| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #65 |

|
| 💔 Wir haben uns alle lieb in der Fabrik |
Wir Wingmenschen haben uns wirklich alle lieb. Und in der SEO-Branche sind auch meist alle unheimlich toll zueinander. Aber manchmal menschelt es dann auch heftig. Mehr dazu findest Du im Abschnitt über das Title-Tag-Replacement.
Wir haben uns sogar so lieb, dass wir uns gestern zum ersten Mal seit einem Jahr getroffen haben. Viele Wingmenschen haben sich überhaupt zum ersten Mal gesehen. Schön wars und Corona-konform. Aber für einige Wingmenschen auch ganz schön viele Menschen auf einem Haufen.
Andere wiederum finden es so toll, endlich wieder Menschen um sich zu haben, dass sie am Mittwoch nach Berlin aufbrechen, um an der Campixx teilzunehmen.
Wenn Du nicht auf der Campixx bist und trotzdem Lust auf Input hast: Ich war letzte Woche beim SEO-Meetup Hamburg und bin über das Feedback hocherfreut:
Super interessantes Meet Up. Super aufbereitet und alles andere als langweilig. Wer "Search Off the Record" selbst nicht kennt bekommt hier zumindest einen sehr umfangreichen Überblick über die dortigen Themen.
und:
Auch wenn ich den Podcast von John, Martin und Gary selbst höre, ist diese Zusammenfassung und Interpretation sehr interessant gewesen. Vielen Dank dafür.
Aber auch hier gibt es natürlich wieder die volle Dröhnung SEO:
Hannah fasst die wichtigsten Punkte zur internen Verlinkung zusammen und Justus denkt das Thema etwas radikaler Ich habe einen Blick auf die Title-Changes geworfen während Caro zeigt, wieso die defaults des ScreamingFrogs nicht immer am Besten geeignet sind Und zum Abschluss frischt Andreas Röne Deinen Wissensstand zu HTTP-Headern noch mal auf.
|
|
| Interne Verlinkung - ein Reminder |
Ich habe mich in letzter Zeit sehr viel mit interner Verlinkung beschäftigt und möchte für Dich die wichtigsten Punkte notieren:
Vorweg: Deine wesentlichsten Seiten sollten von überall schnell erreichbar sein (beispielsweise über die Hauptnavigation). Ziel Deiner internen Verlinkung ist:
Prioritäten setzen: Welche Inhalte sind am Wichtigsten für Deine Nutzer (und Suchmaschinen) Inhalte erreichbar machen: Jeder Inhalt sollte über einen logischen Pfad erreichbar sein. Je kürzer der Pfad, desto besser für Nutzerinnen und Nutzer. Für Googlebot ist es noch schwerer. Denn Googlebot steht die interne Suche nicht zur Verfügung und oft auch nicht das Dropdown-Menü.
Schließlich musst Du berücksichtigen: Viele Nutzer steigen nicht auf der Startseite ein.
Wenn Du einen Link setzt, dann achte immer darauf, dass die Zielseite den Statuscode 200 hat, kein abweichendes Canonical und nicht auf noindex steht. Wenn Du aber doch einmal auf eine noindex-Seite verlinken möchtest / musst, weil es für den Nutzer sinnvoll ist, dann kann es bei sehr häufigen Linkmustern hilfreich sein den Link mit JavaScript für Googlebot zu maskieren.
Wenn Du einen Link setzt, dann musst Du ihn benennen, wir sprechen hierbei vom Linktext oder Ankertext. Hierbei bedenke bitte, dass:
der Ankertext relevant und aussagekräftig ist - am Besten mit Deinem Keyword der Zielseite der selbe Linktext darf immer nur auf eine Seite zeigen, nicht auf verschiedene, ansonsten verliert das Keyword seine Aussagekraft Links zu einer Seite sollten immer mit ähnlichen Linktexten benannt werden, damit das Thema der Zielseite deutlich ist Worte wie "hier" oder "mehr" sind keine aussagekräftigen Linktexte und sind zu vermeiden
Wenn Du den Link setzt kannst Du nicht nur entscheiden, welches Wording Du verwendest, sondern auch welches REL-Attribut der Link bekommen soll. Hier kannst Du beispielsweise das Attribut "nofollow" verwenden, wenn Du für den Inhalt der verlinkten Seite keine "Verantwortung" übernehmen willst oder Du deinen Pagerank auf der verlinkenden Seite behalten möchtest. Bei der internen Verlinkung ist es Google allerdings lieber, wenn Du statt nofollow den Link über die robots.txt ausschließt. Google Search Central hat noch weitere Attribute für Links aufgelistet und erklärt.
Na, wie sieht es aus - konntest Du noch etwas lernen, oder machst Du schon Alles richtig?
|
|
| Das Ende des Hauptmenüs |
Nach Hannahs Reminder zur internen Verlinkung folgt hier gleich der nächste:
Deine Hauptnavigation ist Nutzern egal.
In einem Test mit einem Informationsportal im Bereich Immobilien aus unserem Kundenkreis waren es ganze 1,5% aller Nutzer, die einen Link im klassischen "Hauptmenü" geklickt haben. Das waren Desktop-Nutzer, bei Smartphone-Nutzern waren es sogar deutlich unter 1%.
Dafür sehen wir deutlich zu oft, dass teilweise ganztägige Workshops dafür investiert werden, die Beschriftung der Hauptmenü-Links zu entscheiden.
Für SEOs mit bequem großen Monitoren und viel Zeit ist es leicht zu vergessen, dass Aufmerksamkeit eine knappe Ressource ist. Zu hoffen, dass Nutzer sie für eine komplizierte Navigation opfern, ist der falsche Weg.
Zu groß ist die Gefahr, darüber die wirklich wichtigen Navigationselemente, also Teaser und einfache Textlinks, zu vergessen.
Mythos: "Unsere Nutzer klicken sich durch bis sie zur gewünschten Seite kommen"
Niemand interessiert sich für Deinen Content, zumindest nicht von alleine. Aufmerksamkeit ist wertvoll, man muss sie sich verdienen, indem man gute Inhalte über die interne Verlinkung aktiv bewirbt.
Dabei besonders wichtig:
Themenrelevanz Informative, passende, schöne Überschriften und Teaserbilder Konsistente und vorhersehbare Inhaltsformate, mit denen Nutzer wissen, was sie erwartet
Mythos: "Wir müssen es möglichst einfach machen, von der Startseite überall hin zu kommen."
Diese Nutzer betreten eine Website über die Startseite:
Echte Fans, die regelmäßig vorbeischauen, um immer die neusten Inhalte zu sehen Nutzer, die von Deiner Marke gehört haben und danach suchen Du
Alle anderen steigen auf Unterseiten ein. Interne Verlinkung zu anderen relevanten Inhalten, muss auch genau dort platziert werden, sonst ist sie effektiv unsichtbar.
Mythos 3: "Das Hauptmenü ist die beste Anlaufstelle zur Navigation, darüber kommt man am schnellsten überall hin."
Die meisten Nutzer -- die mit Mobilgeräten -- sehen das Hauptmenü nicht einmal, weil es sich als Burgermenü hinter einem Icon versteckt, das auf großen Smartphonebildschirmen nur mit Handverrenkungen zu erreichen ist.
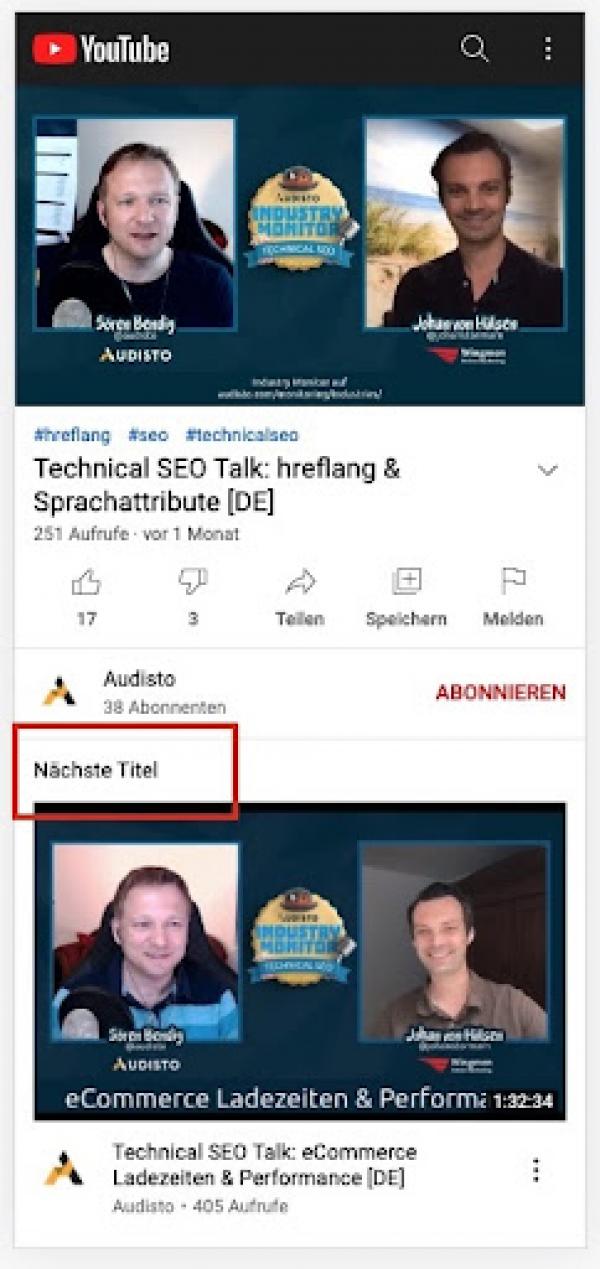
Hat kein Hauptmenü: Die mobile Ansicht von YouTube
Grundregel: Ausnahmslos jede Unterseite braucht einen klaren Call to Action, damit Nutzer wissen, was sie als nächsten tun sollen. Manchmal ist das eine Aufforderung zum Download, mal ein Sonderangebot zum Kauf, häufig ist aber ein ganz einfacher Link zum nächsten passenden Inhalt die beste Option.
Die Absprungrate ist ein guter Messwert dafür, wie gut diese Empfehlung angenommen wird, wenn auch ein ziemlich grober. Besser: Testen! Biete unterschiedliche Optionen an und schau, auf welche internen Links deine Nutzer ansprechen.
Im E-Commerce wird das für Produktlisten z. B. von epoq schon lange gemacht - es gibt aber keinen Grund, das Prinzip nicht auch auf redaktionellen Content anzuwenden.
|
|
| Hey Google: Kannst Du den Title für mich schreiben? |
Manchmal lassen Google Updates Emotionen hochkochen. Häufig Freude oder Angst, dass die eigene Domain jetzt mehr oder weniger relevante Besucher haben könnte.
Manchmal kocht sich das aber auch so hoch, dass Erwachsene Menschen auf ihrem professionellen Kommunikationskanal kommunizieren wie pubertierende Teenies:
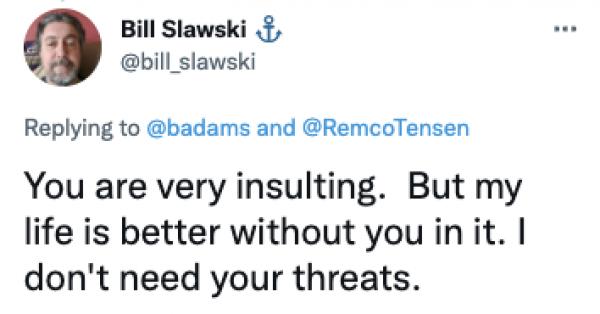
Bildunterschrift: You are very insulting. But my life is better without you in it. I don't need your threats.
Was ist eigentlich passiert?
Nun, wer sich für Gossip interessiert wird auf Twitter fündig. Eigentlich ist aber etwas interessantes passiert:
Google hat die Logik angepasst wie Titles in den SERPs ausgewählt werden
Es ist schon seit Jahren so, dass Google sich vorbehält Deinen Title-Vorschlag zu manipulieren. In den meisten Fällen orientiert sich Google am von Dir gesetzten Title, entfernt eventuell ein paar Zeichen oder fügt Deinen Brand (oder was Google dafür hält) am Ende hinzu.
Meist findet das Umschreiben der Description deutlich mehr Beachtung als das Umschreiben des Titles. Das liegt vor allem aber daran, dass der Title häufiger individualisiert wird als die Description und stärker darauf geachtet wird, dass er passt.
In der letzten Woche (17.08.) hat Google dann eine Änderung des Title-Algos vorgenommen. Dadurch sind viele Titles in den Suchergebnissen gekürzt und verändert worden. Einige der Anpassungen scheinen relativiert worden zu sein und Google aktiv an dem Thema zu arbeiten.
Einen guten Überblick hat Lili Ray geschrieben. Und auch Brodie Clark hat ein paar gute Punkte zusammengestellt.
Was bedeutet das für Dich?
Grundsätzlich ist Google sehr an Deinen Seitentiteln interessiert. Das Keyword sollte (idealerweise am Beginn) in Deinem Title vorkommen und wird auch weiter zum Ranking berücksichtigt.
Allerdings behält sich Google vor einen anderen Title zu wählen, wenn Dein Title Google nicht gefällt (oder nicht so gut zur Suchanfrage zu passen scheint).
Dabei lässt sich Google inspirieren von:
Dazu kommen dann Änderungen im Title oder Ergänzungen aus dem HTML:
Groß- und Kleinschreibung Entfernung / Ergänzung / Verschiebung des Brands Entfernung / Ersetzung von Trennzeichen (bspw. "|", ":" oder "👉") Ergänzung von Produktanzahl oder Ähnlichem
Was können wir bei wngmn.de beobachten?
In einer kleinen Stichprobe haben wir uns die Title für wngmn.de angesehen. Auffällig:
Der Brand wurde häufig gestrichen
 Ist der Brand enthalten geblieben, dann wurde die Pipe " | " durch einen Bindestrich " - " als Trennzeichen ersetzt Der Title wurde gekürzt (meist um 1 Wort, wenn ohnehin noch nicht vollständig) Für /leistungen/web-analyse wurde die H2 "Web Analyse KPI" genutzt
Die Änderungen sind aber eher geringfügig.
Heißt das jetzt ist Handlungsbedarf?
Nein. Auch wenn die Änderung gerade in US-Twitter heiß diskutiert wird, ist hier einiges im Flow. Google passt die Titles offensichtlich gerade sehr häufig an. Vor einer Änderung würde ich erstmal abwarten wollen.
Aber: In den nächsten Wochen wir es spannend zu analysieren wann Google Title/Description ersetzt und wodurch und vor allem, wie sich das wieder auf die CTR auswirkt. Denn wenn es eine schönere Darstellung in den SERPs gibt und Google Dir Möglichkeiten zeigt, dann wäre es nicht clever damit nicht zu experimentieren.
|
|
| Wie quakt der Frog am besten? |
In meinen ersten Monaten als Trainee habe ich das Anlegen und Durchführen von Crawls mit dem Screaming Frog gelernt (übrigens von Hannah und mir stets liebevoll Froggy genannt) und Gefallen daran gefunden.
Eins steht fest: Site Audits ohne eigenen Crawl = ohne eigene Datengrundlage.
Aber wie gestaltest Du Deinen Crawl für einen Site Audit am besten? Passend dazu gab es während meines Urlaubes hilfreiche Tipps zu den besten Froggy-Einstellungen für Site Audits, die ich jetzt frisch erholt gerne mit Dir teile. Die aufgeführten Aspekte beziehen sich auf Einstellungen, die nicht bereits per Default im Froggy vorhanden sind.
Denk daran, dass es nie die eine perfekte Einstellung für jeden Crawl geben wird. Es kommt ganz darauf an, welche Website Du crawlen möchtest. Macht es Sinn, bestimmte Daten für den Audit Deiner Website zu sammeln oder handelt es sich vielleicht auch um unnötige Datenlast?
Ein paar Beispiele direkt zur Hand:
Geht es um eine internationale Website? Dann crawle besser mit Hreflang, um sicherzustellen, dass Du alle URLs aller Sprachversionen entdeckst und somit in den Audit mit einbeziehen kannst. Wenn nicht - eher unnötig. Wird AMP für die Website genutzt? Crawle dies ebenfalls mit ab. Wenn nicht - auch eher unnötig. Inwieweit besteht die Website aus JavaScript? Bei einer Website basierend auf JavaScript solltest Du auch mit JS crawlen. Falls Server Side Rendering genutzt wird, kann es sinnvoller sein, Text only zu crawlen, um zu sehen was der Googlebot schon vor dem eigenen Rendering sieht. Oder man möchte vielleicht zwei Crawls (Text only vs JS) miteinander vergleichen, um mögliche fehlende Elemente in der JS-Version aufzudecken.
Um weiter sicherzustellen, so viele Daten wie möglich zu sammeln, kann Pagination mit gecrawlt werden - nur für den Fall, dass paginierte Seiten ansonsten im HTML Body nicht verlinkt sind. Gerne crawle ich auch immer außerhalb der Start Folders sowie auch alle Subdomains, um wirklich alle Folder und Subdomains entdecken und prüfen zu können (wobei natürlich meistens sowieso bereits die Root für Site Audits gecrawlt wird und daher automatisch alle darunter liegenden Folder inkludiert sind). Das gleiche gilt für Sitemaps - crawlst Du diese mit, kannst Du die Sitemap direkt mit überprüfen und zum Beispiel auch Seiten entdecken, die vielleicht ansonsten nicht weiter intern verlinkt sind. Weitere zu überprüfende Dinge, die bei Site Audits Crawls mit berücksichtigt werden können, sind HTTP Headers und Structured Data.
Das Crawling von nofollow-Seiten wird im Guide zwar empfohlen, um noch mehr Seiten zu entdecken, nofollow-Links zu crawlen, beansprucht bei großen Seiten jedoch sehr viele Ressourcen. Da kann es auch helfen, einmal in den All-Outlinks-Report zu schauen und die Ressourcen zu sparen.
Etwas, was ich bisher nicht auf dem Schirm hatte: Im Guide wird empfohlen, die maximal zu folgenden Redirects von 5 auf das Maximum (20) zu setzen, um auch sehr lange Redirect-Ketten zu erfassen. Kann nicht schaden, sollte aber (hoffentlich) selten der Fall sein (oder auch nicht? Was sind Deine Erfahrungen?).
In dem Guide befinden sich noch viele weitere Empfehlungen für den optimalen Crawl bei einem Site Audit, die unseren Newsletter jetzt leider sprengen würden. Aber wie sieht es bei Dir aus? Hast du eine Standardeinstellung für Site Audit Crawls oder variierst Du je nach Website? Welche Einstellungsoptionen passt Du am häufigsten individuell an?
|
|
| HTTP-Header - kaum Jemand kennt Ihn aber jeder nutzt ihn täglich viele Male, ganz unbemerkt! |
Einige von Euch werden mit Sicherheit schon einmal den Begriff HTTP-Header gehört oder gelesen haben. Doch was genau ist das eigentlich?
Den HTTP-Header kann man sich auch als versteckte Kommunikation zwischen einem Browser und einem Webserver vorstellen. Daten die also zwischen den beiden Computerprogrammen über das Internet ausgetauscht werden, die wir als Benutzer aber im normalen Umgang mit dem Browser nicht sehen. Dabei müssen wir zwischen sogenannten Request-Header und Response-Header unterscheiden.
Request-Header
Der Request-Header wird vom Browser mit jeder Anfrage für eine Datei zu einem Webserver verschickt. Darin enthaltene Daten sind unter anderem:
Die Methode der Anfrage. "POST" und "GET" sind hier die bekanntesten Methoden. Wenn Du eine URL in Deinem Browser eingibst oder einem Link folgst werden diese daten im Normalfall via GET-Methode übertragen. Alle nötigen Informationen werden dabei in der URL übergeben. Die POST-Methode hingegen wird verwendet, wenn viel mehr Daten übertragen werden oder die Daten nicht an die URL angehängt werden sollen. Bei dieser Methode werden die Daten Teil des Request-Headers und somit "versteckt" übertragen. Die wohl häufigste Verwendung ist hier ein Kontaktformular. In so einem Fall wäre es gar fatal, wenn die Daten per GET-Methode Teil der URL werden würden, denn diese landen in vielen Fällen in Logfiles der Server oder gar der Google Analytics Property. Die Browserkennung, auch bekannt als UserAgent Cookies die zu der Domain gehören für die gerade eine Datei angefragt wird Welche Sprachen werden von dem Browser und dem Benutzer unterstützt (Dies kannst Du in den Browsereinstellungen bestimmen) Welche Komprimierungsverfahren unterstützt der Browser um Daten ggf. komprimiert zu empfangen Welche Grafikformate unterstützt der Browser? Der Server könnte z.B. Grafiken in kleineren, modernen Formaten senden, wenn der Browser damit umgehen kann (WebP und Avif) und so Ladezeiten verkürzen. Und natürlich den sogenannten "Referer". Wobei immer mehr Browser aus Datenschutzgründen dazu übergehen, diesen nicht mehr immer mit zu übertragen.\
Dieses Feld wird immer dann gefüllt, wenn die aktuelle Anfrage auf einer zuvor gestellten Anfrage beruht. Wenn der Browser z.B. eine Javascript- oder Bilddatei nachladen muß, weil diese auf einer zuvor geladenen HTML-Seite eingebunden werden soll. In solch einem Fall würde das Feld mit der URL der HTML-Seite gefüllt.\
Ein weiterer Grund weshalb der Referrer gefüllt sein könnte ist ein Link. Wird eine HTML-Seite in einem Browser geladen weil der Benutzer auf einen Link geklickt hat, enthält der Referer die URL der weiterleitenden HTML-Seite.
Du siehst, dass sind viele Daten, die Du mit jedem Aufruf einer HTML-Seite, jeder Grafik und jedem Script überträgst, diese jedoch nie wirklich siehst.
Response-Header
Der Response-Header ist das genaue Gegenstück des Request-Headers, die Antwort des Servers sozusagen. Darin sind Anweisungen und Informationen enthalten, wie der Browser mit den Daten umgehen soll, die nach dem Header gleich im Anschluss gesendet werden.
Wieso ist der HTTP-Header für uns SEOs so interessant?
Zumindest der Response-Header ist für uns SEOs interessant. Können wir hier:
doch Einfluss auf das Browser-Caching nehmen Suchmaschinen das Indizieren von Dateien verbieten und viele weitere Einstellungen vornehmen.
Tipp: In einigen Browsern wie Chrome und Firefox kannst Du Dir über die Entwicklertools des Browsers die Kommunikation anschauen. Öffne hierfür z.B. in Chrome einfach die Entwicklertools (Apple: Option+Command+I) und wähle den Reiter "Netzwerk".

Wenn Du nun eine HTML- Seite geladen hast, werden alle Dateien und Netzwerkanfragen aufgelistet. Wählst Du nun eine einzelne Datei aus, öffnet sich ein Bereich in dem Du die kompletten Header von Browser und Server einsehen kannst.
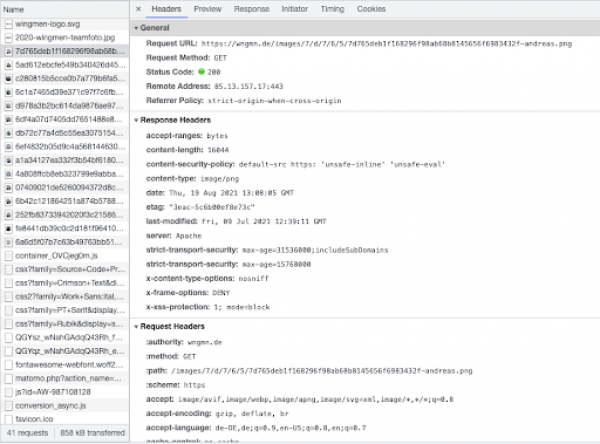
Viel Spass beim Ausprobieren!
Das hast Du jetzt bestimmt als erstes bei Deiner eigenen Website ausprobier, stimmt's? :-) Wenn Du Fragen haben solltest scheu Dich nicht mich oder einen anderen Wingmen zu kontaktieren. Wir freuen uns auf Dein Feedback und Fragen.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmen
|
|
|




