Duplicate Content
Was ist Duplicate Content?
Gemäß der Regel: "1 Inhalt = 1 URL", sollte ein Inhalt einer Website nur unter einer URL auffindbar sein. Als Duplicate Content (kurz DC genannt), bezeichnet man Inhalte im Web, die unter mehr als nur einer URL abrufbar sind. Wenn dieser Grundsatz missachtet wird, kommt es zu den Mehrfach-Aufführungen von Inhalten, unter verschiedenen URLs. Dabei wird zwischen internem und externem Duplicate Content unterschieden.
- Interner Duplicate Content: Gleiche Inhalte, die innerhalb einer Domain unter mehreren URLs zu finden sind.
- Externer Duplicate Content: Gleiche Inhalte, die über zwei oder mehr Domains verteilt und unter mehreren URLs abrufbar sind.

Googles Definition von Duplicate Content lautet wie folgt:
"Duplizierter Content besteht im Allgemeinen aus umfangreichen Contentblöcken, der anderem Content, auf derselben oder einer anderen Domain, entspricht oder auffällig ähnelt."
Dabei wird nicht davon ausgegangen, dass eine Dopplung von Inhalten böswillig oder mit Täuschungsabsicht geschieht.
Warum sollte Duplicate Content vermieden werden?
Duplicate Content verursacht verschiedene Probleme. Wenn ein Inhalt mehrfach auffindbar ist, kann der Crwaler das Original nicht indentifizieren und weiß nicht welches Dokument er ranken soll. Die Suchmaschine versucht dann über verschiedene Methoden das Original zu ermitteln. Trotzdem werden Ranking-Signale, wie zum Beispiel:
- Interne Links
- Externe Links
- Social Media Signale
aufgesplittet. Das Potenzielle Ranking wird unter mehreren URLs aufgeteilt, somit schwächen sich die Seiten gegenseitig. Man spricht von "kannibalisieren", wenn sich mehrere Seiten in den SERPs konkurrieren. Gegenüber anderen Seiten sind sie aufgrund der aufgesplitteten Signale dann im Nachteil.
Versuche Deinen Content auf einer URL zu bündeln und mit dieser ein starkes Ranking zu erzielen.

Das Worst Case Szenario wäre, dass Google die doppelten Inhalte als Spam, Täuschungs- oder Manipulationsversuch gegenüber der Suchmaschine wertet. Dann wird Deine Website im Ranking niedriger eingestuft oder komplett deindexiert. Doch das ist in der Regel nicht der Fall.

Abgesehen von den genannten Problemen, verbaucht Duplicate Content zusätzliches Crawlingbudget. Dadurch stehen weniger Crawlingressourcen für andere Inhalte zur Verfügung. Wie können Suchmaschinen Originale von Kopien unterscheiden? Während Google und Co. keine Angaben darüber machen welche Faktoren einen Inhalt als das Original kennzeichnen, gibt es einige Anhaltspunkte, die zu dieser Entscheidung immer wieder im Gespräch sind.
- Linkpopularität: Wie häufig und von wie starken Seiten wird der Inhalt verlinkt?
- Popularität der Domain, auf der die Dokumente erscheinen
- Menge der Social Signals: Zahl der Likes, Shares, Twitter Links etc.
- Alter der Dokumente
Die Suchmaschinen werden immer bersser darin Duplicate Content zu identifizieren. Trotzdem kann fortlaufend bestehender DC zu Indexierungsproblemen führen, weil nicht klar ist, welches Dokument das relevanteste für eine Suchanfrage ist. Es kann dadurch zu Wechselrankings kommen, die durch die Aufsplittung von Signalen geschwächt, anstatt auf eine URL konzentriert werden. Das wirkt sich negativ auf die Positionen in den Suchergebnissen und auch auf Traffic aus.
Wie entsteht Duplicate Content?
Duplicate Content entsteht aus einer Vielzahl von Gründen. Wie es dazu kommt, dass gleicher oder ähnlicher Content auf unterschieldichen URLs existiert, ziegen wir Dir jetzt.
Systematisch produzierte inhaltlich gleiche URLs
Am schnellsten entsteht Duplicate Content, wenn er durch ein System erzeugt wird. Das tritt häufig bei Online-Shops auf, die beispielsweise eine Sortierung für ihre Produkte nach Preis anbieten. Durch das Anpassen der Ergebnisse hängt das Shopsystem an die bestehende URL einen Paramter an. Es existieren nun zwei unterschiedliche URLs die denselben Content liefern, nur in unterschiedlicher Reihenfolge. Durch jede Filtermöglichkeit wird eine zusätzliche URL generiert und damit weiterer Duplicate Content erzeugt.
Keine einheitliche URL Struktur
Verschiedene Schreibweisen in der URL-Struktur erzeugen schnell Duplicate Content ganzer Websites.
- Gleiche Inhalte unter URLs mit und ohne Trailingslash erreichbar
https://wngmn.de/ und https://wngmn.de - Oder großgeschriebene aber auch kleingeschriebener URLs liefern identischen Content
https://Wngmn.de/ und https://wngmn.de
Auch hier ist die Ursache systematisch und nicht an einer mehrfach Nutzung des Inhalts. Zum Glück sind diese Formen von DC leicht zu beseitigen, indem allgemeine Weiterleitungen auf die korrekte, beziehungsweise die als Standard definierte Form, eingerichtet werden. In den meisten Fällen vom Webserver, zum Beispiel über die Konfiguration der .htaccess Datei bei Apache Servern.
HTTP vs. HTTPS
Das bedeutet konkret: Abrufbare Versionen von Seiten mit http und https, beispielsweise: http://wngmn.de und https://wngmn.de Hier kann potentiell eine ganze Website betroffen sein und es sollte geklärt werden, welche Version genutzt werden soll. An dieser Stelle der kurze Hinweis, dass eine verschlüsselte Version der Seite von Google bevorzugt wird.
Externer Duplicate Content durch Subdomain und Domain
Obwohl sie von vielen als gleich angesehen werden, sind beispielsweise https://wngmn.de und https://www.wngmn.de für Suchmaschinen unterschiedliche Websites. Dabei wird die Website mit dem Präfix "www" als Subdomain der einfachen wngmn.de betrachtet. Nichtsdestotrotz würden duplizierte Inhalte als externer Duplicate Content wahrgenommen werden. Auch eine mobile Version einer Website wie m.wngmn.de würde in diese Kategorie fallen und setzt daher die korrekte Auszeichnung mit rel="alternate" und Canonical-Tag voraus. Externer Duplicate Content entsteht ebenfalls durch:
- Überreste der alten Seite auf der alten Domain nach einem Relaunch
- Gescrapten Content bzw. "Content-Klau"
Wenn die eigenen Inhalte eins zu eins auf fremden Websites zu sehen sind, gibt die Möglichkeit, Urheberrechtsverletzungen bei Google zu melden und dementsprechend entfernen zu lassen.
Eine Kombination der bisher aufgeführten Punkte
Bei solch vielen Möglichkeiten für URL-Variationen, unter denen gleicher Content liegt, ist es natürlich auch möglich dass verschiedene dieser Probleme gleichzeitig auftreten. Das ist dahingehend problematisch als dass sich Inhalte direkt vervielfachen anstatt nur zu verdoppeln. URL Variationen durch verschiedene Schreibweisen:
- www/non www
- HTTP/HTTPS
- Trailingslash/Ohne Trailingslash
- Unterschiedliche Groß- und Kleinschreibung
Wäre ein Inhalt unter jeder Kombination dieser Eigenschaften erreichbar, dann gabe es 16 URLs für einen einzigen Inhalt.
Mehrfach verorteter Inhalt
Duplicate Content entsteht aber nicht immer aus Fehlern in der URL-Struktur. Manchmal ist Content aus inhaltlichen Gründen unter mehreren URLs zu finden. Zum Beispiel, wenn ein Inhalt in mehreren Kategorien passt und daher einfach in diesen abrufbar ist. Ebenfalls ein klassisches Beispiel sind Druckversionen von URLs. Der Spiegel-Artikel http://www.spiegel.de/sport/fussball/bastian-schweinsteiger-abschiedsspiel-vor-halbleeren-raengen-a-1109933.html ist auch als Druckversion verfügbar unter http://www.spiegel.de/sport/fussball/bastian-schweinsteiger-abschiedsspiel-vor-halbleeren-raengen-a-1109933-druck.html. Die wesentlichen Inhalte sind natürlich dieselben.
Gewollter externer Duplicate Content
In einigen Fällen, in den die gleichen Inhalte an mehreren Stellen im Netz auftauchen, ist das gar nicht ungewollt.
- Im Web verbreitete Pressemitteilungen
- Von Herstellern übernommene Produktbeschreibungen
- Ausschreibungen
Natürlich sollte idealerweise vor der Veröffentlichung der Inhalte gekennzeichnet sein, so dass von außen erkennbar ist, von wem das Original stammt.
Beispiele für externen Duplicate Content
1. Republishing von Bento und Spiegel Die folgende Video-Seite auf Bento http://www.bento.de/today/fluechtlinge-in-clausnitz-groelende-menge-blockiert-bus-in-sachsen-353648/ gibt es auch auf Spiegel.de: http://www.spiegel.de/politik/deutschland/fluechtlinge-in-clausnitz-groelende-menge-blockiert-bus-in-sachsen-a-1078236.html

Im Spiegel-Artikel gibt es noch zusätzliche Informationen. Trotzdem wurde mittels eines Canonicals auf der Seite von Bento auf den Spiegel verwiesen. Damit sollte der Suchmaschine verdeutlicht werden, dass bei Spiegel das Original vorliegt und Bento die Ressource ebenfalls nutzt. Hierbei handelt es sich um ein Musterbeispiel für gewollten DC. 2. Domainkonzept des Altonaer Turnverband von 1845 e.V. Der Altonaer Turverband ist bei Google mit der Domain http://atvsports.de/ zu finden. Im Impressum unter http://atvsports.de/?page_id=4638 werden weitere Seiten aus dem Internetangebot des Vereins aufgeführt:
(1) http://www.atvsports.de(Leitet auf (1a) http://atvsports.de/ weiter)(2) http://www.atv-1845.com(3) http://www.atvsport.de(4) http://www.yogasports.de(5) http://www.atvsports.org(Leitet auf (5a) http://atv-1845.de/ weiter)
Von dieser Vielzahl an Domains sind weder alle intakt, noch haben die intakten Seiten alle Inhalte. Hier ein Überblick:
- Die Domains (1) und (5) leiten auf andere Domains (1a und 5a) weiter
- Die Domains (2) und (4) haben keine Inhalte und landen mehr oder weniger im "Nichts"
- Die Domain (3) lässt sich regulär abrufen
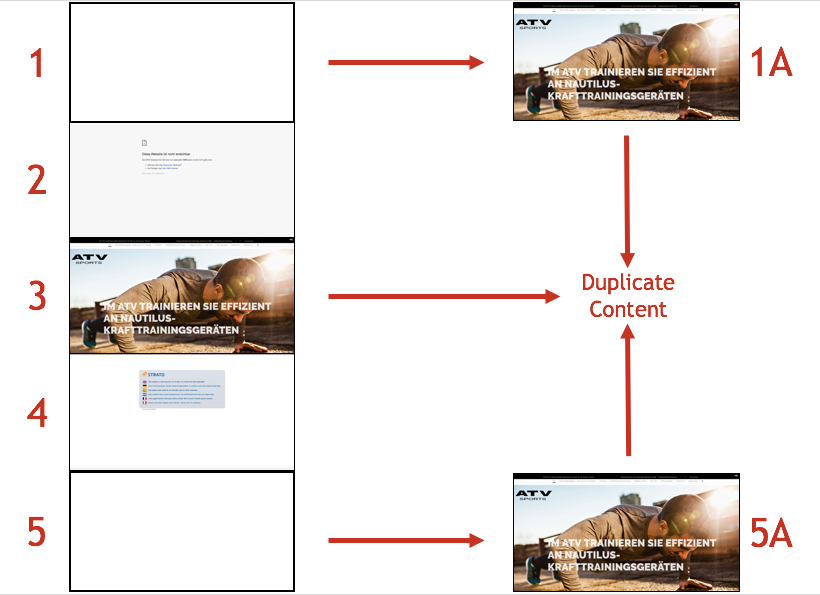
Insgesamt liefern die 3 Domains 1a (http://atvsports.de/), 5a (http://atv-1845.de/) und 3 (http://www.atvsport.de) Inhalte, die anscheinend gleich sind. Drei Websites, die Duplicate Content liefern, statt einer einzigen, starken Website. Dementsprechend gering sind beispielsweise die Sichtbarkeiten in SISTRIX:
- (1a)
http://atvsports.dehat minimale Sichtbarkeit, etwa 930 Rankings aber überwiegend nur für eigenen Namen in diversen Schreibweisen - (3)
http://www.atvsport.de- keine Keyword-Rankings in Sistrix - (5a)
http://atv-1845.de- keine Keyword-Rankings in Sistrix
Am häufigsten verlinkt wird 5a, was bedeutet, dass diese Seite am meisten von außen gestärkt wird. Weiterhin rankt die 1a aber am besten. Für ein besseres Ergebnis könnte es sich also lohnen, diese beiden zu kombinieren und zu optimieren.
Duplicate Content identifizieren
Den unliebsamen Duplicate Content zu finden kann eine Herausforderung sein, insbesondere bei größeren Websites. Glücklicherweise gibt es eine Reihe an Instrumenten und Tools, die diese Aufgabe vereinfachen.
Google Search Console
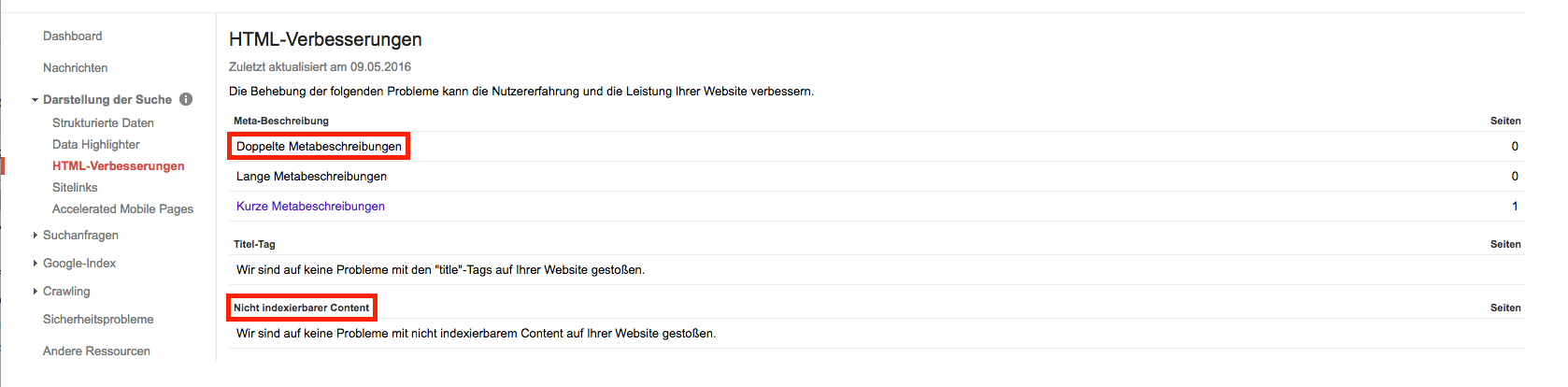
Angefangen mit der Google Search Console, die unter dem Menüpunkt "Darstellung der Suche" die Option "HTML-Verbesserungen" anbietet. Hier kann man sich einen Überblick über doppelte Page Titles und Meta-Beschreibungen der eigenen Seite verschaffen, so wie nicht indexierbare Inhalte erkennen.
Für einen schnellen manuellen Check der Inhalte seiner Seiten kann man auch in der Google Suche die 'site'-Funktion verwenden und so sehen, welche Seiten der eigenen Website für ein bestimmtes Keyword im Ranking landen. Zum Beispiel zeigt "site:wngmn.de conversions" alle Seiten auf wngmn.de, die relevant für das Keyword Conversions sind. Bei kleineren Websites ist diese Methode wahrscheinlich noch machbar, bei größeren Seiten benötigt man dafür jedoch Tools wie zum Beispiel den SISTRIX Optimizer oder den Screaming Frog SEO Spider.
SISTRIX Optimizer
Im Optimizer lässt sich eine gesamte Website auf Fehler im OnPage SEO überprüfen. Dazu legt man im Optimizer zunächst ein neues Projekt an.
Nachdem man Projektname und die zu durchsuchende Domain angegeben hat, wird die Seite automatisch geprüft. Im Anschluss wird ein Bericht ausgegeben, der zwischen Hinweisen, Warnungen und Fehlern unterscheidet. Um Duplicate Content zu finden, wählt man die Fehler. Im folgenden Menü sind die verschiedenen Fehlerkategorien aufgeschlüsselt. Hat der Optimizer ein Problem mit Duplicate Content entdeckt, wird die Kategorie hier unter "Inhalte Doppelt vorhanden" aufgeführt.
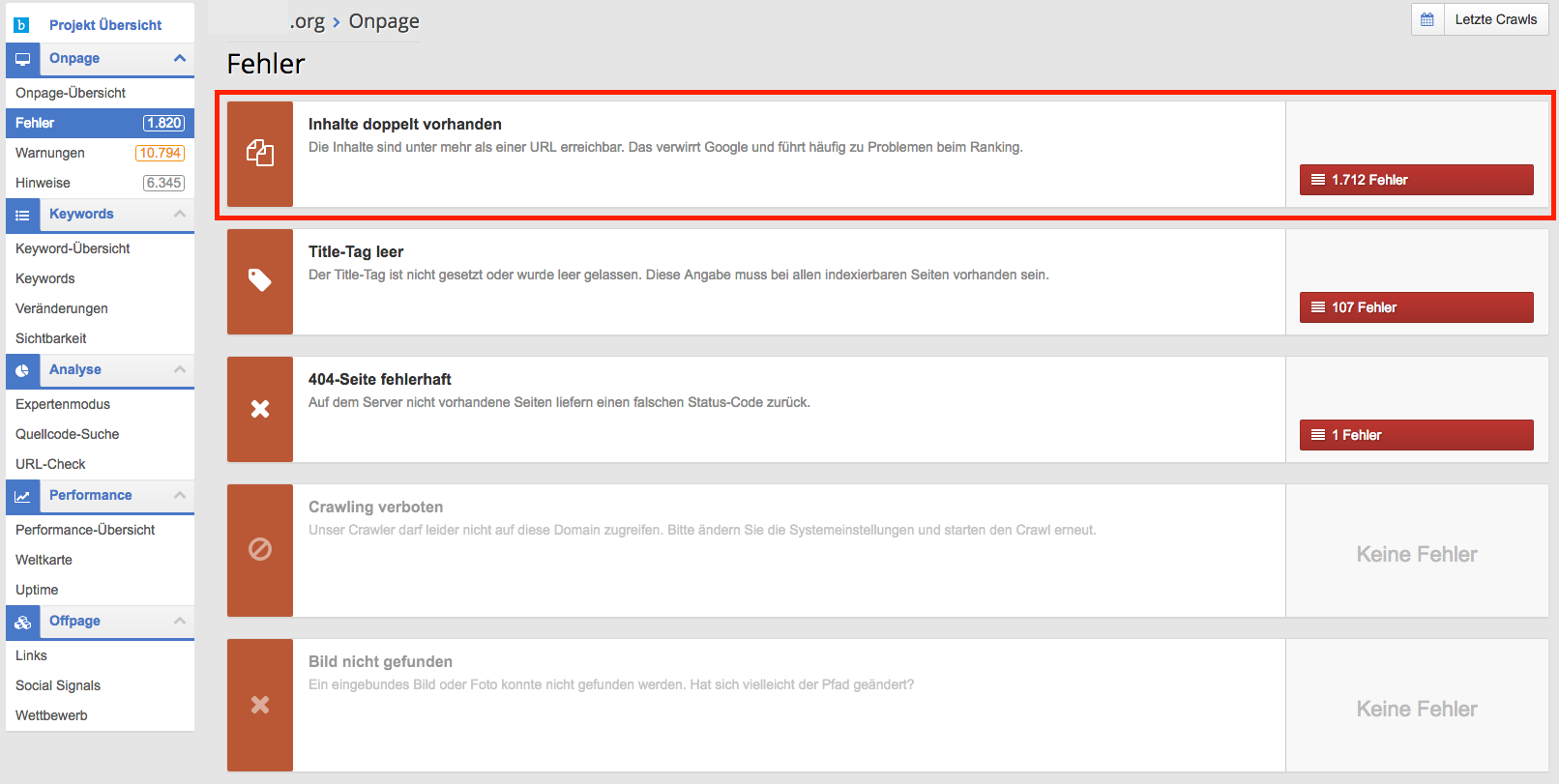
Nach einem entsprechenden Klick werden einem dann die konkreten Fälle angezeigt. Anhand der URLs, welche die doppelten Inhalte anzeigen, lässt sich in der Regel gut auf den Ursprung des Problems schließen.
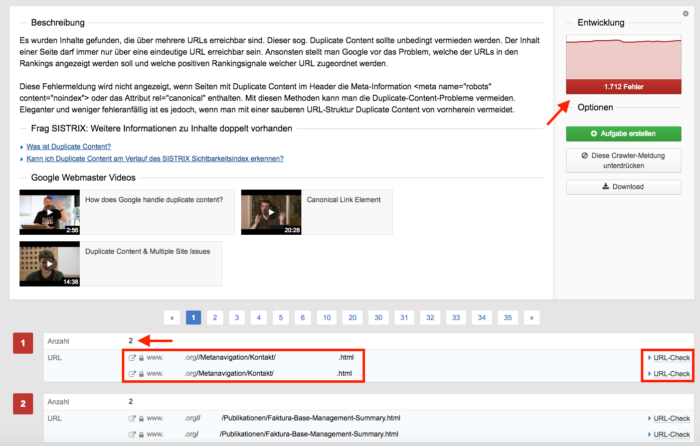
Auf der oberen rechten Seite im Optimizer wird einem zusätzlich ein Graph mit der historischen Entwicklung des Fehlers angezeigt. Nach zusätzlichen Informationen zum Thema Duplicate Content folgt dann eine Auflistung der URLs, die gleiche Inhalte ausspielen. Neben der Anzahl und den URLs gibt es außerdem die Möglichkeit, die einzelnen URLs zu analysieren. Der URL-Check geht dabei allerdings mehr auf Metadaten, Links, Ladezeiten und weiter Info ein, als auf die Thematik Duplicate Content.
Screaming Frog SEO Spider
Mit einem Crawling durch den Screaming Frog SEO Spider erhält man viele Informationen über URLs. Auch gleiche Inhalte zweier oder mehrerer URLs lassen sich identifizieren.
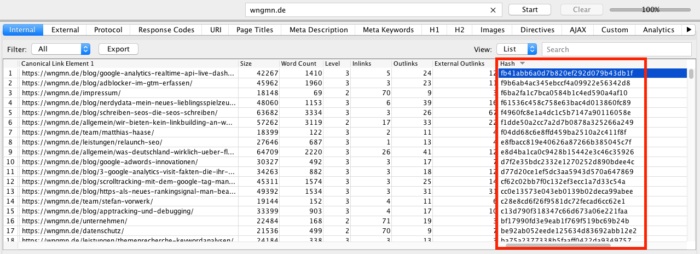
In der Informationstabelle über die URLs befindet sich, wenn man ein Stück nach rechts scrollt, eine Spalte namens "Hash". Haben in dieser Spalte zwei URLs genau den Gleichen Wert, so ist ihr Inhalt ebenfalls identisch.
Near Duplicate Content
Wenn eine Seite nicht zu 100% mit einer anderen übereinstimmt, sondern nur zu 90% Prozent, dann werden die genannten Methoden diese Fälle möglicherweise nicht entdecken. Aber nur weil nicht alles identisch ist, heißt das nicht, dass es sich bei beiden URLs um Original Content handelt. Suchmaschinen wie Google werden diese Seiten trotzdem wie Duplicate Content behandeln. Near Duplicate Content entsteht durch:
- Häufig wiederkehrende Textelemente
- Wenig oder kaum Inhalte abseits der Navigation
- Automatisch generierte Inhalte
- Doorway Pages beziehungsweise Brückenseiten
Diese Art von Duplicate Content ist etwas schwieriger selbst aufzudecken als die komplett identische, aber auch hierfür gibt es Tools. Zum Beispiel kann man mit dem von Onpage.org den Report "Near Duplicate Content" anfordern. Zu finden ist dieser in der Navigation zunächst unter "Content" und dann "Duplicate Content".
Duplicate Content vermeiden
Duplicate Content vermeiden bedeutet die Chancen seiner einzigartigen Seiten zu steigern. Um das zu erreichen, gibt es unterschiedliche Möglichkeiten. In der Regel geht es darum, der Suchmaschine zu verdeutlichen, welcher der originale Inhalt ist und wobei es sich um eine zusätzliche Variante handelt.
301-Weiterleitungen
Wenn auf einer Website bereits identische Inhalte auf verschiedenen URLs zu finden sind, dann müssen diese weitergeleitet werden. Das Mittel dafür sind 301-Weiterleitungen, sogenannten permanenten Weiterleitungen. Diese sorgen dafür, dass Suchmaschinen und Nutzer von der nicht favorisierten URL auf die Gewünschte weitergeleitet werden. Dies ist insbesondere bei den oben genannten Fällen von unterschiedlich geschriebenen oder zusammengesetzten URL seine gute Methode. Je nach Server kann eine Weiterleitung dieser Art unterschiedlich eingerichtet werden. So würde beispielsweise bei Apache der Zugriff über die .htaccess-Datei editiert werden. Sollte beispielsweise von einer http-Adresse auf die verschlüsselte https-Variante weitergeleitet werden, dann sähe der Eintrag wie folgt aus: RewriteEngine On RewriteCond %{HTTPS} off RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]
Paginierung
Gerade im Bereich von Online-Shops wird häufig mit Paginierungen gearbeitet. Also eine Filter- oder Kategorieseite, die eine große Menge an Artikeln anzeigt und deswegen in Blätterseiten mit jeweils einer gewissen Anzahl der Artikel unterteilt wird. Alle diese Seiten haben abgesehen von den angezeigten Artikeln mit hoher Wahrscheinlichkeit einen sehr ähnlichen Inhalt. Laut Google ist das in der Regel kein Problem und in den meisten Fällen kann den Nutzern das relevanteste Ergebnis angezeigt werden. Doch um sich zusätzlich abzusichern, kann einiges getan werden.
- rel="prev" und rel="next" Auszeichnungen
- Meta Robots-Tag „noindex, follow“
- Canonical Tags
Mit den Attributen rel="prev" und rel="next", die einem Link zugewiesen werden, signalisiert man, dass die aktuelle Seite Bestandteil einer zusammenhängenden Reihe von Dokumenten ist. Befänden wir uns auf der vierten Seite einer Paginierung "/page/4", könnte eine Auszeichnung mit rel="prev" und rel="next" so aussehen: rel="prev" href="/page/3/" rel="next" href="/page/5/" Es ist ein nicht zwingender Hinweis für Suchmaschinen, der in der Regel dafür sorgt, dass Suchmaschinen das gewünschte Ergebnis finden und dementsprechend den Nutzern anzeigen.
Das Canonical Tag
Einer Suchmaschine kann mitgeteilt werden, wenn es zu einer Originalseite verschiedene, sehr ähnliche Unterseiten gibt. Das kann beispielsweise bei Shops mit vielen verschiedenen Filtermöglichkeiten eine Option sein. Über das Canonical Tag ist es möglich, eine Einstufung von Seiten als Duplicate Content zu vermeiden, indem von vornherein darauf hingewiesen wird, dass es eine bestimmte Originalseite gibt, die statt der Seite, auf der sich das Canonical Tag befindet, indexiert werden soll. Beim Canonical handelt es sich eigentlich nur um einen Hinweis für eine Suchmaschine, keine Direktive. In der Regel wird dieser Hinweis aber gut von Google verstanden und befolgt. Das Canonical wird immer im HTML-Head einer Seite eingebunden. Gäbe es also eine fiktive Seite https://wngmn.de/beispielseite/mehrbeispiele deren Inhalt in großen Teilen gleich mit der folgenden URL ist https://wngmn.de/beispielseite dann würde man auf der beiden Seiten im HTML-Head das folgende Canonical-Tag einbinden: link rel="canonical" href="https://wngmn.de/beispielseite" Damit zeigt das Canonical der Originalseite auf sich selbst und dass der zusätzlichen Variante ebenfalls. So teilt man der Suchmaschine mit, dass unter der im Canonical angegebenen URL die originale Version der Seite liegt. Es sollte an dieser Stelle erwähnt sein, dass es unter Umständen aber auch passieren kann, dass Canonicals von Google ignoriert werden.
Einzigartige Inhalte produzieren
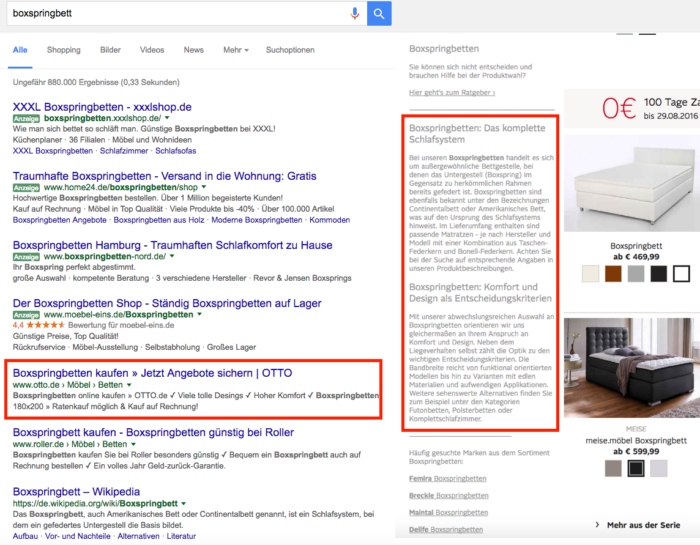
Die wahrscheinlich simpelste und zugleich aufwändigste Strategie zur Vermeidung von Duplicate Content ist, tatsächlich für jede vorhandene Seite einen eigenständigen Inhalt aufzubauen. Das bedeutet die Vermeidung von Textbausteinen und vorgefertigten Texten, bei denen nur Schlüsselbegriffe ausgetauscht werden müssen. Ein derartiger Aufbau des eigenen Contents schützt natürlich nicht vor systematischen Fehlern wie zum Beispiel URLs mit und ohne Trailingslash. Gerade für größere Websites und Onlineshops stellt dies eine monumentale Herausforderung dar, die aber keineswegs unmöglich ist. Ein Beispiel für die erfolgreiche Implementierung von Beschreibungstexten ist die Kategorieseite für Boxspringbetten von Otto.de. Einzigartige Beschreibungstexte schlagen sich dann auch positiv in den Rankings wieder.
Weitere Ressourcen zum Thema Duplicate Content
- Keine oder nur wenige eigene Inhalte - Google Search Console Hilfe
- Duplizierter Content - Google Search Console Hilfe
- How does Google handle Duplicate Content? - Video mit Matt Cutts
- .htaccess Konfiguration bei Apache Servern
--
Hat Dir der Artikel gefallen?
Neue Artikel, Updates zu unseren Artikeln und Artikel von anderen Stellen wir regelmäßig unserem Newsletter.
Beispielausgaben und Anmeldung findest Du unter Wingmen-Newsletter