|
Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #59
|

|
|
👖 Blau, blau, blau sind alle meine Kleider…
|
|
Donnerstag hatten wir Geburtstag. Wir alle Wingmenschen zusammen. Den Achten.
Vielleicht warst Du bei unserer großen Sause zum fünften Geburtstag an unserem Hangar im Anckelmannsplatz dabei. Vielleicht hast Du uns schon vorher mal besucht in unserem Tower am Bahnhof Altona. Und ganz vielleicht kennst Du uns noch, wie wir an unseren Schreibtischen zu Gast zwischen den Mitarbeitern von Sohomint saßen.
Was Du mit Sicherheit aber nicht über uns weißt, ist die Geschichte unseres Logos. Unser Logo war nämlich bis zum Tag der Gründung blau.

Glücklicherweise hatte meine Frau Sophie rechtzeitig den Hinweis, dass sie das an das Hermes-Logo erinnert.

Kurz bevor wir dann tatsächlich gegründet haben, musste Florian dann noch mal alles bunt anmalen.
Mit dem roten Logo haben wir dann letzte Woche gefeiert:
Heute hat Anita sich Gedanken zum FAQ-Markup gemacht. Nora diskutiert das Aussperren böser Bots. Heiko hat wieder ein Update zu FLoC. Nils zum finalen Stand des Tippspiels (ich hab Flo eingeholt. yay.). Und Mattia hat uns die erste korrekte Antwort zum Quiz letzte Woche geschrieben.
Falls das noch nicht genug ist, haben wir auch unser
angekündigtes Whitepaper zu internationaler Suchmaschinenoptimierung veröffentlicht
(auch wenn noch ein paar Illustrationen fehlen).
Für heute gibt es noch eine ganz besondere Empfehlung für die Mittagspause: Um 12 Uhr sind wir mit den Kollegen von t3n zu Gast bei Marcus Tandler und Alexander Breitenbach.
Da diskutieren wir die kräftig roten Core-Update-Zahlen von t3n, sowie unseren Maßnahmenplan für eine Core-Rektur dieser Entwicklung. Den Stream kannst Du auf den gängigen Kanälen von Ryte (
Twitter
,
Youtube
,
Facebook
,
LinkedIn
) verfolgen.
Bis dahin aber viel Spaß bei Lesen
|
|
|
Mehr zum “2 FAQs per Snippet”-Limit
|
|
Vor 2 Wochen hatte ich ein bisschen was zu verschiedenen Updates seitens Google zusammengeschrieben. Ganz kurz und bündig natürlich ;)
Unter anderem ging es auch um das neu eingeführte
Limit von 2 Fragen in FAQ-Rich Snippets
.
Brodie Clark
befasst sich mit dem Thema schon seit einer Weile intensiver und hat die Veränderungen seit dem Launch des Features im Mai 2019 im Blick. Wusstest Du beispielsweise, dass die Anzahl der Snippets mit FAQ-Erweiterungen auf 3 limitiert wurde? Das heißt wenn Du auf der Position 4 rankst mit Deiner Seite und alle vor Dir liegenden Ergebnisse haben ein FAQ-Enhancement, dann gehst Du leider leer aus. Hintergrund dafür sehr wahrscheinlich: Die SERP nicht bis ins Unendliche aufblähen.
Über diesen und weitere Filter berichtet
Brodie hier
. So hat er auch festgestellt, dass die FAQ-Erweiterungen exklusiv für die erste Ergebnisseite genutzt werden. Wenn Du also mit Deiner Seite auf Platz 11+ liegst, wirst Du auch in diesem Fall keine entsprechende Erweiterung Deiner Snippets erhalten. Erst wenn Du auf die erste Seite vorgedrungen bist - und es vor Deinem Ergebnis nur maximal 2 andere Wettbewerber mit FAQ Rich Snippet Feature gibt.
In einem weiteren Experiment hat Brodie sich mit dem Thema HTML befasst: In den Antworten kann HTML genutzt werden, zum Beispiel kannst Du Dinge hervorheben oder Links einbinden. In der Frage ist das nicht möglich.
Ebenfalls eine spannende Erkenntnis: Wenn es eine Google My Business / GMB Integration gibt, gibt es - zumindest auf Mobilgeräten - keine FAQ.
Seit Mitte Juni gibt es nun einen weiteren Filter, der Einfluss auf Snippets mit FAQ nimmt. Bis dahin wurden im Snippet bis zu 4 Fragen direkt angezeigt mit einem Akkordeon das 10 Fragen umfassen konnte. Nun ist bei 2 Fragen Ende Gelände. Genau genommen ist das sogar kein maximaler Wert, sondern auch ein minimaler Wert, denn eine Frage funktioniert laut Brodie nicht.
Was bedeutet das jetzt für Dich
und den künftigen Umgang mit FAQ-Schema
? Ist es beispielsweise sinnvoll, nun alles was über 2 Fragen hinaus geht wieder ausbauen? Keinesfalls.
Wenn Du mehr als 2 Fragen mit dem FAQ-Markup in einem Inhalt ausgezeichnet hast, behalte das gerne bei. Selbst wenn Google nur 2 davon anzeigt und sich auf die ersten beiden konzentriert, ist es nicht schlimm, wenn mehr da sind. Bei dem ein oder anderen sehr spezifischen Query zahlt sich das vielleicht aus. Abgesehen davon, dass es keine Aufwand macht und auch keinen Schaden anrichtet.
Was aber sinnvoll ist, da stimme ich der Empfehlung von Brodie 100% zu: Schau Dir die ersten 2 Fragen-Antwort-Sets unbedingt an! Kann sinnvoll sein, da nochmal etwas feinzutunen oder umzusortieren. Falls Du für einen Inhalt noch keine FAQ formuliert hast, hast Du die Möglichkeit, die neue Anforderung direkt von Anfang an zu berücksichtigen.
Fragst Du Dich jetzt auch, ob und welche nicht ganz so offensichtlichen Filter es bei anderen Rich Snippets gibt?
|
|
|
Böser, böser Bot 😈
|
|
Im Netz tummeln sich mittlerweile zahlreiche Bots, deren Anfragen unter Umständen zu einer Überlastung Deiner Website führen können. Oder Du hast andere Gründe, warum Du einem Bot bestimmte Inhalte deiner Seite unzugänglich machen möchtest. Hierfür kann die Robots.txt eine Lösung sein. Sie dient dazu, Bots mitzuteilen, was sie auf Deiner Seite dürfen und was nicht. Die Robots.txt sollte aber nicht dazu genutzt werden, Webseiten aus der Google-Suche auszuschließen. Dafür solltest Du noindex-Anweisungen verwenden oder deine Seite mit einem Passwort schützen.
Falls dieses Thema nun komplettes Neuland für Dich ist, hat Johan einen
umfassenden Artikel zur Robots.txt
geschrieben.
Nun ist es leider so, dass nicht alle Bots gut sind, es gibt auch zahlreiche Bad Bots da draußen. In dem
Artikel Bot Wars
sagt Tobias von Dewitz, dass häufig sogar 20% des Traffics von Bad Bots stammt. Daher liegt die Vermutung nahe, diese einfach mittels der Robots.txt auszuschließen. Und genau diese Frage hat sich
Florian Elbers auf Twitter gestellt:
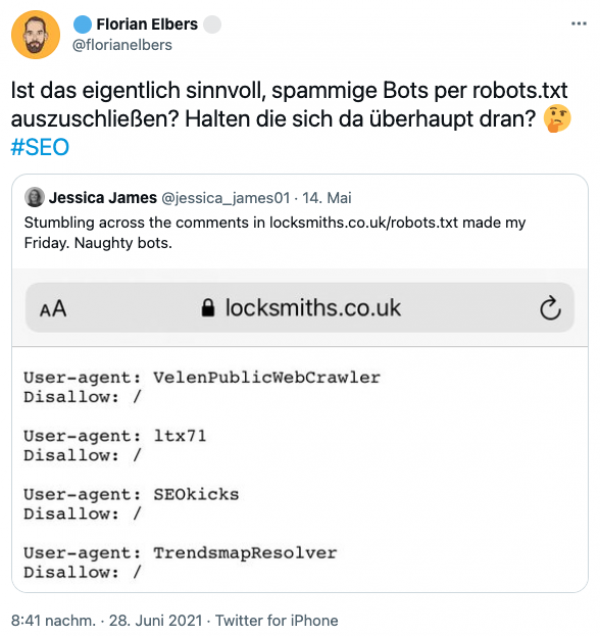
Aus SEO-Sicht wäre es aber nicht sinnvoll, Bad Bots mittels der Robots.txt auszuschließen, da die Erstellung einer solchen Datei mit relativ hohem Arbeitsaufwand verbunden ist und viel wichtiger ein
hohes Risiko für Fehler
bietet.
Aber halten sich Spambots überhaupt an die durch die Robots.txt definierten Regeln?
Lass uns diese Frage mit einem Beispiel aus dem Alltag beantworten:
Stell Dir vor, ein Auto fährt auf ein Stoppschild zu. Laut den Verkehrsregeln musste der/ die Fahrende mindestens drei Sekunden halten. Nun frage Dich einmal selbst. Würdest Du anhalten? Der Bad Bot jedenfalls nicht. Im Fall Deiner Robots.txt freut sich der Spam-Bot sogar für den netten Hinweis, dass seine Anwesenheit Probleme bereitet. Viele default-robots.txt Files sind sogar ein deutliches Indiz für das genutzte CMS. Ein Blick weiter ist die README in der die Versionsnummer steht und noch ein Schritt weiter dann ein Blick in die
Exploit-Datenbank
mit gängigen Schwachstellen für die eingesetzte Software-Version.
|
|
|
Ob und wie es weitergeht, siehst Du, wenn das Licht angeht
|
|
Googles FLoC-Experiment, das in insgesamt 10 Ländern (zum Beispiel USA, Brasilien, Australien und Japan) seit März 2021 getestet wurde, scheint vorerst nicht weitergeführt zu werden, wie
Golem
, beziehungsweise
the Register
berichtet. Wie es mit der Initiative weitergeht ist noch ungewiss und harrt einer Entscheidung von Google. Die Abschaffung von Third-Party-Cookies im Chrome-Browser hat Google aber schonmal um
eineinhalb Jahre nach hinten verschoben
.
Über das recht eindeutige Feedback von
Amazon
,
Worpress
und
Co
haben wir
bereits berichtet
.
Welches Feedback es von Nutzern zu diesem Experiment gab, wollte Google dagegen nicht veröffentlichen. In der aktuellen Ausprägung wird das wohl kaum klappen. Wir bleiben gespannt, ob Google noch einen Weg findet, die FLoC-Schäfchen ins Trockene zu bringen. Es bleibt nur: Abwarten.
|
|
|
Das Spiel ist aus!
|
|
Die Fußball-Europameisterschaft wurde am Wochenende mit dem Finale zwischen England und Italien entschieden. Unsere herzlichen Glückwünsche gehen über die Alpen an die Sieger. Das Ende der EM bedeutet aber auch, dass wir Dir noch das Endresultat unseres Tippspiels mitteilen müssen.
Gewonnen hat mit satten 109 Punkten der Kollege Andreas (ebenfalls Glückwunsch!), aber das tut hier ja eigentlich nichts zur Sache. Viel spannender war ja die Frage der überlegenen Tipp-Methodik. Zur Erinnerung: Lars hatte seine Tipps aus den Verhältnissen von Suchvolumina verschiedener Suchanfragen zu den antretenden Nationen abgeleitet. Ich bin dagegen mit einem vierseitigen “Würfel” an den Start gegangen.
Von meiner Seite aus musste in den K.O.-Spielen natürlich eine kleine Anpassung vorgenommen werden, da ein Unentschieden kein mögliches Ergebnis abbildete. Falls ich also nach dem Wurf für beide Seiten ein unentschieden hatte, wurde einfach für beide weitergewürfelt, bis es kein Unentschieden mehr war.
Nun aber zu den Ergebnissen: Lars konnte mit 79 Punkten seinen 8. Platz verteidigen. Behrend, der auch einen SV-orientierten Ansatz fuhr, belegt den 9. Platz mit ebenfalls 79 Punkten, aber weniger Spieltagssiegen. Mein Würfel hat mir immerhin 62 Punkte und damit Platz 11 beschert.
Die Differenz beträgt etwa 4 komplett richtig getippte Spiele, 5 Tipps mit der richtigen Tordifferenz oder 8 mit richtiger Tendenz. Rein auf der Datenebene scheint der Suchvolumen-Ansatz für Tippspiele also erfolgreicher als der komplette Zufall. Ich wage aber zu behaupten, dass sowohl unser Versuchsaufbau als auch die abgeleiteten Thesen einer seriösen, wissenschaftlichen Untersuchung womöglich nicht standhalten würden (Anmerkung der Redaktion: Eine hanebüchene Behauptung. Natürlich waren das alles statistisch einwandfrei).
Aber mit der WM im nächsten Jahr winkt ja bereits eine neue Testreihe ;)
|
|
|
Auflösung Search Console-Rätsel
|
|
In der
letzten Ausgabe des Newsletters
hatten wir Euch gefragt, wie zu Differenzen zwischen Search Console Daten kommen kann (wir haben diese über die API erhoben, aber das ist für den Case letztlich unerheblich). Mattia Geremicca von logicline.eu hat uns als Erster eine korrekte Antwort geschickt:
Die Antwort […] ist die unterschiedliche Datenaggregierung. Üblicherweise werden die Daten in der Search Console nach Property gruppiert. Nur wenn nach URL gefiltert wird, werden die Daten nach URL gruppiert.
Bei der Gruppierung nach Property wird pro Ergebnis in der Suche maximal 1 Impression und 1 Klick gewertet. Bei der Gruppierung nach URL können es aufgrund von Sitelinks jedoch mehr sein. Hier wird jeder Sitelink als eigene Impression ausgewertet.
Das ist richtig gewesen, aber noch nicht vollständig. Auf Nachfrage hat Mattia aber noch mal erklärt, warum bei der Erhebung der Daten nach Query im Beispiel fast 50% der Klicks und Impressions verloren gehen:
Die Differenz zwischen Total und Query ergibt sich dadurch, dass in der Google Search Console nicht alle Keywords ausgegeben werden, nach denen die Nutzer suchen. Zählt man die Klicks der ausgegebenen Keywords zusammen, kommt man somit nicht auf die Total Klicks. Google selbst sagt hierzu, dass Suchanfragen die selten gestellt werden, oder sensible oder personenbezogene Daten enthalten aus Datenschutzgründen in der Kategorie „(other)“ zusammengefasst werden. Diese Kategorie wird bei API Abfragen aber nicht ausgegeben und kann daher für größere Unterschiede in den Daten sorgen.
Schöner hätten wir das auch nicht erklären können.
Learning: Wenn Du mit Daten arbeitest, dann musst Du verstehen, wie diese Daten erfasst, verarbeitet und ausgegeben werden. Ansonsten entgehen Dir 50% des Traffics und Du merkst es noch nicht einmal. Das Schlimme an der Stelle: Dieser Bias in der Auswertung führt regelmäßig dazu, dass SEOs dazu neigen, den Shorthead zu stark zu gewichten und den Longtail unterschätzen.
Mehr zu
Stolperfallen in der Search Console hat Dir Behrend zusammengestellt
.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an
[email protected]
oder
ruf uns einfach kurz an:
+49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|




