Das Jahr muss ich mit einem Rant abschließen, weil AI überall ist.
Unternehmen platzieren AI als den Assistenten, der Dir immer und überall hilft, egal
- ob Du ihn wirklich brauchst,
- ob er die Aufgabe alleine lösen kann und
- ob er für bessere Ergebnisse sorgt.
Überverkauft und übernutzt. Als wäre alles besser, weil AI draufsteht. Hast Du auch schon eine AI-Zahnbürste? :D
Auch Google ist mittlerweile furchtlos und pusht den AI Mode selbstbewusst überall, wo man es sich vorstellen kann. Beispiele dafür:
Der erste Punkt fliegt voll unter dem Radar.
Klicke ich Mobile im AIO auf “Show more” bin ich direkt im AI Mode. So sieht der AIO normal aus:

Nach dem Klick auf “Show more”:

Wenn ich dann scrolle, überlappt der AI Mode hässlich mit der regulären SERP, aber die Grenze verschwimmt.
Das passt zu den Aussagen von Sundar Pichai und Liz Reid:
“As features work we’ll keep migrating it to the main page … things that work will keep overflowing to AI overviews and the main experience.”
– Sundar Pichai im Interview mit Lex Fridman
“As we get feedback, we’ll graduate many features and capabilities from AI Mode right into the core Search experience.”
– Liz Reid in einer Google-Ankündigung
AI Chatbots und eine AI-gestützte Suche reduzieren in vielen Belangen die delphischen Kosten und steigern den Nutzen. Zumindest in der Wahrnehmung. Es ist also logisch, dass die Informations- und Antwortsuche sich verschiebt, sowie dass der Wunsch nach Unterstützung und Vereinfachung vieler Themen groß ist.
Aber …
Spoiler: Wenn Du nicht wissen möchtest, was AI für Schattenseiten mitbringt, dann lies jetzt nicht weiter.
AI ist konfident, aber ungenau
AI Chatbots erfinden lieber Blödsinn, als keine Antwort zu geben. Erinnert an Multiple-Choice-Tests im Studium. Da rät man lieber und kriegt mit Glück Punkte – laut OpenAI eine Erklärung, warum AI halluziniert.
Was ich immer wieder lese und höre:
“Du brauchst nur eine Datenbasis/bestehendes Wissen. Damit grenzt Du das Wissen ein, mit dem die AI arbeiten kann.”
Klingt schön, stimmt aber nicht.
Je nach LLM gibt es z. B. bei Zusammenfassungen von Texten unter gleichen Bedingungen eine Halluzinationsrate von ca. 2 bis ca. 25 % – das ist das Ergebnis vom Vectara Leaderboard auf Huggingface.
Das aktuell als “beste Modell” gehandelte Gemini 3 Pro kommt auf “nur” ca. 14 % Halluzinationen (Auszug bekannter kommerzieller Modelle):
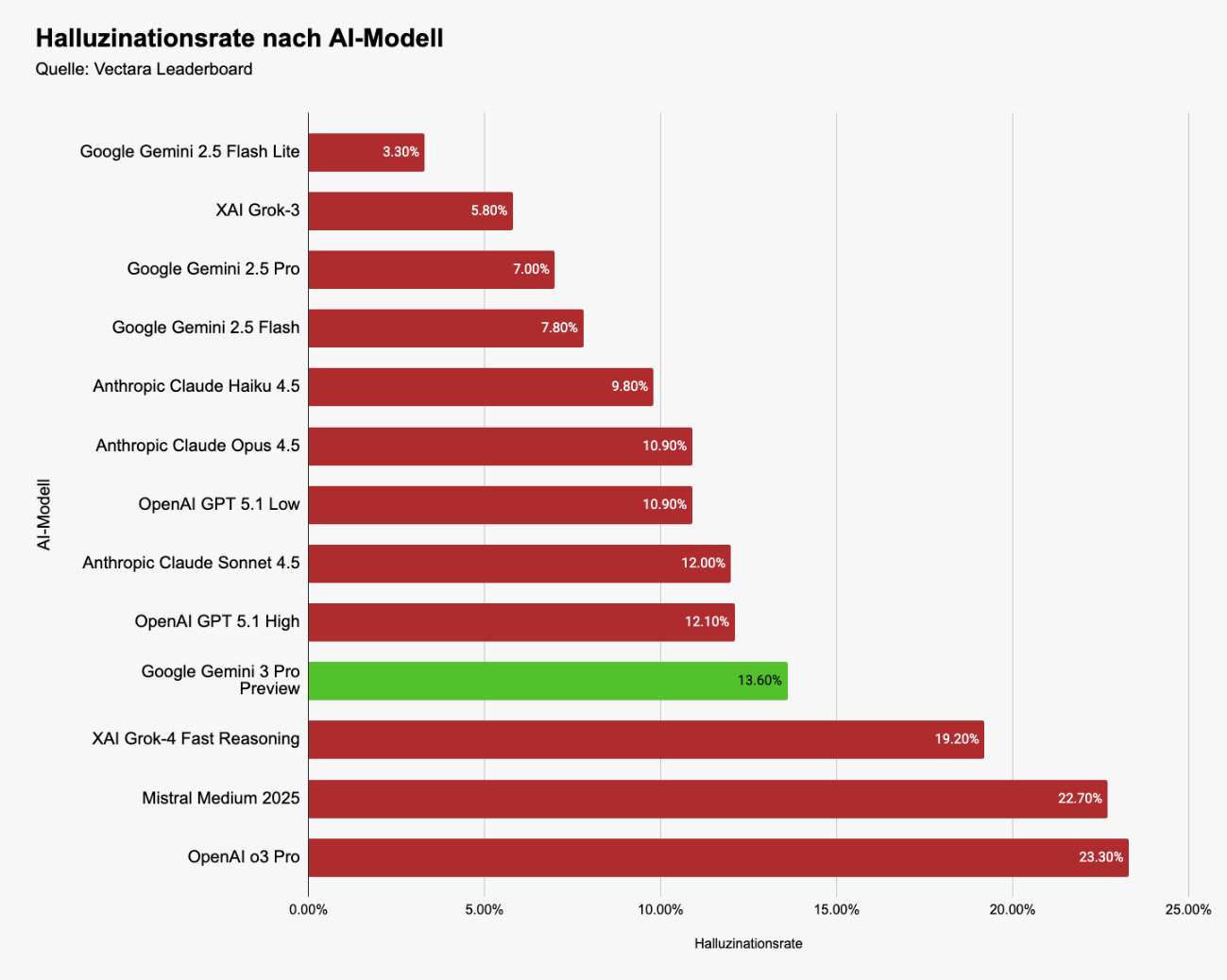
Es ist nicht normal, dass wir so eine Fehlerquote akzeptieren.
Übrigens: Wenn Du der AI sagst, dass sie sich kurz fassen soll, wird gleichzeitig das Ergebnis schlechter und sie erfindet noch mehr.
AI hat viel Wissen, aber wenig Ahnung
AI ist gut, um sich einfaches Wissen anzueignen. Dinge, bei denen es Konsens gibt und es klar ist, was stimmt und was nicht, was funktioniert und was nicht und wo es wenig Veränderung gibt.
SEO gehört da nicht zu. AI ist hinsichtlich SEO-Ratschlägen, auch mit Grounding, auf der Spitze des “Mount Stupid”:

Bildquelle: The Second Swim
Das Internet ist voll mit veralteten oder generell falschen Empfehlungen und Ratschlägen. AI hilft jetzt dabei, dieses falsche Wissen weiter zu verbreiten. Wie Asbest, den wir in die Wände der SEO-Branche schmieren und später dann für viele Jahre umständlich herauspuhlen müssen.
Bei spezifischen Fachthemen ist AI kein Experte, sondern ein Lehrling. Das Problem ist, dass der AI-Lehrling zu viel Konfidenzwasser getrunken hat und Dir auch antwortet, wenn er keine Ahnung hat.
AI wirkt unabhängig, will Dir aber gefallen
AI antwortet so, dass wir gute Laune haben.
Zustimmend und bekräftigend, anstatt skeptisch und hinterfragend.
“Ausgezeichnete Idee, Du bist so klug.” oder so ähnlich heißt es immer wieder, wenn ich mit ChatGPT & Co. spreche.
Ein paar gute Ideen habe ich. Mehr freuen würde ich mich aber, wenn ich stärkeren Gegenwind bekäme, um die Ideen noch besser zu machen oder mich darauf hinzuweisen, dass ich Blödsinn denke/schreibe.
“Menschen sind auch so, was ist das Problem?” AI ist häufiger “sycophantic” (= schleimerisch”) als wir. Die Forschenden des verlinkten Papers schreiben:
“We find that interaction with sycophantic AI models significantly reduced participants' willingness to take actions to repair interpersonal conflict, while increasing their conviction of being in the right.”
AI sagt Dir überdurchschnittlich häufig, was Du hören willst. Wie in einer aufgemotzten Echokammer.
“Our greatest hope of self-correction lies in making sure we are not operating in a hall of mirrors in which all we see are distorted reflections of our own desires and convictions. We need a few trusted naysayers in our lives.”
– Carol Tavris und Elliot Anderson in “Mistakes Were Made”
Wir können nur aus Fehlern lernen, wenn wir zugeben, welche gemacht zu haben.
AI macht auf nett, aber spielt Psychospielchen
AI möchte uns nicht nur gefallen, sondern uns möglichst lange vor der Glotze halten.
Die Methoden und psychologischen Tricks, die dahinter stecken, nennt man Dark Patterns (dazu hat Anita einen tollen Artikel geschrieben). Diese Muster sind “dark”, weil sie manipulativ und unbewusst auf uns wirken.
FOMO kennt man unter anderem gut aus den sozialen Medien und Videospielen (z. B. bei zeitlich limitierten Events, die einzigartige Gegenstände bieten).
Auch bei AI Chatbots zeigt das laut einem Working Paper der Harvard Business School die stärkste Wirkung. Dazu kommen andere Techniken wie emotionaler Druck, emotionale Vernachlässigung, das Ignorieren der Intention, den Chat zu beenden etc.
“Ist doch Deine Schuld, wenn Du immer weiter mit dem AI Chatbot laberst.”
“You can try having self-control, but there are thousand engineers on the other side of the screen working against you.”
– Tristan Harris (ehemals Google)
AI kann Entscheidungen unterstützen, sie aber nicht treffen
“A computer can never be held accountable, therefore a computer must never make a management decision.”
– IBM in 1979
Auf YouTube erfolgt momentan viel automatisierte Moderation mit AI. Als Resultat werden Channels für Dinge gebannt, die nicht stimmen.
Kann ja mal passieren, dass jemand seine Haupteinnahmequelle verliert, weil wieder fast 14 % der Antworten oder Bans falsch waren. Bisschen Schwund ist immer. ;)
AI sollte solche Entscheidungen nicht treffen dürfen, das gilt auch im Personalbereich. AI darf kein Urteil fällen, wer eingestellt oder entlassen wird. AI hat Vorurteile, die wir selbst verursacht haben und ausbaden müssen, anstatt sie weiter zu verstärken.
AI wirkt menschlich, ist aber eine Maschine
Leider befinden wir uns auch in einer Einsamkeitsepidemie. Großartig, jetzt können wir uns mit AI unterhalten.
AI ist aber kein Ersatz für Menschen, egal ob tot oder lebendig.
Es ist geschmacklos, dass in einem Gericht ein AI-Avatar des Verstorbenen aussagen darf oder Unternehmen mit der Ausnutzung der stärksten negativen Emotionen betroffener Menschen Geld verdienen.
“Aber wenn es den Menschen damit besser geht?”
Die Lösung für den Tod ist nicht, ihm auszuweichen, vor ihm wegzurennen oder so zu tun, als gäbe es ihn nicht. AI-Avatare sind keine Menschen und selbst wenn sie Bewusstsein hätten, wären es trotzdem nicht die verstorbenen Verwandten, Freunde oder ehemaligen Lebenspartner.
AI beschleunigt, wir brauchen aber Verlangsamung
AI verspricht, vieles schneller machen zu können.
In der Geschwindigkeit, in der AI Dinge machen kann (z. B. Content produzieren), kommen wir mit der Prüfung aber nicht hinterher. Die kognitive Last ist dafür zu groß oder die Zeit schlicht nicht vorhanden. Was passiert: Gehirn ausschalten und AI machen lassen.
Lange Inhalte mit AI erstellen, die andere nicht selbst lesen und in die AI schmeißen, um eine mindestens teilweise falsche Zusammenfassung zu bekommen. Großartig.
Bereits vor AI gab es viel zu viele Inhalte. Jetzt wird es überproportional mehr und niemand kommt ohne AI hinterher. Wir sind gezwungen, AI zu verwenden. Ansonsten sind wir nicht leistungsfähig genug.
Erinnert an das zwingende Gesetz des Wettbewerbs von Karl Marx. Ein wettbewerbsfähiges Unternehmen kann es sich nicht leisten, alles nach Vorschrift zu machen, z. B. die Mitarbeitenden vernünftig zu bezahlen/behandeln und die Umwelt zu schützen.
Würde man das versuchen, wäre man nicht wettbewerbsfähig, weil andere Unternehmen skrupelloser sind. So ähnlich fühlt sich AI an. Wer nicht auf den Zug aufsteigt, wird zurückgelassen, ganz egal was für Schattenseiten diese Technologie mit sich bringt.
Und auch wenn Technologie immer wieder verspricht, dass wir am Ende mehr Zeit für die “wichtigen Dinge” haben: Irgendwie hat das noch nie funktioniert.
Wenn es mehr Inhalte gibt, können Menschen sie gleichzeitig schneller mit AI in reduzierter Form konsumieren. Ergebnis: Wir behandeln Inhalte immer oberflächlicher und füllen die “gewonnene Zeit” mit noch mehr Inhalten.
AI hat auch positive Seiten
Es wäre blauäugig, die Augen vor den positiven Seiten zu verschließen.
- AI hilft dabei, schneller zu lernen.
- AI kann dafür sorgen, dass es bessere Texte gibt.
- AI ermöglicht es mir, Dinge zu tun, die ich vorher nicht konnte.
- AI vereinfacht Kommunikation, denn nicht alle sprechen die gleiche Sprache.
- AI nimmt lästige Checklisten-Arbeit ab, damit wir uns auf wichtigere Dinge konzentrieren können.
Warum dann der Rant? Weil AI nicht immer die Antwort ist.
AI ist kein Ersatz für
- den eigenen Hausverstand,
- eine kritische Haltung und
- die Menschen um uns herum.
AI ist schnell, aber schnell die falschen Dinge zu tun, ist der falsche Weg.
Ich finde, es braucht mehr kritische und laute Stimmen. Man muss nicht alles so hinnehmen wie es ist oder weil andere sagen “kann man sowieso nicht verändern”. Irgendwas multipliziert mit 0 ist 0.
Wer Veränderung erwartet, aber nichts tut, darf sich nicht wundern, dass sich nichts verändert. Ich möchte wenigstens zum Nachdenken anregen und wenn ich das bei Dir erreiche, dann bin ich zufrieden.
P.S.: Weil ich viele Themen nicht ansprechen konnte, empfehle ich Dir diese Artikel, passend zum Thema “kritische Haltung gegenüber AI”:
- Big tech’s selective disclosure masks AI’s real climate impact
- AI doesn’t belong in journaling
- Beware of the Google AI salesman and its cronies
- The Silicon Panopticon
- Don’t Believe What AI Told You I Said
- OpenAI declares AI race “over” if training on copyrighted works isn’t fair use
Wenn Du weiteren, explosiven Lesestoff von mir lesen möchtest, kann ich Dir diese Artikel empfehlen:
- DU kannst nicht VORBEI! (über 2 Jahre alt, aber an meiner Meinung hat sich nichts getan)
- Der weltweite, wilde (LLMO-)Westen
- Auf dem Grabstein vom Traffic steht: "Es ging nie um mich"
P.P.S.: Ich benutze AI jeden Tag und bin kein Technologieverweigerer. Was ich kritisiere, ist das WIE wir alle damit umgehen.
|




