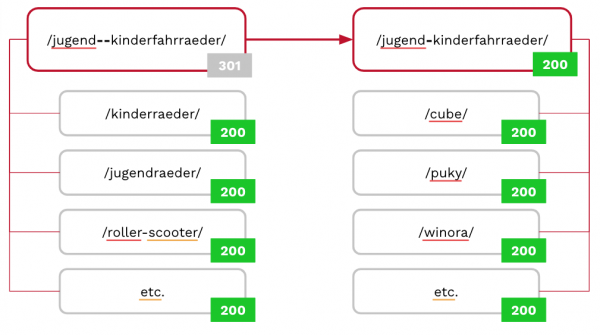
Am 11.09. durfte ich im Vorfeld der SMX Advanced einen sehr intensiven Technical SEO Workshop halten. Das war ein fantastischer Einstieg. Und das komplett ohne AI. Der Workshop war ein toller Auftakt für mich, um meinen Kopf auf englisch umzustellen.
Die SMX Advanced ist nämlich ein wenig anders als andere Konferenzen in Deutschland:
Es gibt nur einen Raum. (Okay. Da ist noch der PPC-Raum, aber wer interessiert sich schon dafür?) Das bedeutet: Du kannst nicht aussuchen. Das erleichtert das „Treibenlassen" auf der Konferenz enorm. Und es führt dazu, dass Du nicht immer nur Deinem Lieblingsthema hinterherrennst, sondern von überall Deine Synapsen befeuern lässt. Das Niveau der Speaker ist vortragstechnisch, aber auch inhaltlich, extrem hoch. Muss es auch, denn es gibt ja nur einen Slot. Alles auf englisch. Schließlich kommt die Audience dieses Mal aus 23 Ländern 🤯. Bei den Speakern war die Varianz nicht ganz so hoch. Aber: Bayern, Deutschland, USA, Niederlande, Großbritannien. Übrigens: Die Moderation von Dominik Schwarz war fantastisch.
Aber nun, without further ado: Was hab ich mitgenommen?
Ich habe fast alle Sessions gesehen. Hier meine (fast ungefilterten) Notizen:
André Morys:
Toller Auftakt. Conversion darf SEOs und SEAs nicht egal sein. Sein Beispiel „Girokonto eröffnen" und die dysfunktionale Landingpage der Commerzbank – die am Silodenken scheitert – war sehr lustig. Bis einem aufgeht, dass man auch selbst Kunden hat, denen das passieren kann. Sein Zitat dazu gebe ich mit Freude wieder:
"They are not responsible for this shit. They just executed badly."
Tom Anthony:
These: Entitäten in Schema.org sind limitiert. Google wird durch Vector Space die Lücken füllen. Darauf muss ich mich einstellen. Nicht mehr in Schema investieren, sondern andere Beschreibungen des gleichen Sachverhalts einfügen: „Hey ChatGPT, gib mir 5 Formulierungen für kindersicherer Pool, die ich auf einer Ferienhausseite unterbringen könnte, die aber das Wort kindersicher nicht enthalten."
Das war unterhaltsam, aber ich teile weder die Analyse, noch die Schlussfolgerung. Wenn die Entitäten in Deinem Bereich nicht ausreichen, um Deine gewünschten Produkte zu beschreiben, dann ist es relativ leicht, die in Schema.org unterzubringen. Schema hat weiterhin eine höhere Verlässlichkeit als Text Extraction. Und der Vorschlag, dass wir jetzt immer denselben Inhalt in noch mal anderen Formulierungen auf der Seite unterbringen, kann einfach nicht die Lösung sein.
Bastian Grimm:
... hatte einen tollen Primer zu AI in der Suche. Notizen habe ich mir keine gemacht. Nur noch mal ein Foto seiner Folie mit den Anforderungen an bessere Prompts:
Role Context Instructions Format Examples Constraints
Lily Ray:
Auch Lily war zu AI unterwegs. Sie hat wieder den Preis für die mit Abstand hübschesten Slides gewonnen. Und der Vortrag war der nächste extrem souveräne Vortrag. Das sind Vorträge auf einem anderen Level, als wir das in Deutschland gewohnt sind.
Lily hatte sich vorgenommen, praktische Anwendungsfälle für ChatGPT, Claude, Bard und Bing zu Teilen. Sie hat mehrfach erwähnt, dass sie Claude lieber mag als ChatGPT und ich stimme ihr zu. Ich habe in den letzten Wochen viel mit Claude gearbeitet und das macht einfach Spaß.
Ein paar Workflows, die sie erwähnt hat und die ich smart fand:
Content vergleichen
Klopp den Content der Top3 oder Top5 Seiten in den Automaten und lass Dir einen Vergleich bauen.
Bei ChatGPT (ich glaube nur Pro) kannst Du die URLs angeben. Bei Claude musst Du den Umweg gehen, die Seiten einmal als PDF zu speichern. Aber der Aufwand lohnt sich.
Du kannst dann fragen:
Welchen Content haben diese Seiten, der in meinem Artikel fehlt? Was machen diese Seiten, um Experience, Expertise Authoritiveness und Trustworthiness zu unterstützen? Wie könnte mein Artikel verbessert werden, um mehr EEAT im Vergleich auszustrahlen? Bitte liste 10 Gemeinsamkeiten und Unterschiede der Inhalte dieser Seiten!
Etwas, das Lily nicht erwähnt hat, ich aber wichtig finde, wenn man PDF oder Crawling anwirft: Du musst validieren, dass der Content korrekt extrahiert wurde.
Guidelines abgleichen
Vor einiger Zeit geisterte der Vorschlag durch die Blogs, dass man doch die Quality Rater Guidelines an ChatGPT geben sollte. Ich habe das für Quatsch gehalten, weil die viel zu ausführlich sind, als dass die LLMs das in ihrem beschränkten Speicher merken könnten.
Aber Lily hatte eine schöne Idee: Google hat einige Blogposts mit Fragen an Dokumente / Seiten zur Evaluation der Qualität. Diese Fragen kann man LLMs gut gegen den eigenen Content prüfen lassen.
Muster finden
Wir können ChatGPT die Headlines unserer erfolgreichsten Artikel geben und daraus Muster identifizieren lassen für neue Artikel. (Ich bin mir nicht sicher, ob sie sich auf Discover bezogen hatte, aber da ist der Impact natürlich besonders groß.)
Natürlich können wir diese Überschriften auch nutzen, um eine bessere Überschrift für einen neuen Artikel zu finden.
Oder, um eine Guideline daraus zu formulieren.
SGE
Anschließend hat Lily noch ihre Erkenntnisse zur SGE geteilt.
SGE kann man beeinflussen durch den Content auf der eigenen Seite Wir können nicht nur beeinflussen ob wir angezeigt werden sondern auch, auf welche Schwerpunkte Google eingeht SGE ist nicht immer sooo schlau
Es wird also weiter SEO brauchen.
Joost de Valk:
"The Internet will use a fifth of all the world's electricity by 2025."
🤯
"Cloudflare says that 28% of web traffic is bot traffic. That means 5% of the world's electricity is bots.
It's likely that you will have a bigger impact on climate change by changing your robots.txt than by stopping to fly."
Joosts Botschaft: Bots crawlen dumm. Aber viel. Wir sollten daher unsere Defaults ändern: Nicht alles erlauben, sondern allen Bots alles verbieten, bis auf das, was wirklich gecrawlt werden muss.
Wenn China keine Rolle für Dich spielt, dann kannst Du Baidu blocken. SEO-Tools sowieso.
Martin Splitt:
"Tools are like street lights.
They guide your way. But only a drunk would cling to them."
Tech Audits sind nicht einfach. Es braucht Erfahrung und Mut, sich von der Checkliste zu lösen.
Ich würde jedes Wort dieses engagierten Vortrags unterschreiben.
Wenn wir uns nicht mit dem Geschäftsmodell und Aufbau der Seite auseinandersetzen, dann werden wir mit unseren Empfehlungen schnell dämlich aussehen. Gleiches gilt für Tools, die wir benutzen, aber nicht verstehen.
Wir sollten also viel mehr Dokumentation lesen (nicht nur die von Google, sondern auch die von Tool-Anbietern). Und wir sollten mehr mit den Menschen reden, die auch wirklich die Umsetzung machen.
Außerdem müssen wir unsere Vorschläge darauf prüfen, ob sie wirklich eine Traffic-Verbesserung für diese Domain bringen werden. Es geht nicht um viele Todos, sondern um die wichtigen, die wirklich etwas bringen.
"If everything is important, nothing is."
Auch ein wichtiges Zitat:
"Don't fix what's not broken. Search for impact."
Wenn eine SEO-Checkliste sagt, dass wir etwas ändern sollen, dann sollten wir das nur ändern, wenn es auch wirklich ein Problem verursacht. Und das können wir nur mit Erfahrung sagen. Denn je nach Seite sind 1 Mio. nicht indexierbare URLs ein Problem, oder nur eine Randnotiz wert.
Markus Hövener:
Bilder spielen eine wichtige Rolle in den SERPs. Und was Bilder angeht, können SEOs viel von Youtube lernen.
Markus hatte ein paar schöne Beispiele:
Das Bild neben einem Ergebnis ist abhängig von der Suchanfrage. Bilder sollten, um neben der Suchanfrage zu erscheinen, größer als 200x200px sein. Die Bilder neben den Suchergebnissen lassen sich mit CTAs vollballern, oder anderweitig auf die CTR optimieren. Google nimmt meistens das erste Bild, aber das lässt sich beeinflussen. Insbesondere mit kontraststarken Bildern, die sich von den anderen auf der Seite abheben. Und mit Alt-Attributen. Die SGE nimmt als Seitenverhältnis nicht 1:1, sondern eher 19:10. Außerdem scheint SGE grundsätzlich das og:image image zu wählen. Das wird natürlich ein wenig tricky zu optimieren.
Christopher Gutknecht und Danny Zidaric
haben zusammen vor allem einen Einblick in ihre Monitoring-Prozesse gegeben. Leider habe ich den ersten Abschnitt verpasst (um mich nochmal auf meine Präsentation vorzubereiten). So habe ich wenig von der Herleitung mitbekommen und eher die Beispiele.
Die waren aber schön gemacht: Wie kann ich mit einem schmalen Budget selbst Monitoring aufsetzen? Dafür haben sie sich ein paar Tools aufgesetzt, die die Daten an unterschiedlichen Stellen einsammeln und mit Alerts und Dashboards auf diese Daten wieder aufsetzen.
Tasks waren unter anderem:
Bei den Vorträgen von David Mihm und Jan-Willem Bobbink war meine Konzentration raus.
David hat über einen Prozess für lokale Themenrecherche gesprochen. Und betont, dass wir nicht einfach unlokalisierte Keyworddaten für lokalisierte Keywords verwenden können. Insbesondere die Bewertung, wie schwer es wird, zu ranken, ist dann oft fehlerhaft.
Jan-Willem hat LLMs zum Glühen gebracht. Aber eigentlich war ich froh, dass der zweite Tag wenig mit AI zu tun hatte.
Johans Vortrag
Mit meinem eigenen Vortrag bin ich ganz zufrieden. Zwei Leaks in einem Vortrag sind aber für die Zuhörer ein sportliches Programm. Es schien der Audience aber gefallen zu haben und ich glaube wirklich, dass die Meisten Dinge mitgenommen haben, die sie noch nicht wussten. Zumindest einige SEOs, die ich sehr schätze, wussten nicht, was in dem Google Leak so alles versteckt ist.
Alles in allem: Eine tolle Konferenz!
|