| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #237 |
|

|
| 🎄Festtags-SEO: Zwischen Tannenbaum-Trends und Lebkuchenduft |
+++ ACHTUNG🚨: Sei nicht traurig, aber dieser Newsletter wird der letzte für dieses Jahr sein, am 07.01.25 geht es aber fröhlich und wie gewohnt weiter +++
Weihnachten steht vor der Tür, und die Vorbereitungen laufen auf Hochtouren. Die Weihnachtsdeko ist ausgepackt, und auch der Tannenbaum wurde schon gekauft. Dieses Jahr habe ich ein ganz besonderes Exemplar erwischt – sagen wir so, er weist hier und da ein paar Lücken auf. 😄
Der Weihnachtsbaum ist ein gutes Beispiel dafür, wie sich Offline-Themen ins Internet schleichen. Die Suchnachfrage nimmt seit 2010 kontinuierlich zu, doch das liegt wohl kaum daran, dass immer mehr Menschen zu Hause einen Weihnachtsbaum aufstellen. Meine unbelegten Thesen, auf die die Google-Suchergebnisse schließen lassen:
- Die Menschen werden zu faul, zum Weihnachtsbaumstand auf dem nahegelegenen Supermarktparkplatz zu fahren, um sich selbst ein schönes Exemplar auszusuchen – sie wollen lieber online bestellen.
- Sie wollen keine stolze, echte Nordmanntanne mehr in ihr Wohnzimmer stellen, sondern sind auf der Suche nach einem möglichst authentisch aussehenden, nachhaltigen künstlichen Weihnachtsbaum, den sie ebenfalls online kaufen möchten…
Doch das Thema „Weihnachtsbaum“ ist nur die Spitze des Schneebergs. Die digitale Welt hat die Art und Weise verändert, wie wir die Adventszeit erleben: Vom Plätzchenrezept über die steigende Nachfrage nach Last-Minute-Geschenkideen bis hin zur Online-Buchung von Weihnachtsmarktbesuchen. Selbst das gute alte Weihnachtskarten-Schreiben hat mit personalisierten digitalen Grußkarten einen modernen Twist bekommen.
Welche Trends uns in der Vorweihnachtszeit noch bewegen, haben Dir unsere Wingnachtsmenschen als snackable Keksbuffet aufbereitet:
- Butterplätzchen Jolle, die Dupes, Clusterfucks und marodierende schwarze Löcher unter die Lupe genommen hat
- Mandelplätzchen Nils, der über Googles neustes Core Update berichtet
- Vanillekipferl Florian, der erklärt, wie TF-IDF funktioniert und warum er so wichtig für die Textoptimierung ist.
- Spekulatius Nora, die Dir zeigt, wie Du SEO und Social miteinander verbinden kannst
- Zimtstern Philipp, der sich mit seinen zwei Herzensthemen befasst hat: Lesen und SEO
Viel Spaß beim Lesen!
Deine Wingmenschen
|
|
| Same, same, but different: Über Dupes, Clusterfucks und marodierende schwarze Löcher 👯🔀🕳️ |
Eine neue Folge von Search Off The Record (Trankskript) ist live und sie verdient Deine Aufmerksamkeit! Allan Scott aus Googles Dupes Team ist zugast bei Martin und John. Die Drei beugen sich intensiv über Indexierungs- und Retrieval-Werkzeuge wie Canonicalization, Deduping, Document Clustering oder HREFLANG.
Wir lernen (erneut), dass “Mixed Signals” wirklich ein Problem sind, Soft 404s intern “Crypto 404s” heißen und Fehlerseiten ganze Domains in “marauding black holes” ziehen können, wo sie vom Crawler geghostet werden. 👻 Eine großartige SOTR-Folge, die Dein Verständnis von Suchmaschinen – oder den Problemen, die sie zu lösen haben – schärfen wird.
Von Dupes, Document Clusters und Canonicals
Einmal Punkt für Punkt zum Mitdenken:
- In Googles Index stehen nicht einzelne URLs, sondern Dokumente.
- Verschiedene URLs werden zu einem Document Cluster zusammengefasst.
- Die URLs heißen in diesem Kontext “Dupes” (= Duplicates).
- Dupes innerhalb eines Document Clusters teilen sich Signale (zum Beispiel Backlinks).
- Randnotiz: Das kann schon mal dazu führen, dass fremde Domains, die Deinen Content hijacken, von Deinem Backlinkprofil profitieren. Autsch.
- Innerhalb des Clusters bemüht sich Google, die beste, originäre URL als Canonical zu identifizieren.
- Es gibt dutzende (Schätzwert: 40) Signale, die helfen sollen, das korrekte Canonical zu finden.
- Der Canonical-Link ist eins davon.
- Die Relevanz von x-default wird hier mehrfach betont. Was Du im HREFLANG-Kontext als übergreifende URL angibst für User, die Du nicht mit konkreten Sprach-Land-Anweisungen versorgst, ist also auch ein wichtiges Signal dafür, welches Canonical sich Google greift.
- Viele der Signale werden in Googles Dokumentation “How to specify a canonical URL with rel="canonical" and other methods” explizit genannt. x-default fehlt hier (noch). Der URL-Slug der Doku ist spannenderweise: “consolidate-duplicate-urls”.
- Website-Betreibende können sich selbst einen riesigen Gefallen tun und dafür sorgen, dass sämtliche Signale eindeutig sind, damit Google das korrekte Canonical wählt.
- Also bitte nicht die http-Version statt https in den Canonical-Link schreiben. Und natürlich nur URLs mit Status Code 200 und keine wilde Redirect-Rutsche.
- Wenn Google Dein Canonical nicht übernimmt, hat es die URL vermutlich nicht mal in dasselbe Document Cluster geschafft.
Von Localization und HREFLANG
Die Frage, welche URL an welchem Ort der Erde bzw. für welchen User mit welcher Sprache ausgespielt werden soll, behandelt Google unter dem Begriff “Localization”. SEOs denken hier direkt an HREFLANG. Auch dazu hat Google in diesem Jahr eine gute Podcast-Folge veröffentlicht, in der ebenfalls das Konzept der “Dupes” angerissen wird.
“Boilerplate Translations" vs.”Full Translations”
Seiten wie Social-Media-Feeds, die vielleicht eine Übersetzung von Header und Footer haben, dann im Main Content aber die identischen Inhalte einbetten, können getrost in ein Cluster wandern.
The boilerplate translations, we want to put into the same cluster. That means that they'll consolidate signals, but it also means that we don't have to crawl every single localization variant[,] because [...] we're wasting your bandwidth, and we're wasting our space by doing that.”
– Allan Scott vom Google Dupes Team
Dagegen werden tatsächliche, komplette Übersetzungen in verschiedene Cluster gepackt. Das ist auch der Grund dafür, warum Du zwischen unterschiedlichen Sprachen gar kein HREFLANG brauchst. Ein deutsches Dokument rankt in der Regel für deutsche Suchanfragen und ein englisches für englische.
”[T]he full translation pages should not cluster because they have different tokens they're going to retrieve for different queries, so we don't want them in the same cluster. We want to have all those pages available for retrieval.”
– Allan Scott vom Google Dupes Team
Wenn bei den Boilerplate-Übersetzungen HREFLANG korrekt verwendet wird, ist Google laut Allan dennoch in der Lage, die passende URL aus dem zusammengeworfenen Cluster im passenden Land anzuzeigen. Es könnte also sein, dass Google nur einmal prüft, ob es sich um Dupes handelt und der HREFLANG-Block passt. Anschließend werden die Seiten dann entweder gar nicht mehr gecrawlt oder vielleicht nur der HTTP-Header geprüft, nicht aber der komplette Inhalt.
Ein Mechanismus des Vertrauens?
Allan deutet an, dass sich Website-Betreibende künftig durch zutreffende Signale Vertrauen erarbeiten könnten, so dass Google mit weniger Kontroll-Crawls die Signale einer Domain für bare Münze nimmt.
”We want to serve more hreflang variants. We want to utilize that more, but we need to put in place mechanisms that will determine basically how much we can trust it on a given site. We're doing some crawl and verification, basically, to determine, you know, is this site serving its map correctly, and if so, then we're going to try to serve that more often without necessarily having to verify it as much as we currently do.”
– Allan Scott vom Google Dupes Team, eigene Hervorhebung
Near Duplicates: Same, same, but different
Anstrengend, aber es geht noch weiter 😬.
Manchmal ist es notwendig, dass minimale inhaltliche Unterschiede zweier sonst identischer Seiten dazu führen, dass sie nicht in ein Document Cluster gepackt werden. Zum Beispiel, wenn auf einer Produktseite für die Schweiz der Preis in Schweizer Franken steht, während für Deutschland als Währung der Euro geführt wird.
“Those ones become more complicated because it's basically the same content, but for one token. But that one token really matters. And then that one token case, we still want to have them in different clusters.”
– Allan Scott vom Google Dupes Team, eigene Hervorhebung
Denn zur Erinnerung: Dupes eines Clusters werden nicht separat gecrawlt. Um Content für “Franken” bzw. “Euro” während des Retrieval-Prozesses in die passenden Posting Lists zu schreiben, muss Google den jeweiligen Content aber kennen.
Die Krux? Wir wollen also, dass Google diese Seiten in verschiedene Cluster packt und trotzdem als “gleiche” Variante in einem HREFLANG-Block respektiert.
HREFLange Nase
Umgekehrt sind Website-Betreibende oft irritiert, wenn ihr österreichischer Content in Deutschland rankt, obwohl der HREFLANG-Block korrekt gesetzt ist. Das passiert gerne, wenn unterschiedliche Teams die Inhalte ausdifferenzieren. Zum Beispiel wenn eine Shop-Kategorie in Deutschland die blanke Produktliste abbildet, während das AT-Team darüber hinaus nützliche Produkttipps in den Content integriert, für die sich auch Menschen in Deutschland interessieren.
Unterschiedliche Inhalte → unterschiedliche Document Cluster → unterschiedliche Tokens für unterschiedliche Posting Lists → unterschiedliche Rankings
Wenn Du diese Mehrfachrankings willst, kannst Du Dir HREFLANG sparen. Ansonsten musst Du den Content vereinheitlichen.
Die Sache mit den schwarzen Löchern 🕳️
Fehlerseiten mit Inhalten wie “Dieses Produkt gibt es aktuell nicht”, werden zusammengeclustert. Google denkt sich: “Das ist alles derselbe Käse, warum sollte ich mich damit weiter beschäftigen?” Ein Indikator dafür ist, wenn Google laut Search Console ein abweichendes Canonical gewählt hat, das zu einer inhaltlich völlig anderen Seite gehört.
Das ist OK, wenn zum Beispiel ein Produkt ausverkauft ist und es das nie wieder geben wird. Blöd ist es, wenn das Produkt zurückkehrt. Denn die Seiten im Fehlercluster werden (fast) nie wieder gecrawlt. Google bemerkt also nicht, dass sich der Inhalt auf der Seite wieder geändert hat und es das Produkt wieder zu kaufen gibt.
Wir können natürlich mit Verlinkung, Sitemaps und Pings in der Search Console oder der Indexing API versuchen, Google zum Crawling zu überreden. Aber das funktioniert nicht stabil.
Abhilfe schafft ein passender Status Code für Fehlerseiten, der nicht 200 ist.
”Only 200s go into black holes.”
– Allan Scott vom Google Dupes Team
Du siehst: In der Podcast-Folge steckt jede Menge Wissen, über das wir als SEOs gerne mehrfach und intensiv nachdenken können. Denn all der ungelenke Tech-Sprech hat massive Konsequenzen für Deine Content-Strategie.
Welcher Aspekt bringt Dich ins Grübeln? Hast Du Fragen? Meld Dich gerne bei uns oder bei mir auf Linkedin und wir diskutieren darüber.
|
|
| Wer Updates bestellt, der bekommt Updates |
Egal in welchem Feld, wenn man Prognosen wagt, läuft man das Risiko, dass man mit Zitronen handelt. In unserer letzten Ausgabe hatten unter anderem Nora und ich das Vergnügen. Nora sagte:
“Nach dem Update ist vor dem Update. Wie wir Google kennen, rollt die nächste Update-Welle im März 2025 auf uns zu.”
Der erste Teil hätte treffender nicht sein können. Mit dem Zeitpunkt lag sie dann doch leicht daneben. Denn seit vergangenem Donnerstag läuft schon das nächste Core Update. Das Dezember-Update stand damit ca. eine Woche nach dem Abschluss des November-Updates in den Startlöchern. In einem Versuch der Küchenpsychologie könnte man sagen “Dann hat denen das letzte Update wohl nicht gefallen.”, wenn sie direkt ein weiteres machen müssen.
Google selbst sagt allerdings, dass dieses Update andere Systeme betrifft. Scheinbar war es nicht gewollt oder möglich, diesen Systemen gleichzeitig ein Update zu geben. Welche Teile im November und auch jetzt genauer betroffen sind, hat Google natürlich nicht bekanntgegeben. In den ersten Tagen sind allerdings schon erste Auswirkungen zu sehen. So berichten die Kollegen von Sistrix beispielsweise, dass die in den letzten Monaten stetig gestiegene Sichtbarkeit von Reddit in Deutschland von 77 auf 56 Punkte einbrach.
Es ist wieder einiges in Bewegung in den SERPs, also wirf auch einen Blick auf deine Rankings. Doch wie immer raten wir Dir, in beide Richtungen Ruhe zu bewahren.
Zur Kontrolle der Rankings guckst Du wahrscheinlich auch in die GSC. Diese hat ebenfalls einen neuen Anstrich bekommen. Hierzu hatte ich letzte Woche noch gemutmaßt, ob wir etwas frischere Daten zur Verfügung bekommen. Auch hier sind zumindest teilweise von mir gehandelte Zitronen in Umlauf. Denn auch wenn die frischen Daten nun umfangreicher zur Verfügung stehen, sind sie noch nicht automatisch im jeweilig gewählten Zeitraum zu sehen. Stattdessen sieht es aktuell wie folgt aus:
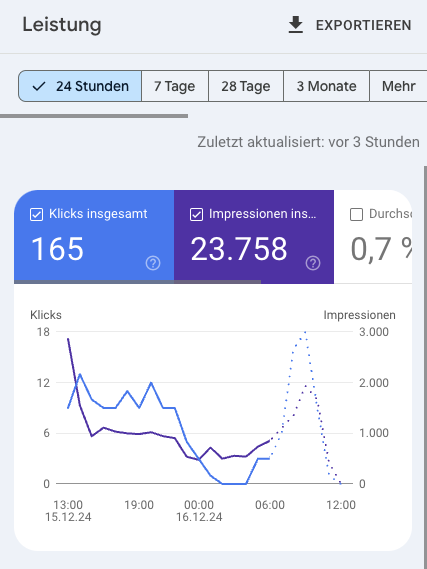
Die Zeiträume bis drei Monate stehen über Schaltflächen zur Verfügung und die weiterhin bekannten Einstellungen im Dropdown daneben. Die im Bild gezeigte Übersicht über die letzten 24 Stunden, die jetzt möglich ist, ist aber aus Sicht von News-SEOs noch spannender. Gerade weil sie auch für News und Discover zur Verfügung steht. Damit könnten z.B. Republishing-Entscheidungen auch ohne Zuhilfenahme weiterer Daten aus der Webanalyse getroffen werden. Für Publisher liegt hier ja quasi pures SEO-Gold. Jetzt müssen wir nur noch schauen, wie wir die Daten exportiert bekommen.
Alles neu macht also dieses Jahr wohl der Dezember. Und damit frohe Festtage :)
|
|
| Back to Basics: Was ist eigentlich dieses TF-IDF? |
Wenn Du Dich mal mit Content Optimierung beschäftigt hast, oder einfach nur mal darüber nachgedacht hast, wie die Welt wohl für den Suchbot von Google aussieht, dann bist Du bestimmt schon mal über den Begriff TF-IDF gestolpert.
Was auf den ersten Blick wie die Abkürzung eines drittklassigen Fußballvereins wirkt, ist eigentlich eine leicht erklärte Sache.
TF-IDF steht für Term Frequency - Inverse Document Frequency und ist eine Metrik, die sowohl für Information-Retrieval, als auch für viele Konzepte im Machine Learning genutzt wird.
Für uns ist TF-IDF natürlich besonders interessant, da es uns einen kleinen Einblick in den Prozess der Dokumentenbewertung von Google gibt. Um die Funktion und den Nutzen von TF-IDF zu verstehen, schauen wir uns das am besten an einem Beispiel an:
Stell Dir vor, Du bist Google. Du hast es geschafft, das Internet nach Inhalten zu crawlen und diese zu speichern. Das Problem ist nun jedoch, wie bewertest Du diese Inhalte? Schließlich willst Du Nutzern ja möglichst nur Forbes hilfreiche und passende Inhalte liefern. Wie gehst Du da am besten vor?
Du könntest jemandem, der nach “Glühweinrezept” sucht, einfach alle Seiten des Indexes mit dem Wort “Glühweinrezept” im Text ausspielen. Statt einer Anleitung, wie man leckeren Glühwein zubereitet, hat der Nutzer jetzt hunderte Seiten voll mit Kurzgeschichten, Über-Uns Seiten von Weihnachtsmarktbetreibern und Shoppingseiten für Zimtstangen. Der Nutzer wäre dann etwas überfordert bei der Aufgabe, die für ihn relevanteste Seite zu finden.
Das stellt Dich vor das Problem des Rankings. Und wenn Du etwas ranken willst, musst Du erstmal die Bedeutung des Dokumentes verstehen (oder wenigstens vortäuschen). In der Realität verwendet Google wahnsinnig viele Faktoren und Variablen um Dokumente zu verstehen und zu bewerten, wir schauen uns das allerdings nur aus TF-IDF Sicht an:
Term Frequency
Wenn Du einfach Suchergebnisse anhand der vorhandenen Terme ausspielst, bringt Dich das nicht weiter. Der nächste Schritt wäre das Zählen dieser Terme. Ein Dokument, in dem 5 Mal das Wort Glühwein vorkommt, sollte doch relevanter sein, als eines mit nur 3 Verwendungen des Wortes, oder?
Leider ist es nicht ganz so einfach. Das häufige Vorkommen eines Termes bedeutet nicht, dass der Text auch relevanter ist. Andernfalls würde eine 6.000 Wörter lange Kurzgeschichte über einen fiktiven Weihnachtsmarkt mit 100-facher Verwendung des Keywords “Glühweinrezept” relevanter sein, als ein richtiges Glühweinrezept, welches das Wort nur 5 Mal auf 200 Worte enthält. Längere Texte bringen zwangsweise mehr Verwendungen eines Termes mit sich.
Hier kommt TF - also die Term Frequency ins Spiel. Bewertet wird ein Dokument nicht nur anhand des Vorkommens eines Wortes, sondern anhand der Frequenz, mit der ein Wort im Vergleich zum Rest des Textes vorkommt. Dafür wird einfach die Anzahl des Wortes durch die Anzahl der Wörter im Text dividiert.
TF = Anzahl des Termes / Gesamtanzahl der Worte
Auf unser Beispiel bezogen heißt das:
- TF der Kurzgeschichte: 100/6000 = 0.017
- TF des Glühweinrezepts: 5/200 = 0.025
So wird die Häufigkeit der Verwendung eines Wortes und dessen Relevanz im Verhältnis zur gesamten Wortanzahl des Textes bewertet.
Würde Google nur anhand dessen bewerten, wäre das System allerdings sehr spamanfällig. Schließlich könnte jedes 200 Worte lange Rezept den Term Glühwein einfach noch 20 Mal ans Ende des Textes schreiben.
Um Keyword Stuffing nicht positiv zu bewerten, schaut Google sich die Term Frequency in Relation zu allen anderen Dokumenten an. Wenn die Median Term Frequency (von einem Ergebnis >0 ausgehend) 0,02 ist, Deine allerdings bei 0,5 liegt, ist es für Google ein Indiz dafür, dass in dem Text Keyword Stuffing vorliegt.
Inverse Document Frequency
Mit Term Frequency haben wir nun also eine akkurate Methode, die Relevanz eines Wortes für einen Text zu messen. Wir stehen allerdings immer noch vor dem Problem der Bewertung der Wichtigkeit eines Wortes für das Dokument.
Wenn man einfach zu jedem Wort einen Term Frequency Wert misst und dann die höchsten Werte für die Bewertung nimmt, würde die höchste Relevanz wahrscheinlich unwichtigen Wörtern beigemessen werden. Denn selbst ein gut geschriebenes Glühweinrezept wird immer öfter Wörter wie “ist”, “der” oder “und” enthalten, als es das Wort “Glühweinrezept” enthält. Theoretisch würde mit dieser Methode jedes Dokument für solche ranken.
Das Problem löst allerdings die Inverse Document Frequency. Die Inverse Document Frequency schaut sich an, wie häufig oder selten ein Wort im Gesamtkorpus der Dokumente vorkommt und misst somit die Menge an Gewicht, die einem Wort beigemessen wird.
Berechnet wird das Ganze so:
IDF = log (Anzahl der Dokumente / Anzahl des Termes)
Sagen wir, der Google Index würde nur aus 100 Dokumenten bestehen. 10 davon enthalten das Wort “Glühweinrezept” während 99 das Wort “und” enthalten.
- IDF “Glühwein” = log 100/10 =1
- IDF “und” = log 100/99 ≈0.0044
Je dichter die Zahl an Null ist, desto häufiger kommt das Wort vor und desto weniger Gewicht wird diesem beigemessen.
TF-IDF
Zusammengefasst lässt sich das gut an einem Beispiel erkennen.
Unser fiktives Glühweinrezept hat 100 Worte, von denen 5 “Glühweinrezept” und 15 “und” sind. Ausgehend an unserer oben berechneten Inverse Document Frequency, würde unsere Rechnung dann so aussehen:
TF-IDF = Anzahl des Termes / Gesamtanzahl der Worte * log (Anzahl der Dokumente / Anzahl des Termes)
- tf-idf “Glühweinrezept” = (5/100) * (log 100/10) = 0,05 * 1 = 0,05
- tf-idf “und” = (15/100) * log(100/99) = 0,15 * 0,0044 = 0.00066
Die Zahlen sind leider etwas unschön, allerdings lässt sich leicht erkennen, dass unser fiktives Glühweinrezept wesentlich relevanter für das Keyword “Glühweinrezept” als für den Begriff “und” ist.
Und da der Wert für die Inverse Document Frequency gleich bleibt, ist unser Glühweinrezept durch den höheren Term Frequency Wert auch weiterhin relevanter als die Kurzgeschichte über einen fiktiven Weihnachtsmarkt.
Was heißt das für Dich?
Heutzutage nutzt Google noch viel ausgefeiltere und komplexere Methoden zur semantischen Analyse von Texten. Dennoch bietet die Betrachtung von TF-IDF nicht nur einen praktischen Einblick in die Welt von Google, sondern kann auch ein nützliches Tool für die Analyse Deiner Inhalte sein.
Speziell mit Tools wie Termlabs kannst Du hier Deine Inhalte analysieren. So kannst Du sehen, wie die Term Frequency Werte Deiner wichtigen Keywords im Vergleich zu den Term Frequency Werten der restlichen Dokumente abschneiden. So kannst Du auch sehen, welche anderen wichtigen Begriffe Deinem Content bisher noch fehlen und ihn möglichst informativ ausführen.
Denke nur immer dran, das Ziel sollte nicht keywordreicher Inhalt, sondern hilfreicher Inhalt für Deine Nutzer sein.
|
|
| 🫶 Schaffe Synergien zwischen SEO und Social |
Wie Du vermutlich weißt, beschäftigt mich das Thema schon länger. Deshalb habe ich mich sehr über Sara Schwartz Vortrag auf der SEOkomm gefreut.
Sara hat hier nicht nur sehr schön beschrieben, dass sich eine Social-SEO-Themenrecherche eigentlich gar nicht so sehr von einer klassischen Themenrecherche unterscheidet, sondern auch Ideen geteilt, wie Social und SEO besser zusammenarbeiten können.
Diese Tipps von Sara möchte ich Dir für 2025 ans Herz legen:
- Teile Insights aus Deiner Themenrecherche und GSC mit dem Social-Team. ▶️ Nicht jedes Thema ist hier unbedingt geeignet, aber es schadet nicht, Evergreen-Themen zu teilen. Evergreen-Themen funktionieren häufig plattformübergreifend. Als Beispiel hatte Sara “einfache rezepte”. Zusätzlich kannst Du Insights aus der GSC teilen. Frei nach dem Motto: Was funktioniert gut? Was geht gerade durch die Decke? Gibt es das Thema schon auf Social?
- Analysiere die Rankings von anderen Plattformen. ▶️ Dieser Tipp geht mit Pinterest besonders gut. Hier kannst Du die eigenen Kanäle unter die Lupe nehmen, oder Du schaust, wofür die Plattformen im Allgemeinen ranken, um neue Themen zu erschließen. Das geht zum Beispiel mit Sistrix:
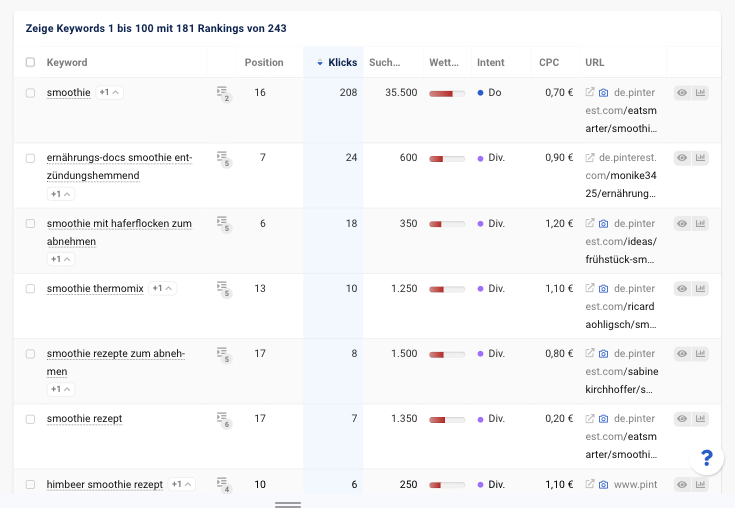
- Steuere Keywords für Kampagnen bei. ▶️ Sara hat erzählt, dass sie gebeten wurde, Keywords für eine Influencer-Kampagne zu recherchieren, um besser über die Suche gefunden zu werden. Auch hier ergeben sich großartige Synergien.
- Frag die Socials nach einem Trendreporting. ▶️ Es ist kein Geheimnis, dass Trends häufig auf Social Media starten. Frage daher nach einem regelmäßigen Trendreporting, um der Google-Nachfrage einen Schritt voraus zu sein. In meiner Zeit im Content-Marketing habe ich einen Blogartikel zum Thema “gaming zimmer ideen” vorgeschlagen, weil gerade die Roomtour von Montana Black viral gegangen ist. Das Suchvolumen lag da laut Sistrix bei 1.250 und stieg in den kommenden Monaten auf 2.850 an.
- Social-Signals einsammeln ▶️ Erwähnungen auf Social-Media zahlen nicht nur auf Dein Branding ein. Du sammelst zusätzlich jede Menge Social-Signals und Dein Content erreicht mehr Nutzer. Falls das Social-Team Deine Inhalte also noch nicht featured, frag unbedingt nach, wie ihr zusammenarbeiten könnt.
- Apropos Zusammenarbeiten: Frag nach Tools! ▶️ Wir lieben Daten. Vielleicht haben die Socials Tools, die Du für Analysen oder Themenrecherchen zusätzlich anzapfen kannst. Sei es zur Keywordrecherche oder um Deinen Content besser auf die User Journey anzupassen.
SEO und Social sind keine getrennten Welten, sondern zwei Seiten derselben Medaille. Die Symbiose von Social Media und SEO bietet großes Potenzial, das wir für 2025 und darüber hinaus nutzen sollten. Indem wir Wissen und Insights teilen, innovative Ansätze verfolgen und plattformübergreifend zusammenarbeiten, schaffen wir nicht nur Synergien, sondern stärken auch unsere Inhalte, Reichweite und Branding.
|
|
| Lesen ist schwer – genau wie SEO – und darum wertvoll |
In Island ist es an Heiligabend üblich, sich Bücher zu schenken und den Abend gemeinsam zu lesen. Dazu gibt es heiße Schokolade und Marshmallows – alles zusammen bekannt als Jolabokaflod.
Schöne Tradition und Grund für einen Exkurs statt reiner SEO-Weisheiten. Zum Jahresende motiviere ich Dich, ein Buch zu lesen. Ich bevorzuge Papier, aber Hauptsache ein Buch. SEO und Bücher haben viele Parallelen.
Ende 2023 habe ich schon mal so einen Artikel geschrieben und folgendes mit Dir geteilt: Bücher sind wie das reale Leben und SEO – kompliziert und komplex statt schnelllebig und oberflächlich wie Social Media.
Das erwartet Dich heute:
- Einige Zahlen, die mir Angst machen
- Warum wir es schwerer mit dem Lesen haben
- Welche Tugenden Lesen und SEO gemeinsam haben
- Persönliche Buchempfehlungen, um das Jahr ausklingen zu lassen
Die Lesekrise: Wir lesen immer weniger
Wie schlimm sind die Zahlen?
NAEP hat Folgendes festgestellt:
- 1984 lasen 35% der 13-Jährigen zum Spaß.
- 2023 waren es nur noch 14% und 31% gaben an, nie aus Spaß zu lesen.
- Eine These: Die Einführung von Smartphones hat zu dieser Entwicklung geführt.
Im “What Kids Are Reading Report?” heißt es, dass Kinder zwischen 1-11 Jahren YoY 4,4% weniger gelesen haben.
In Deutschland lesen wir auch weniger. 27 Minuten (2022) statt 32 Minuten (2012) und sitzen über 2 Stunden vor dem Fernseher. Gleichzeitig ist die Fernsehzeit gestiegen.
Die Washington Post hat Anfang des Jahres zwei Artikel veröffentlicht und Zahlen geteilt:
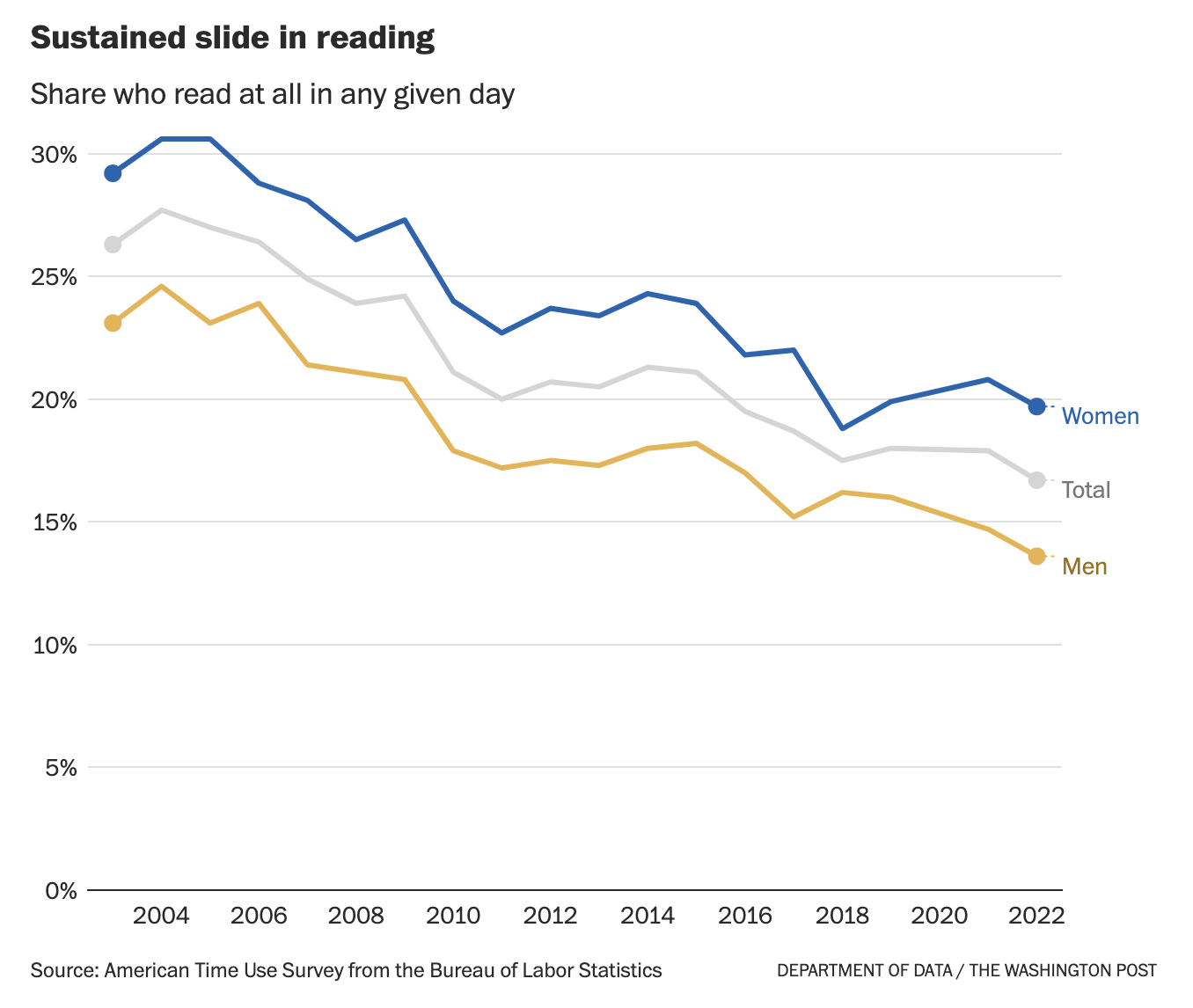
Von über 25% auf leicht über 15%, die überhaupt lesen. 46% der Amerikaner*innen haben in 2023 kein Buch gelesen und Bücherläden in allen Größen schrumpfen. Uffff. Aber das ist nur ein Problem.
Die Aufmerksamkeitskrise: Wir können kaum noch lesen
Im Kollektiv sinkt unsere Aufmerksamkeitsspanne (Zeit, die wir über ein Thema sprechen). Das betrifft Kinokartenverkäufe, n-grams in Google Books und z. B. Themen auf Twitter. Hier ein paar Zahlen zu Twitter:
- 2013 war ein Thema durchschnittlich 17,5 Stunden in den Top-50
- 2016 waren es nur noch 11,9 Stunden
"Ja, aber wir hören stundenlang Podcasts und bingewatchen ganze Serien.“ Das stimmt. Aber das eine ist passiv und das andere aktiv.
Stundenlanges Lesen ist anstrengend und erfordert viel Aufmerksamkeit und Konzentration – vorausgesetzt Du möchtest nicht nur berieselt werden, sondern lernen. Wenn Du mit dem Gelesenen in Zukunft etwas anfangen möchtest, braucht es Wiederholung und aktiven Recall.
Stattdessen nehmen wir häufig unser Smartphone in die Hand. Manche Studien gehen von mehr als 2.500x am Tag aus. Allein die Anwesenheit von unseren Smartphones kann uns ablenken, was als Brain Drain bekannt ist.
Als ich diesen Artikel von Evan Armstrong (Lead Writer bei Every) las, musste ich lachen (Evan ist witzig) und intensiv nachdenken:
“The first time I opened TikTok was the first time I was terrified by technology. At 9 p.m. on a Tuesday night in Southern Utah, I downloaded the app thinking I would check it out for five minutes. Then, without warning, I looked over at the clock and it was 3:30 a.m. I had been scrolling for six-and-a-half hours without pause.
At first, I thought I had a stroke or the clock was wrong, but then I realized that I had just been laying in bed, flicking my thumb up the screen, my mind ignoring the passage of time. TikTok had grabbed control of me—body and mind. It was spooky.”
Kennst Du das? Das ist der Grund, warum ich TikTok als Tor zur Hölle bezeichne. Und ich bin froh, dass ich größtenteils ohne Smartphones aufgewachsen bin und meine Kindheit genießen konnte.
Es liegt aber nicht nur an unserer schrumpfenden Aufmerksamkeit, dass wir weniger lesen. Wir sind auch süchtig nach Geschwindigkeit.
Der Geschwindigkeitsrausch: Wir müssen immer schneller werden
In seinem Buch Stolen Focus beschreibt Johann Hari unseren heutigen Umgang beim Bücherlesen als nervöses Umherhuschen in einem vollen Supermarkt – wie jetzt zur Weihnachtszeit – schnell rein, alles grabschen, was man braucht und sofort wieder raus.
Das steht im Kontrast zu Entspannung, Verlangsamung und einer Reise in eine andere Welt. Warum muss alles so schnell gehen heutzutage?
Nach Hartmut Rosa geht es um das Konzept der sozialen Beschleunigung, welches 3 Ebenen hat:
- Technologische Beschleunigung
- Beschleunigung der sozialen Veränderung und
- die Beschleunigung des Lebenstempos
Die wahrgenommene Zeit in der Gegenwart schrumpft und wenn man stillsteht, fühlt es sich so an, als würde man zurückgelassen werden (bekannt als Red Queen Effect).
Wir wollen ein Gefühl der Kontrolle haben und wenn wir in weniger Zeit mehr schaffen, haben wir dieses Gefühl. Schnelle Erfolge fühlen sich besser an, als lange in die Zukunft zu arbeiten, ohne sichtbare Meter zu machen.
“When you start behaving like a winner, doing the right things, there is a time delay of when you will see the results of this work. The bigger the win you are looking for, the longer the delay. You must be willing to endure this period.”
– Alex Hormozi (Unternehmer und Investor)
Alles, was viel Wert ist, ist entweder selten oder nur mit viel Geduld und harter Arbeit möglich. Wir wollen es aber schnell und mit wenig Aufwand. Das funktioniert nicht.
Gute SEO ist nicht kurzlebig und zerbrechlich, sondern langlebig und antifragil. Etwas, was schnell wächst, stirbt schneller. Wir wollen ein stabiler Baum sein, der Generationen überdauert statt einer Wunderkerze zum Jahresende, die kurz aufglüht und dann für immer erlischt.
Die Navy Seals folgen dem Mantra “Slow is smooth, smooth is fast.” Um schneller ans Ziel zu kommen, müssen wir langsam vorgehen, anstatt um dem schnellen Erfolge wegen alles übers Knie zu brechen.
Neben Geduld brauchen wir Anstrengung. Schwierige Dinge haben größere Eintrittsbarrieren und sind weniger überfüllt.
Anstrengung schafft Sinn
“Reading is meaningful and everything meaningful has effort behind it.”
– Odysseas (Content Creator)
Bedeutsam ist, was anstrengend ist. In diversen Podcasts erzählt Robert Greene z. B. wie er Altgriechisch gelernt hat und Thukydides übersetzen musste – ohne technische Hilfsmittel.
Er hat Stunden für einen Absatz gebraucht, und laut seinem Professor war das Ergebnis nicht gut genug. Also musste er nochmal ran. "Ja, aber er könnte das heute einfach mit ChatGPT übersetzen.”
Ja, das könnte er. Aber ohne die schwierigen Gewässer wäre er laut eigener Aussage heute kein erfolgreicher Autor, der Millionen an Büchern verkauft.
Manche Dinge skalieren nicht. Schnelleres Lesen führt ab einem gewissen Punkt zu abnehmendem Grenznutzen. Statt schneller zu lesen, kannst Du dann nur die Zeit, die Du liest und die Zeit, die Du wirklich liest (anstatt abgelenkt zu sein) steigern.
Ähnlich ist es, wenn der Aufwand, etwas zu erstellen, schrumpft. Dann verlieren manche Dinge ihren Wert:
- Kunst wirkt wertvoller, wenn viel Aufwand und bestimmte Techniken zur Erstellung nötig waren
- Wir sehen und hören uns Podcasts an, weil zwei echte Menschen mit echten Erfahrungen aufeinander treffen und miteinander sprechen
Notebook LM ist eine nette Spielerei, aber nach 1-2 mal anhören fühlt es sich für mich nicht richtig an und verfehlt, worum es in einem wirklich guten Podcast geht.
Ich habe das folgende Zitat gefeiert (und “AI images” durch “cheap AI content” eigenmächtig ersetzt):
“You know what I realized about cheap AI content in your marketing? It sends out the message that you've got no budget. It's the digital equivalent of wearing an obviously fake Chanel bag. Your whole brand immediately appears feeble and impoverished.”
– Del Walker (Principal Character Artist)
Kunst ist subjektiv und wir sind nicht rational. Selbst wenn KI-Podcasts sich mal authentisch nach “echten Menschen” anhören, wären sie für uns weniger wertvoll (wenn wir wüssten, dass der Inhalt per Knopfdruck entstanden ist).
Den Zauberknopf drücken, auch wenn das Ergebnis objektiv das Gleiche wäre, ist nicht das Gleiche.
Beispiel: Mit einem Helikopter auf dem Mount Everest zu landen ist nicht dasselbe, wie wenn Du den Gipfel selbst erklimmst.
Der Flug wäre einfach. Den Gipfel selbst zu erklimmen ist mit monatelangem Training, großer Anstrengung und viel Risiko verbunden. In beiden Fällen wirkt das Ergebnis auf den ersten Blick gleich, ist es aber nicht. Der harte Weg fühlt sich wertvoller an.
Wenn etwas anstrengend ist, müssen wir weitermachen statt aufzugeben.
“Stopping a piece of work just because it’s hard, either emotionally or imaginatively, is a bad idea. Sometimes you have to go on when you don’t feel like it, and sometimes you’re doing good work when it feels like all you’re managing is to shovel shit from a sitting position.”
– Stephen King (Autor)
Bücher lesen ist anstrengender, als einen Artikel zu skimmen, einen Podcast zu hören oder sich nur eine Zusammenfassung reinzuziehen. Aber es lohnt sich.
Ein Fazit und Buchempfehlungen, um besser zu werden (in der SEO und persönlich)
Lesen erfordert Konzentration, Aufmerksamkeit, Anstrengung und Geduld. Genau die Tugenden, die uns besser in der SEO machen:
- Die Basics für lange Zeit sehr gut machen,
- nicht von neuen, funkelnden Spielzeugen ablenken lassen,
- die extra Meilen für hervorragende Inhalte gehen und
- die Geduld, dass gute Dinge länger dauern.
Der größte Vorteil ist, dass wenn der Stein rollt, das Wasser gepumpt ist und der erste Dominostein gefallen ist, dann ist alles einfacher.
Zum Abschluss 3 Buchempfehlungen, die Dich garantiert besser machen:
Never Split The Difference (Chris Voss): Verhandlungen, die wir täglich als SEOs führen, basieren fundamental auf dem Verständnis menschlicher Emotionen, Empathie und aktivem Zuhören.
“When they’re not talking, they’re thinking about their arguments, and when they are talking, they’re making their arguments. Often those on both sides of the table are doing the same thing, so you have what I call a state of schizophrenia: everyone just listening to the voice in their own head.”
Influence (Robert Cialdini): In unserer modernen, komplexen Welt verlassen wir uns immer mehr auf unsere mentalen Shortcuts, um von der Reizflut nicht überflutet zu sein. Und für Dich ist wertvoll zu wissen, welche Hebel Du ziehen kannst, um die Menschen um Dich herum zu beeinflussen.
“We, too, have our preset programs, and although they usually work to our advantage, the trigger features that activate them can dupe us into running the right programs at the wrong times.”
The Obstacle is the Way (Ryan Holiday): Probleme sind Herausforderungen und Herausforderungen sind Chancen. Fokussiere Dich auf Dinge, die Du ändern kannst. Je mehr Kontrolle Du dem zuschreibst, was Dir passiert, desto mehr kannst Du selbst auch verändern.
“In our own lives, we aren’t content to deal with things as they happen. We have to dive endlessly into what everything “means”, whether something is “fair” or not, what’s “behind” this or that, and what everyone else is doing. Then we wonder why we don’t have the energy to actually deal with our problems.”
Das Schönste an guten Büchern: Du bekommst 10 Jahre Erfahrung eines Menschen für ca. 10 Euro. Das ist besser als ein Artikel, für den im Durchschnitt 4 Stunden notwendig waren. Den kannst Du zwar gratis lesen, aber häufig kommen sie von Sesselpupsern, die eigentlich keine Ahnung haben.

|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





