|
Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #25
|

|
|
SEO macht müde Geister munter
|
|
Diese Slogan wurde Ihnen präsentiert von
sloganizer.net
. Für Halloween sind wir zwar ein bisschen spät dran, aber 2020 ist ohnehin gruselig genug. Spannend hingegen sind mal wieder unsere SEO-Fundstücke, die heute einmal mehr einen sehr starken Content-Fokus haben.
Für das technische Gleichgewicht sorgen das gestrige Geburtstagskind Johan mit Einblicken in die Passage-Indexing-Sesamstraße und Justus mit einer kleinen Status Code-Diskussion.
Viel Spaß beim Lesen,
Eure Wingmen
|
|
|
Ihr SEOs der Welt, hört auf diesen Malte!
|
|
Seit einiger Zeit geht der liebe Juan von Sistrix mit SEO-Live-Sessions bei YouTube auf Sendung.
Diesmal zu Gast war Malte Landwehr
, Head of SEO bei idealo mit dem Thema “Räumt verdammt nochmal Euren Content auf” (so oder so ähnlich, vielleicht sind auch nur die emotionalen SEO-Sicherungen bei mir durchgebrannt und der Titel lautete schlicht: “SEO-Wert von Evergreen Content“).
Mit sehr anschaulichen Beispielen führt Malte durch ein paar Gruseleien aus dem Netz, bei dem sich mit der Content-Aktualisierung so gar keine Mühe gegeben wurde und zeigt Wege auf, wie man es besser machen kann. In ~25 sehr kurzweiligen Minuten sollte sich hier die ein oder andere Content-Strategie eine große Scheibe vom Know-How abschneiden.
TL:DR:
-
Nur das Datum auszutauschen reicht nicht aus
-
Dinge entwickeln sich und müssen über die Zeit neu bewertet werden
-
(Fehl-)Einschätzungen müssen stetig aktualisiert werden
-
Auf Versionierung und Umbenennungen Dritter acht geben und darauf eingehen
Oder um es auf den Punkt zu bringen: Autoren sollten sich mit der Materie über die sie schreiben intensiv beschäftigen und Details sauber herausarbeiten. Textmüll vom Fliessband besser in die Tonne. Qualität sticht immer heraus!
|
|
|
Wie geht Google eigentlich mit Status 307 um?
|
|
SEOs können sich die Köpfe heiß diskutieren, ob man 302 in 301 umwandeln sollte oder nicht. Kommt dann noch ein standardverliebter Entwickler der alten Schule (wir lieben Euch!) dazu, dann kann es ziemlich lustig und leicht nerdig werden. Ein wenig anders ist das mit dem Status 307. Hier haben wir schon Empfehlungen anderer Agenturen gesehen auch den 307 in einen 301 zu ändern. Warum das nicht geht und
wie Google aber mit dem 307 umgeht hat John sehr schön in diesem Video herausgearbeitet
.
Long story short:
-
Da der 307 nicht wirklich existiert, kann Google ihn nicht crawlen.
-
Da Google sich zwischen den Crawl-Vorgängen nichts merkt (auch keine Cookies), crawlt Google die HTTP-Version der Seite auch wenn HSTS gesetzt ist erneut.
-
HSTS führt also nicht dazu, dass Google weniger HTTP-URLs crawlt.
-
Trotzdem ist der 307 natürlich eine gute Praxis. Wir sind dafür.
|
|
|
Ein Artikel über EAT, der schwer zu verdauen ist
|
|
Eigentlich ist er gut zu fassen, aber schlecht zusammenzufassen. Lily Ray hat sich hingesetzt und Bill Slawski interviewed. Bill ist ein profilierter SEO, der regelmäßig die Patente von Google auseinandernimmt. Aus diesem Gespräch ist eine Zusammenfassung geworden
welche Patente wohl hinter Googles Verarbeitung von E-A-T stehen könnten
.
Wer sich für E-A-T interessiert, sollte diesen Artikel gelesen haben. Die ganz kurze Fassung ist, dass Google bei EAT Faktoren besonders auf Entitäten achtet. In Verbindung mit
Gary Illyes Erwähnung der Entity Extraction aus Structured Data (s. Anitas Linktipp)
spricht einiges dafür sich noch mal intensiver damit zu beschäftigen welche Inhalte mit noch mehr Structured Data ausgezeichnet werden können.
|
|
|
Google, die ganze Sesamstraße und einzelnen Passagen
|
|
Die ganze SEO-Welt redet von BERT.
Dawn Anderson hat einen umfangreichen und extrem guten Artikel geschrieben
in dem sie den aktuellen Stand von BERT und die Probleme dahinter herleitet und diskutiert. Der zentrale Satz ist gut versteckt:
In two stage ranking there is first full ranking (the initial ranking of all the documents), and then re-ranking (the second stage of just a selection of top results from the first stage).
Der Satz fast sehr gut zusammen, worum es beim Passage Indexing gehen wird und sagt uns auch, worauf wir bei der Optimierung achten müssen. Was meint das: BERT ist auch bei Optimierung sehr teuer in der Ausführung. Daher ist die Basis vorab immer noch eine „ganz einfache“ Bag of Words vorqualifizierte Liste. Und diese Liste wird dann mit den teuren Methoden in eine Reihenfolge gebracht.
Die erste Phase versucht so viele grundsätzlich relevante Dokumente zusammenzutragen, wie möglich. Wenn hier ein paar nicht ganz so relevante dabei sind, dann ist das nicht so wild. Eine solche Liste ist recht einfach skalierbar abzubilden. Wahrscheinlich wird dabei eine Weiterentwicklung von
Okapi BM25
genutzt (eine Weiterentwicklung von
WDF*IDF
).
In der zweiten Phase können aufgrund der kleineren Dokumentenmenge mehr Ressourcen aufgewandt werden, um die Dokumente in eine relevante Reihenfolge zu bringen. Hier spielen dann die üblichen Rankingfaktoren eine deutlich größere Rolle und natürlich auch BERT.
To summarize, efficiency and effectiveness combined are the main driver for two stage ranking processes. Use the most computationally expensive resources on the most important documents to get the greater precision because that’s where it matters most. Full ranking is stage one with reranking as stage two for improvements on the top-K retrieved from the full collection.
Und warum hängt das nun mit Passage Indexing zusammen? Nun ein Grund ist, dass BERT ein Problem mit langen Dokumenten hat. Zum anderen ist das Ranking von Einzelabschnitten ein lang gehegter Wunsch von Google. Eine schnellere Antwort auf die Frage des Nutzers bietet eine bessere User Experience, mehr Suchen und mehr Klicks auf Werbung.
Im Artikel zeigt Dawn anhand verschiedener Paper, welche Performance-Gewinne BERT-basierte Modelle auch für die erste Phasen haben können. Und warum es in der ersten Phase sinnvoll sein kann, nur Einzelabschnitte eines Dokuments zu bewerten.
Dieser Artikel ist ein Brett, aber eines, das sich lohnt zu bohren.
|
|
|
Kleine Fundstücke, die man so eigentlich nicht finden will
|
|
Schaust Du regelmäßig in Deine robots.txt und Deine XML-Sitemaps? Oder hast dafür vielleicht sogar ein
Monitoring am Start
? Könnte sinnvoll sein, damit Dir sowas nicht passiert:
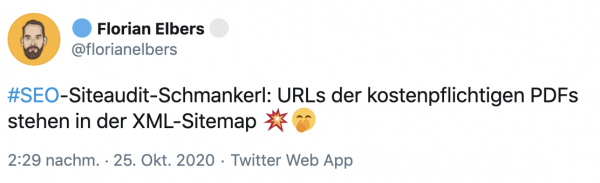
Im Best Case werden kostenpflichtige Inhalte, die in der XML-Sitemap landen, nur
von neugierigen SEOs gefunden
. Im Worst Case packt Google sie, wenn es kein “noindex” gibt, in den Index. Da können sie dann potenziell von jedem gefunden werden, ohne das Du einen Cent siehst.
Schade auch, wenn Inhalte, die Google sehen sollte, in der robots.txt gesperrt werden:
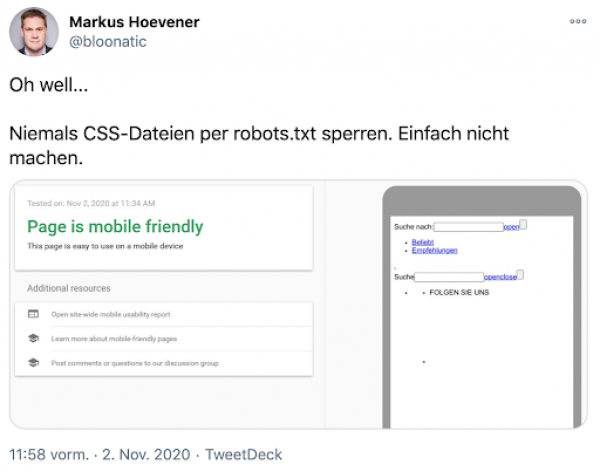
Klar, ist zwar immer schön, wenn der Mobile Friendly Check validiert. Aber nicht, wenn
das Ergebnis dann so aussieht
. Ein Grund, warum wir Fans von möglichst schlanken robots.txt sind, denn der
Standard-Eintrag tut es in den allermeisten Fällen
und verhindert solche Fails.
Also immer dafür sorgen,
-
dass wirklich nur verfügbare und indexierbare Dinge in der XML-Sitemap stehen
-
dass die robots.txt nicht zu restriktiv ist und Google vielleicht den Zugriff auf relevante Ressourcen verwehrt
-
dass es Dir möglichst direkt und nicht nur durch Zufall auffällt, wenn doch mal was schief geht
|
|
|
Kann man sich schon mal merken
|
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an
[email protected]
oder
ruf uns einfach kurz an:
+49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





