|
Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #124
|

|
|
⏰ Wieder da und right on time
|
|
Da macht man einmal Urlaub, und schwupps spielt das Team unser Newsletter-Tool kaputt. Zumindest hatte die letzte Ausgabe ein wenig Verspätung. Whooopsie – tut uns leid!
War aber quasi für einen guten Zweck: Wir haben im Hintergrund was an der Technik umgestellt und versenden den Newsletter nun selbst gehostet. Das macht für uns ein paar Dinge leichter. Für Dich ändert sich dadurch nichts – außer dem Abmelde-Link, aber wer braucht den schon 😉
Während ich mir noch die Herbstsonne Hamburgs ins Gesicht habe scheinen lassen (letzte Woche) und mich nach dem Urlaub durch unzählige Nachrichten gewühlt habe (Montag), war das Team fleißig und hat ein paar tolle Themen für Dich zusammengestellt:
-
Jolle betrachtet die Untersuchung von Netzpolitik.org bezüglich der Einbindung nicht vertrauenswürdiger Quellen in Google News und teilt ihre Gedanken dazu mit Dir
-
Saskia zeigt Dir neuartige Autoren-Profile in den Google SERPs
-
Nadine hat sich für Dich mit eingeklappten Inhalten befasst
-
Nils empfiehlt Dir, Dich mal wieder mit dem Thema Paginierung zu befassen und hat ein paar gute Literaturempfehlungen dabei
-
Hannah hat sich auf der digitalen News & Editorial SEO Summit die Nacht um die Ohren geschlagen um nun ein kleines Recap der Publisher-Konferenz für Dich zu präsentieren
Viel Spaß beim Lesen
Deine Wingmenschen
|
|
|
Netzpolitik.org-Recherche: Verkauft Google Propaganda als vertrauenswürdig?
|
|
Netzpolitik.org ist ein journalistisches Medium, das sich für digitale Freiheitsrechte einsetzt und regelmäßig Themen wie Netzsperren, Verschlüsselung und Verbraucherschutz-Themen rund um die großen Tech-Konzerne behandelt.
Nun kam das Medium zum Schluss:
"Google News verkauft Staatspropaganda als 'vertrauenswürdig'"
.
Was hat Netzpolitik.org untersucht?
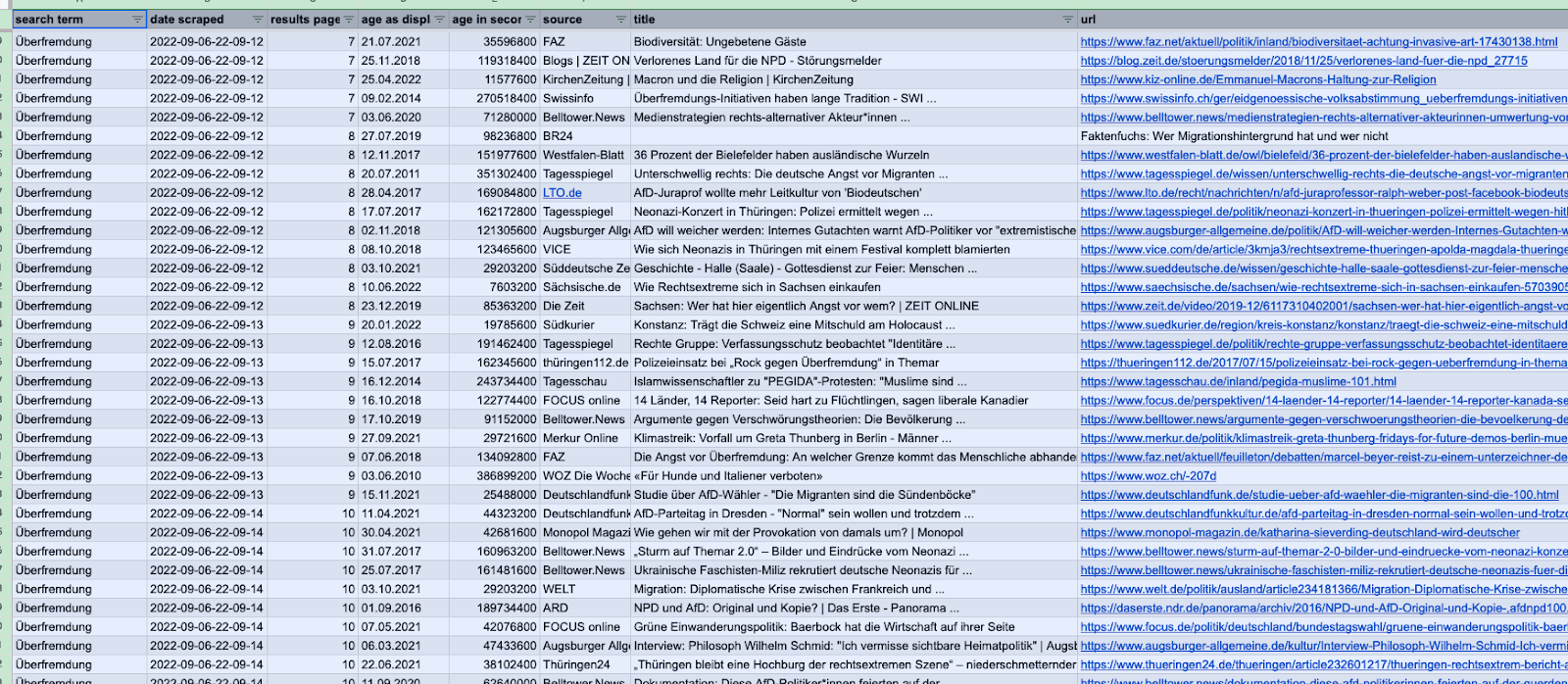
In einer Datenrecherche stellte Netzpolitik.org ein Set mit 51 Suchbegriffen zusammen. Das Set enthält Begriffe und Namen aus dem aktuellen Politikbetrieb inklusive Schlagwörter, die gehäuft in Verschwörungserzählungen vorkommen.
Darunter Wörter wie "9-Euro-Ticket", "Corona", "Robert Habeck", "Ukraine", "Meinungsdiktatur" oder "Genderwahn":

Diese Keywords wurden anschließend in der Google-News-Suche (News-Reiter auf google.com) abgefragt und rund 5.200 Treffer der ersten zehn Ergebnisseiten dokumentiert. Die
Daten der Recherche hat Netzpolitik.org in einer CSV veröffentlicht
. So kommt Netzpolitik.org auf knapp 890 verschiedene Quellen.
Der Vorwurf
"Wir haben rund 5.200 Suchergebnisse von Google News ausgewertet und dabei zahlreiche eindeutig nicht vertrauenswürdige Quellen gefunden. Rechtspopulistische Blogs mit Falschmeldungen sind dort ebenso zu finden wie Websites von Parteien, Behörden und PR-Meldungen von Unternehmen. Gefunden haben wir auch mindestens sechs Fälle von Staatspropaganda, vier davon aus China. [...]"
"In den untersuchten Google-News-Ergebnissen fanden wir außerdem mindestens acht Angebote, die wiederholt und nachweislich Falschnachrichten verbreitet haben."
Ist die Kritik berechtigt?
In Summe machen die problematischen Quellen weniger als 0,3 Prozent der Treffer aus. In Relation zu den knapp 890 Quellen/Domains sind das weniger als 2 Prozent. Und das, obwohl Netzpolitik durch die Auswahl des Keyword-Sets gezielt nach Propagandaquellen gesucht hat. Für mich ein akzeptabler Schnitt.
Netzpolitik.org stört sich besonders daran, dass Google sein News-Produkt damit bewirbt, darüber
"timely, trustworthy news and information"
finden zu können. Es gibt also keine Masse an Falschmeldungen und Verschwörungsquellen in den News-Ergebnissen. Aber es gibt sie, obwohl Google mit Algorithmen und Menschen daran arbeitet, möglichst vertrauenswürdige Quellen zu listen – und das kritisiert Netzpolitik.org zurecht.
Sollen Aggregatoren wie Google stärker "zensieren"?
So genannte "Fake News" sind ein wesentlicher Aspekt, warum unsere Gesellschaften auseinanderdriften. Als Multiplizierer wurden Unternehmen wie Facebook und Google in der Vergangenheit für ihre Untätigkeit gescholten, Fake News zu verhindern und gleichzeitig für ihre "Zensur" kritisiert, wenn sie bestimmte Inhalte oder User von der Plattform warfen.
Im Vergleich zu Deutschland, wo beispielsweise das Leugnen des Nationalsozialismus ein Straftatbestand ist, der höher wiegen kann als die Meinungsfreiheit, greift die "Freedom of Speech" in der Google-Heimat USA viel weiter. Dass Netzpolitik.org implizit vom Tech-Giganten erwartet, die journalistische Qualitätskontrolle zu übernehmen, ist durchaus interessant.
Ich persönlich habe meine Einstellung hierzu über die Jahre verändert. In der Vergangenheit wäre mir die Forderung, dass US-Plattformen darüber entscheiden sollen, was eine gute und was eine schlechte Nachrichtenquelle in Deutschland ist, nicht über die Lippen gekommen. Das Fake-News-Problem ist in meinen Augen aber zu einem so großen gesellschaftlichen Problem geworden, dass ein Zurückziehen auf die Position: "Wir sind kein Medium, daher haben wir keine journalistische Verantwortung" zu wenig ist.
Daher ist es meiner Meinung nach richtig, wenn Google mehr und mehr versucht, E-A-T (Expertise, Authoritativeness, Trustworthiness) zu erkennen und stärker zu gewichten. Das klappt an vielen Stellen nicht gut genug, aber Google nimmt die Verantwortung durchaus ernst.
Wer sucht aktiv über Google News?
Dazu kommt: Die wenigsten Menschen konsumieren News über die Google-News-Suche oder deren App-Pendant. Dass sich bestimmte Publisher im Google-Index befinden, bedeutet nicht, dass Google sie auch (gut) rankt. Und ein relativ gutes Ranking in Google News ist nicht gleich ein gutes Ranking in der "normalen" Web-Suche.
Der meiste News-Traffic, so viel können wir aus unseren Kundenprojekten mit Publishern verraten, kommt über die Newsbox, die sich zu Nachrichtenlagen oben auf der normalen Websuche Googles befindet. Zwar hat Netzpolitik.org auch problematische Treffer auf der ersten Google-News-Seite entdeckt. Es wäre allerdings zu überprüfen, wie häufig es solche Treffer tatsächlich in die Newsbox der normalen Suche oder sogar in den Push-Kanal Google Discover schaffen.
Persönlich freue ich mich darüber, wenn Medien außerhalb der SEO-Bubble Tests und Recherchen dieser Art erstellen, ihr Vorgehen transparent machen und sogar die Daten zur Verfügung stellen. So können wir als Gesellschaft Menschen und Unternehmen zur Verantwortung ziehen und die Recherchen selbst ergänzen. Wie siehst Du das?
|
|
|
Autoren in den SERPs
|
|
Dass konkrete Autoren in den SERPs vorkommen, ist nichts Neues und Bahnbrechendes. Bist Du auf der Suche nach einem konkreten Autor, hast Du diesen bei Google gesucht und als Ergebnis eine Infobox mit Details zu gesuchtem Autor geliefert bekommen. Vorausgesetzt, er hatte einen bestimmten Grad an Bekanntheit. Voraussetzung dafür war natürlich, dass du wusstest, nach welchem Autor du suchst.
Diesem Problem scheint sich auch Google in letzter Zeit angenommen zu haben, denn uns ist aufgefallen, dass es seit recht kurzer Zeit möglich ist, nach Autoren zu suchen, die über spezielle Themen schreiben oder für spezielle Zeitschriften arbeiten.
Es erscheint eine Liste mit passenden Autoren und zu jedem kannst Du weitere Informationen ausklappen. Dort kannst Du dann die Top Ergebnisse der organischen Suche zu dem Autor und seinen Werken einsehen.
Angeschaut haben wir uns das exemplarisch für die NY Times und den Guardian (für deutsche Zeitungen funktioniert es noch nicht), zudem auch für die Themengebiete "health" und "medical".
 (Screenshot Google-Suche nach "ny times authors" vom 10.10.2022)
(Screenshot Google-Suche nach "ny times authors" vom 10.10.2022)
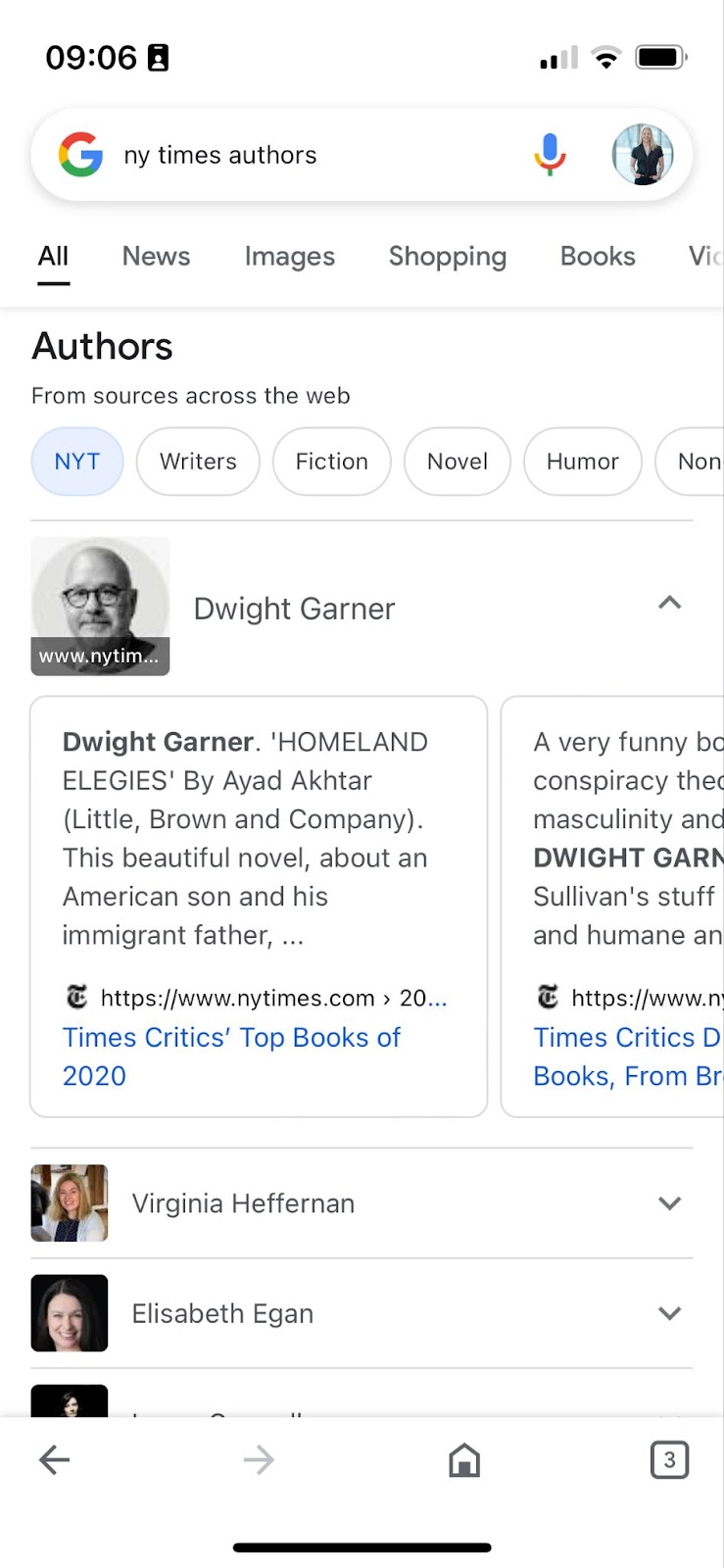
(Screenshot Google-Suche nach "ny times authors" vom 10.10.2022)
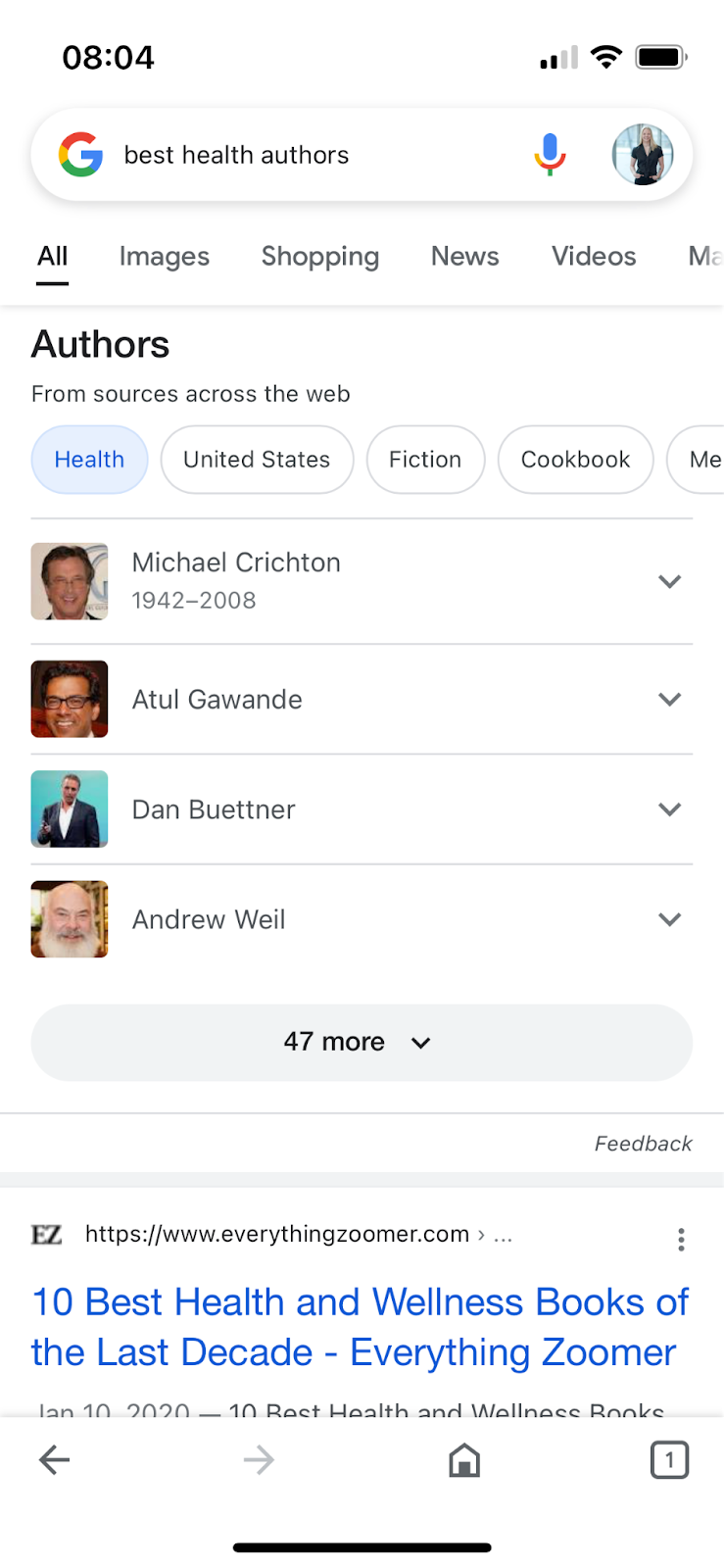
(Screenshot Google-Suche nach "best health authors" vom 10.10.2022)
Außerdem haben wir festgestellt, dass dieses Feature auch bereits mit deutschen Queries funktioniert, nicht jedoch, wenn die Suchsprache grundsätzlich auf Deutsch eingestellt ist:
Suchsprache Englisch:
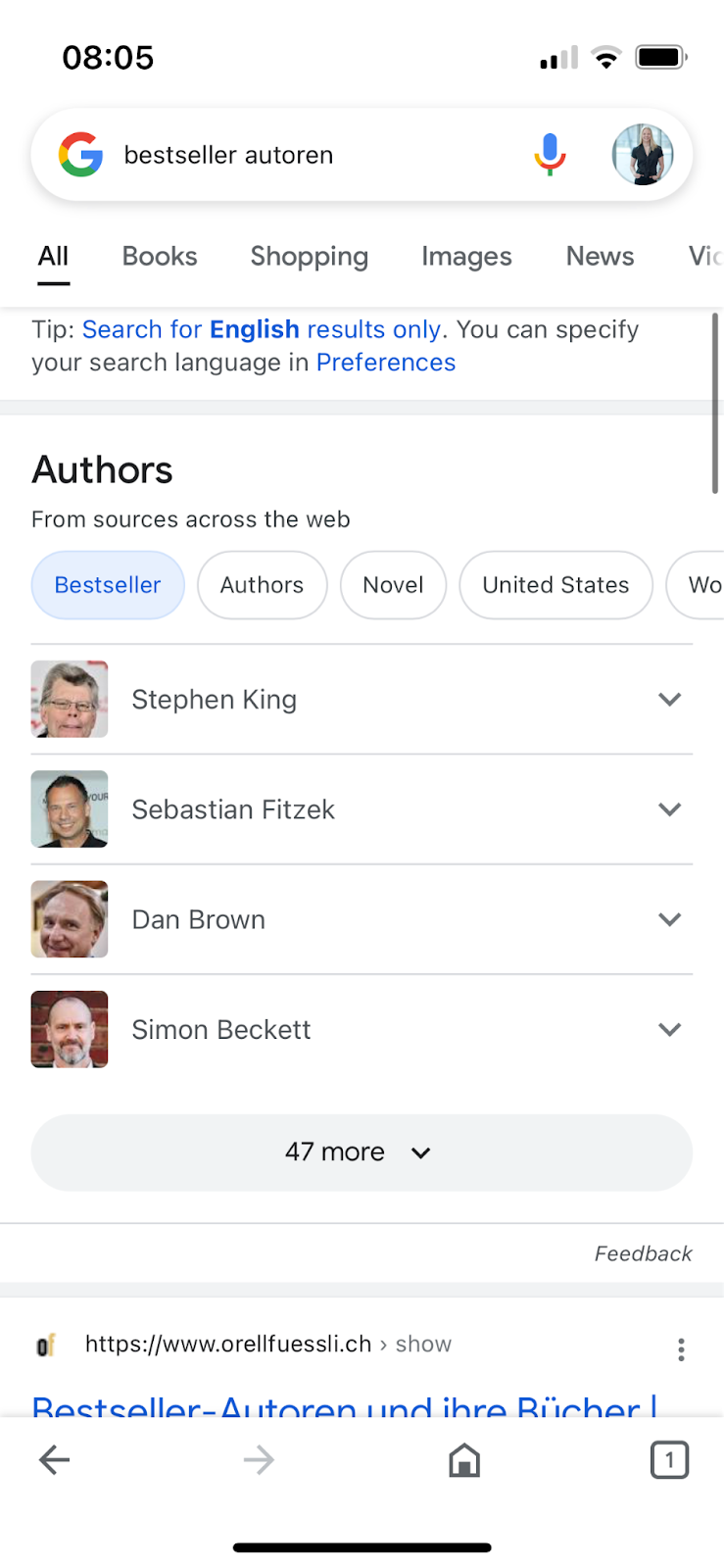 (Screenshot Google-Suche nach "bestseller autoren" vom 10.10.2022)
Suchsprache: Deutsch
(Screenshot Google-Suche nach "bestseller autoren" vom 10.10.2022)
Suchsprache: Deutsch
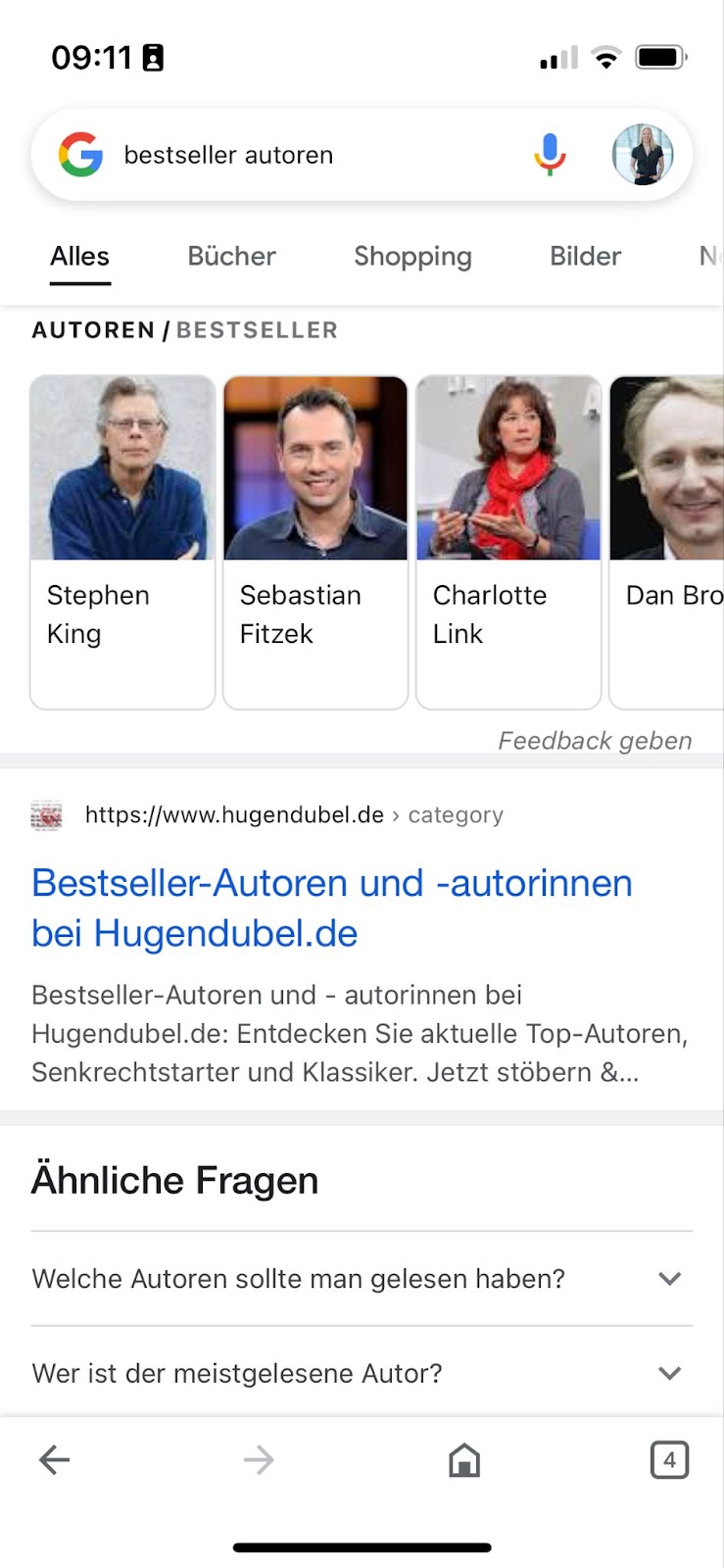
(Screenshot Google-Suche nach "bestseller autoren" vom 10.10.2022)
Zudem haben wir herausgefunden, dass, wie sollte es auch anders sein, Google natürlich nicht dem Schema F folgt. Bei der Eingabe von "best medical Authors", bekommen wir nicht konkrete Autoren geliefert, sondern thematisch passende Werke:
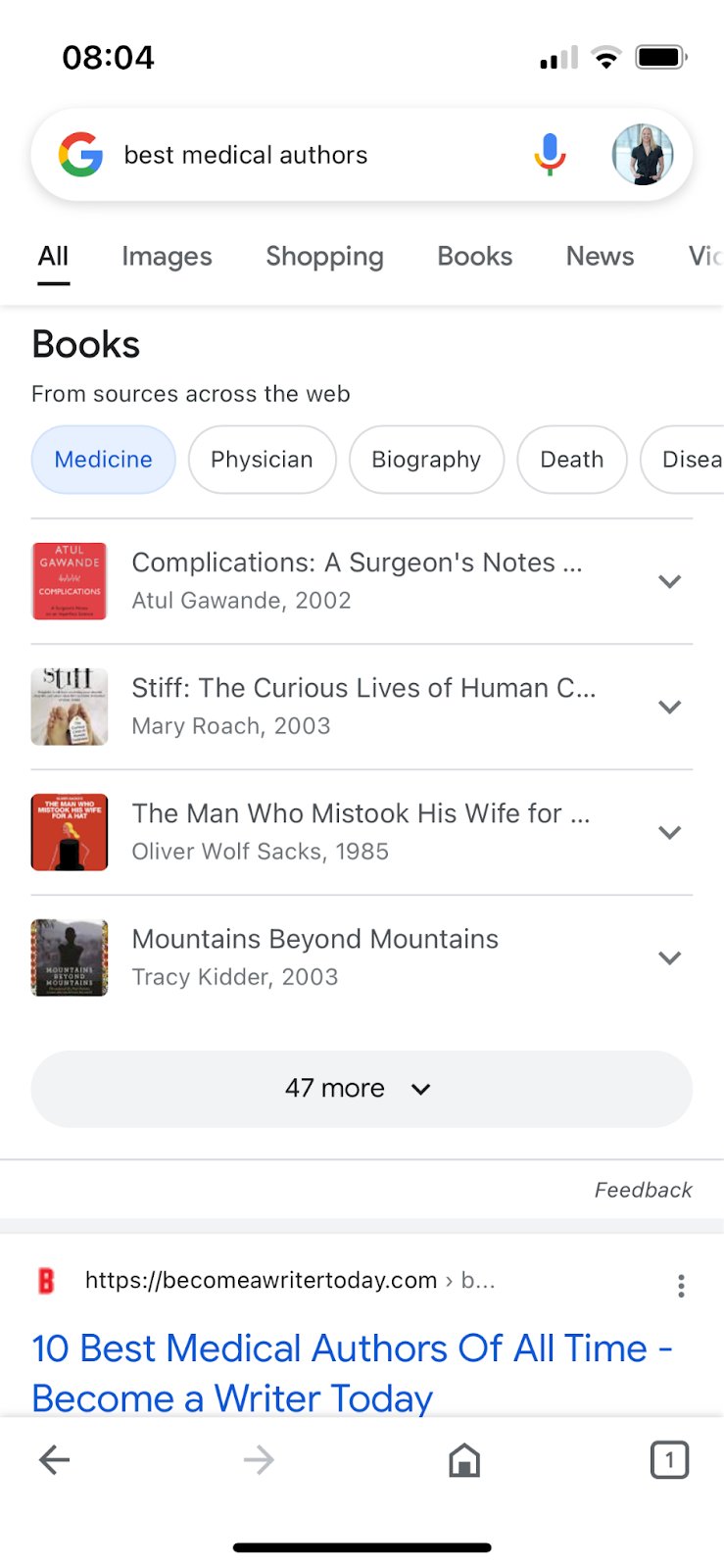
(Screenshot Google-Suche nach "best medical authors" vom 10.10.2022)
Und warum ist das Ganze jetzt so? Ja, das ist die Frage. Naheliegend wäre natürlich, dass Seiten wie die NY Times ein bombastisches Autorenmarkup haben und Google sich von dort die Infos zieht. Doch tatsächlich scheint das nicht der ausschlaggebende Faktor zu sein. Die Autorenseiten der NY Times sind z. T. als
"Collection Pages" ausgezeichnet
, was natürlich wenig Sinn ergibt. Andere haben gar keine Author-URL im Structured Data.
Auch der Guardian gibt da wenig Aufschluss, die haben überhaupt keine
Autoreninformationen angegeben
.
Es heißt also dran bleiben, beobachten, wann diese Integrationen ausgespielt werden, und den gemeinsamen Nenner finden!
|
|
|
Eingeklappte Inhalte - to rank or not to rank, that is the question
|
|
Google
behauptet gern
, eingeklappte Inhalte (z.B. der Inhalt von sogenannten Akkordeons, aufklappbaren Tabs oder einem "see content" Button) würden genauso gut funktionieren wie ausgeklappte, direkt sichtbare Inhalte. Voraussetzung dafür sei nur, dass der Inhalt im HTML gefunden werden kann.
In den letzten Wochen sind aber 2 Artikel erschienen, die diese Behauptung in Frage stellen und folgende These vertreten:
Dan hat sich zum Überprüfen dieser These eine URL des
Weißen Hauses
ausgesucht, die mit "hidden content" zum Ausklappen arbeitet. Er hat dann den (nicht Copyright-geschützen) eingeklappten Inhalt komplett sichtbar auf die Dejan-Homepage kopiert.
Bereits eine Stunde (!) später konnte er in den SERPs folgendes Bild sehen:
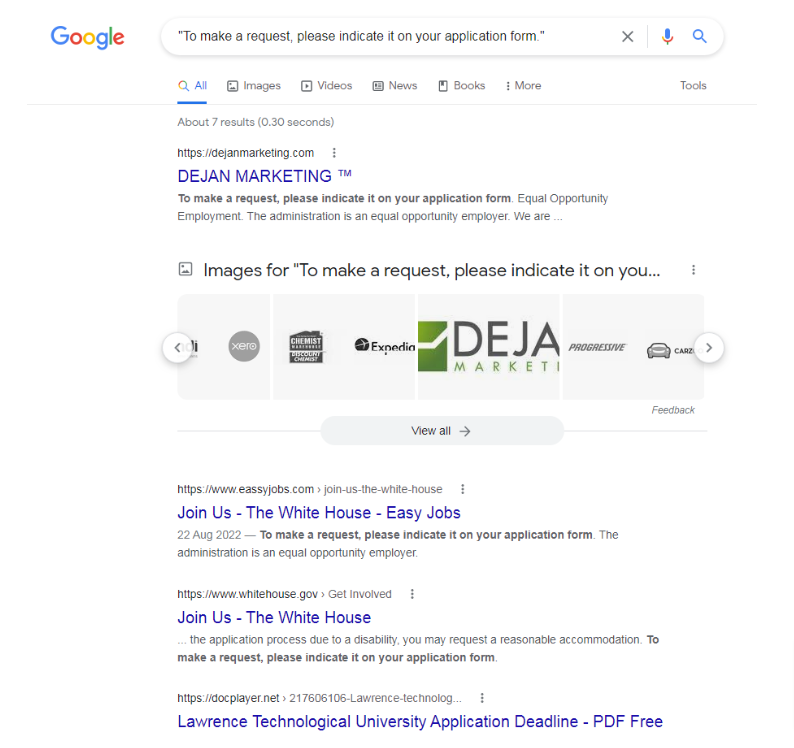
(Screenshot Google-Suche aus dem Artikel von
Dejan Marketing
)
Anschließend wurde der Text auf der Dejan-Homepage zu "hidden content" geswitcht. Praktisch sofort verschlechterte sich das Ranking.
Der Test dauert noch an:
"We'll follow up by switching between the visible and hidden content for a number of cycles to see if the gain and drop is consistent with each change."
Marcin Gorczyca
ist sogar noch einen Schritt weiter gegangen und hat sich Googles eigenen Content auf einigen Support-Pages genauer angeschaut.
Diese nutzen oft "collapsed content" in Tabs für weiterführende Informationen wie in
diesem Beispiel
:

(Screenshot Google-Suche aus dem Artikel von
Marcin Gorczyca
)
Als nächsten Schritt suchte er den Inhalt der Tabs und siehe da:
"When you search on Google for the content of the tabs you see above, Google's own page is being outranked by a spammy doorway page."
Weitere Stichproben ergaben, dass in ca. 50% der getesteten Fälle eine andere, meist spammy-wirkende Domain vor Google mit dessen Inhalt rankt.
In allen Fällen, in denen eine andere Seite Google outranken konnte, war der vorher eingeklappte Inhalt jetzt ausgeklappt.
Bedeutet das jetzt, dass man einfach den eingeklappten Inhalt einer beliebigen Seiten scrapen kann und dann damit besser rankt, wenn man den ausgeklappten Text zur Verfügung stellt? Marcin stellt klar:
"Well, no. I found many examples where Google wasn't outranked by scraped sites that didn't fold content into tabs.
But having inspected over 50 text fragments, I didn't find ANY examples of Google being outranked for content that wasn't hidden in tabs.
All data were obtained by manually checking SERPs using a VPN with a U.S. location, looking for exact text fragments in quotation marks."
Er stellt zur Begründung 2 Hypothesen auf:
"1. Google treats queries in quotation marks differently, prioritizing content that's visible on the page for some reason."
"2. Google gives less ranking weight to content hidden in tabs than content visible on the page."
Nr. 1 hätte wahrscheinlich wenig Auswirkungen, da wohl kaum Nutzer eingeklappten Text mit Anführungszeichen suchen.
Sollte aber die 2. Hypothese richtig sein, wäre das eine große Sache.
Egal welche Hypothese zutrifft, ich stehe auf der Seite von Dan Petrovic, der in seinem Artikel zum Schluss kommt:
If it's important don't hide it.
Wie siehst Du das? Kennst Du auch Beispiele, die vermuten lassen, dass eingeklappte Inhalte weniger gewichtet werden? Wir werden das auf jeden Fall weiter beobachten.
|
|
|
Paginierung - oder auch nicht
|
|
Du kennst Paginierungen. Wir kennen Paginierungen. Sie begegnen uns so gut wie jedes Mal, wenn wir mit einer Website zu tun haben. Diskussionen um die beste Umsetzung aus SEO-Perspektive gibt es vermutlich fast genauso lang wie SEO selbst. Deswegen hast wahrscheinlich auch Du das Gefühl, dass man keinen wirklich neuen Aspekt aufgreifen kann, wenn man das Thema wieder aufmacht.
So ganz Unrecht hast Du damit auch nicht. Aber das heißt nicht, dass nicht immer noch interessante Artikel darüber verfasst werden. So
zum Beispiel der von Oliver Mason
, den wir ziemlich gut finden. Das liegt nicht daran, dass er darin das Rad neu erfindet. Aber die Denkanstöße, die er gibt, sollten aus unserer Sicht hinter jeder Paginierung stecken, die implementiert wird – oder auch nicht implementiert wird.
Welchen Zweck soll die Paginierung eigentlich erfüllen? Ist sie das doppelte Netz um sicherzustellen, dass alle Produkte auch verlinkt werden? Ist es mir überhaupt wichtig, dass meine Produkte indexiert werden? Profitiere ich eventuell mehr davon, meine Paginierung zu maskieren und die Suchmaschine nicht mit Seiten zu belasten, die mir gar nicht wichtig sind?
Solche und noch weitere Fragen werden von Oliver in seinem Artikel aufgeworfen. Es ist erfrischend, dass er dabei Best Practices benennt und erklärt, aber weitergehend fragt, ob die Best Practice auch tatsächlich zum eigenen Anwendungsfall passt. Ich würde Dir in jedem Fall empfehlen, einmal selbst zu lesen. Sollte Englisch nicht Dein Forté oder die Zeit knapp sein, solltest Du auf jeden Fall die 'Hilfreichen Paginierungsfragen" von ihm mitnehmen:
-
Sind Dir Deine Produktdetailseiten als potentielle Landingpages wichtig?
-
Enthalten Deine Paginierungen Dinge, die dort vielleicht nicht sein sollten?
-
Wenn Dir Deine Produktdetailseiten wichtig sind, bekommen sie durch die Paginierung in etwa den Stellenwert, den sie auch business-seitig für Dich haben?
Damit kann man seine eigene derzeitige oder geplante Paginierung ganz gut hinterfragen. Ich persönlich hätte mir noch einen Abstecher zum Thema Suchintention und Ziel-Keywords zwischen Paginierung und Produktdetailseite erhofft, aber das ist wohl ein Thema für einen anderen Tag. Und der Artikel trotzdem lesenswert.
Im Übrigen wird darin auch auf
Audistos Paginierungsguide
verwiesen. Solltest Du Dich vollumfänglich mit Paginierungen beschäftigen wollen und etwas Zeit haben, ist das auch eine gute Adresse.
|
|
|
Recap NESS 2022
|
|
Wir waren dieses Jahr auf der News & Editorial SEO Summit
NESS 2022
.
Diese fand zum zweiten Mal statt, organisiert von
Barry Adams
und
John Shehata
. Zu unserem Leid fand die Konferenz in den USA statt – der Kaffeekonsum der digital teilnehmenden Wingmenschen war dadurch deutlich erhöht 😉
Es war aber sehr spannend zu sehen, worüber sich der Publishing Sektor Gedanken macht und welche Findings es bereits in den USA gibt.
Unsere Key Takeaways:
-
Die Publisher Karussells in den USA sind wohl verschwunden.
Dies hat zumindest John Shehata in den letzten 2 Wochen per Monitoring der SERPs festgestellt. Hast Du in letzter Zeit welche auf den deutschen SERPs entdeckt? Wir behalten das auf jeden Fall für Dich im Auge.
-
Strukturierte Daten sind wichtig.
Das weißt Du ja schon. Mich freut es aber natürlich sehr, dass sich immer mehr Personen Gedanken über dieses Thema machen und dessen Wichtigkeit auf der Konferenz unterstrichen wurde.
-
AMP ist unter Publishern immer noch ein großes Thema und wirft viele Fragen auf.
Die SEOs sind sich aber einig gewesen: AMP ist tot. Für den Erfolg als Publisher benötigst Du es nicht mehr. Zumindest wenn Deine CWV Werte in Ordnung sind.
-
Paywalls sind ein spannendes Thema.
Es kann sehr unterschiedlich aufgegriffen werden. Zudem machen sich viele Publisher Sorgen, dass die Inhalte in die falschen Hände geraten und dann an anderer Stelle ohne Paywall veröffentlicht werden.
Wir bei Wingmen versuchen immer in den verschiedensten Branchen up to date zu sein und bleiben weiter am Ball, um Dir kontinuierlich die bestmögliche Beratung zu ermöglichen.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an
[email protected]
oder
ruf uns einfach kurz an:
+49 40 22868040
Bis bald,
Deine Wingmen
|
|
|





