|
Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #91
|

|
|
🤹 Achtung, der kleine SEO möchte aus dem Bällebad abgeholt werden!
|
|
Sooo viel Tolles in nur einer Woche! Ich fühle mich wie SEO im Wunderland. Nicht nur gibt es eine Chance auf ein
"echtes" Random
, verpixeltes Zeug lässt sich
entzaubern
und der
100ste Geburtstag von Chrome und Firefox
steht an (und lässt Deine User-Agent-Detection möglicherweise kaputtgehen), nein auch in Punkto SEO war Einiges los:
-
Anita defibrilliert den Googlebot
-
Meine Wenigkeit hat ein schickes BERT-Erklärbär-Video von Google aufgetan und 2-3 Anmerkungen dazu verbrochen
-
SEO-Biologe Behrend vermisst royales Geflügel
-
Johan legt klassische SEO-Walzer in der Google Search Console auf und
-
Caro hat den friendly SEO-Reminder der Woche für Dich
Tja, und als wäre das noch nicht genug, gibt es auch noch Termine, Termine, Termine!
Viel Spaß beim Lesen,
Deine Wingmen
|
|
|
My Googlebot skipped 🎶 skipped a beat
|
|
Hattest Du letzte Woche mal einen Blick in den Crawl Stats Report Deiner GSC-Properties geworfen? Dann ist Dir sicherlich auch aufgefallen, dass der Googlebot sich offenbar
einen Tag Urlaub
gegönnt hat. Das ist weder Jaimie Alberico entgangen, noch eine Reihe anderer SEO-Menschen, die
SE Roundtable zusammengetragen hat
.
Ich hab hier einmal einen Screenshot aus unserer Wingmen-Property für Dich reingepackt. Bei uns ist die Lücke am 09. Februar:
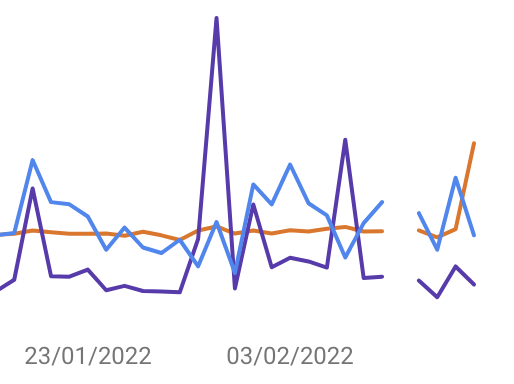
Noch deutlicher wird es in diesem GIF, das ich mir von Barry Schwartz ausgeliehen hab, in dem die Daten für den 08. Februar fehlen:
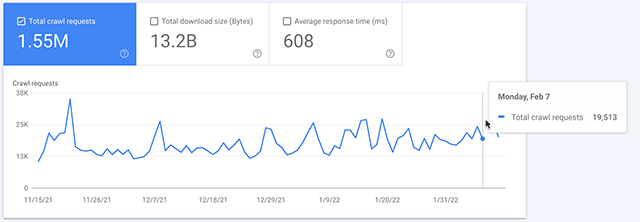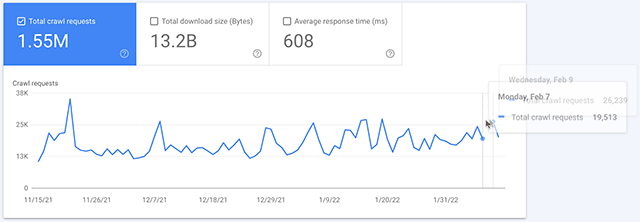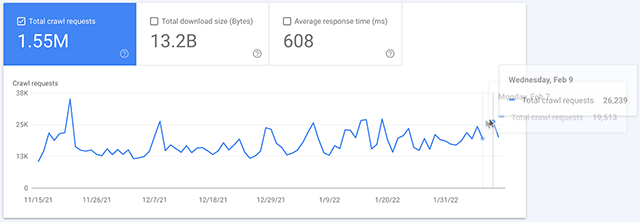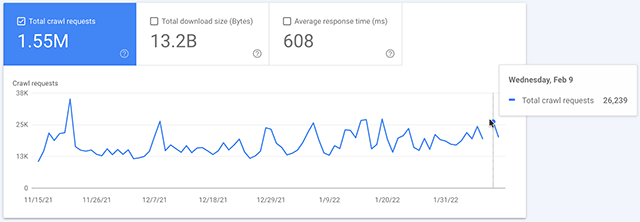
In einigen Properties scheint der 08. Februar betroffen, in anderen der 09. Februar. In allen von mir geprüften Properties war es das spätere der beiden Daten.
John Müller
sagt dazu folgendes:
"If there's a gap in the graph like this, it's due to not having a datapoint for that time. If the graph went down to 0 during that time (no gap), that would be due to not crawling. So in short, you can ignore these gaps -- they're not a sign of a problem on your end."
Also keine Panik, es ist kein kollektiver Fehler seitens der SEO-Welt aufgetreten. Einfach ruhig bleiben und weitermachen. Und siehe da, wenige Tage nach dem die Lücke aufgefallen ist,
wurden die fehlenden Daten nachgezogen
:
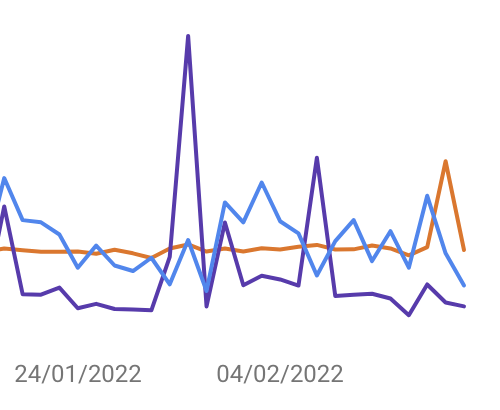
Erst Ende November letzten Jahres hatte es bereits einen
kleinen Schluckauf
gegeben. Der konnte aber schon am Folgetag beseitigt werden.
Aber nicht nur im Crawl Stats Report ist es gerade etwas ruckelig. Zwischen dem 01. und 03. Februar gab es ein "logging issue" im Performance Report, siehe
Data Anomaly Doku von Google
und im begleitenden
Artikel von SE Roundtable
wird ergänzend auf weitere Ausfälle aus der jüngsten Zeit verwiesen.
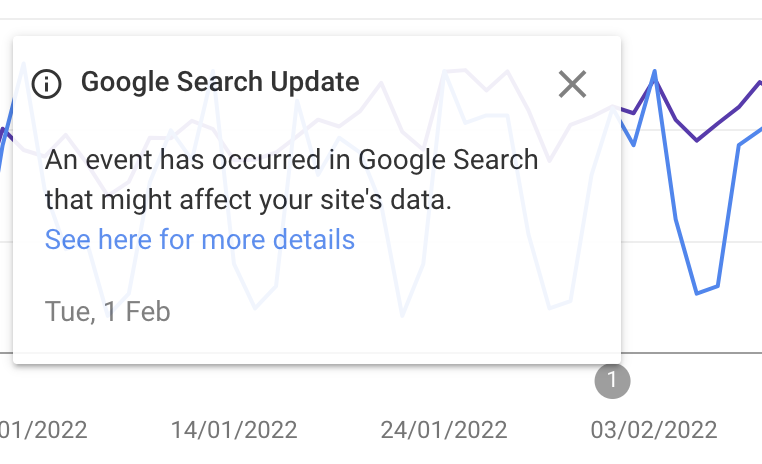
"Performance metrics suffered a logging issue on analytics for Search, Discover, and Google News. As a result, you may see some discrepancies in your performance data during this period. This is only a logging issue; it does not reflect a change in either user behaviour or search results on Google."
Gut zu wissen, dass es nicht an uns, sondern an Google liegt. Und auch, dass man innerhalb kürzester Zeit ein klärendes Feedback seitens Google erhält, wenn man über Ungereimtheiten stolpert. Trotzdem kann das hier und da erstmal für einen kleinen Schrecken sorgen.
|
|
|
BERT bringt brillante Besserungen in die Buchstabensuppe
|
|
Google möchte, dass wir BERT besser verstehen und hat ein sehr gutes
Video
zu dem Thema erstellt. Nicht nur für Neulinge ein Must See:

Eine kleine Zusammenfassung für Dich:
-
Kontext, Tonalität und Intention sind für Menschen in der Regel klar, für Maschinen aber nicht
-
Für die Suche ist es wichtig, nicht nur die Sprache zu verstehen, sondern eben auch, wie die Wörter zusammenhängen und welche Bedeutung sich aus ihrer Kombination ergibt
-
Google wird immer besser darin, diese Nuancen, die für die meisten von uns intuitiv sind, zu verstehen; dabei sind sogenannte Bidirectional Encoder Representations from Transformers, oder kurz BERT, eine enorme Unterstützung
-
Mit Hilfe von BERT schafft Google es immer besser, Sprache zu verarbeiten und in ihrem Kontext zu verstehen
-
Während früher bei der Suche vor allem der Fokus auf wichtig erscheinenden Worten lag und die Ergebnisse darauf aufbauend herausgesucht wurden, erhalten so eher kleine und unscheinbare Wörter wie "für" mehr Bedeutung, da sie als Verbindung zwischen einzelnen Begriffen relevant sind, um Kontext zu erfassen
-
Es geht also darum, nicht nur Wörter zu kennen, sondern ihre situativ bedingte Bedeutung zu verstehen
-
Wie genau man so ein Modell trainiert, wird im Video erklärt

-
So können zunehmend komplexere Suchanfragen immer besser verstanden werden
Long story short, im Grunde geht es um die Frage:
Welche Begriffe bedeuten in welchem Kontext was?
Ist mit "Bank" gerade ein Geldinstitut 💰 gemeint oder eine Sitzgelegenheit 🪑? Geht es bei "Jaguar" um einen schnittigen fahrbaren Untersatz 🚗 oder eine ziemlich schnelle, große Katze 🐈?
Kai Spriestersbach hat die ganze
BERT-Kiste
vor einer Weile übrigens mal genauer aufgeschrieben, falls Du nochmal tiefer reinlesen möchtest.
|
|
|
Schwarze Schwäne muss man richtig messen
|
|
Als
Schwarze Schwäne
werden sehr unwahrscheinliche, aber mögliche Ereignisse bezeichnet. Als SEOs müssen wir uns damit auseinandersetzen. Das ist der Grund, warum wir A/B-Tests durchführen.
Will Critchlow und sein SearchPilot-Team haben
daraus sogar einen sehr spannenden Newsletter gebaut
, in dem
sie immer wieder spannende Tests aus ihrer täglichen Arbeit zeigen
(auch wenn man sich oft mehr Details wünschen würde).
Jean-Christophe Chouinard hat jetzt bei OnCrawl untersucht,
wie gut eigentlich die Ergebnisse von CausalImpact sind
. CausalImpact ist eine Machine Learning Library von Google, die oft genutzt wird, um Kausalität (= ursächlichen Zusammenhang) nachzuweisen.
Wir finden diese Punkte sehr wichtig. Vielleicht hast Du (wie einige unserer Kunden) ein eigenes Test-Setup und Auswertung mit
CausalImpact
? Vielleicht machst Du es wie wir und
nutzt meist Ryte für die A/B-Tests
, weil es wesentlich einfacher ist? Vielleicht nutzt Du etwas anderes? In jedem Fall solltest Du Dir diesen Post einmal anschauen.
Die wichtigsten Punkte, auf die wir auch immer achten:
-
Wenn Deine Domain aus verschiedenen Gründen (Corona, Relaunch, heftige Bugs) Schwankungen unterliegt sind die Ergebnisse wenig verlässlich
-
A-Gruppe vs. B-Gruppe funktioniert besser als die gleiche Gruppe Vorher vs. Nachher zu testen
-
Die Gruppen müssen (!) vergleichbar sein
-
Je größer die Änderungen, desto besser die Ergebnisse
-
Im Artikel nicht so richtig intensiv herausgearbeitet: Auf welche Metrik wird unsere Hypothese eigentlich genau wirken?
Eine schöne Erinnerung: Nicht immer muss es ein A/B für SEO sein. Manche SEO-Ergebnisse lassen sich auch über klassische User-A/B-Tests testen. Und deren Reliabilität ist deutlich größer.
|
|
|
In der GSC ist wenig wie es scheint
|
|
In der letzten Woche hatte ich einen Klassiker doppelt auf dem Tisch: Die Zuschreibung der Klicks in der GSC zur Canonical-Version.
In beiden Fällen sieht es meist nur so aus.
Denn die GSC macht etwas sehr sinnvolles: Sie schlägt
seit nunmehr 3 Jahren
die Klicks der führenden Variante eines Duplikats-Kreises zu. Wenn ich also legitimen DC habe (beispielsweise AMP oder Ländervarianten der gleichen Sprache), dann werden Impressions und Klicks immer der von Google als Canonical identifizierten Variante zugeschlagen.
(Mehr dazu in der Search Central.)
Das ist sinnvoll, weil es ja letztlich um die Analyse der Performance eines Inhalts geht.
Das macht einen aber wahnsinnig, wenn es um die Analyse der Performance einer URL geht.
Bei AMP ist das noch relativ einfach. Denn schließlich kann ich einfach die Anzeige des Treffers als AMP in den meisten Berichten filtern und damit prüfen, ob die korrekte URL mobile angezeigt wird oder nicht. Und AMP wird recht gut in den Coverage-Reports geklärt.
Bei HREFLANG sieht es anders aus (insbesondere Cross Domain, aber auch auf einer Domain). Hier ist es nicht möglich, in der GSC zu identifizieren, ob Nutzerinnen und Nutzern die in ihrem Land korrekte Variante angezeigt wird. Denn die Klicks werden immer auf die führende Variante gezählt. Zusätzlich werden sie immer im Fehlerbericht „Google hat ein abweichendes Canonical gewählt" aufgeführt.
Damit sieht es immer so aus, als wäre mit den Canonicals etwas falsch.
Richtig prüfen kann man das nur durch die Betrachtung der Suchergebnisse in den jeweiligen Ländern. Also beispielsweise indem man in SISTRIX einen Vergleich der Sichtbarkeit der DE/AT/CH-Varianten in den jeweiligen Länderindizes prüft.
Individuelle Ergebnisse kannst Du natürlich auch beispielsweise mit Hilfe einer regionalisierten Abfrage prüfen (bspw. mit
https://valentin.app
vom großartigen
Valentin Pletzer
).\
Was wir uns hier von der GSC wünschen, sind klare Filtermöglichkeiten. Beispielsweise explizit nach angezeigter URL.
Aber natürlich ist das nicht der einzige Filter, den wir uns wünschen
.
|
|
|
18 SEO-Reminder und Tipps der Woche
|
|
In den
Google SEO Office Hours vom 18.02.
hat John Mu wieder einige Fragen beantwortet. Hier kommt eine Liste mit 18 nützlichen SEO-Remindern und Tipps für Dich:
-
Ob wenige starke oder viele spezifische Seiten für Dich sinnvoll sind, hängt stets von der Strategie ab.
-
Probiere das Einpflegen von Produktrezensionen einfach aus, als ewig zu versuchen zu analysieren, ob Google diese nutzen wird.
-
Es gibt keinen EAT Score, sondern nur indirekte Zusammenhänge. Primärer Zweck von EAT ist immer noch das Verständnis für die Qualität des Contents einer Seite.
-
Kostenfreie SSL-Zertifikate sind vollkommen ausreichend - Da gibt es keinen Unterschied zwischen kostenpflichtigen und kostenfreien. Gültig ist gültig.
-
Mehrfache Auszeichnung des gleichen JobPosting Markups auf der gleichen Domain oder auf mehreren Subdomains sollte keine Probleme darstellen. John wäre überrascht, wenn es eine solche Regel gäbe, dass ein JobPosting nur einmal pro Website gelistet werden sollte.
-
Google versucht verschiedenste Listen (ob Bilder oder HTML-Seiten) zu deduzieren und bei gleichen Inhalten den Inhalt nur einmal und nicht mehrfach anzuzeigen.
-
Gleicher Content als HTML und als PDF werde nicht als Duplicate Content gewertet und beide können in den Suchergebnissen angezeigt werden (wenn beides indexierbar).
-
Bei mehreren Seiten mit Kommentaren zum selben Thread und verschiedenen Sortierungsmöglichkeiten (neueste, meist gevotete, etc.) würde Google vermutlich auf die kanonische Default-Sortierung zurückgreifen. John schließt aber auch nicht aus, dass Google hier hin und wieder auch die Seiten mit anderen Sortierungen crawlen könne, um auszuprobieren (Canonicals könnten dort ja auch anders gesetzt sein). Indexiert werden aber sicherlich die Default-Seiten, meint John.
-
Google nutzt beim Rendering einen sehr hohen Viewport
(als hätte man einen sehr langen Screen) und kann dadurch einen Teil des durch Infinite Scrolling sichtbar werdenden Contents rendern und indexieren. Dies hängt aber auch davon ab, wie das Infinite Scrolling implementiert ist und muss auch nicht zwingend den gesamten Content umfassen. (Tipp von John: Mit dem Inspection Tool prüfen, wie viel Google tatsächlich rendert).
-
Es gibt für Google kein bestimmtes vorgegebenes Verhältnis zwischen indexierbaren und nicht indexierbaren URLs einer Domain. Wenn es möglich ist, Qualität des Contents auf wenigen Seiten zu konzentrieren, seien diese wenigen Seiten im Schnitt stärker. Vor allem für neue Websites, meint John.
-
Die Referring Page im Inspection Tool in der GSC brauchst Du nicht zu ernst zu nehmen: Es sei nicht relevant, welche Seite als Referring Page steht. Um zu verstehen, woher Google manche Seiten kennt, die eigentlich nicht gefunden werden sollten, kann Dir die Referring Page im Inspection Tool natürlich gut Aufschluss geben.
-
Crawling Rate von Google ist abhängig von der Wichtigkeit einer Website und der Notwendigkeit, Content up to date zu halten sowie von technischen Bedingungen wie die Overall Response Time to Requests und Anzahl an Server Errors (John appelliert, eher auf diese beiden Aspekte als auf die Ladezeiten der Seiten im Browser schauen, wenn es um das Crawling-Verhalten geht).
-
Verringertes Crawling durch Google kann auch mit dem Server zusammenhängen, auf welchen eine Website gehostet wird: Wenn der Server zum Beispiel regelmäßig überladen ist, werde Google Websites mit solchen Server eher weniger crawlen, um keine Probleme zu verursachen.
-
Du kannst
in den Einstellungen der GSC eine Crawl Rate spezifizieren
, welche Google möglicherweise wahrnimmt und berücksichtigt. Diese Funktion sei aber eher praktikabel, wenn man das Crawling der Website reduzieren möchte, nicht um das Crawling anzukurbeln, da dort lediglich eine Maximal-Angabe möglich ist.
-
Unerklärliches Crawling-Verhalten in der GSC zu melden ist immer sinnvoll, damit Google weiterhin das Crawling und die Bots verbessern kann.
-
Schlechte CTRs für bestimmte Seiten einer Domain beeinflussen die CTR für die übrigen Seiten der Domain nicht.
-
Du kannst in der GSC URL-Pfade (durch Erstellung einzelner URL-Properties) den jeweiligen Ländern zuweisen, um Google zu helfen, Deine internationale Website besser zu verstehen.
-
Bei merkwürdigem Crawling-Verhalten kann es Dir helfen, einmal selbst Deine Website zu crawlen, um detaillierter zu schauen, wie sich Deine Website crawlen lässt und woran es vielleicht hapern kann.
|
|
|
Termine, Termine, Termine
|
|
Außerplanmäßig gibt's die Februar-Ausgabe des SEO Meetup Hamburg erst diese Woche. Heute Abend startet der Stream bei YouTube wie immer um 19:00 Uhr. Bist Du dabei?
Hier geht's zur Anmeldung!
Und wo Du gerade so fleißig beim Anmelden bist... schau doch auch gleich hier in der neuen
Discord-Community WorldOfWux
vom Marcus vorbei und wenn dann noch Zeit ist... sichere Dir Dein um satte 15% rabattiertes
SMX-Ticket
mit dem Code WNGMNSMX.
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an
[email protected]
oder
ruf uns einfach kurz an:
+49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|




