| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #166 |

|
| 🐲 SEO-Learnings aus den Drachenlanden |
Wingmenschen sind ja beinahe überall zu finden. In diesem Fall hat mich mein (Urlaubs-)Weg zum Drachenfest geführt, einer der größten Fantasy-LARP-Veranstaltungen Europas. Auf den ersten Blick müsste man meinen, das fiktive Streiten um die Vorherrschaft in den Drachenlanden habe allgemein wenig mit Online-Marketing gemeinsam. Schaut man jedoch genauer hin, fallen durchaus Parallelen auf:
Die Größe Deines Lagers ist unbedeutend, wenn Deine Streiter nicht motiviert sind. Es gibt keine Abkürzungen: Nur Ausdauer und Commitment führen zum Erfolg. Um sturmfest zu sein, braucht jede Palisade ein solides Fundament.
Unbenommen von meiner Exkursion waren die weiteren Wingmenschen fleißig und haben wieder Wissen für Dich gehortet:
Hannah führt News-Crawling-Insights ins Gefecht. Philipp stählt seine Gedanken mit mentalen Modellen. Nora entwickelt Notfallpläne für Sichtbarkeitsverluste. Jolle erforscht Crawling-Magie. Andreas beleuchtet ein Bündnis von Screaming Frog und KNIME.
Und Achtung: Lässt Du Deine Jira-Tickets Geburtstag feiern, dann muss ich eventuell erneut die Rolle eines Streiters annehmen ;)

Nun aber viel Spaß beim Lesen!
Deine Wingmenschen
|
|
| Crawling Insights für News SEOs von Barry Adams |
Barry Adams hat im aktuellen News-SEO-Newsletter darüber berichtet, wie Publisher das Crawling optimieren können, hier eine kleine Zusammenfassung und Wiederholung für Dich:
Wie entscheidet Google, was gecrawlt wird? Hierbei spielt die Relevanz der Seite eine große Rolle. Diese ergibt sich daraus, wie viele Links auf die URL zeigen, wie oft die URL aktualisiert wird und neue Links dazu kommen.
Wichtige URLs, zB. Evergreens, also regelmäßig aktualisieren und gut verlinken. Aber auch Hub- und Themenseiten fallen hierunter - nutze diese um das Crawling zu optimieren.
Ein weiteres wichtiges Thema (vor allem für News) ist, dass die Artikel nicht regelmäßig gerecrawled werden. Barry betont, dass SEO bereits beim ersten Publishen mitgedacht sein muss, denn ein eventuelles Recrawling findet erst Stunden oder sogar Tage später statt.
"This is why it's so incredibly important to make SEO part of your editorial workflow and ensure articles are optimised before they are published."
"Any improvements made to an article after its publication is unlikely to have any impact on the article's visibility. Unless, of course, you change the URL - because then Googlebot will treat it as an entirely new article."
Die wichtigste Ableitung also: Nimm SEO in den Publishing-Prozess mit auf.
Barry erwähnt auch noch einmal, dass die Robots.txt genutzt werden kann, um bestimmte Seitenbereiche vom Crawling auszuschließen. Hierbei betont er auch, dass seit 2011 nicht mehr mit dem Googlebot News gecrawlt wird, sondern mit dem Smartphone Bot. Wenn Du also in deiner robots.txt Angaben zum User-agent: Googlebot-News machst, wirkt sich das nicht auf das Crawling, sondern auf die Möglichkeit in Google News zu ranken.
Wie Du mit Large Language Models und deren Crawling umgehen kannst
Möchtest du künstliche Intelligenzen davon abhalten, mit den Daten Deiner Seite trainiert zu werden, dann kannst Du
"User-agent: GoogleOther
Disallow: /
User-agent: CCBot
Disallow: / "
in der robots.txt aufnehmen, denn Google crawlt dafür wohl mit dem GoogleOther Bot und OpenAI nutzt wohl den Common Crawl Bot. Möchtest Du mehr über das Sperren Deiner Inhalte vor LLMs erfahren, empfehle ich Dir den Artikel von Roger Montti.
Ein weiterer Tipp von Barry ist zu prüfen, ob Du wirklich die ganze Domain in der GSC angemeldet hast, oder nur einzelne Subdomains. Wenn Du die gesamte Domain angibst, siehst Du in den Crawl Stats, welche Subdomains Google wie crawlt und kannst so auch prüfen, dass beispielsweise keine Testumgebung aus Versehen gecrawlt wird. ;)
Interne Verlinkungstipps
Ein paar gute Hinweise für die interne Verlinkung hat Barry auch parat:
Keine Tracking-Parameter nutzen – solche URLs erzeugen unnötiges Crawling → nutze lieber andere TrackingSetups, die nicht für zusätzliche URLs sorgen. Lösche keine Artikel – vor allem nicht zu Themen, die Dir wichtig sind!
Alte Artikel sind mitunter oft nicht mehr der Traffic-Bringer. Sie spielen aber eine wichtige Rolle im Bereich Topical Authority. Sei also achtsam, wenn Du Inhalte löschen möchtest. Eine Themenseite mit wenig Artikeln schneidet im Vergleich zu einer Themenseite Deiner Konkurrenz mit mehr Artikeln schlechter ab.
|
|
| Mit mentalen Modellen nach oben denken |
"Ich wusste, dass das passieren würde."
"Das Bottleneck ist in der Technik, wir haben dafür nicht genug Ressourcen."
"Auch wenn wir das machen, haben wir Opportunitätskosten."
Diese drei Zitate sind Beispiele für mentale Modelle (Englisch: Mental Models) und sind Dir sicherlich schon mal über den Weg gelaufen. Mentale Modelle helfen uns, die Welt zu verstehen und aus komplexen Sachverhalten einfach verständliche und merkbare Gedankenstützen und Konzepte zu bauen.
Auch im SEO begegnen wir mentalen Modellen nahezu jeden Tag. Daher möchte ich Dir heute 3 vorstellen, die Du auf SEO und verwandte Disziplinen gut anwenden kannst.
1. First Principle Thinking
Einfach umschrieben sind First Principles die Dinge, von denen wir wissen, dass sie wahr sind. First Principle Thinking beschreibt, dass wir uns an den Dingen orientieren sollten, von denen wir wirklich wissen, dass sie wahr sind. Beispielsweise kam Elon Musk durch diese Art zu denken überhaupt erst auf die Idee, SpaceX anzugehen.
Einige First Principles aus dem SEO sind:
Damit etwas ranken kann, muss es vorher gecrawlt und indexiert worden sein. Verlinkungen (intern und extern) helfen Suchmaschinen neue Websites und Inhalte zu entdecken. Damit ein Inhalt langfristig gut ranken kann, muss die Suchintention befriedigt werden. Einzelne Seiten können für eine große Anzahl an Keywords ranken. Je nachdem von wo ich suche, bekomme ich andere Suchergebnisse ausgespielt. Und viele weitere Beispiele, die Dir sicherlich einfallen.
Damit man in First Principles denkt, sollte man das eigene Wissen hinterfragen. Prüfe das am besten mit folgenden Fragen:
Warum denke ich das und was genau denke ich? Woher weiß ich, dass das wahr ist? Welche Quellen bestätigen das? Ist das heute immer noch so? Gibt es unterschiedliche Meinungen zu dem Thema? Was ist, wenn ich falsch liege?
First Principles sollen Dir helfen, Dich auf die wesentlichen Wahrheiten zu fokussieren und Dein gesammeltes Wissen auf den Prüfstand zu stellen.
2. Second Order Thinking
Ein weiteres sehr gut zu SEO passendes Mental Model ist Second Order Thinking. Wenn Maßnahmen geplant werden, wird häufig nur an die Konsequenzen erster Ordnung gedacht. Was dabei gerne vergessen wird ist die Frage:
"Was könnten die Konsequenzen dieser Entscheidung in 12 Monaten, 3 Jahren oder 10 Jahren sein?"
Es geht also darum, sich nicht nur auf die möglicherweise unmittelbaren oder ersten Konsequenzen einer Entscheidung oder Maßnahme zu fokussieren, sondern mögliche nachgelagerte Konsequenzen und Effekte zu berücksichtigen.
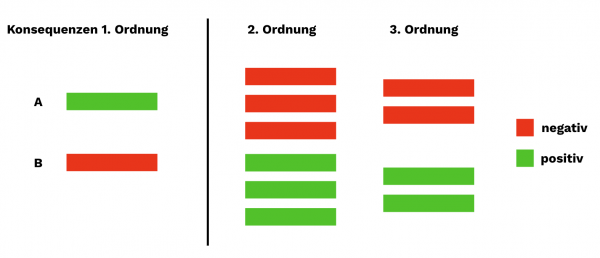
Eine Entscheidung könnte kurzfristig vielversprechende positive Auswirkungen zeigen, langfristig aber negative Konsequenzen bedeuten und umgekehrt.
Es lässt sich immer wieder feststellen, dass im Online Marketing (und natürlich auch im SEO) häufig kurzsichtig geplant wird. Hier mal zwei Beispiele:
"Wir ranken gut mit vollständig automatisiertem KI-Content. Vielleicht brauchen wir keine Redaktion mehr, das klappt auch so."
"Wir kaufen Links und sind vorsichtig, dann sollte uns nichts passieren, weil es bringt uns Ranking-Erfolge und stärkt unsere Domain."
Bei solchen Entscheidungen sollte man die angesprochenen Konsequenzen nachgeordneter Ebenen berücksichtigen.
Heute rankt KI-Content, was ist aber, wenn ALLE die gleichen Tools und austauschbare Inhalte verwenden? Dann haben wir unseren eigentlichen Wettbewerbsvorteil, ein gut gemeinsam arbeitendes Redaktionsteam, verspielt.
Wer heute Links kauft, die Wirkung zeigen, könnte morgen Links haben, die von Google entwertet wurden und keinen Effekt mehr haben. Im Worst Case wird man manuell abgestraft. Wir erwähnen oft, dass wir kein Linkbuilding machen und dabei spielt vorausschauendes Handeln im Sinne unserer Kunden natürlich eine große Rolle.
Das sind einfache Beispiele. Diese Gedanken lassen sich aber auf jede Entscheidung anwenden und helfen, sich auch auf nachgeordnete Reaktionen und Konsequenzen vorzubereiten und bessere Entscheidungen zu treffen.
3. Red Queen Effect
Abschließen möchte ich heute mit dem Red Queen Effect. Charles Darwin hat gesagt:
"It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is most adaptable to change."
Das ist genau das, was der Red Queen Effect ausdrückt. Wir SEOs müssen uns ständig an neue Gegebenheiten anpassen und vorbereiten. Gerade in den jetzigen Zeiten von
KI-Content, verändertem Suchverhalten jüngerer Generationen, KI-Anwendungen die Antworten auf Fragen liefern, wie es sie vorher nicht gab (ChatGPT, Google Bard, SGE, etc.) und neue Integrationen in den Suchergebnissen.
Das Spielfeld hat sich in den letzten 10 Jahren immer wieder verändert und die, die sich immer wieder angepasst haben, sind heute weiterhin erfolgreich. Hier lässt sich auch der Bogen zu den First Principles aufspannen.
Die Spielregeln werden durch Google geändert und daher gilt es bisherige Annahmen zu überprüfen, weil durch neue Gegebenheiten Dinge, die man als gegeben angesehen hat, nicht mehr gegeben sind und hinterfragt werden müssen.
Es gibt viele mentale Modelle und ich finde das Thema sehr spannend. Daher kannst Du dich auf einen zweiten Teil freuen.
|
|
| Sichtbarkeitsverlust – WTF 😱 |
Ungefähr so sah der Betreff einer E-Mail aus, die Donnerstagmorgen in mein Postfach geflattert ist, inklusive folgendem Bild:
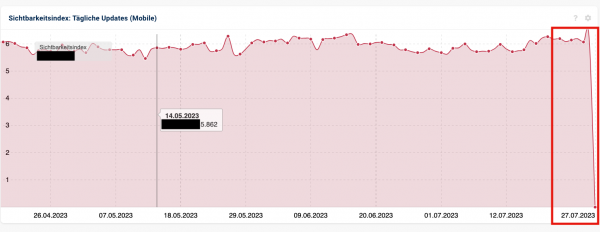
Auf dem Bild wird deutlich, die Sistrix-Sichtbarkeit ist von ca. 6 auf 0 abgefallen. Das ist natürlich erstmal besorgniserregend.
Was kannst Du in einer solchen Situation tun?
Ruhig bleiben und erstmal tief durchatmen. 🧘 Deinem Kunden oder Deinem Team zeigen, dass Du da bist und Dich kümmerst. 🤝 Dir ein zweites Paar Augen ins Boot holen – gemeinsam segelt man besser durch einen Sturm. ⛵ Jetzt geht es in die Analyse! 🧪 Sind andere auch betroffen? ➡️ In dem gezeigten Screenshot war nur der tägliche Sichtbarkeitsindex betroffen. Alle anderen Berichte schienen normal. Zusätzlich hat uns der Komplettverlust stutzig gemacht. Daher haben wir geprüft, ob weitere Domains betroffen sind. Ergebnis: Ja, aber nicht alle. Vielleicht ein Bug? ➡️ Das sprach dennoch für einen Bug. Wir haben uns also an den Sistrix-Support gewandt. Live-Check ➡️ Parallel haben wir geprüft, ob die Seite überhaupt erreichbar ist und ob es Änderungen in der Robots.txt gab. Ergänzend haben wir die Rankings direkt bei Google überprüft. Hier war alles im grünen Bereich und unsere Rankings vorhanden. GSC-Check ➡️ Auch in der GSC sah alles normal aus. Es gab keine Auffälligkeiten im Performance Report, den Crawl Stats und auch keine Penalty. Spricht alles für einen Sistrix-Bug 🪲
Genau diesen Zwischenstand haben wir dann erstmal an den Kunden gebeamt und konnten wenig später auch offiziell Entwarnung geben:
"[...] Wie es scheint, haben ein paar mobile Daten von heute gefehlt, die Kollegen bei der Entwicklung haben ein wenig nachgeholfen, laut Aussage sollten nun auch die anderen Domains wieder normale Daten für heute
anzeigen. [...]"
Und unsere Sichtbarkeit war auch wieder auf dem erwarteten Stand:
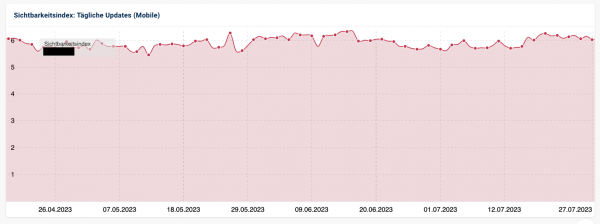
Puhh, auf den Schreck erstmal einen Kaffee! ☕ Ist Dir so etwas schon einmal passiert?
|
|
| Ausmisten des Heuhaufens lohnt sich, sofern die Nadel kein rostiger Nagel ist |
In der SEO-Sprechstunde wurde John Müller neulich gefragt, ob das Eindampfen eines Großteils des URL-Inventars in einem Shop dabei helfen kann, den in der Google Search Console (GSC) kommunizierten Fehler "Discovered - currently not indexed" zu beheben.
Konkret ging es darum, aus 8 Millionen Produktdetailseiten (PDPs) durch Deindexieren und Aggregieren 2 Millionen zu machen, wie Roger Montti im Search Enginge Journal dokumentiert.
Discovery, Crawling, Indexing, Ranking
Vorsicht bei der Lektüre des SEJ-Artikels! Da geht mit Blick auf die Begriffe "Crawling" und "Indexing" einiges durcheinander.

Für gute Rankings in den Suchergebnissen muss Google die URLs mit Deinen relevanten Inhalten finden, crawlen, verarbeiten, einordnen und gemessen am Wettbewerb bewerten.
Discovered - currently not indexed
Dieses Problem fällt laut GSC in den Entscheidungsbereich von Google. Im Gegensatz zum noindex-Metatag gibt es hier keinen Knopf oder eine Direktive, die wir als Website-Betreibende ein- oder ausschalten können, um das Problem zu beheben. In Googles Dokumentation heißt es hierzu:
"The page was found by Google, but not crawled yet. Typically, Google wanted to crawl the URL but this was expected to overload the site; therefore Google rescheduled the crawl. This is why the last crawl date is empty on the report."
Google hat mit der Einschätzung, ob es sich um gute (nützliche) oder schlechte Inhalte handelt, noch gar nicht begonnen, da die URLs noch gar nicht gecrawlt worden sind.
Du bist Google trotzdem nicht hilflos ausgesetzt
Natürlich haben wir indirekt trotzdem Einfluss auf dieses Problem. John gibt keine konkrete Antwort auf den Einzelfall, bringt aber generelle Prinzipien und Ressourcen ins Spiel, die Du mit Blick auf die eigene Situation prüfen kannst, um zu einer Entscheidung zu kommen:
Er verweist auf den Large site owner's guide to managing your crawl budget, damit Du sicherstellen kannst, dass Deine Website mit mehr Crawling durch Google überhaupt umgehen kann. Als nächstes strapaziert John die "Overall site quality". Nur wenn sich die Qualität Deiner Domain durch das Eindampfen des URL-Inventars um ein Viertel von 8 auf 2 Millionen verbessert, hält er die Maßnahme für zielführend – andernfalls versenkst Du viel Zeit und Ressourcen und kommst trotzdem nicht vom Fleck.
Technische Hebel
Je größer Deine Domain, desto größer ist auch der Hebel, den Du mit Technical SEO in der Hand hältst. Sorge dafür, dass Dein Server schnell und erreichbar ist und nur wertvolle Ressourcen gecrawlt werden:
Die GSC berichtet Dir in den Crawl Stats von "inacceptable fail rates", weil Dein Server nicht angepingt werden kann oder die Antwortzeiten Deines Servers liegen regelmäßig oberhalb von durchschnittlich 700 oder sogar 1.000 Millisekunden? ➡️ Dann kann Dich ein Serverupdate nach vorne bringen. Verlinke intern ausschließlich auf URLs mit Status 200. Erstelle und melde nur Sitemaps via robots.txt und GSC, die ausschließlich URLs mit Status 200 enthalten, indexierbar sind und rankingwürdigen Content enthalten. Googlebot hat sich in Deine Schriftarten verliebt und hört trotz passender Caching-Settings nicht auf, diese wieder und wieder zu crawlen? ➡️ Trau Dich wie Johan, diese Ressourcen per robots.txt für den Bot zu blockieren. Das PPC-Team schaltet regelmäßig Google Ads auf URLs mit Status Code 301 und der Adsbot frisst laut Crawl Stats mehr als 5-10 Prozent des Crawl Budgets? ➡️ Gib dem Performance-Team den Hinweis, dass auch sie am besten nur auf URLs mit Status Code 200 verlinken. Die GSC zeigt Dir Probleme mit Canonicals an und es gibt demnach redundante Inhalte, bei denen Google nicht genau weiß, welche die Originale sind, die Rankings bekommen sollen? ➡️ Dann entferne inhaltliche Dubletten, deindexiere sie und/oder zieh die Canonicals nochmal glatt.
Inhaltliche Hebel
Doch Deine Website kann technisch schnurren wie ein Kätzchen, wenn die Inhalte darauf für niemanden einen Mehrwert bieten, nützt es nichts. Wenn Du den Heuhaufen entfernst und trotzdem keine Nadel zu finden ist, gibt es für Google keinen Anreiz, Deine URLs für Suchanfragen mit einem Top-Ranking vor die Nase von Menschen mit Fragen und Bedürfnissen zu setzen.
Was kannst Du also stattdessen tun?
Lies Dir die Quality Rater Guidelines mit Blick auf "3.2 Quality of the Main Content" nochmal genau durch. Dann verstehst Du, dass Google Content mit Rankings belohnen möchte, in dem hoher Aufwand, Originalität und neue Perspektiven sowie Einzigartigkeit, Erfahrung, Talent und Können eingeflossen sind, die nicht beliebig imitiert werden können.
Brand
Allerdings schaffen es bekannte Marken immer wieder, andere Seiten aus den Top-Rankings rauszuhalten, obwohl sie selbst weder technisch noch inhaltlich auf der Höhe sind. Das liegt daran, dass für bestimmte Suchanfragen wie nach der Marke selbst oder nach Themen, mit denen die Brand untrennbar verknüpft ist, ein Suchergebnis dieser Marke selbst die beste Antwort ist.
Diese Säule ist am weitesten von Deiner direkten Einflusssphäre entfernt, aber gute PR- und Marketing-Leute wissen seit Jahrzehnten, wie sie Ihre Marke mit Werbung, PR und Influencern ins passende Licht rücken und ein Image entwickeln. Product People wissen, welche Qualitäten, Lösungen und Funktionalitäten ein Produkt braucht, um am Markt bestehen zu können oder sogar geliebt zu werden.
Von diesen Maßnahmen profitiert auch SEO. Doch was können wir hier direkt beisteuern?
Über digitale PR lassen sich organische Backlinks aufbauen. Aber vielleicht überlässt SEO diesen Teil doch lieber den Hardcore-PR- und Content-Menschen. Kein manipulatives Linkbuilding, bitte! Auch Mentions, also Erwähnungen Deines Markennamens ohne Link, zählen. Baue also Kookkurrenzen Deiner Marke mit Deinem relevanten Thema auf. Wie das im Prinzip (aber nur kurzfristig) funktioniert, hat Kai Spriestersbach hier mal aufgeschrieben. Lies Dir die Quality Rater Guidelines durch, diesmal mit Blick auf "3.3 Reputation of the Website and Content Creators": Denn nicht nur Dein Produkt und Deine Website brauchen einen guten Ruf, auch die Menschen, die auf Deiner Seite veröffentlichen, sollten die typischen E-E-A-T-Kriterien (Experience/Erfahrung, Expertise, Authoritativeness/Autorität und Trustworthiness/Vertrauenswürdigkeit) mit Blick auf die Themen, über die geschrieben wird, erfüllen. Eine gute Verlinkung und Schema-Markup können dabei helfen, externe Quellen als Zeugen für E-E-A-T strukturiert für Google lesbar zu machen.
Fazit
Ich denke, dass die Reduktion der URLs um drei Viertel von 8 Millionen auf 2 Millionen durchaus viel bewirken kann. Die fragende Person sprach schließlich nicht nur vom Deindexieren, sondern auch vom Aggregieren. Das klingt danach, als würden verschiedene redundante Versionen von Produkten zusammengeführt auf nur noch eine starke URL. Das würde ich als Benutzerin und SEO sehr begrüßen.
Google kann die Seite dann viel schneller crawlen und hat weniger Canonical-Probleme, die es zu sortieren gäbe. Das sollte in der Tat helfen.
Was mich darüber hinaus beim Lesen des Artikels im SEJ zum Grübeln gebracht hat:
Letztes Jahr war die SEO-Bubble sauer und hat sich von Google benutzt gefühlt, als das Helpful Content System so riesig angekündigt wurde und dann kaum Auswirkungen spürbar waren. Google macht hier nochmal deutlich, dass sie oft Monate brauchen, um die Qualität einer ganzen Domain beurteilen zu können, wozu neben Technik und Inhalten auch Design, Layout und UX zählen.
Das bedeutet für mich, dass viele Ranking-Schwankungen in den letzten Monaten, bei denen wir den Bezug zu einem Google Update nicht mit einer klaren Abbruch- oder Aufschwungkante in Zusammenhang bringen konnten, insgeheim doch mit dem Wirken des Helpful Content Systems zusammenhängen.
Nach und nach gelingt es Google besser und besser, das, was sie den Quality Ratern als Ziel vorgeben, algorithmisch in Suchergebnisse zu übersetzen.
|
|
| Direkter Frosch-Zugriff mit KNIME (Teil 1) |
Bei der täglichen Arbeit mit dem Screaming Frog und den Auswertungen der Daten hat mich immer der Umweg über die CSV-Exportdateien gestört. Gerade mit KNIME gehören fixe Prozesse und Daten-Sheets doch der Vergangenheit an. Im letzten Newsletter hatte ich angekündigt, dass ich Dir zeige, wie Du auf Screaming Frog Exporte direkt zugreifen kannst. Jedoch fand ich diesen (Um)Weg immer noch zu kompliziert. Aus diesem Grund habe ich mir die Frage gestellt, ob ein direkter Datenbankzugriff auf die Daten im Screaming Frog möglich ist.
Und die Antwort lautet „ja", solange Du in den Einstellungen den „Storage Mode" auf „Database Storage" gestellt hast, kannst Du direkt auf Deine Crawls mit SQL und etwas Magie zugreifen!

(Bild erstellt mit Bing Image Creator)
Wie das genau funktioniert und welche Schritte Du durchführen musst, um ebenfalls in den Genuss diesen genialen Features zu kommen, zeige ich Dir in diesem Step by Step Guide:
1. Derby-Treiber installieren
Als Erstes benötigen wir einen aktuellen Derby-Datenbank-Treiber, den wir hier herunterladen können. Der Treiber ist ein JDBC-Treiber und wird benötigt, damit KNIME (und andere Programme) auf die Screaming Frog-Daten zugreifen können. JDBC steht für „Java Database Connectivity" und ist eine universelle Datenbankschnittstelle für Java und in Java entwickelte Programme.
2. Wo findest Du nun Deine Crawl-Daten?
Dazu habe ich Dir ein kleines Tool in PHP gebastelt. Mit diesem kannst Du Dir den jeweils benötigten „Verbindungs-String" eines bestimmten Crawls anzeigen lassen. Danach musst Du diese Zeichenkette nur noch via Copy&Paste in Deine Programme übernehmen, um Dich mit dem jeweiligen Crawl zu „verbinden".
Öffne ein Terminal auf Deinem Rechner Lade das Script an die Stelle, an der Du mit dem Script arbeiten möchtest. Starte das Script mit dem Kommando "php sfadmin.php". Danach wirst Du dieses Menü sehen.
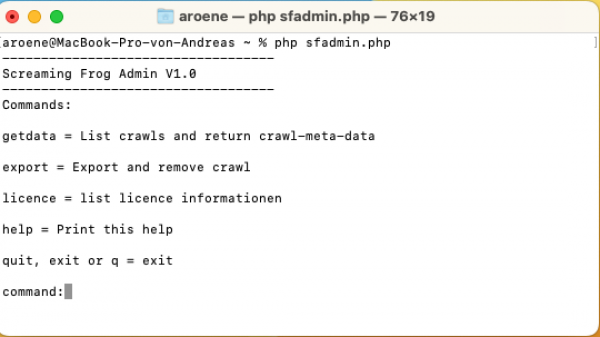
(Das Script wartet auf die Eingabe eines Kommandos)
- Gib das Kommando "getdata" ein. Das Script listet alle im Frog gespeicherten Crawls auf.
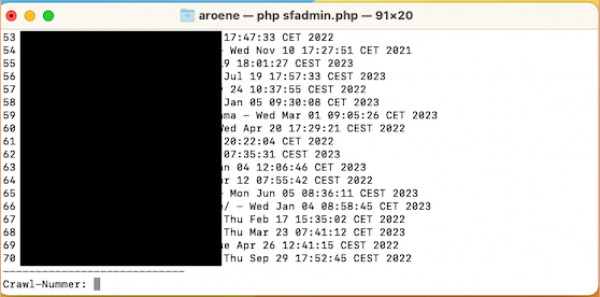
(Nach dem Kommando "getdata" listet Dir das Script alle verfügbaren Crawls auf.)
- Wähle jetzt Deinen gewünschten Crawl aus, indem Du die Zahl vor dem Crawl eingibst und dies mit Enter bestätigst. (0 bringt Dich zurück ins Hauptmenü)
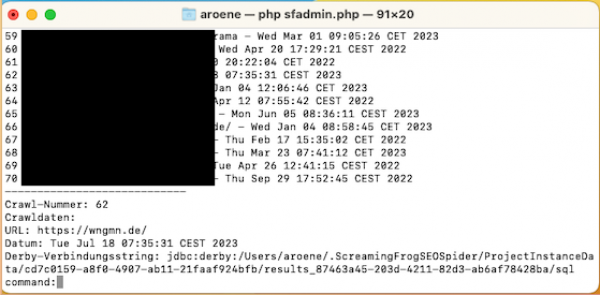
(Das Script gibt nun die wichtigsten Daten des Crawls aus. Unter anderem den Derby-Verbindungsstring)
3. Erster Blick in die Datenbank mit DBeaver
Aber wozu benötigen wir jetzt den DBeaver? Ganz einfach: Derby unterstützt „nur" die Datenbanksprache SQL-92. Diese schränkt KNIME in der aktuellen Version noch sehr stark in der Zusammenarbeit mit Derby ein. Um Dir die Struktur der Datenbank besser zu verdeutlichen, nutzen wir ein freies Datenbank-Tool, das hier eine bessere Unterstützung bietet.
Datenbankverbindung anlegen:
Suche in den Verbindungen nach "Derby". Die Verbindungsart "Derby Embedded"ist die Version, die wir für den Frog verwenden müssen.
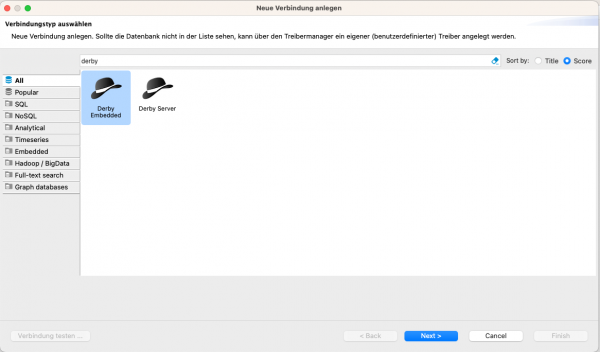
(Wähle in diesem Dialog "Derby Embedded" aus)
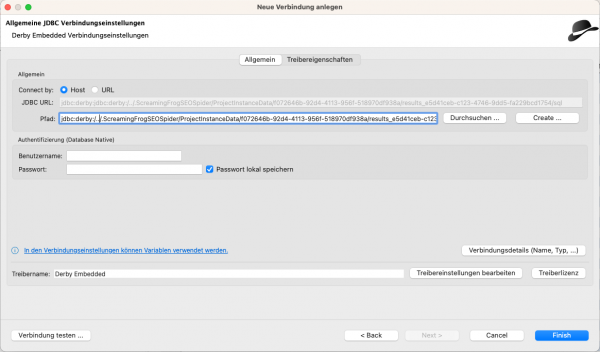
(Füge den Verbindungs-String aus der Zwischenablage in dem Feld "Pfad" ein.)
Prüfen, ob der Datenbanktreiber in der aktuellen Version 10.16.X genutzt wird:
Klicke dazu auf den Button "Treibereinstellungen bearbeiten"
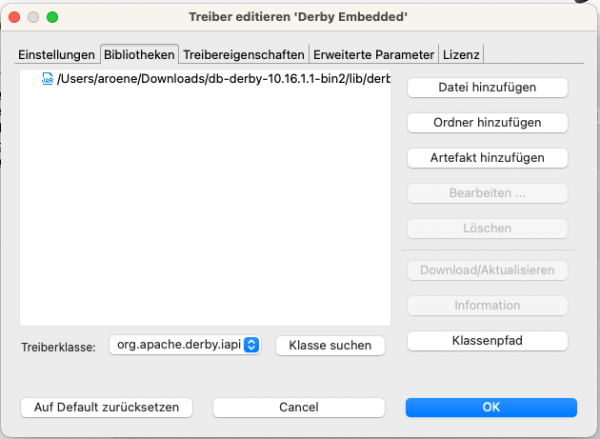
Sollte hier noch eine andere (ältere) Version installiert sein, so müssen wir diese entfernen und unsere als erstes heruntergeladenen Treiber über "Datei hinzufügen" einbinden. Suche in Deinem Download nach dem Verzeichnis "db-derby-10.16.x.x-bin", dort ist das Verzeichnis "lib" enthalten und darin die Datei "derby.jar". Diese musst Du in dem Dialog auswählen.
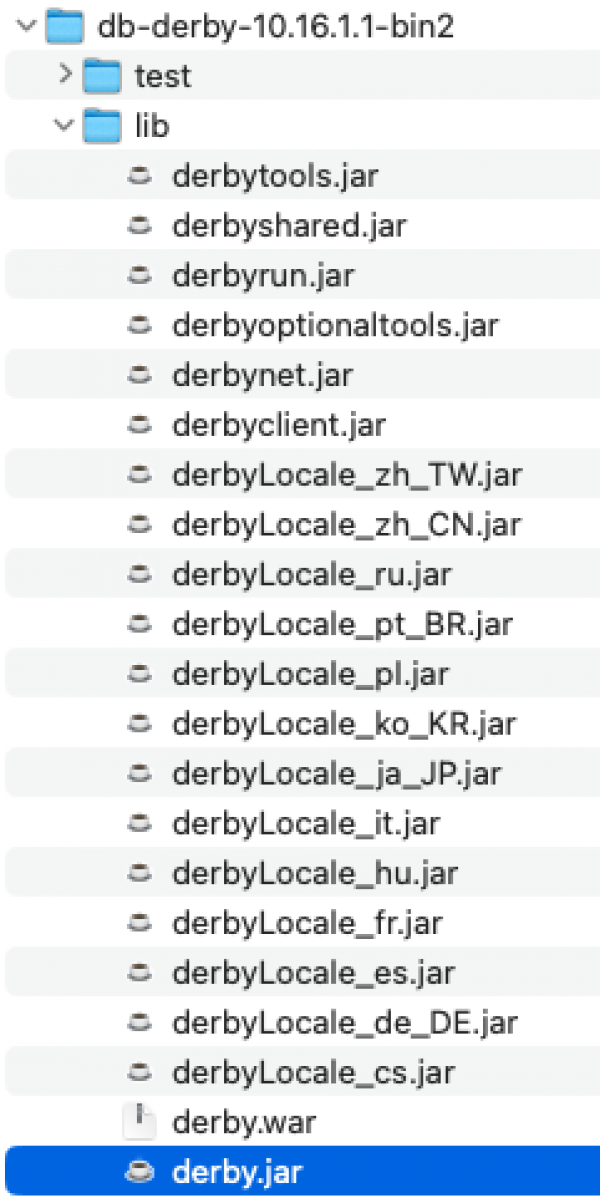
Danach kannst Du mit einem Klick auf "Klasse suchen" checken, ob der richtige Treiber gefunden und genutzt wird: Die Pull-down-Liste links neben dem Button sollte sich nun mit Klassennamen gefüllt haben. Ausgewählt ist hier "org.apache.derby.iapi.jdbc.AutoLoadedDriver".
Danach können wir den Dialog mit einem Klick auf "OK" schließen.
Das Verzeichnis zur eigentlichen Datenbank haben wir ja schon ausgewählt und so können wir den Dialog "Verbindungseinstellungen" ebenfalls mit einem Klick auf "OK" schließen.
Herzlichen Glückwunsch! Du hast Deine erste Datenbankverbindung eingerichtet. Du solltest nun in der Baumstruktur einen neuen Knoten mit Deiner Verbindung sehen. Wenn Du diesen nun mit einem Klick öffnest, erscheint die Datenbankstruktur Deines Crawls.
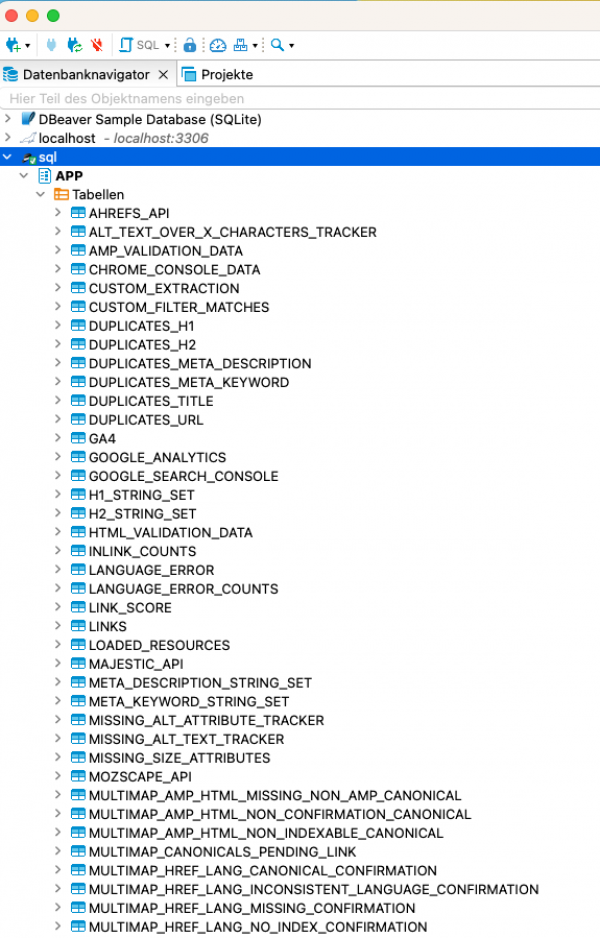
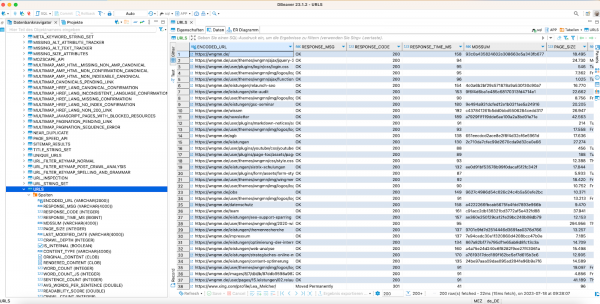
Was Du bei Deiner Arbeit mit Derby-Datenbanken beachten solltest:
Auf Derby-Datenbanken kannst Du nur mit Programmen zugreifen, die JDBC als Datenbankschnittstelle unterstützen. Dies sind in der Regel daher „nur" JAVA-Anwendungen Programme haben auf Derby-Datenbanken im "Embedded" Modus einen exklusiven Zugriff. Das bedeutet, es kann immer nur ein Programm aktiv auf eine Datenbank zugreifen. Dies kann bei beim Wechsel zwischen DBeaver und KNIME häufiger mit einer Fehlermeldung enden. Du musst hier leider immer zwischen den Programmen sauber beenden bzw. die Datenbankverbindung schließen und nach kurzer Zeit benötigst Du DBever auch kaum noch, da Du die Struktur der Datenbank verinnerlicht hast.
Im nächsten Newsletter stellen wir dann die Verbindung direkt in KNIME her und erstellen die ersten Nodes.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





