|
Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #69
|

|
|
9️⃣6️⃣ Nanu Nona? Wer sucht denn da?
|
|
Nein! Bei den Emoji dieser Ausgabe handelt es sich nicht um einen Zahlendreher. Denn bei Redaktionsschluss waren es nur noch 96 Tage bis Weihnachten.
Mit den ganzen neuen Suchmaschinen verlieren gerade den Überblick. Jetzt kommt mit
nona.de
die Nächste.
Und da passt es hervorragend, dass wir auch intern was Neues probieren. Unser jahrelang geliebtes Podio muss einem jüngeren Tool weichen.
Notion
wird jetzt unser Zentrum für Dokumentation und wir versprechen uns eine Menge frischen Wind davon.
📦 Aber wie bei jedem Umzug ist es auch jetzt: wo ist nochmal der Karton mit dem Besteck? Wo finde ich Kerzen? Und wer hat denn die Bücher SO ins Regal gestellt? Das kann man doch nicht machen?
In all dem kreativen Chaos haben wir trotzdem richtig spannende Geschichten für Dich gefunden:
-
Nils beschleunigt Deine Ladezeiten mit einem einfachen Trick.
-
Behrend hat einen kleinen Fehler mit schlimmen Auswirkungen gefunden.
-
Ich hab mir ein paar neue Maschinen auf dem Suchmarkt angesehen.
-
Außerdem haben wir die vorletzte Campixx-Review für Dich dabei und einen Event-Tipp für heute Abend!
Jetzt aber rein in die gute Content-Stube!
|
|
|
Fahrlässige Freitags Fehler forcieren fatale Fehlannahmen
|
|
Es ist exakt 15.33 am Freitag als wir diese Mail-Benachrichtigung von Ryte bekommt. Es geht dabei um einen Kunden dem wir vor zwei Jahren beim Umzug von der .de-Domain auf .com unterstützt haben.
Betreff: Änderung der Robots.txt für Domain.de
https://www.domain.de/robots.txt
hat das Redirect-Ziel geändert:
Alt:
Location: https://www.domain.com/de-de/?utm_source=domain.de
Neu:
Location: https://www.domain.com/en-de/?utm_source=domain.nl
Wir sind fast vom Stuhl gefallen.
Was lief hier vorher schon falsch?
-
Die Robots.txt sollte idealerweise von der catch-all-Redirect-Regel ausgenommen sein und eine Robots.txt bereitstellen, die explizit das Crawling von domain.de erlaubt, um das Crawling der Redirects sicherzustellen
-
Schon vorher ging der Redirect mit einem utm_source=parameter auf die neue Domain. Das erschwert Google die Verarbeitung der Weiterleitung. Denn Google muss dann nicht nur die Weiterleitung verarbeiten, sondern auch das Canonical von mit Parameter auf ohne Parameter. Die Identifizierung der Original-URL fällt schwerer. Unter Umständen ranked Google weiter die .de statt der .com
-
Durch den UTM-Parameter werden im Zweifel Sessions mehrfach gezählt. Die zusätzliche UTM-Angabe überschreibt dabei den Referrer und es gehen Reporting-Informationen verloren: Die Weiterleitung führt zu einer Überbewertung der alten Domain im Reporting
Was läuft jetzt noch falscher?
-
Der Redirect zeigt nicht mehr auf /de-de/, sondern auf /de-en/. Die deutschen Inhalte werden auf die englische Variante weitergeleitet. Das führt zu einer weiteren Schwächung der Redirects, denn jetzt sind die Inhalte der alten Domain nicht mehr identisch mit denen der neuen Domain
-
Die Änderung der Redirects kann grundsätzlich führt dazu, dass Google die alten URL-Gruppen auflösen und neu bilden muss. Das kann zu einer kompletten Entwertung der Redirects führen
-
Die utm_source wurde von .de auf .nl geändert. Damit werden im Reporting die Besuche von .de den Kollegen aus den Niederlande gutgeschrieben. Das führt zu falschen Analysen. Denn natürlich wird man als Erstes untersuchen, warum die .nl jetzt auf die .com/de-en/ weiterleitet. Und dort das Problem an der falschen Stelle suchen
-
Die Kollegen aus den Niederlande haben im Reporting ein deutliches Plus. Ein klassischer Reportingfehler
-
User aus Deutschland werden jetzt grundsätzlich zu englisch-sprachigen Seite weitergeleitet. Dadurch sinken Conversions
-
Im Zuge der Umstellung wurden 1:1 Redirects durch die Catch-All-Redirect Regel ersetzt. Viele ehemals gültige Redirects führen jetzt auf die Startseite
Wisst Ihr, warum kleine Fehler mit großer Wirkung immer an einem Freitag Nachmittag live gestellt werden?
|
|
|
Mit einfachem Mittel den LCP auf 1/7 Reduzieren!? SEOs lieben diesen Trick!
|
|
Du hast bestimmt auch schon Mal einen Werbeslogan gelesen, der so ähnlich klingt. Häufig steckt hinter diesen Schlagzeilen aber auch nicht mehr und sie werden zurecht komplett ignoriert. Im Gegensatz dazu wurde auf das heutige Thema,
content-visibility
, bei uns geradezu mit Aufmerksamkeit überschüttet und ausführlich diskutiert.
Dabei handelt es sich um eine CSS-Property, die eigentlich schon seit der Mitte letzten Jahres im Spiel ist. Mit ihr lässt sich das Rendering für ein HTML-Element und alle seine Kinder steuern. Setzt man nun im CSS für eine ID oder Klasse die CSS-Property content-visibility: auto hat man quasi Lazy Rendering für dieses DOM-Element. Für Elemente die sich nicht im initialen Viewport befinden wird noch die größe des Elements bestimmt, aber sonst nichts. Das ganze lässt sich natürlich wie alle anderen CSS-Properties noch mit Media Queries verbinden um diesen Effekt für verschiedene Displaygrößen und Gerätetypen unterschiedlich steuern zu können.
Layout, Styling und Painting werden erst dann ausgeführt, wenn der Viewport sich besagtem Element nähert. Im WebDev-Beispiel wird im Beispiel angepriesen, durch die Auszeichnung einiger Content-Blöcke mit content-visibility: auto die Rendering Dauer auf ein Siebtel des ursprünglichen Wertes reduziert zu haben. Da sind wir direkt hellhörig geworden, wobei dort natürlich gleich einige große Bilder dabei waren.
In unserem eigenen Test auf der Dir hoffentlich sehr gut vertrauten Newsletter-Seite konnten wir zwar nicht ganz so herausragende, aber trotzdem ansehnliche Ergebnisse erzielen (in der Simulation mit Chrome DevTools Local Overrides. Der Test mit Felddaten wartet noch darauf, dass CSS-König Justus wieder aus seinem Urlaub in den Palast zurückkehrt).
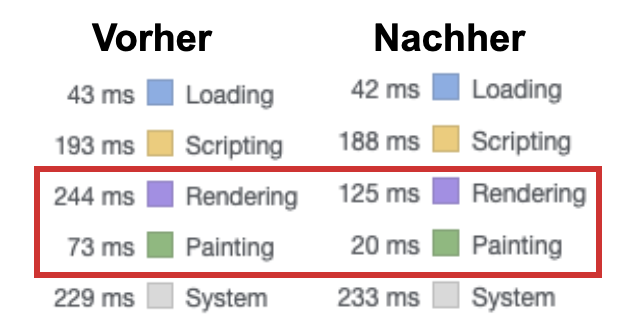
Durch das Auszeichnen der Anmelde-Box und des Archivs konnten die Rendering-Zeit immerhin halbiert und die Painting auf etwas weniger als ein Drittel reduziert werden. Zusammen ist eine Ersparnis von 172MS bei einer vorherigen Gesamtladezeit von 852MS, macht ~20%. Für eine Änderung, die man quasi per Copy and Paste in die gewünschten Elemente einpflegen kann gar nicht mal so übel.
Insbesondere vor dem Hintergrund von etlichen Websites, die auch heute noch gänzlich ohne Deferring oder mit veralteten JavaScript-Lösungen unterwegs sind, eine echte Goldgrube. Neben Rendering und Painting könnte eine Implementierung hier auch noch Scripting Zeit sparen.
Wie immer gilt: content-visibility: auto ist kein Allheilmittel. Aber auch kein Schlangenöl vom zwielichtigen fahrenden Händler. Ein Haken an der Sache:
Von Firefox und Safari wir dieses Feature aktuell noch nicht unterstützt
. Wenn Deine Seite aber am LCP krankt hilft es Chrome-Nutzern (und damit den Core Web Vital Felddaten) und Googlebot schon heute, und ist daher definitiv einen Test wert.
Codebeispiel:
.footer {\
...
content-visibility: auto\
...\
}
|
|
|
Was passiert im Suchmaschinenmarkt?
|
|
Mit
Nona.de
gibt es jetzt schon wieder eine neue Suchmaschine. Und so langsam hab ich den Überblick verloren. Zeit also sich wieder einen Überblick zu verschaffen, was sich neben der Dominanz Googles so tut, denn das war in den letzten Monaten Einiges.
Fangen wir an mit den alten Hasen:
Regionale Player
Da sind zum Einen die regionalen Spezialisten: Baidu (China), Yandex (Russland), Naver (Südkorea) und Seznam (Tschechien). Manchmal gibt es auch noch andere kleinere regionale Player, aber von Dominanz sind die Meisten weit entfernt.
Kindersuchmaschinen
Meist ebenfalls regionale Schwerpunkte haben die Suchmaschinen für Kinder. In Deutschland fallen mir da vor allem Blinde-kuh.de und FragFinn.de ein. Similarweb findet für beide
100.000 Visits je Monat
. Real dürften die Zahlen deutlich darüber liegen, wenn wir berücksichtigen, dass Kinder besonders häufig mobile unterwegs sind und Similarweb mobile Reichweite traditionell unterschätzt.
Runner-Ups
Natürlich: Wenn Du an eine andere Suchmaschine denkst, dann fällt Dir als erstes
https://www.bing.com
ein.\
Aber es gibt auch andere:
-
Metager ist als Meta-Suchmaschine
, die sich aus verschiedenen Indizes bedient, nicht totzukriegen.
-
🦆 DuckDuckGo
wird von Statcounter aktuell bei 1% für Deutschland gesehen
. Dabei kuratiert DuckDuckGo die Suchergebnisse von bing, aus einem eigenen Crawler und 400 weiteren Quellen, DuckDuckGo gilt als Vorreiter für Privacy Settings. 🔒
-
🌳 Ecosia kennst Du als die Suchmaschine,
die bei Suchen etwas für den Umweltschutz tut
. Im Gegensatz zu DuckDuckGo hat Ecosia keinen eigenen Crawler, sondern passt die Suchergebnisse von Bing an.
-
🧪 Bei Wolfram Alpha hab ich ein wenig überlegt, ob ich sie in diese Liste aufnehmen sollte. Wolfram Alpha möchte nicht jede Frage beantworten, aber einige Fragen sehr gut. Wenn Du nicht nach einem Pizza-Rezept suchst, sondern irgendwas in sprachlicher oder (natur-)wissenschaftlicher Richtung, dann ist die Wahrscheinlichkeit groß, dass
https://www.wolframalpha.com/
eine Lösung für Dich hat.
-
qwant ist vergleichbar mit DuckDuckGo. Setzt auch auf Privacy 🔒. Hat einen eigenen Bot, der Großteil der Ergebnisse wird aber von Bing und anderen geholt. Ein Unterschied: qwant kommt aus Frankreich.
-
Ebenfalls aus Frankreich, aber auf Basis eines eigenen Indexes arbeitet
Exalead
schon seit fast 20 Jahren.
-
Startpage setzt wie DuckDuckGo auf den Datenschutz als Markteinstieg 🔒. Aber: Im Hintergrund zieht sich startpage die Google Ergebnisse 🤖. Eigentlich handelt es sich nur um einen Privacy-Layer über Google, aber nicht um eine eigene Suchmaschine
New Kids on the block
Zu diesem reichlichen Zoo gesellen sich einige Neulinge:
Gibt es clevere Deutsche Entwicklungen?
Deutschland ist ja nicht immer clewwa was Suchmaschineninnovationen angeht. (clewwa ist eine Suchmaschine des Bundes gewesen.
Als ich noch jung war hab ich mal nach den Kosten gefragt
. >70k€ Erstellung (20k€ Betrieb pro Jahr) für <200 Suchen am Tag)
Dennoch tut sich was:
-
xayn.com
hat 10 Mio. eingesammelt und positioniert sich als hyperpersonalisierte Suchmaschine (KI) mit Datenschutz (natürlich) 🔒. Nachdem
die App 250.000 Mal installiert
wurde, gibt es jetzt die
Suche auch im Browser
. Dabei verzichtet xayn auf einen eigenen Crawler und
kuratiert verschiedene Indizes
.
-
Nona.de
verfolgt den gleichen Weg wie Neeva (teilweise mit den gleichen Werbeaussagen). Auch Nona verspricht Dir keine Werbung für 2€ im Monat in Deinen Suchergebnissen aus verschiedenen Quellen 💸.
Und natürlich die Bundesregierung:
Die neue Ressortübergreifende Suche (mit KI!)
liefert tatsächlich interessante Ergebnisse für "Pizza-Rezepte". An der Erfüllung des Search Intents müssen wir aber noch mal arbeiten.
Und sonst?
-
Besondere Freude
bereitet mir wiby. Die
Suchmaschine für das "Old Web"
-
searx ist eine Open Source Metasuchmaschine. Hier kannst Du also Deine eigene Suchmaschine hosten und
die Datenquellen konfigurieren
.
Ein paar öffentlich verfügbare Instanzen
geben Dir einen Einblick in die Möglichkeiten und unterschiedlichen Resultate
Und jetzt? Ist ein Google-Killer dabei?
Nein. Einen Google-Killer sehe ich nicht. Viele begnügen sich damit, ein anderes Frontend und eine kleine Umsortierung der Ergebnisse von Bing vorzunehmen. Das wird nicht reichen, um einen Google-Killer zu bauen. Denn ohne eigenen Index sind die Möglichkeiten endlich und die Abhängigkeiten von Deinem Indexlieferanten zu stark.
Das bedeutet nicht, dass sich nicht was entwickelt. Brave-Search hat es ja erkannt, dass ein eigener Index wichtig ist und nutzen den Input anderer Maschinen als Sprungchance.
Ich glaube die Neulinge tun sich keinen großen Gefallen Privacy als Haupt-Anker für das Marketing und Wachstum zu nehmen. Den Platz hat duckduckgo schon besetzt und letztlich möchte ich nicht möglichst private Ergebnisse, sondern in erster Linie gute Ergebnisse.
Vielleicht tut sich
da ja aber was mit Buzzword-Bingo KI, NLP und Machine Learning
?
Aktuell sind die Ergebnisse underwhelming
Ich habe in allen angesprochenen Suchmaschinen nach „Wann ist die Bundestagswahl" gesucht. Und ich bin ein wenig enttäuscht:
Meine Bewertung von Suchergebnissen zu „Wann ist die Bundestagswahl?"

Die
Langfassung der Ergebnisse
zeigt sehr gut die Abhängigkeit der meisten Suchmaschinen von Bing. Natürlich hätte man auch einen englischen Query nehmen sollen, aber wir wollen es ja auch nicht zu einfach machen.
|
|
|
Campixx-Review: Kannibalismus im SEO - Interne Konkurrenz ermitteln und vermeiden? (Michael Brumm)
|
|
Schon die Definition von Keyword-Kannibalismus ist nicht ganz einfach, aber Michael hat eine schöne Variante formuliert: „Ein Keyword für das mehrere URLs ranken, die die gleiche Suchintention bedienen". Die gefällt mir, denn oft ist es bei Doppel-Rankings in Top-Positionen so, dass beide URLs unterschiedliche Facetten bedienen, während das Bedienen gleicher Facetten zu Problemen führt:
-
Crawling: Google muss beide Inhalte crawlen
-
Indexing: Unter Umständen fasst Google beide URLs im Collapsing zusammen
-
Linkprofil: interne und externe Links, sowie Ankertexte werden auf konkurrierende Seiten verteilt anstatt gebündelt
Wie kannst Du interne Konkurrenz erkennen?
Michael empfiehlt:
-
"Site:"-Abfrage in Kombination mit "inurl:" und "intitle:" (
mehr Operatoren
)
-
Ryte-Bericht in Search Success
-
Sistrix URL-Changes Report
-
Sistrix Kannibalisierungs-Report
Aus dem Kannibalisierungs-Report von Sistrix in Kombination mit Search Console Daten, Adplaner Suchvolumina und einem (groben) Clustering der URLs nach Intent (Magazin=Informational, Produktseite=Transaktional) hat Michael eine Übersicht gebaut, die schnell URLs erkennen lässt, die in Konkurrenz zueinander stehen.
Wichtig: Stehst Du trotz Konkurrenz auf Position 1-5 mit beiden URLs, dann ist es ratsam die URLs nicht anzufassen. Aber:
Was kannst Du tun, wenn es Konkurrenz gibt?
-
Suchintention/Keyword ausdifferenzieren
-
Inhalte zusammenfassen
-
Löschen/Redirect einrichten
-
(interne) Links anpassen und die Beantwortung der Intention in den Ankertext integrieren
-
Oberkategorien schaffen
-
Noindex setzen für veraltete Seiten wenn keine Zusammenfassung oder Löschung möglich/gewollt ist
Ähnlich haben wir das mal
in unserem Artikel zu Content-Löschung thematisiert
.
Im Anschluss haben wir nochmal Möglichkeiten diskutiert, die man wahrnehmen könnte, falls Excel bei den Datenmengen nicht mitmachen möchte:
-
Schneller und aggressiver die Rohdaten filtern
-
PowerBI
-
Knime
-
Python Pandas oder R
Vorteil vor allem der letzten beiden Lösungen: Die Schritte werden leicht nachvollziehbar und reproduzierbar.
|
|
|
Termine, Termine, Termine
|
|
Zum Abschluss noch ein kleiner Reminder an das
SEO Meetup Hamburg
: Heute Abend um 19:00 Uhr dreht sich alles um Content Marketing im B2B. Achtung: Diese Session wird nicht aufgezeichnet!
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an
[email protected]
oder
ruf uns einfach kurz an:
+49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|


