| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #140 |

|
| 💨 Viel (Yandex)-Wind um nichts? |
Wie ein Orkan ist der Leak des Yandex Source Code durch die SEO-Welt gefegt. Wir finden - erstmal viel Wind um eigentlich gar nicht so viel. Warum Du Dich entspannt wieder unter Deine Decke kuscheln kannst:
Yandex = Google: Ist Quatsch. Und nur weil ein paar Google-Mitarbeiter bei Yandex sind, heißt das noch lange nicht, dass Google die Dinge auch benutzt. Es gibt viele Ranking-Faktoren, die Google nicht verwenden würde. Viele der Ranking-Faktoren sind schon lange bekannt. Es ist eigentlich egal, welche Ranking-Daten wir nutzen, solange wir nicht wissen, was überhaupt wie in den Index einläuft.
Falls Du Dich dennoch genauer damit befassen magst, sind zum Einstieg diese Quellen für Dich sicher interessant: Twitter-Thread von Alex Buraks, Artikel von Martin MacDonald, Yandex Search Code Explorer Tool von Rob Ousbey, Artikel von Danny Goodwin, Twitter-Thread von Malte Landwehr
Neben brausenden Yandex-Böhen kommen außerdem folgende Themen geweht:
Matt pfeift ein Lied von Continuous Scrolling Nadine erzählt Dir, warum Du die Robots.txt eher luftig gestalten solltest Andreas windet sich nicht um die Frage nach dem richtigen CMS für E-Commerce Anita kommt mit einem Data Deep Dive geschwebt Christoph haucht Dir weitere KNIME-Vorlagen ins Ohr
Lass Dich nicht vom Winde verwehen.
Viel Spaß beim Lesen ❣️
Deine Wingmenschen
|
|
| They see me scrollin’, they clickin’: Continuous Scrolling für Desktop |
 Continuous Scrolling gibt es in der mobilen Suche bei Google ja nun schon eine Weile. Was es in Deutschland bisher noch nicht gibt, ist die Continuous Scrolling-Funktion bei den Desktop-Suchergebnissen. Das könnte sich nun jedoch bald ändern! Continuous Scrolling gibt es in der mobilen Suche bei Google ja nun schon eine Weile. Was es in Deutschland bisher noch nicht gibt, ist die Continuous Scrolling-Funktion bei den Desktop-Suchergebnissen. Das könnte sich nun jedoch bald ändern!
Statt der Auswahl von Seite zwei bis zehn (auf die ohnehin fast niemand geklickt hat) am Ende der Seite... 
...würde dann ein rundes Ladesymbol auf Dich warten:

... und einen Wimpernschlag später bekämst Du auch schon die nächsten Suchergebnisse präsentiert. Und das, ohne ein einziges Mal auf die linke Maustaste klicken zu müssen. Luxus pur!
Seite 2 und alle weiteren Seiten würden damit endgültig von der Bildfläche verschwinden und mit ihnen die Möglichkeit, dort bequem eine Leiche zu verstecken (Du wusstest, der Spruch würde kommen...). Was für Deutschland aktuell noch mit sehr viel Konjunktiv gespickt ist, könnte bald schon Realität werden, denn in den USA ist die Continuous Scrolling Funktion für Desktop inzwischen bereits ausgerollt.
Damit drängt sich natürlich auch die Frage auf, was diese Veränderung für die Verteilung der Klicks bedeuten würde.
Hätte, wäre, könnte: Die möglichen Folgen von Continuous Scrolling für Desktop
Bisher sieht es so aus, dass sich über 50% aller Klicks auf die ersten drei Suchergebnisse verteilen. Die meisten Klicks erhält dabei üblicherweise das Top-Ergebnis auf Position 1 mit rund 20 - 40% aller Klicks.
An dieser Verteilung würde sich wohl auch mit der Einführung von Continuous Scrolling für den Desktop hier in Deutschland nicht viel ändern. Warum auch? Der Ladekreis mit den weiteren Ergebnissen lauert ja erst weiter unten auf der Seite.
Für die übrigen Suchergebnisse, allen voran die hinteren Plätze auf Seite 1, sähe es dagegen schon etwas anders aus. Denn gerade die Treffer, die sonst auf Seite 2 im Nirgendwo verschwunden sind, hätten nun die Chance, ebenso auf dem Bildschirm des Nutzers aufzutauchen und dadurch ebenfalls Klicks abzugreifen.
Das bedeutet im Umkehrschluss natürlich, dass die hinteren Positionen künftig möglicherweise einige Klicks einbüßen müssten (Sich mühsam von Seite 2 auf Seite 1 vorzuarbeiten, würde sich somit weniger lohnen. Danke für nichts, Continuous Scrolling!). Umso stärker würde dadurch noch einmal die Snippet Optimierung in den Fokus rücken, ebenso wie der Versuch, sich durch Rich Snippets von den anderen Ergebnissen abzuheben.
Eine weitere Veränderung würde sich vermutlich beim Anpassen einer Suchanfrage feststellen lassen: Statt die eigene Suchanfrage direkt zu korrigieren und eine neue Query in das Suchfeld einzugeben, wird der Nutzer fortan möglicherweise erst noch ein wenig weiter nach unten scrollen, bis er oder sie die Suchanfrage noch einmal anpasst.
Kurzes Fazit zum Schluss
So weit, so gut. Trotz der eben erwähnten Punkte, sollten wir realistisch bleiben: Die Umstellung auf Continuous Scrolling für Desktop wird (voraussichtlich) weder die deutsche noch die gesamte SEO-Welt auf den Kopf stellen. Einige spannende und sicher auch überraschende Veränderungen wird das Thema allerdings sicher dennoch mit sich bringen.
Welche genau das am Ende sein werden, bleibt abzuwarten. Wir sind jedenfalls schon sehr gespannt, was da auf uns zukommt und wie sich das Ganze entwickelt, wenn es dann endlich auch hier in Deutschland heißt: Keep on scrollin', baby!
|
|
| Robots.txt: Size DOES matter 🤖 |
Wir SEOs und Webmaster kommen nicht an einer robots.txt vorbei, wenn wir der Suchmaschine sagen wollen, welche Seiten(bereiche) gecrawled werden sollen - und welche bitte nicht.
Aber hast Du Dich mal gefragt, wie groß diese Datei eigentlich ist? 🤔
Gary Illyes hat zum Thema Größe der Robots-Datei auf LinkedIn vor kurzem eine spannende Info rausgehauen, die ich noch nicht auf dem Schirm hatte.
Ein paar Wochen zuvor hatte er eine Umfrage gestartet, wie viele Bytes die robots.txt der Teilnehmer umfasst. Immerhin 8% gaben an, dass die Datei mehr als 500 kb groß ist.
Dazu kam jetzt von Gary folgender Kommentar:
"To those who said their robotstxt file is over 500kb, just keep in mind that Google only processes the first 500kb of the file."
Nur die ersten 500kb werden von Google verarbeitet. Bedeutet also:
"Basically try to put everything you mean for googlebot to see in the first 500kb and you're good."
Wie sieht es bei Dir aus? Wie groß ist Deine robots.txt? Checken kannst Du das zum Beispiel mit den Chrome Entwicklertools im "Network" Tab. Ist die Datei aus irgendeinem Grund größer als 500kb, solltest Du sicherstellen, dass die wichtigsten Informationen innerhalb der ersten 500kb stehen.
Im Normalfall solltest Du aber gar nicht erst in die Verlegenheit kommen, ein solches robots.txt Monstrum erschaffen zu müssen. Ansonsten solltest Du Dir die interne Verlinkung Deiner Website etwas genauer anschauen.
Viele weitere nützliche Infos findest Du in unserem Wissensartikel über die robots.txt.
|
|
| SEO ist, was Du draus machst |
Oft werden wir als SEOs gefragt, welches CMS oder Shop-System am besten für SEO ist. Oder welches System wir empfehlen würden. Vielleicht denkst Du es Dir schon, auch hier ist meine Antwort natürlich wie so häufig im SEO: "Es kommt drauf an". Es kommt auf Dich und Dein Business an.
Wie viele Produkte wirst Du im Shop verkaufen? Wie häufig ändern sich diese Produkte? Mit wie vielen Verkäufen rechnest Du pro Tag? Was für ein Budget steht Dir für die Einrichtung, das Hosting und die Weiterentwicklung zur Verfügung?
Diese und viele weitere Fragen entscheiden letztendlich, mit welchem System Du am besten an Dein Ziel kommen kannst.
Und dann höre ich immer wieder Sätze wie "Wir haben uns für System XY entschieden, weil dies ja schon am besten SEO optimiert ist". Dieser Satz schmerzt bei mir aus zwei Gründen: Als erstes kippt jedes mal irgendwo auf der Welt ein unschuldiges Bit einer Festplatte bei dem Begriff "SEO optimiert" und zweitens
würde ich diesen Satz so nie unterschreiben. Wie ein System optimiert ist oder wird, hängt maßgeblich von Deinen Entwicklern und deren Wissen sowie Fähigkeiten ab. Es ist richtig, dass sich ein System besser optimieren lässt als ein anderes. Oder dass wir bei Website-Baukästen auch sehr schnell an unsere technischen Grenzen gelangen. Jedoch kann und sollte man so eine Aussage nicht pauschalisieren. Für manche Shops sind Baukastensysteme und die Verwendung von bestimmten Plugins genau das Richtige, wenn beispielsweise nicht genügend hauseigene Devs zur Verfügung stehen.
SEOs sind deshalb ein wichtiges Teammitglied schon weit vor dem eigentlichen Relaunch. Gerne helfen wir Dir natürlich bei der richtigen Auswahl oder für einen kurzen Schulterblick, damit Deine nächste Systemwahl nicht zum SEO-Desaster wird.
|
|
| Data Deep Dive: Anonymized Queries & Co |
Die wohl wichtigsten Daten, die wir aktuell in der GSC zur Verfügung gestellt bekommen, sind Performance-Daten aus der Google Suche (& Discover). Die Daten werden nicht in Gänze ausgegeben, sondern aufbereitet und aggregiert. Das funktioniert insgesamt sehr gut (auch wenn neulich noch ein paar Verbesserungswünsche bei Google abgegeben wurden).
Ein paar Details zu der Aggregation rückt Google in diesem Google Search Central Blog-Beitrag aus letztem Oktober heraus: A deep dive into Search Console performance data filtering and limits.
"This post explains in detail the data available and how Google processes it, including privacy filtering and other limitations related to serving latency, storage, and processing resources."
Die 4 Metriken des Performance Reports kannst Du als SEO sicher im Schlaf aufzählen:
Klicks Impressionen CTR Position
Wie genau sie berechnet werden, wird übrigens in diesem Artikel im Detail aufgedröselt. Also zum Beispiel: Wann genau wird eine Impression gezählt? Was gibt es zu beachten, was die Agreggationsformen "by property" und "by page" betrifft? Zu diesem Thema empfehle ich auch immer gerne Behrends Wissensbeitrag (auch wenn der an ein paar Stellen schon wieder überarbeitet werden sollte *hust*)
Diese Metriken werden durch die Dir sicherlich ebenfalls geläufigen Dimensionen zur Betrachtung ergänzt:
Queries Pages Countries Devices Search Appearance
So weit, so klar. Jetzt wird es aber spannend, also Ohren spitzen:
"Both the data in the report interface and the data exported are aggregated and filtered in different ways."
Wenn man das nicht weiß oder vergisst, kann es passieren, dass man vor den Daten steht und sich auf vermeintliche Anomalien und Widersprüche keinen keinen Reim machen kann. Happens to the best of us, daher kann man es gar nicht oft genug nochmal ins Bewusstsein rufen. (Hier nochmal der freundliche Hinweis auf den oben referenzierten Artikel von Behrend, denn doppelt gemoppelt hält besser ❤️)
Außerdem werden die Daten durch zwei Faktoren eingeschränkt: Privacy Filtering (zu deutsch "Datenschutzfilterung") und das Daily Data Row Limit (aka das dezent behördlich klingende "Tageslimit für Datenzeilen").
Privacy Filtering
Weil einige Suchanfragen extrem selten sind, sind sie nicht Teil der Search Console Daten. So soll die Privatsphäre der Suchenden geschützt werden (und die Datenbank von Google vor zu rechenaufwändigen Filtern, aber Datenschutz klingt halt besser). Diese Suchanfragen werden als "Anonymized Queries" bezeichnet.
"Anonymized queries are those that aren't issued by more than a few dozen users over a two-to-three month period."
Die Anonymized Queries werden in der GSC generell mitgezählt. Aber sobald Du auf Queries filterst oder Dir die Keywords ausgeben lässt, fliegen sie aus den Daten. Das bedeutet, dass die Summe aus Brand und Non-Brand Queries niedriger ist, als das ungefilterte Gesamtergebnis.
Ein konkretes Beispiel: Für einen bestimmten Zeitraum werden für diese Property 157 Klicks reportet. Wenn wir einen Filter anwenden, der einen Query einschließt, bekommen wir für den Betrachtungszeitraum 15 Klicks. Drehen wir den Filter um und schließen den Query aus, sind es 27 Klicks. Summieren wir beide Filter-Werte auf, kommen wir auf 15 + 27 = 42 Klicks. Zu den 157 Klicks, die wir initial ohne Filter gesehen haben, beträgt die Differenz 115 Klicks. Diese 115 Klicks sind die anonymisierten Suchanfragen, die zwar in die Gesamtsumme mit eingehen, in der Filter-Ansicht aber nicht.
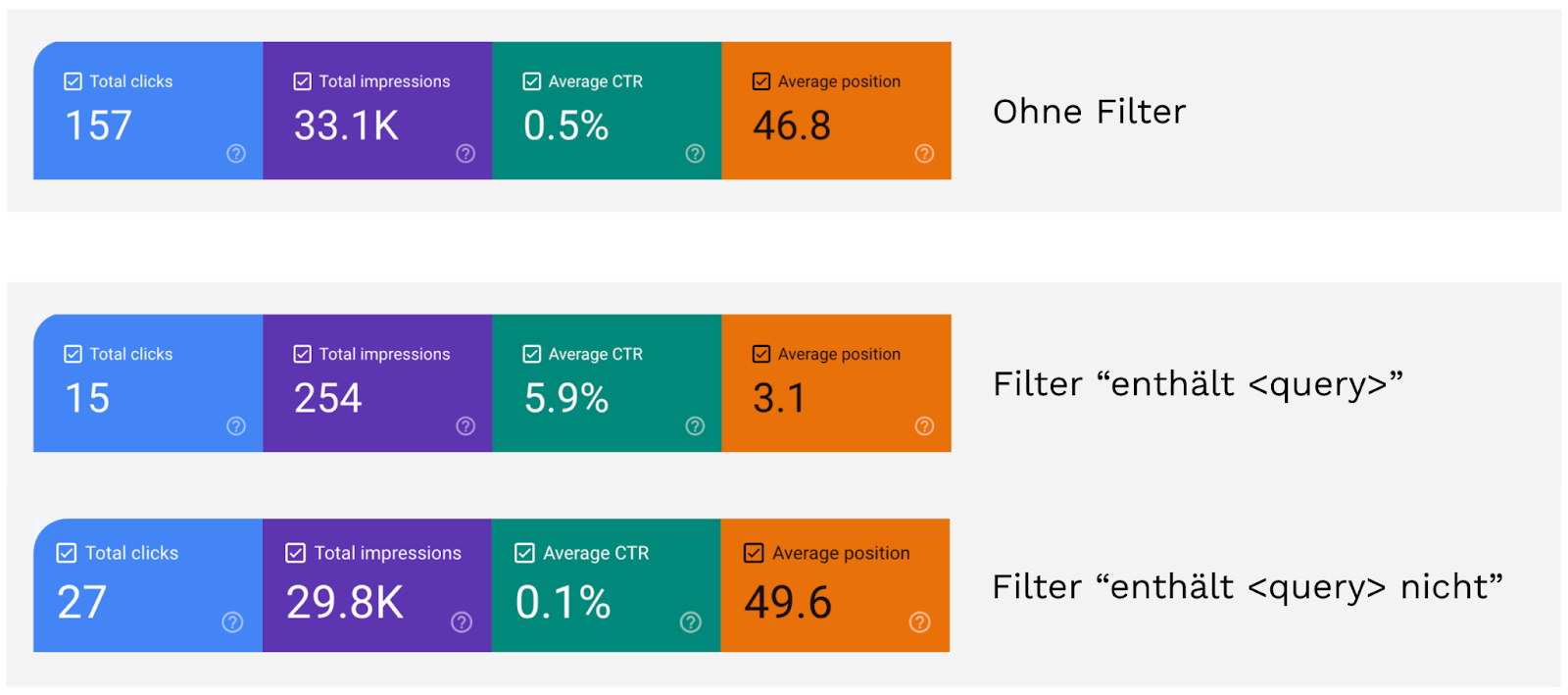
Je nachdem wie Longtail-lastig Dein Traffic ist, können diese Queries auch der Großteil Deines Traffics sein. Das bedeutet nicht, dass die Daten falsch sind, aber es ist natürlich ein blinder Fleck. Du kannst aber davon ausgehen, dass die Anonymized Queries der Longtail sind und wahrscheinlich sind es spezifische Varianten der bekannten Keywords.
Daily Data Row Limit
Aus verschiedenen Gründen stellt uns Google in der GSC nur 1.000 Zeilen zur Verfügung.
"Due to limitations related to serving latency, storage, processing resources, and others, Search Console has a limit on the amount of data that can be displayed or exported."
Über die API bekommst Du bis zu 50.000 Zeilen. Aber auch das reicht nicht immer aus. Bei großen Properties kann es sein, dass nicht der komplette Traffic darüber ausgegeben werden kann. Mittels verschiedener Subfolder-Properties ist es möglich, noch mehr Daten zu bekommen. Aber das kann sehr umständlich sein, und es sind nur Keywords und Seiten mit dem geringsten Traffic betroffen. Wichtige To Dos identifiziert man so eher selten.
Mach Dir einen Reim auf Ungereimtheiten
Wenn Du Dich also das nächste Mal durch GSC-Daten wühlst und Dir etwas merkwürdig vorkommt, dann denk daran: Vielleicht sind es die Logiken by property und by page, die Dir hier einen kleinen Streich spielen. Oder die Anonymized Queries stiften Ninja-artig Verwirrung. Falls diese fiesen Fallen keine Erklärung für Deine Fragezeichen liefern - nicht verzagen, gerne bei uns nachfragen! Bisher haben wir jedes Mysterium ergründen können.
|
|
| Knime-Vorlage die Zweite |
Vor Weihnachten haben wir Dir eine erste Knime-Vorlage unter den Baum gelegt, nun möchten wir Dir die zweite Vorlage vorstellen.
Du wertest öfters den Suchanfragenbericht der GSC aus und möchtest dabei folgende Fragen beantworten:
1. Wie hoch ist der Anteil von Longtail-Suchanfragen?
2. Wie viele Suchanfragen fallen in welchen Positions-Bereich?
3. Wie viele Suchanfragen haben einen Bezug zu Städten oder W-Fragen?
4. Wie viele Suchanfragen fallen in welchen Klicks-Bereich?
Dann kannst Du gern unsere Knime-Vorlage verwenden und dies im Handumdrehen erledigen.
Bei der Analyse, wie hoch der Anteil der Longtail Suchanfragen ist, stellen wir Dir eine Tabelle zur Verfügung, in der wir
Weiterhin gruppieren wir die Suchanfragen nach Position und Klicks. Dabei erhältst Du bei den Klicks folgende Gruppen:
< 10 Klicks 10 - 50 Klicks 51 - 100 Klicks 101 - 500 Klicks 500 - 1000 Klicks und > 1000 Klicks
Bei den Positionen gruppieren wir in Zehnerschritten.
In der Analyse, ob die Suchanfrage einen Bezug zu einer Stadt hat, gruppieren wir anhand der Top 200 Städte Deutschlands. Ein ähnliches Vorgehen wenden wir bei der Gruppierung der W-Fragen an, mit den Fragewörtern Wer, Wie, Was, usw.
Nun bleibt nur zu sagen: Viel Spaß beim Auswerten!
Du hast Anregung und Fragen zu unserer Knime-Vorlage? Dann schreib uns gern.
Wir freuen uns auf Dein Feedback!
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





