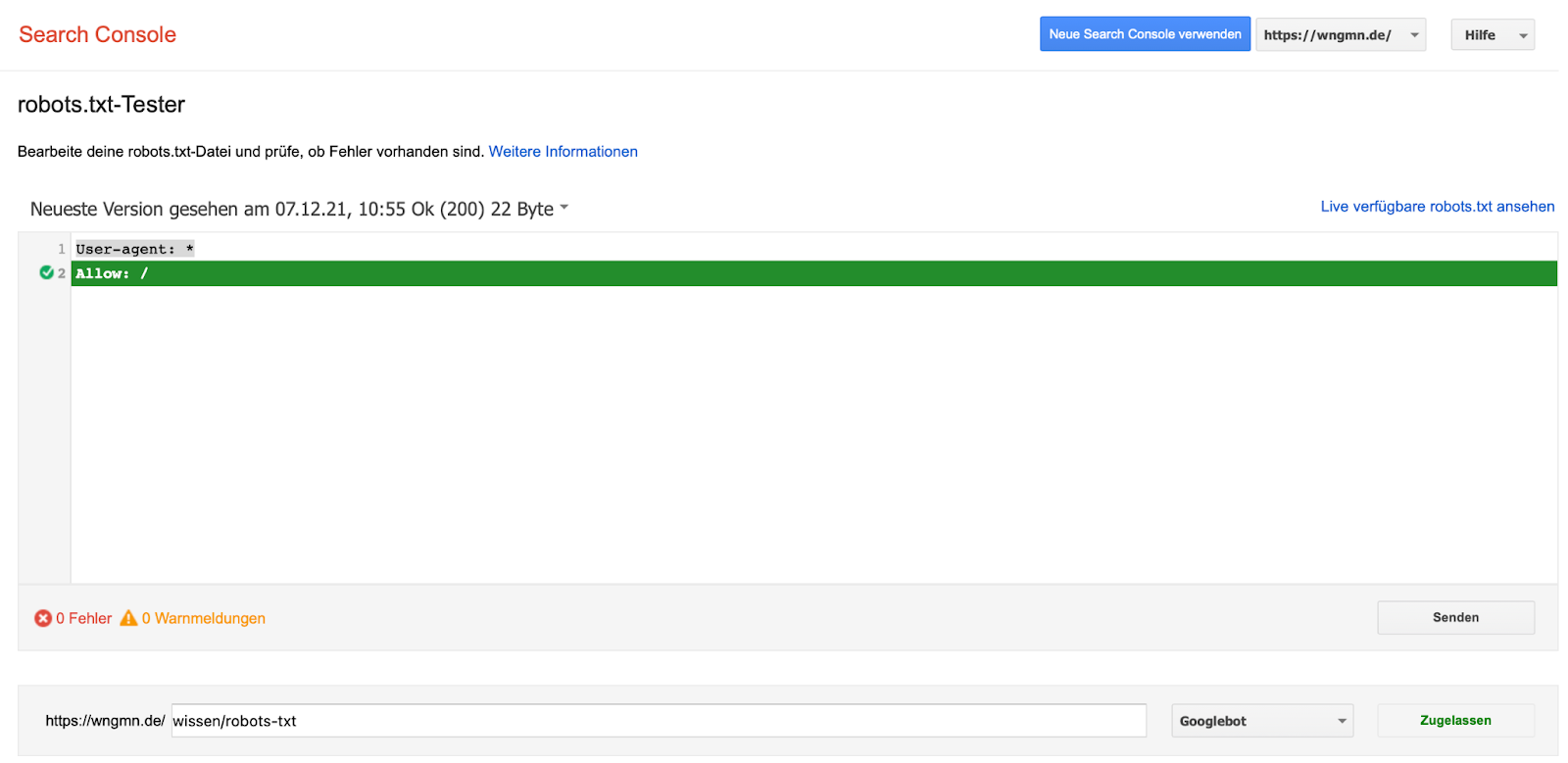
Wenn Du von robots.txt Dateien nicht genug bekommen kannst, dann sei Dir an dieser Stelle die folgende sehr ausführliche Lektüre empfohlen. Wir haben da nämlich schon mal
alles, was Du bezüglich robots.txt wissen und beachten solltest
zusammengetragen.
|
|
|
Autocomplete Suggest Menü füllt sich mit People also ask und People also search for
|
|
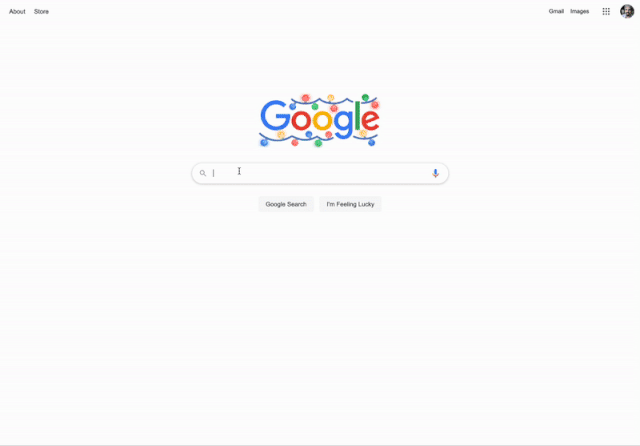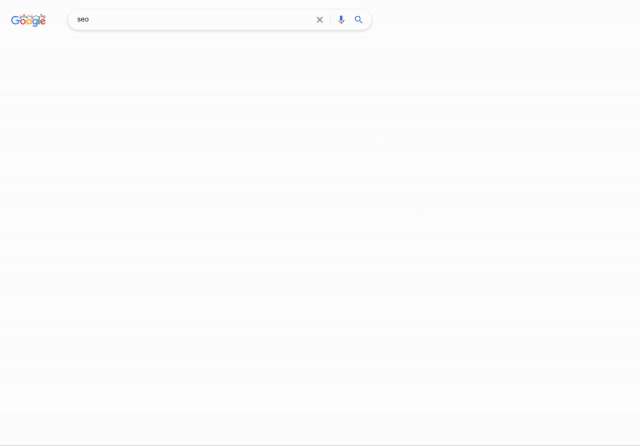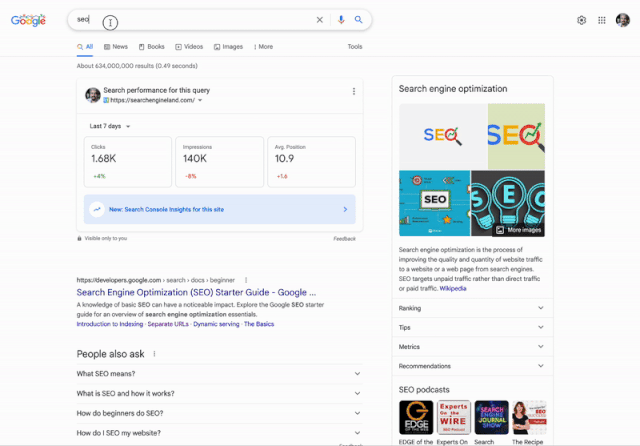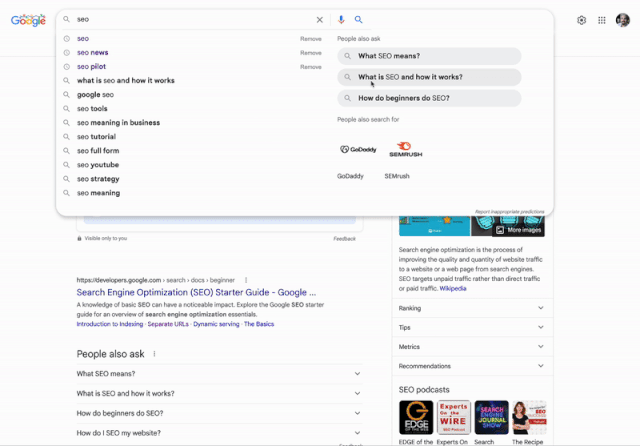
Offenbar befindet sich derzeit eine neue Darstellung im Bereich der Suchbegriff-Eingabe bei Google im Rollout. Barry Schwarz hat die Funktionsweise einmal
bei Search Engine Roundtable
als kleines GIF visualisiert.
In diesem Blogpost
bei Search Engine Land
gibt es noch ein paar ausführlichere Infos - zum Beispiel, dass Google den Launch dieser neuen Darstellung wohl auch offiziell bestätigt hat.
Google has officially launched a new enhanced autocomplete search suggestions that may include a second column of predictions, and provide easier access to content related to a search, a Google spokesperson confirmed with Search Engine Land.
Laut
Brodie Clark
lässt sich das ganze triggern, in dem man einen Suche ausführt und dann in das Eingabefeld klickt. Ich kann das bei mir bisher nicht reproduzieren. Aber
Phil von Sassen
ist dieses um "People als ask" und "People also search for" erweiterte Autocomplete Suggest Menü tatsächlich schon in freier Wildbahn begegnet.
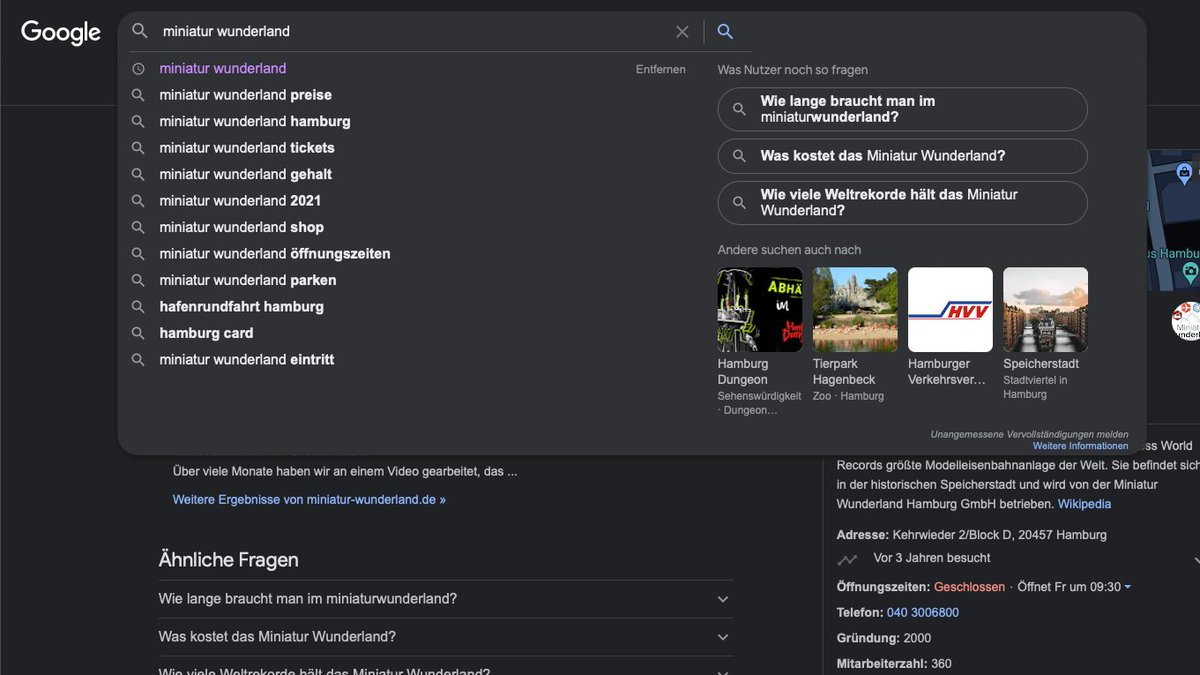
Da kommen bei mir direkt Fragen auf. Zum Beispiel, ob sich das rein auf die Darstellung auf dem Desktop bezieht oder ob damit zu rechnen ist, auch auf Mobilgeräten die regulären Suggest um weitere Elemente erweitert zu sehen. Das könnte ziemlich eng werden. Außerdem, direkt bezogen auf das Beispiel von Phil, wie toll es wohl das Miniatur Wunderland findet, dass auf der Suche nach der eigenen Brand andere Sehenswürdigkeiten wie das Hamburg Dungeon und der Tierpark Hagenbeck so prominent und visuell betont präsentiert werden.
Möglicherweise entstehen aber auch Vorteile dadurch, wenn im Suchkontext relevante Fragen direkt in den Fokus gestellt werden. Denn ob und wie stark diese in der Standardansicht ins Auge fallen und genutzt werden - da wird das Interesse im Rahmen der neuen Darstellung auf jeden Fall steigen.
Das wiederum hat zur Folge, dass wir ganz genau im Auge behalten sollten, ob und welche Fragen bei für uns relevanten Suchen - insbesondere solche, die die Marke beinhalten - aufkommen und vor allem was passiert, wenn man diese auswählt. Sind wir in der Antwort-SERP hinreichend vertreten oder muss hier noch etwas aufgeholt werden?
Ich bin auf jeden Fall gespannt drauf, ob mir dieses Format auch demnächst mal begegnet. Hast Du es schon beobachten und testen können?
|
|
|
Bei TYPO3 ist das Glas eher halb leer… 🖼
|
|
Kürzlich wurde ich darauf hingewiesen, dass das CMS TYPO3 beim Einpflegen von ALT-Attributen diesen Hinweis gibt: "This should be empty only for purely decorative images"
Eine Ausführung dazu findet man auch auf der Homepage von TYPO3
:
DAS BILD IST REIN DEKORATIV
Bei rein dekorativen Bildern lassen Sie das Feld Alternative Text leer. In der Praxis ist es oft schwer zu entscheiden, ob ein Bild rein dekorativ ist. Ein Bild ist dann dekorativ, wenn Sie das Bild weglassen können, ohne dass dabei die Aussage oder das Verständnis der Webseite beeinträchtigt wird.
Dieser Tipp ging mir nicht mehr aus dem Kopf und ich habe mir ein paar Gedanken dazu gemacht, warum ich diesen Hinweis als nicht sinnvoll erachte. Diese Gedanken möchte ich heute mir Dir teilen und wer weiß, vielleicht kannst Du mich auch vom Gegenteil überzeugen. 😉
4 Gründe, die gegen das Leerlassen von ALT-Attributen sprechen:
1. Wenn das ALT-Attribut leer ist, muss die jeweilige Suchmaschine trotzdem versuchen zu verstehen, in welchem Kontext das Bild eingebunden ist und in welcher Korrelation es zum jeweiligen Content steht. Das reine Leerlassen vermittelt einer Suchmaschine schließlich nicht die Botschaft: "Ist nur Deko, kannst Du ignorieren."
2. Falls das Bild aus irgendwelchen Gründen einmal nicht angezeigt werden kann, ist der ALT-Text wichtig, damit der Leser weiß, dass das Bild nicht so wichtig ist.\
3. Strategisch kann man natürlich auch hinterfragen, ob ein Bild, dass rein dekorativ und nicht wichtig für das Verständnis des Contents ist, dann überhaupt eine Daseinsberechtigung hat.
4. Wenn es um die Barrierefreiheit und Inklusivität einer Website geht, sind leere ALT-Attribute ebenfalls problematisch, denn Personen mit einer Hilfstechnologie wie einem Screenreader wird der Zugang verwehrt. Sollte es diesen Personen nicht aber selbst überlassen sein, die Relevanz oder Nicht-Relevanz eines Bildes zu evaluieren? Und darüber hinaus, warum sollte man diesen Personen ein dekoratives Bild vorenthalten?
Übrigens konnte ich weder bei Google noch bei Bing einen Hinweis dazu finden, dass Bilder in zwei Kategorien wie "rein dekorativ" und "wichtig für den Content" eingeteilt werden. In der
Bing Dokumentation zu Bildern
heißt es "Always provide descriptive alt attribute text with your non-text-based content." Hier wird lediglich eine Ausnahme für Elemente wie einen farbigen Hintergrund gemacht. Und auch
Google weist in den Bilder-Guidelines
lediglich auf die Verwendung von ALT-Attributen in Bezug auf Barrierefreiheit und maschinelles Verständnis hin und empfiehlt daher deren Pflege. Das ALT-Attribut sollte den Inhalt des Bildes beschreiben und darf Keywords beinhalten, aber nur, wenn diese wirklich zum Inhalt Deines Bildes passen.
Wie findest Du diesen Hinweis? Kannst Du ihn nachvollziehen? Vielleicht kennst Du auch eine andere Quelle, die die Empfehlung von TYPO3 begründet? Dann schreib mir gerne eine E-Mail 💌
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an
kontakt@wngmn.de
oder
ruf uns einfach kurz an:
+49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





