Letzte Woche schrieb ich:
"Wir müssen wachsam sein, dürfen uns aber auch nicht zu sehr von den wichtigen Dingen in der Gegenwart abhalten lassen, da unklar ist, wann genau die SGE ausgerollt und überhaupt offiziell in Deutschland verfügbar gemacht wird."
da kommt ein Artikel um die Ecke, bei dem ich fast vom Stuhl gefallen bin. 🪑
Vorgestellt wurde ein Framework beziehungsweise Modell, mit dem man den Impact der SGE messen können soll. Angepriesen wurden auch Antworten auf folgende Fragen:
"If and when Google SGE goes live, how will it impact organic traffic?
"Will our traffic drop, and if so, by how much?"
"And what can we do about it?"
"Das klang für mich nach Clickbait."
Die Basis des Frameworks
Das Framework greift auf vereinfachende Annahmen zurück (das Emoji signalisiert, ob ich bei der Annahme mitgehe oder nicht):
✅ Wenn eine Seite im AI Overview auftaucht, wird sie (etwas) organischen Traffic bekommen ❌ Der Traffic aus dem AI Overview wird genauso viel oder wenig sein, wie über den aktuellen Rang in der organischen Suche kommt ❌ Wenn Deine Seite noch nicht im AI Overview rankt, aber in den regulären Top-10, wirst Du keinen Traffic bekommen (konservative Schätzung) 🚧 Wenn die SGE nicht aktiv ist, rankt Deine Seite genauso wie bisher
Annahme 1 finde ich valide. Ob und wie viel Traffic über eine Kachel in der Carousel-Box oder Quellenverlinkungen kommt, wissen wir aber nicht.
Annahme 2 finde ich kritisch, weil nur informationale Keywords betrachtet wurden. Im E-Commerce wird es, so die These vieler und auch von mir, viele Chancen geben, dass vor allem Produktseiten wichtiger werden und mehr Traffic bekommen, als es jetzt der Fall ist.
Annahme 3 wird im Artikel direkt selbst relativiert, weil sie unrealistisch ist. In dem Fall hat man sich das Modell direkt selbst invalidiert.
Annahme 4 würde ich auch mit Skepsis betrachten. Wenn damit gemeint ist "es wird kein AI Overview ausgespielt", dann gehe ich mit. Ansonsten nicht, weil Google an der SGE festhält und es vermutlich keine Suche mehr geben wird, bei der man sagen kann "ich möchte SGE" oder "ich möchte keine SGE".
Was ich gerade nur in einem Satz erwähnt habe, möchte ich hervorheben:
"Our study focused on websites in the technology industry, with traffic mainly from informational keywords."
Die Ergebnisse lassen sich also auf keinen Fall verallgemeinern.
Noch mehr Gemecker
Der "eigentliche Rang" soll aussagen, ob eine Seite im AI Overview auftaucht und an welcher Position. So wird es im Artikel beschrieben:
Optimistischer Rang = wenn man mehrfach prüft, ob und an welcher Position im AI Overview gerankt wird, wird nur die beste Beobachtung gezählt (z.B. 3, 5 und kein Ranking -> optimistischer Rang = 3) Pessimistischer Rang = wenn man mehrfach prüft und gar kein Ranking vorhanden (= kein Ranking) ist oder es immer ein Ranking gibt, dann wäre der Durchschnitt der pessimistische Rang (z.B. "kein Ranking" im genannten Beispiel, weil einmal nicht gerankt wurde oder 3, 4 und 5 dann wäre 4 der pessimistische Rang)
Das ist VIEL zu einfach gedacht. Ich verstehe, man muss irgendwo und irgendwie anfangen. Aber es hat schon einen Grund, warum wir alle Tools verwenden, die unsere Keywords über lange Zeiträume beobachten. Wenn ich 3x am selben Tag prüfe, sieht vielleicht alles gut aus. Möglicherweise auch, wenn ich das 3x in der Woche mache.
Wie sieht das aber über einen Monat aus? Das sind wichtige Informationen, um Aussagen über langfristige Traffic-Entwicklungen tätigen zu können.
Neben dem eigentlichen Rang gibt es auch Annahmen zur potenziellen CTR-Veränderung. Der aktuelle Status-Quo wird mit einer optimistischen Schätzung (Top-3 im AI Overview bekommt jeweils die gleiche Menge an Klicks) und einer pessimistischen Schätzung (Halbierung der optimistischen Schätzung) angegeben, um die Auswirkungen zu simulieren.
Dass alle 3 Positionen den gleichen Traffic bekommen, finde ich unrealistisch. Was aber entscheidender ist: Zum Zeitpunkt der Veröffentlichung des Artikels gab es bereits die Dropdown-Pfeile für die Quellenhinweise, die nicht berücksichtigt wurden.
Wie werden Keywords ausgewählt?
Es wird davon gesprochen, dass ein kleines Keyword-Set (20%) gewählt werden soll, das einen Großteil des organischen Traffic generiert (80%). Klingt erstmal gut. Bei sehr großen Websites oder Websites, die ihren Traffic auf viele URLs und Keywords diversifiziert haben, aber schwierig anzuwenden.
Abseits der ganzen Annahmen und Vereinfachungen: Dieses Modell ist nicht skalierbar. Es geht immer um manuelle Beobachtungen und das ist ab einer bestimmten Seitengröße nicht mehr effizient machbar.
Wie aussagekräftig sind die Ergebnisse?
So wie ich beim Lesen des Artikels fast vom Stuhl gefallen bin, würde vermutlich auch die Person fallen, die gerne wissen wollte, wie groß der Impact der SGE wohl sein könnte.
Von -30% Verlust ist auch fast 220% Traffic-Gewinn möglich (gleiches Beispiel). Das ist eine sehr große Spanne und zeigt auch, dass dieses Modell eher wenig sinnvoll ist. Vor allem wenn man daran denkt, dass diese Annahmen nur auf den wenigen Beobachtungen basieren, die man für den eigentlichen Rang braucht.
Die SGE ist unglaublich volatil. Wenn es eine Beobachtung gibt, die ich besonders wichtig finde, dann ist es diese.
Hier mal ein paar Beispiele, wie sich der AI Overview in den letzten 2 Wochen verändert hat:
Beispiel 1: Depression (YMYL)
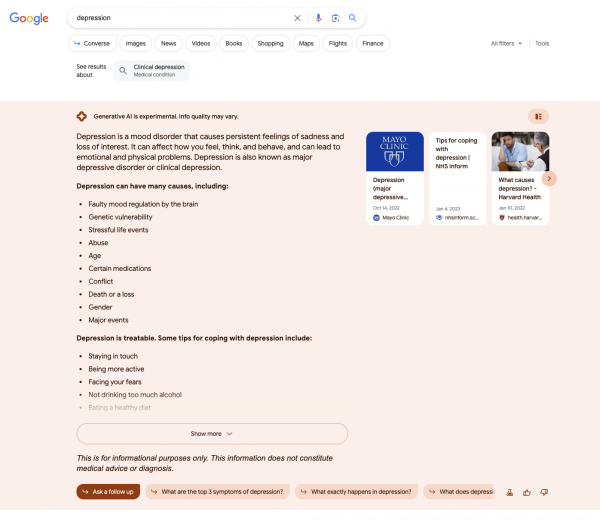
Datum: 25.08.2023
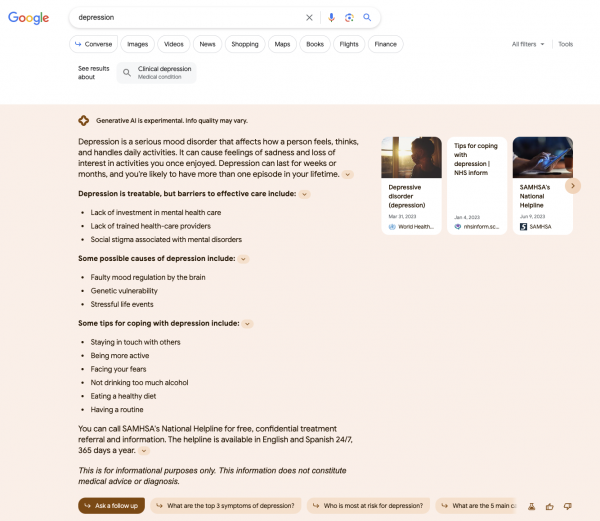
Datum: 11.09.2023
Beispiel 2 Dresses (E-Commerce Kategorie)
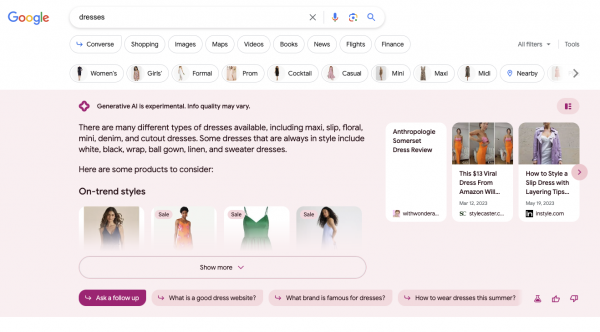
Datum: 25.08.2023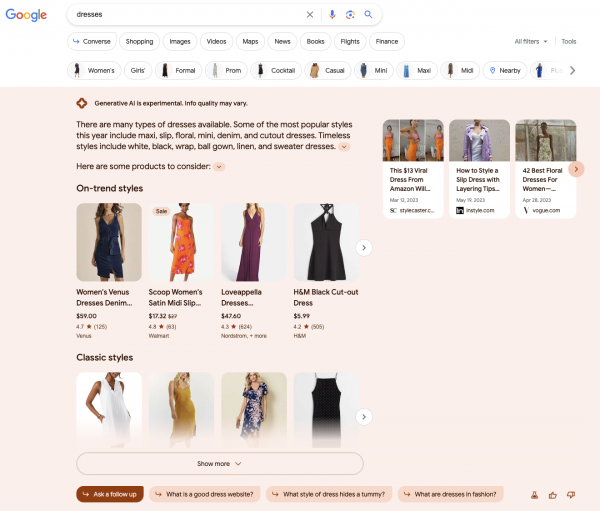
11.09.2023
Wie man sieht: Die AI Overviews unterscheiden sich. Manchmal mehr, manchmal weniger. Im ersten Beispiel zur Suchanfrage Depression werden jeweils erst viele Unterpunkte dargestellt und dann deutlich weniger. Die Quellen sind jeweils auch in ⅔ der Fälle unterschiedlich.
Etwas drastischer sind die Veränderungen vom AI Overview für Dresses. Die Quellen überschneiden sich in ⅔ der Fälle (aber nicht in der Reihenfolge) und der AI Overview ist nahezu doppelt so groß. Wenn man in diesem zweiten Beispiel nicht im AI Overview landen würde, wäre der Verlust sicherlich deutlich größer als zum Zeitpunkt der ersten Betrachtung. Auch interessant: Bei den Bildern in der ersten Beobachtung wurden die Köpfe der Models nicht angeschnitten, in der zweiten Beobachtung hingegen schon.
Es geht noch weiter!
Am Ende wurden noch mögliche Experimente und Interventionen vorgeschlagen – oder auch nicht, weil "geheim".
Case Studies sind, wenn sie gut aufbereitet sind, sehr spannend. Aber nur dann, wenn die Ergebnisse auch real sind. Der Autor zeigt hier anonymisierte Kundendaten und die möglichen Auswirkungen auf deren Seiten, die jetzt durch "Maßnahmen" verhindert werden sollen.
Die SGE gibt es offiziell aber noch nicht in der normalen Suche. Aktuell ist es ein Test in den USA und seit kurzem auch in Indien und Japan. That's it. Seit Ankündigung der SGE haben sich viele Sachen verändert. Unter anderem:
Angaben zu Quellen (die es vorher gab, aber versteckt waren) Für welche Queries die SGE überhaupt ausgespielt wird (für Politiker*innen konnte ich eine Zeit lang keine AI Overviews erzeugen) Lokale Ergebnisse als 3 Pack (alt) oder 5 Pack (neu)
Auch in den Case Studies findet sich erneut ein Ergebnis, bei dem der mögliche Verlust auf -31% geschätzt wurde und ein potenzieller Zuwachs von bis zu 97% möglich sein soll. Solche Schätzungen sind mir zu extrem.
Was habe ich beobachtet?
Die Entwicklungen rund um die SGE beobachte ich seit der Ankündigung. Einige Keywords prüfe ich regelmäßig. Was sich hier im Artikel wie Zauberei anhört (= die geheimen Interventionen), ist bei informationalen Keywords häufig das, was man bei Featured Snippets auch schon gemacht hat:
Welche Keywords haben ein Featured Snippet? Wie kurz/lang ist die ausgegebene Antwort? Wie ist die Antwort formatiert? Wo taucht die Antwort im Text auf?
Im Carousel der SGE kann man erscheinen, wenn man die Informationen zur Verfügung stellt, die der AI Overview beinhaltet (Suchintention). Da die Antworten aber sehr wandelbar sind, ist das oft von kurzer Dauer.
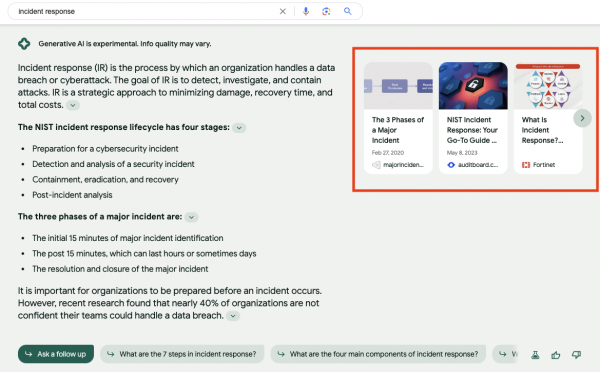
Im Artikel wird ein konkretes Beispiel genannt, bei dem ein Kunde durch Maßnahmen (🤐) in der SGE auftauchte (Position 1 der Carousel-Box) Das Query: "incident response". Witzig ist, dass in der Headline der Antwort von vier Schritten gesprochen wurde, in der Antwort aber nur 3 ausgegeben wurden.
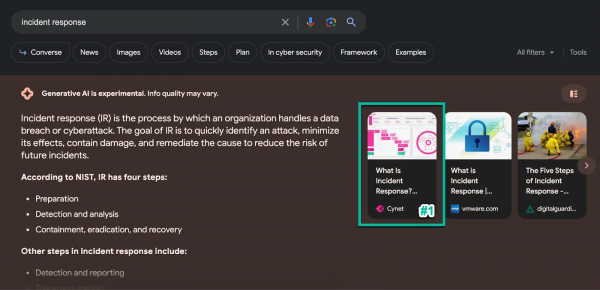
Die angesprochene Kundenseite von Cynet sah vorher so aus (Einstieg der Seite):
Und nachher so (Einstieg der Seite):

Die Seite wurde also daran angepasst, dass es ein informationales Query ist (inhaltliche Ausrichtung der Headline) und dass es einen Prozess mit 4- oder 6-Schritten gibt (die Namen haben), je nachdem welchem Modell man folgt. Vorher waren diese beiden Teile aufgespalten und die NIST incident response wurde nicht namentlich genannt.
Inzwischen sieht der AI Overview anders aus. Cynet taucht auch nicht mehr an Position 1 auf und ist im AI Overview nicht mehr vertreten.

Mein abschließender Take
Im Intro habe ich meine Worte der letzten Woche zitiert und komme gedanklich für den Abschluss auf diese zurück:
Beschäftige Dich mit der SGE Denke über Modelle nach, um den potenzielle Impact auf die für Dich wichtigsten Keywords abschätzen zu können Mache Dir Gedanken zu potenziellen Maßnahmen – wenn Du eine internationale Seite mit USA-Präsenz hast, kannst Du auch eigene Maßnahmen vertesten ABER: Mache Dich nicht verrückt und hinterfrage derartige Modelle, wie sie im Artikel bei Search Engine Land vorgeschlagen wurden
Das Modell ignoriert andere Keyword-Arten. Natürlich kann man (wie vorgeschlagen wird) ein eigenes Modell entwickeln. Aber so wie es beschrieben wird, ist das Modell nicht skalierbar und trifft Annahmen, die bereits vor Anwendung des Modells kritisch zu sehen sind.
Wir wissen nach wie vor nicht, wann und in welcher Form die SGE offiziell ausgerollt wird. Bard hat eine ganze Weile auf sich warten lassen und wenn es neue SERP Features in den USA gibt, dauert es in der Regel, bis wir das in der deutschen Suche sehen, wenn es überhaupt dazu kommt.
Was man statt diesem Modell braucht, ist eine relativ stetige Beobachtung der SGE-Ergebnisse für die wichtigsten Keywords. Es müsste gemessen werden,
ob/wie die eigene Seite in der organischen Seite rankt (das wissen wir), ob/wie die eigene Seite im AI Overview rankt, wie lange sie dort rankt, wie oft sie in den Quellenangaben zitiert wird (abseits der Carousel-Box) und wie sich die Position in der Carousel-Box verändert.
Das reicht aber immer noch nicht aus, weil es ja auch noch Ads gibt (die wir alle lieben). Und Queries, die entweder keinen AI Overview generieren können (aktuell beobachte ich das bei Queries für Rezepte) oder Queries, bei denen nicht direkt ein AI Overview generiert wird.
Welcher Tool-Anbieter wird wohl als erstes SGE-Funktionalität integrieren, wenn die SGE offiziell ausgerollt wird? Und wie sieht es mit Traffic-Zahlen aus der SGE aus – werden wir die bekommen? Es gibt viele Glaskugeln, in die man schauen könnte. 🔮
|




