| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #275 |
|
|

|
| 🕵️♀️🍽️ Bratort Münster – Spurensuche nach schmackhafter Beratung |
Tatort? Fast. Letzte Woche war unser Wingmen-Offsite in Münster und statt Mordkommission hieß es bei uns: Ermittlungen im Fall Beratungsqualität. Die Indizien fanden wir nicht im Hinterhof, sondern auf dem Teller. Denn: Gutes Essen und gute Beratung haben mehr gemeinsam, als man denkt.
Die Spur führte uns zu drei entscheidenden Kriterien:
👉 Geschmack, also die Frage: Schmeckt’s uns selbst (Werkstolz) und unseren Kunden?
👉 Gesundheit: Objektive Qualitätsfaktoren, die eine Beratung nahrhaft machen statt Fast Food.
👉 Nachhaltigkeit: Das, was bleibt, wenn die Teller längst abgeräumt sind: Wirkung beim Kunden.
So saßen wir also zusammen, wie Kommissar:innen an einer Beweiswand, sammelten Perspektiven, legten Rezepte an und überlegten, wie wir künftig noch schmackhaftere Beratungsmenüs servieren.
Und weil wir keine halben Sachen machen, liefern wir Dir heute nicht nur das Protokoll aus Münster, sondern auch die heißesten SEO-Spuren der Woche:
- Justiz-Johan nimmt KPI ins Verhör
- Nachforschungs-Nils protokolliert die Beweisstücke zu Googles Spam-Update
- Clever-Cleo enttarnt die Zugänglichkeit von Webseiten für KI-Modelle
- Meisterdetektiv-Matt löst den Store-Widget Fall
- Ich bringe Licht ins Dunkle der Produktivität mithilfe von Apps
Fall abgeschlossen? Noch lange nicht. Aber wir sind der Beratungsqualität in Münster auf die Schliche gekommen.
Deine Wingmenschen
|
|
| Neue KPI, alte KPI – alles [K]ein [P]lanungs[I]ndikator |
Oder: Warum wir aufhören müssen, an die Messbarkeits-Illusion zu glauben
Mit KI kommen neue Tools, neue Reports – und natürlich: neue KPIs!
Zumindest steht das überall.
Und dann kommt sie: die Slide mit den „23 KPIs, die Du jetzt brauchst“.
Du schüttelst den Kopf. Und wir auch.
Denn:
Eine KPI ist ein (!) aggregierter Faktor aus mehreren Metriken, der Orientierung gibt.
KPI im Plural? Ist wie „Alleinstellungsmerkmale“.
Wer mehrere KPIs pro Kanal hat, hat den KPI-Grundsatz nicht verstanden.
Wir schütteln weiter den Kopf.
Denn:
Wie kann Dir jemand eine KPI empfehlen, der Deine Ziele, Projekte, Strategie und Situation nicht kennt?
Metrik? Okay.
Leading Indicator? Vielleicht.
Aber KPI? Niemals! (Hier Braveheart-Meme vorstellen bitte)
Daten sind eine Illusion
Als ich mit SEO begann, habe ich geglaubt:
Online können wir alles messen. Also treffen wir datenbasierte Entscheidungen.
Schön wär’s.
Aber diese Illusion kostet jedes Jahr Geld.
Und sie ist doppelt falsch:
- Wir können nicht alles messen – und das, was wir messen, ist oft falsch.
- Wir glauben, wir könnten auf Basis dieser Daten sicher entscheiden.
Was wir eigentlich wissen wollen:
Nehmen wir mal die Basisformel:
Indexierte Seiten × Rankings × Suchvolumen = Impressions
Impressions × CTR = Traffic
Traffic × CR × Warenkorb = Umsatz
Klingt einfach. Aber um gezielt zu optimieren, müssen wir den Ist-Zustand dieser Werte kennen. Und da wird’s haarig.
Indexierung: Nicht mal das Einfachste klappt
Wie viele Seiten sind indexiert?
Die grobe Antwort geht.
Aber: Welche Seiten? → ab 2.000 URLs wird’s hässlich.
- GSC zeigt max. 1.000 URLs je Bericht, mit 3–5 Tagen Delay.
- Live-Check via API? Ja, aber nur 2.000 URLs pro Property.
- Vertical-Indizes wie Google Scholar, Shopping, News? Keine Chance.
Als Hilfsgröße können wir für Web, Image oder News die Impressions heranziehen. Eine URL mit Impressions muss ja indexiert sein. Aber:
- Klickdaten ≠ Indexierungsdaten
- Kein Query → keine Messung → keine Daten → keine Entscheidung
Aber immerhin Clicks können wir messen
Jetzt sagen manche: Ja, das gilt für die Indexierung, aber ja nicht für den Traffic. Denn die GSC reported alle Klicks und Impressions.
Aber auch das stimmt nicht. Wir haben das Problem:
- der Anonymisierung,
- dass nicht die Daten aller Such(maschinen) von Google in die GSC einlaufen
- und umgekehrt, dass wir ein organisches Ranking und ein Ranking über die Bildersuche der Universal Search nicht auseinanderhalten können
- Wir haben die tageweise Auflösung der Daten, die Schwankungen innerhalb des Tages nicht auflösbar macht (zugegeben für die letzten 10 Tage ist das mit den 24h Daten besser geworden. Die gibt es aber wieder nicht im BigQuery Datenexport)
Und selbst wenn wir die Daten in BigQuery haben und alle Clicks auswerten können und die Ungenauigkeiten akzeptieren, dann fehlt zu unserer Erhebung noch das Verhalten auf der eigenen Seite:
Und selbst, wenn wir das Problem lösen und ein eigenes Server-Side-Tracking auf unserem eigenen Server haben ohne die Daten anonymisieren zu müssen, weil sie bei Drittparteien gespeichert werden, gibt es Lücken:
- User, die keinen Referer übergeben
- Die das Tracking anderweitig unterbinden
- AI Agents, die als User getrackt werden
- Interner Traffic, der nicht ausgeschlossen wird, weil die Mitarbeiter im HomeOffice arbeiten und niemand daran gedacht hat die Logik “interner Mitarbeiter = Firmen-IP” zu hinterfragen
Und auch wenn wir diese Themen lösen und die Conversions sauber erfassen, dann müssen wir noch die Retouren, gescheiterten Zustellungen und stornierten Zahlungen lösen.
Aber mal angenommen wir haben das alles sauber aufgesetzt:
Können wir dann SEO sauber messen?
Was ist denn mit:
- Bing?
- DuckDuckGo? Brave? Ecosia?
- Web.de Suche?
- Traffic über CoPilot?
Und auch da wieder die Frage nach Indexierung? Keywords? Traffic?
Und natürlich hast Du Recht: Das ist alles gar nicht so schlimm, weil das ja alles Daten der Vergangenheit und für vergangene Performance sind. Das hilft uns gar nicht so sehr bei der Gestaltung der Zukunft.
Aber wie planen wir Zukunft?
- Mit Suchvolumina von Einzelkeywords, die diese Keywords in der Vergangenheit in Google hatten?
- Mit Suchvolumina, die massiv verzerrt, politisch zensiert und für Ad-Umsatz optimiert sind?
- Mit A/B-Tests in Google, bei denen kaum jemand den Zeitpunkt der (Neu)-Indexierung beachtet und damit massive Verschiebungen in den Tests hat?
- Mit dem Ergebnis von limitierten Tests in Google, deren Aussagekraft durch die oben genannten Schwierigkeiten kaum belegbar ist?
- Mit der Annahme, dass Suchvolumen der Zukunft sich so verhält, wie Suchvolumen der Vergangenheit?
Interessanterweise scheinen of die, die sagen, dass sich alles ändert und die, die sagen, dass alles messbar ist, die gleichen zu sein.
Natürlich braucht es bei großen Investitionen einen Business Case.
Natürlich muss am Ende eine positive Entwicklung stehen.
Aber die Illusion, dass alles messbar ist, die müssen wir endlich aufgeben, damit wir mit den Daten, die wir haben, vernünftig arbeiten können.
|
|
| PlusSpamPerfekt: Wir hatten ein Update gehabt |
Fast einen Monat hatten wir Spaß am August Spam Update. Es begann am 26.08.2025 und gestern, am 22.09.2025 kam die Meldung, dass es abgeschlossen wurde. Diese vergleichsweise lang laufenden Updates nagen gut an den Nerven eines SEOs, machen sie doch größere Bewegungen bei den eigenen Rankings zu einem zweischneidigen Schwert. Liegt der neueste Rankinggewinn jetzt an meiner Maßnahme oder profitiere ich vom Update? Bin ich vom Update betroffen, oder ist was mit meiner Seite passiert?
Rückblickend kann man sagen, dass global in DE vor allem die letzte Woche vor dem Ende des Updates in den SERPs für eine starke Volatilität gesorgt hat.
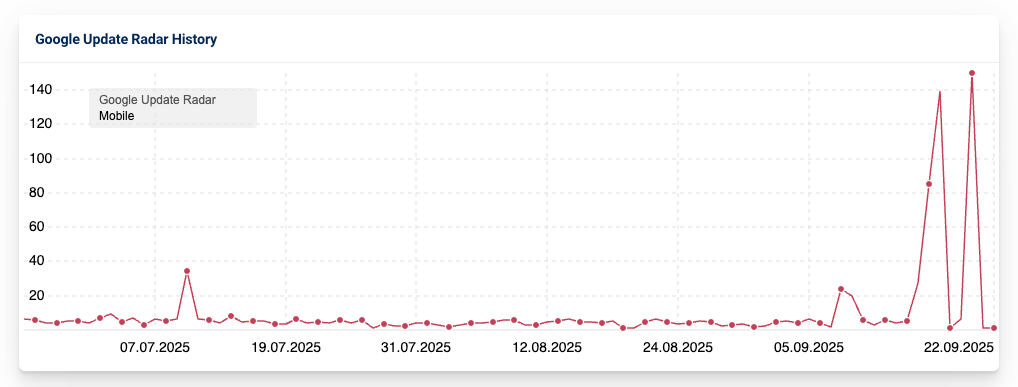
Meine persönliche Erfahrung war diesmal, dass insbesondere in den ersten Tagen starke Rankingschwankungen bei mehreren Kundendomains zu sehen waren. Hier würde mich interessieren, ob das bei Dir auch so war? Das Update-Radar von Sistrix legt es zumindest nicht nahe.
Wie immer gilt für die Updates: Wenn sich der Staub erstmal gelegt hat, können wir sehen, was am Ende dabei herumgekommen ist. Wie immer sollten hauptsächlich Seiten negativ betroffen sein, die sich nicht an die Guidelines halten. Es wäre aber auch nicht das erste Mal, dass Traffic von Seiten verschwindet, der beispielsweise nach einem früheren Spam-Update gestiegen ist.
Insofern nimm diesen Beitrag gerne als Anlass, nochmal in Deine Auswertungen zu schauen.
|
|
| Peekaboo: Wie Du siehst, siehst Du nicht immer was |
Die Frage, wie Inhalte von Webseiten für KI-Modelle wie ChatGPT oder Gemini zugänglich sind, entwickelt sich derzeit zu einem Prüfpunkt für technische Auslesbarkeit. Denn während Nutzer und Nutzerinnen längst an nahtlose, interaktive Oberflächen gewöhnt sind, wie schnelle Filter, dynamische Nachlade-Prozesse oder personalisierte Inhalte, basiert vieles davon auf JavaScript. Für Nutzer ist das selbstverständlich und kaum wahrnehmbar. Für Large Language Models hingegen entsteht damit eine unsichtbare Wand: Was im Browser flüssig funktioniert, bleibt für KI-Systeme oft unlesbar.
Damit prallen zwei Welten aufeinander: Auf der einen Seite moderne Frontend-Technologien, die das Nutzererlebnis perfektionieren sollen, auf der anderen Seite Sprachmodelle, die Inhalte nur so gut interpretieren können, wie sie technisch zugänglich gemacht werden. Das Resultat: Viele Produktinformationen, Preise oder Beschreibungen, die für User elementar sind, verschwinden für KI-Modelle in einer Blackbox. Wenn ich also ChatGPT frage, welche Produkte Firma XY anbietet, kann es mir keine Aussagen darüber machen.
Was ist das Problem?
ChatGPT und Gemini erkennen zwar, dass es sich bei Kategorieseiten um solche handelt, können die Inhalte jedoch nicht lesen, wenn diese aus clientseitig gerendertem JavaScript bestehen. Auch Produktdetailseiten verlieren ihren Informationswert für LLMs, wenn Inhalte ausschließlich clientseitig nachgeladen werden.
Selbst korrekt eingebundenes JSON-LD im Quelltext wird von LLMs nicht zuverlässig verarbeitet, um Aussagen über Seiteninhalte zu generieren. Innerhalb eines <script>-Tags bleiben Daten für diese Modelle praktisch unsichtbar.
Gerade bei Gemini, dessen Nähe zu Google eigentlich vermuten ließe, dass es Scripts problemlos ausliest, fällt die eigene Erklärung des Modells überraschend nüchtern aus: Das Problem ist nicht das Vorhandensein von Markup, sondern dass seine Werkzeuge nicht darauf ausgelegt sind, strukturierte Daten in Skripten zu parsen.
Schema bleibt trotzdem wichtig. Wer es konsequent pflegt, gewinnt Relevanz im etablierten Such-Ökosystem und positioniert sich auch für AI, nur im direkten Grounding-Prozess aktueller Sprachmodelle liefern strukturierte Daten bislang keinen messbaren Vorteil.
Wer sich zukunftssicher aufstellen will, sollte auf technische Auslesbarkeit setzen:
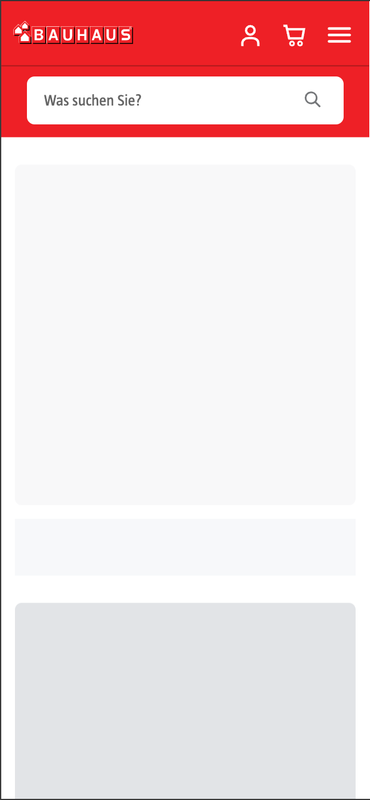
Server-Side Rendering einsetzen, um Inhalte nicht ausschließlich clientseitig nachzuladen und regelmäßig prüfen, wie Bots und LLMs Inhalte tatsächlich sehen. Tools, die eine nicht gerenderte Ansicht zeigen, offenbaren oft erschreckend leere Ergebnisse.
Am Beispiel von Bauhaus wird deutlich, was der Nutzer sehen kann

und was das LLM sieht, nämlich nichts.
Agentenmodus vs. Standardmodus
Ein Sonderfall ist der so genannte Agentenmodus von ChatGPT. Hier wird von dem LLM ein echter Browser genutzt, der JavaScript rendert. Doch der Agentenmodus ist kein Standard und für die meisten Anwendungen von AI in Such- und Assistenzfunktionen bleibt die Limitierung bestehen.
Fazit
AI-Readiness ist weniger eine Frage von Markup als von technischer Transparenz. Inhalte, die nur über JavaScript ausgeliefert werden, bleiben für aktuelle Inferences, die mit dem Server zugreifen, unsichtbar.
Und klar ist auch: Die Entwicklung schreitet rasant voran. In den kommenden Monaten wird sich zeigen, ob und wie schnell sich die Fähigkeiten von LLMs beim Auslesen von Strukturierten Daten und JavaScript weiterentwickeln und welche neuen Chancen oder Hürden dadurch entstehen. Deine rasenden Reporter bleiben an der Sache dran.
|
|
| Store Widget: Der neue Conversion-Boost für Online-Shops? |
Wenn Du gerne online einkaufst und hin und wieder neuen Shops eine Chance gibst, kennst Du vermutlich die Sorgen: Der Warenkorb ist voll, der Preis unschlagbar. Verdächtig unschlagbar. Schon kommen die ersten Zweifel auf: Sollte ich hier wirklich kaufen? Oder sehe ich dann weder die Ware noch mein Geld jemals wieder?
Genau hier setzt Google erfreulicherweise mit einem Widget an, dem Store Widget.
Was hat es mit dem Store Widget nun wieder auf sich?
Besagtes Store Widget lässt sich ganz einfach per Code-Snippet in jede Shop-Seite einbauen. Dort zeigt es Besucherinnen und Besuchern dann auf einen Blick, wie es um Kundenbewertungen, Servicequalität sowie Versand- und Rückgaberichtlinien steht:
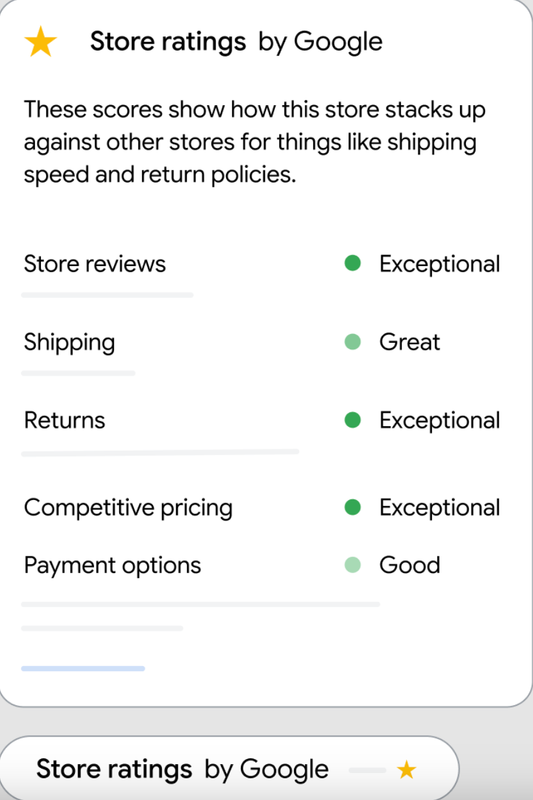
Neben Trustedshops, den klassischen Google-Bewertungen und Co. also ein weiterer Vertrauensboost. Inklusive Qualitätssiegel für Top Händler.
Klingt im ersten Moment sehr, sehr nice. Und noch besser: Es aktualisiert sich automatisch mit aktuellen Bewertungen. Der manuelle Aufwand ist demnach überschaubar.
Drei Stufen, je nach Bewertung
Dabei gibt es drei Stufen dieses Widgets. Nämlich:
- Top Quality Store Widget: Für Händler mit Spitzenqualität: Das Gütesiegel für ein herausragendes Einkaufserlebnis.
- Store Rating Widget: Wenn schon gute Bewertungen da sind, der Top-Status aber noch nicht erreicht ist.
- Generic Store Widget: Die Basisversion für alle, die auf dem Weg sind, sich diese Abzeichen zu verdienen.
Warum das spannend ist und was das bedeutet
Google selbst berichtet, dass Shops mit einem solchen eingebauten Widget innerhalb von 90 Tagen bis zu 8 % mehr Verkäufe erzielen. Das ist eine Menge! Vor allem, wenn man bedenkt, dass dafür nur ein kleiner JavaScript-Fetzen eingebaut werden muss. Klingt also nach einem kleinen Zusatz mit großer Wirkung, der die Conversions ordentlich nach oben treiben kann.
Gerade ich verlasse mich bei Restaurants und Online-Shops doch sehr stark auf Sternebewertungen. Trotz des Wissens, wie käuflich und manipulierbar solche Angaben sein können. Vor allem größere, schon bekannte Shops werden hiervon vermutlich profitieren. Für Shops, die neu dazukommen, könnte das die Chancen erschweren, sich am Markt zu etablieren. Aber wie üblich: Lassen wir uns doch erst einmal überraschen. Zumal das Widget ja Daten mit Google-Servern austauscht… Stichwort: Datenschutz. Ein beliebtes Thema in der Kombination Google + EU.
|
|
| 📲 Mach Dir ’ne App draus: Mein Productivity-Hack für Gmail & Calendar |
Ich sag’s mal so: Eines der größten Privilegien bei Wingmen ist, dass ich nicht mehr mit Microsoft 365 arbeiten muss. Wie Behrend neulich schon im letzten Newsletter geschrieben hat: Teams, SharePoint und Co. sind für mich eine Katastrophe.
Excel, Word und PowerPoint? Die will ich nicht unbedingt missen. Aber wenn’s ums Zusammenspiel und kollaboratives Arbeiten geht, macht Google das einfach deutlich besser. Daher bin ich froh, dass wir auf Google Workspace setzen.
Dennoch bin ich bei Wingmen an einem Punkt anders: Ich bin der einzige ohne Macbook. Stattdessen tippe ich fröhlich auf einem Windows-Gerät herum. Mit dieser ganzen Äppelwoi-Technik kann ich mich einfach nicht anfreunden. Für mich ist das einfach nur „Most“. Aber ja, damit bin ich hier allein auf weiter Flur. Die Diskussion über den ewigen Wettstreit zwischen Windows und Apple bleibt am Ende genauso ergebnislos wie die Verständigung zu der Frage, ob es “Dreiviertel drei” oder “Viertel vor drei” heißt. Oder ob man Pfannkuchen “Berliner” nennen darf.
Doch zurück zum Thema. Google Workspace ist cool, aber trotzdem hatte ich hier schon immer ein Problem: Ich kann mich nicht damit anfreunden, wenn E-Mail und Kalender nur im Browser laufen. Für mich gehören die als eigenständige Programme auf den Desktop. So wie’s auf dem Smartphone ja auch eigene Apps gibt.
Mein Workaround war früher jahrelang Outlook. Für mein Google-Konto. Und das war … naja … für alle Beteiligten bescheiden. Ihr kennt das sicher auch? Da sieht die Kalendereinladung dann einfach Murks aus. Das matcht so gar nicht miteinander.

Umso glücklicher war ich, als ich vor einiger Zeit WebCatalog entdeckt habe. Das Tool macht eigentlich nichts anderes, als Websites in eigenständige Desktop-Apps zu verwandeln. Heißt: Ich habe jetzt in meiner Taskleiste zwei hübsche „Programme“ - eins für Gmail und eins für Google Calendar.

Das Ganze ist kostenlos für bis zu zwei Apps. Reicht mir völlig. Denn viele andere Tools haben sowieso schon brauchbare Desktop-Versionen.
Einziger Wermutstropfen: Man muss WebCatalog und die erstellten Apps regelmäßig updaten. Für mein Empfinden etwas zu oft. Aber das wird seine Gründe haben. Damit kann ich leben.
Falls Du also auch so tickst wie ich und bestimmte Web-Tools lieber als eigenständige Desktop-Programme hättest: Schau’s Dir mal an. Falls nicht: auch gut, dann scroll einfach weiter 😉
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|




