Infinite Scrolling – Die SEO-Guideline zur richtigen Umsetzung
Durch Infinite Scrolling werden Inhalte und Navigationselemente auf Basis des Scrollingverhaltens des Users dynamisch nachgeladen.
In vielen Fällen wird hierdurch eine einfachere und nahtlosere Nutzererfahrung angeboten. Im Gegensatz zu einer klassischen Paginierung werden Inhalte nicht auf einzelne HTML-Dokumente aufgeteilt. Durch das Nachladen bei Scrolling entfällt das ständige Neuladen von Dokumenten.
Infinite Scrolling bietet sich an für Listenformate, wie Artikelübersichtsseiten in redaktionellen Portalen oder auf Kategorieseiten in Shops. Die größte Herausforderung aus SEO-Sicht ist die eingeschränkte Crawlbarkeit, die dazu führen kann, dass Suchmaschinencrawler nicht alle in den Listen verlinkten Seiten finden:

Weder Googlebot noch andere bekannte Crawler lösen verlässlich Scrollevents auf der Website aus und können das Nachladeverhalten des Infinite Scrollings daher nicht wie ein menschlicher Nutzer nachvollziehen. Sie sehen nur die Listenelemente (Artikel, Produkte, …), die unmittelbar beim initialen Laden der Seite verlinkt sind.
Fallback: Paginierung
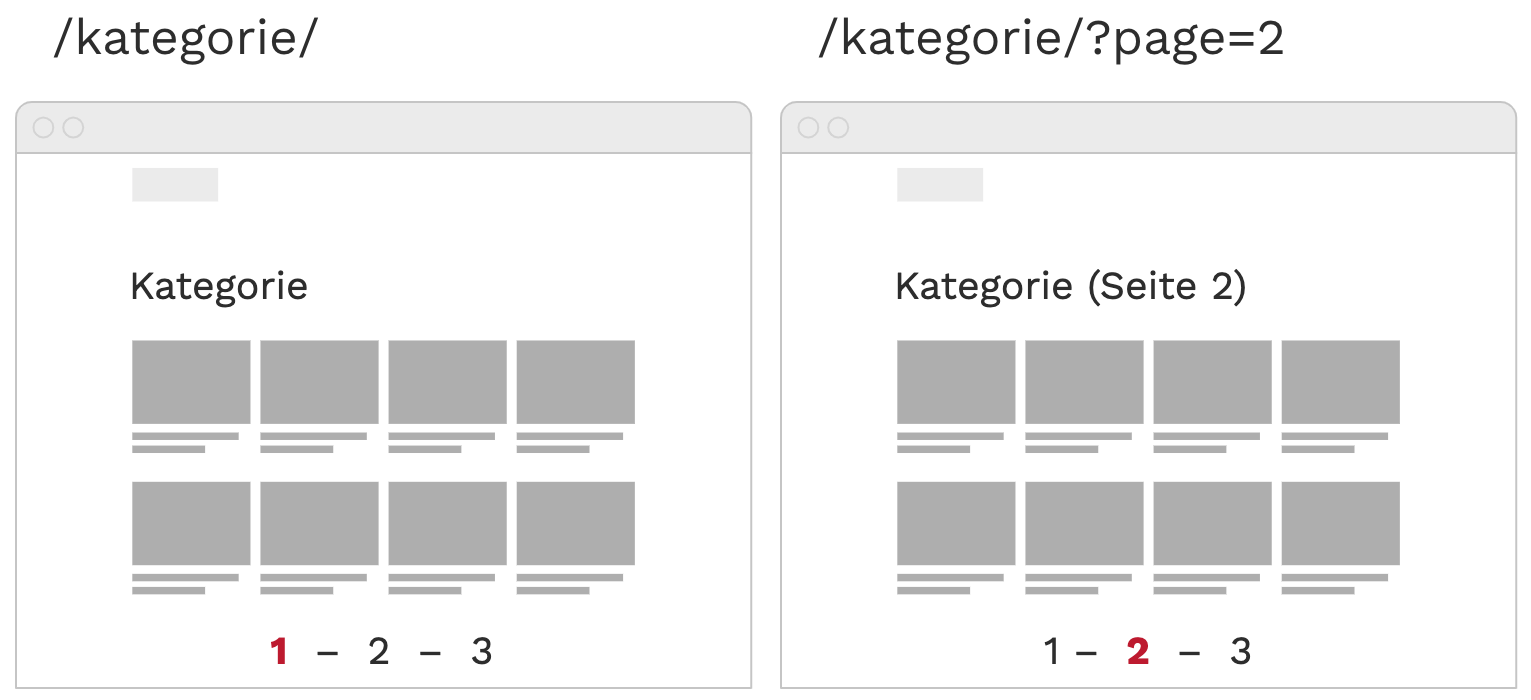
Um Suchmaschinencrawlern und Nutzern mit deaktiviertem JavaScript trotzdem eine Möglichkeit zur Navigation durch die komplette Produktliste zu geben, sollte ergänzend zum Infinite Scrolling eine Paginierung eingerichtet werden: Es wird eine bestimmte Anzahl Produkte festgelegt, die pro Seite angezeigt werden, beispielsweise 20. Bei insgesamt 100 Produkten in der Kategorie und gleichmäßiger Verteilung ergäben sich so 5 Seiten:
https://www.domain.de/kategorie
https://www.domain.de/kategorie?page=2
https://www.domain.de/kategorie?page=3
https://www.domain.de/kategorie?page=4
https://www.domain.de/kategorie?page=5Innerhalb dieser paginierten Seiten gibt es keine Überschneidung der gelisteten Produkte, d. h. ein Produkt ist immer nur auf einer dieser Seiten verlinkt.

Am Seitenende werden in einem klassischen Paginierungselement alle in der Kategorie verfügbaren Paginierungsseiten verlinkt:
<a href="https://www.domain.de/kategorie">1</a>
<a href="https://www.domain.de/kategorie?page=2">2</a>
<a href="https://www.domain.de/kategorie?page=3">3</a>
<a href="https://www.domain.de/kategorie?page=4">4</a>
<a href="https://www.domain.de/kategorie?page=5">5</a>Wird eine URL mit Paginierungsparameter ?page=… aufgerufen, wird sie über das Robots Meta-Tag
<meta name="robots" content="noindex, follow">als nicht indexierbar markiert, um sie von der Indexierung auszuschließen. Lediglich die erste Seite, die stets ohne Parameter verlinkt wird, ist indexierbar
<meta name="robots" content="index, follow">
Damit ist sichergestellt, dass die erste Seite das primäre Rankingziel bleibt, die Produkte auf den nachfolgenden Seiten aber trotzdem per Crawling gefunden werden können. Um sicherzugehen, dass die URL der ersten Seite konsistent ohne Parameter verlinkt wird, sollte der page=1 Parameter per HTTP Statuscode 301 auf die parameterlose Variante weiterleiten: /kategorie?page=1 → /kategorie. Die Produkte der aufgerufenen Seite werden bereits mit dem initialen Seitenaufruf ohne JavaScript direkt im HTML ausgeliefert, um möglichst früh für den Nutzer zur Verfügung zu stehen. Scrollt der Nutzer, werden die nächsten Produkte über eine API nachgeladen. Um den Datentransfer zu minimieren empfehlen wir, ausschließlich die benötigten Produktdaten z. B. per JSON zu laden. Das HTML, das für die Darstellung der Produktkacheln benötigt wird, sollte dann daraus clientseitig generiert werden.
Beispiele:
https://www.domain.de/kategorie: Produkte 1-20 im initialen HTML
https://www.domain.de/kategorie?page=2: Produkte 21-40
https://www.domain.de/kategorie?page=3: Produkte 41-60
…
Ruft der Nutzer direkt eine Paginierungsseite auf, sollte er gleichermaßen hoch scrollen können, um vorherige Produkte zu erreichen:
Insbesondere bei sehr langen Produktlisten wird es für den Nutzer schnell frustrierend, bei der Navigation
Kategorie → Produkt → zurück zur Kategorieüber den Zurück-Button des Browsers an einer anderen Stelle zu landen als die, die er vor dem Klick zum Produkt hatte – im schlimmsten Fall wieder ganz oben und der gesamte Scrollvorgang müsste wiederholt werden. Stattdessen sollte beim Scrolling über die HTML5 history API der Browserverlauf des Users mit pushState und/oder replaceState so bearbeitet werden, dass sich während des Scrollings die URL im Browser ändert.

Vorteile: a) Nutzer können Produktlisten-URLs mit Freunden teilen und dabei direkt auf bestimmte Scrollpositionen verlinken b) Nutzer gelangen nach dem Klick auf eine Produktseite wieder an ihre vorherige Scrollposition zurück. Mit fortlaufendem Scrolling ändert sich also die URL von
https://www.domain.de/kategorie
zu https://www.domain.de/kategorie?page=2
zu https://www.domain.de/kategorie?page=3
usw.
und umgekehrt bei Scrolling zurück nach oben.
Weitere Informationen zur HTML5 history API auf CSS-Tricks.com
Praxisbeispiel
Wir empfehlen http://scrollsample.appspot.com/ als Praxisbeispiel dieser Guideline.
--
Hat Dir der Artikel gefallen?
Neue Artikel, Updates zu unseren Artikeln und Artikel von anderen Stellen wir regelmäßig unserem Newsletter.
Beispielausgaben und Anmeldung findest Du unter Wingmen-Newsletter