|
Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #117
|

|
|
🤦 Sag noch einmal helpful SEO-Content…
|
|
Wisst ihr noch... damals... als Google gesagt hat, Pagespeed wird zum Rankingfaktor und alle panisch wurden und ganz schnell alle Regler auf 100% bringen mussten und dafür alles haben stehen und liegen lassen?
Wie schön wäre es doch, wenn man daraus gelernt hätte... Und Dinge mal für die User und nicht zum Austricksen der Suchmaschinen machen würde. Sich mal in den Intent der Suchenden reinversetzt hätte und auch mal gesagt hätte: "Nein, für diese Listing-Seite von Schnürsenkeln brauchen wir keinen Kaufratgeber!".
Ich schreibe hier in einer entspannenden Melange aus Vorfreude aufs Update (immerhin können wir ja bei den Amis zuerst gucken, was passiert und zur Not dann noch hektisch werden), meinen Yoga-Übungen für die nächste Paar-Übung mit Marcus Tandler und dem Schmökern der heutigen Newsletter-Themen.
Heute in Yoga-Stellung:
-
Johan malt im Trikonasana die GSC neu an
-
Hannah im Salabhasana über Neuigkeiten zum Product-Markup
-
Anita im Pada Hasthasana zum Helpful Content Update
-
Jolle im Kakasana auf den Spuren des indexifembedded-Experiments
-
Nora bringt das Knowledge Panel ohne Wikipedia ins Savasana
In diesem Sinne... Namasté und viel Spaß beim Lesen!
Eure Wingmenschen
|
|
|
Ein neuer Anstrich für den GSC-Coverage Report
|
|
Der Search Console Coverage Report hat sich geändert
:

Die wichtigsten Änderungen im Überblick:
-
Es gibt nur noch "Indexiert" und "Nicht indexiert", die komische Rubrik „Warning" ist verschwunden.
-
Dafür können wir jetzt alle Berichte filtern auf: "All Submitted Pages" (also URLs in Sitemap, das ging vorher schon) aber auch auf "Unsubmitted Pages Only" (Endlich, denn bisher ging das nicht, dass man Fehlerberichte gezielt nach nicht in Sitemap übermittelten URLs filtern konnte).
-
Dafür fehlt leider die übersichtliche Darstellung "URLs im Index", "davon in Sitemaps", "davon nicht in Sitemaps". Das muss man sich jetzt mit drei Klicks selbst zusammensammeln. Für viele Webmaster kleiner Seiten bestimmt weniger verwirrend. Für uns mit vielen großen Seiten kostet das ein paar Minuten im Monat.
-
Die sparen wir aber, da auf der Übersicht direkt eingeblendet wird, warum URLs nicht indexiert sind.
-
Bei den Fehlerberichten gibt es ein paar kleine Verschiebungen. Sehr gelungen finde ich aber die Aufteilung auf die Quelle des Fehlers "Website" oder "Google Systems". Das ermöglicht Google elegant "Crawled not indexed" und "Found not crawled" aus der Übersicht zu schieben. Aber es erleichtert die Kommunikation deutlich.
-
Die Aufsplittung nach Sitemap/Nicht in Sitemap zieht ein paar Änderungen nach sich in den Fehlerberichten. "Submitted URL not Canonical" ist jetzt nicht mehr aufgelistet. Dafür kann man die Canonical-Fehlerberichte jetzt nach "in Sitemap" und "nicht in Sitemap filtern"
-
Die alten Warnings sind jetzt in "Improve appearance" gruppiert.
Insgesamt: Deutlich strukturierter, aber einige Fehler - die man sofort gesehen hat in der Vergangenheit - in Bezug auf Sitemaps muss man jetzt ein bisschen intensiver zusammenklicken. Ich muss noch ein wenig intensiver damit arbeiten - aber ich glaube, ich kann mich daran gewöhnen.
Ach ja - wenn Du Dich wunderst, warum Dir womöglich ein paar indexierte Seiten abhanden gekommen sind: Das hat mit der veränderten Darstellung nichts zu tun. Aber damit, dass Google in der Vergangenheit nicht indexierte Seiten als indexiert reportet hat. Upsi!
Diese Fehler wurde nun gefixt
, was sich entsprechend auf die Anzahl der reporteten indexierten Seiten auswirkt.
|
|
|
Google macht es offiziell: Neue Erweiterung für Product Markup
|
|
Sind Dir die Pros und Cons in den SERPs auch schon aufgefallen? Bereits seit einigen Monaten kann man darüber in der freien Wildbahn stolpern.
Anfang August hat Google nun offiziell eine neue
Erweiterung für das Product Markup
vorgestellt. Somit kannst Du die Vorteile und Nachteile zu einem Produkt künftig mit strukturierten Daten auszeichnen.
"You can tell Google about your pros and cons by supplying pros and cons structured data on editorial review pages"
Im Snippet sieht das dann beispielsweise so aus:
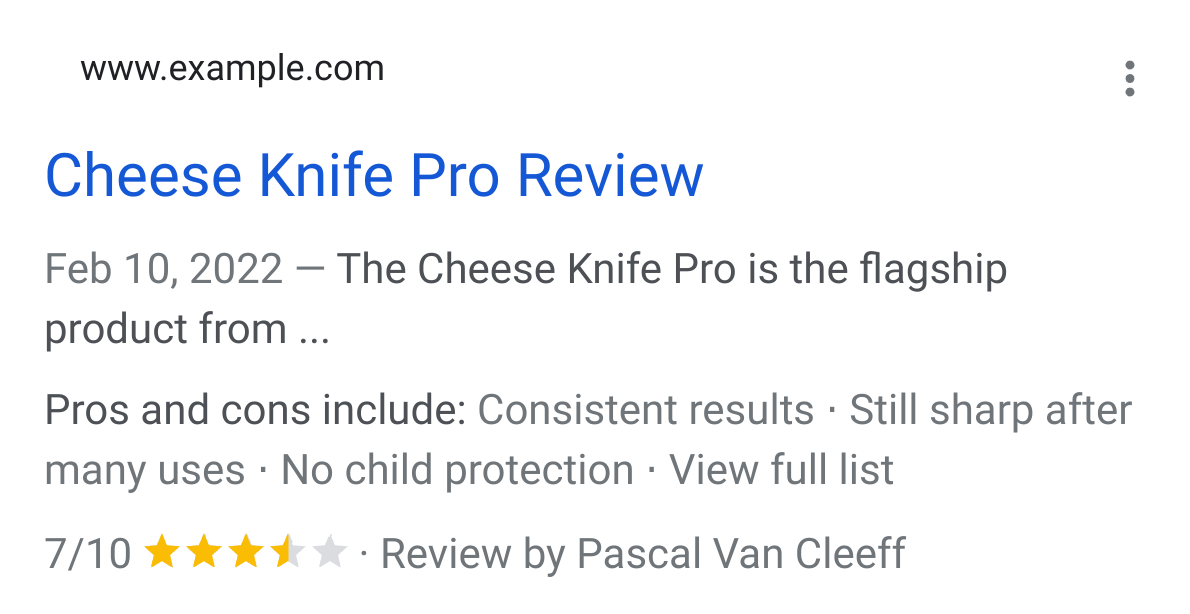
Bisher konntest Du neben den üblichen Angaben zum Produkt folgende Ergänzungen nutzen:
-
Shipping Details
-
Price Drop
Die dritte Erweiterung im Bunde sind nun
Pro und Cons
.
Wenn Du zwar über Vorteile und Nachteile berichtest, aber (noch) keine strukturierten Daten nutzt, wird Google übrigens trotzdem versuchen, die wesentlichen Infos zu extrahieren und darzustellen.
"If you do not provide structured data, Google may try to automatically identify pros and cons listed on the web page. Google will prioritize supplied structured data provided by you over automatically extracted data. We tested this with website owners, and received positive feedback on this capability."
Mit dem neuen Datentyp hast Du es aber selbst in der Hand, was Google anzeigt - denn von Dir bereitgestellte Inhalte werden laut Google gegenüber automatisiert herausgezogenen Daten bevorzugt.
Dem bestehenden Product Markup werden dabei einfach nur zwei Item Lists hinzugefügt:
"positiveNotes": {
"@type": "ItemList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"name": "Consistent results"
},
{
"@type": "ListItem",
"position": 2,
"name": "Still sharp after many uses"
}
]
},
"negativeNotes": {
"@type": "ItemList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"name": "No child protection"
},
{
"@type": "ListItem",
"position": 2,
"name": "Lacking advanced features"
}
]
}
Die Properties "positiveNotes" und "negativeNotes" müssen nicht zwangsläufig im Set auftreten, Du kannst auch nur eine davon nutzen.
Dabei ist natürlich wichtig, dass der in den strukturierten Daten bereit gestellte Text tatsächlich auch auf der Website zu finden ist:
"Note that the text in the structured data must match the text on your page."
Achtung - aktuell sind die Pros und Cons nur für redaktionelle Reviews verfügbar:
"Currently, only editorial product review pages are eligible for the pros and cons enhancement in Search, not merchant product pages or customer product reviews."
Oder wie
Nati Elimelech es auf Twitter formuliert
:
"A reminder: You can tell Google about the pros and cons of
a
product, but not
your
product. This is only relevant for product review pages rather than PDPs."
Wobei das "currently" impliziert, dass hier eine Erweiterung auf andere Seitentypen in der Zukunft nicht unwahrscheinlich ist.
Die
Richtlinien für die Pros und Cons
umfassen derzeit neben der Einschränkung auf "editorial product review pages" und der Anforderung, dass der Inhalt auch auf der Seite für Nutzer sichtbar vorhanden sein muss noch einen dritten Punkt:
"There must be at least two statements about the product. It can be any combination of positive and/or negative statements (for example, ItemList markup with two positive statements is valid)."
Wie immer solltest Du daran denken, die strukturierten Daten mithilfe der
Testing Tools
und (nach erfolgter Implementierung) der Google Search Console zu validieren..
|
|
|
Helpful Content Update
|
|
Google hat Ende letzter Woche ein neues Update angekündigt:
Das "Helpful Content Update"
oder kurz "HCU", wie es an einigen Stellen bereits genannt wurde.
Worum geht es beim Helpful Content Update?
Ziel des Updates ist es, hilfreiche, authentische, unique, hochwertige Inhalte, die von Menschen für Menschen verfasst wurden, in den Fokus zu stellen:
"...better surface original, helpful content made by people, for people, rather than content made primarily to gain search traffic."
Denn:
"Many of us have experienced the frustration of visiting a web page that seems like it has what we're looking for, but doesn't live up to our expectations. (...) We know people don't find content helpful if it seems like it was designed to attract clicks rather than inform readers."
Nein zu AI-Texten, SEO-Content & Co.
Gibt es einen Grund zur Panik? Oder ist es einfach nur eine aufregende News, die einen mittelfristig nicht direkt betrifft?
Der weltweite Rollout für Englisch startet diese Woche. Falls Du also keine englischsprachigen Inhalte anbietest, kannst Du Dich erstmal entspannt zurücklehnen und schauen, was passiert. Es lohnt sich aber schon jetzt, die eigene deutsche Seite HCU-sicher zu machen.
Auffällig ist: Google betont mehrfach, dass es ihnen um Inhalte von Menschen für Menschen geht:
"created for, or even by, a person"
"made by, and for, people"
Das ist ein klares NEIN zu
-
AI-generated Content
-
dem, was einige unter "SEO Content" verstehen
-
Inhalten, die nicht wirklich hilfreich, informativ, einzigartig und mehrwertig sind
-
"unoriginal, low quality content"
-
"content that doesn't meet a visitor's expectations"
-
irgendwelchen übernommenen oder nur leicht umgeschrieben Texten und Passagen
Google erwartet basierend auf Tests vor allem eine Verbesserung der Ergebnisse in diesen Bereichen:
-
Online-Bildung
-
Kultur und Unterhaltung
-
Shopping
-
Inhalte mit Technikbezug
Das HCU geht Hand in Hand mit den derzeit stattfindenden Bemühungen um hochqualitative Product Reviews und hat das erklärte Ziel:
"...reduce low-quality content and make it easier to find content that feels authentic and useful in Search."
Der Mensch steht im Mittelpunkt
Ergänzend zur Ankündigung stellt Google ein paar tiefergehende Informationen für Content-Erstellerinnen und Ersteller bereit:
What creators should know about Google's helpful content update
.
Unter den Überschriften "Focus on people-first content" und "Avoid creating content for search engines first" listet Google dort eine Reihe von Fragen. Wenn Du diese "richtig" beantworten kannst (ja im ersten und nein im zweiten Abschnitt), musst Du Dir im Hinblick auf das Helpful Content Update keine Sorgen machen.
Google macht auch deutlich, dass sich das Erstellen von Nutzer-zentriertem wertvollen Content und das Anwenden von SEO Best Practices nicht gegenseitig ausschließen:
"People-first content creators focus first on creating satisfying content, while also utilizing SEO best practices to bring searchers additional value."
Die Message ist glasklar: Humans first, SEO second.
Was genau passiert jetzt?
Unter
Google Search ranking updates
kannst Du verfolgen, wann der Rollout des Helpful Content Updates startet und wann er abgeschlossen ist. Schätzungsweise nach 2 Wochen.
Es handelt sich dabei um ein neues, seitenweites Signal:
"Any content --- not just unhelpful content --- on sites determined to have relatively high amounts of unhelpful content overall is less likely to perform well in Search (...). For this reason, removing unhelpful content could help the rankings of your other content."
Barry Schwartz liefert auf Search Engine Land eine
gute Erklärung
, was "sitewide" bedeutet:
"That means that if Google determines your site is producing a relatively high amount of unhelpful content, primarily written for ranking in search, then your whole site will be impacted."
"This will not just impact individual pages or sections of your site, but rather, it will impact the whole site."
Das heißt zusammengefasst:
-
auch hochwertige Inhalte performen schlechter, wenn es viele Inhalte gibt, die im Sinne des Updates nicht hilfreich sind
-
durch das Entfernen und/oder Deindexieren dieser unerwünschten Inhalte kann sich das Ranking der guten Inhalte verbessern
Laut
John Müller
wird viel Content, der sich vom Qualitätsaspekt eher in der "gray area" befindet, nicht zwingend im ersten Rollout betroffen sein. Wen es jetzt nicht trifft, kann es aber künftig erwischen. Für Leserinnen und Leser ist dieser Content schon jetzt eine Belastung -- und die Domain nicht zukunftssicher.
Wie lange dauert es, bis sich eine Domain ggf. aus einem HCU-Tal herausarbeiten kann?
Sollte man von diesem Update betroffen sein, kann es einige Zeit dauern, bis man sich davon erholt, selbst wenn man sich zügig an die Überarbeitung und Löschung der Inhalte macht.
"... it can take several months for the site to recover. A site needs to prove itself over time that it no longer publishes content with the sole reason to rank in search engines, a search engine first content experience, and that takes time."
Barry Schwartz, Search Engine Land
"do not push short-term changes, only to revert back to old ways. Keep the right changes in place over the long-term. Don't cherry pick changes... tackle "unhelpful content" aggressively. That's how you can see recovery from the Helpful Content Update."
Glenn Gabe, G-Squared Interactive
Die SEO-Bubble reagiert vor allem mit AI-Content-Kritik:
"This is why I was never a fan of AI content. All my research shows users don't like it. Google seems to agree." -
Ryan Jones
"good, so much AI-generated junk plaguing SERPs over the past 12 months. almost felt like a second generation of keyword stuffing. glad i never gave in and kept writing everything for clients like a real human." -
Jeeves Williams
"Hoping and preying that this tackles the AI spam that's been plaguing the SERPs for months 🙏" -
Introvert Geek
Und Danny Sullivan gibt Grund zur Hoffnung, dass genau das der Zweck hinter dem Update ist:
Lily Ray stellt in ihrer Zusammenfassung zum Update die E-A-T-Kriterien ins Zentrum
. Zu Recht! Denn Google kommt hier nicht wie Kai aus der Kiste mit einem völlig neuen Ansatz um die Ecke. Was Google unter Qualität versteht, wird mit jedem Update deutlicher. Deshalb passen die Fragen, die sich Content Creators laut dem Helpful Content Update stellen sollen, perfekt in den Fragenkatalog, den Google über vergangene Updates hinweg erstellt hat.
Danny Goodwin liefert die konsolidierten Fragen der "H
elpful Content
(HCU),
Product Review
(PRU),
Core
(CU) and
Panda
Updates (PU) in der handlichen Übersicht
.
Für
Wil Reynolds bedeutet das Update einmal mehr: "Stay in your lane"
. Große Publisher sind nicht automatisch die beste Quelle, wenn es Nischen-Publikationen mit mehr Fachexpertise gibt.
Wir sind gespannt, was in den nächsten zwei Wochen während des Rollouts passieren wird!
|
|
|
Kleines, aber feines SEO-Experiment zu indexifembedded
|
|
Im Januar 2022 gab
Google die Existenz eines neuen Robots Tags bekannt: "indexifembedded"
und
Nora berichtete im Newsletter
, was es damit auf sich hat.
In welchen Fällen die eingebetteten Elemente, wie beispielsweise PDFs, im Index landen oder nicht, hat
Dave Smart
in einem super strukturierten Experiment aufgedröselt und für
TameTheBots
dokumentiert.
Dave zeigt, auch mit einer kleinen Test-Domain, die vermutlich nicht den Traffic für statistische signifikante Splittests aufweist, lässt sich ein Proof of Concept sauber ausarbeiten.
Dazu hat er sechs verschiedene Seiten angelegt, jeweils einen uniquen Textabschnitt ins HTML gepackt und weiteren Inhalt (PDF oder HTML) per iframe eingebettet. Die Seiten unterschieden sich wie folgt:
-
HTML-Embed mit noindex & indexifembedded
-
HTML-Embed nur mit noindex
-
HTML-Embed ohne Robots Meta Tag
-
PDF-Embed mit X-Robots-Tag im HTTP-Header: googlebot: noindex, indexifembedded
-
PDF-Embed mit X-Robots-Tag im HTTP-Header: googlebot: noindex
-
PDF-Embed ohne X-Robots-Tag im HTTP-Header
Die sechs Seiten hat Dave per Sitemap an Google gemeldet und das Indexierungsverhalten an drei Stellen überprüft:
-
URL Inspection Tool: Crawled HTML
-
URL Inspection Tool: Live Test
-
Auf der Suchergebnisse selbst (SERP)
Sein Verdikt: Funktioniert so, wie es soll. Da, wo Dave es nur als "sort of expected" eingestuft hat, führt er es darauf zurück, dass er eigentlich keine klare Vorstellung davon hatte, wie es funktionieren soll.
Während ich Anfang des Jahres noch unsicher war, wofür man das neue Tag genau gebrauchen kann, hat das Experiment die Use Cases für mich verdeutlicht. Inhalte eines PDFs suchen zu können, sodass der Content auf die HTML-Seite einzahlt und nicht das PDF selbst im Index landet, finde ich tatsächlich nützlich.\
Schau Dir die
Ergebnisse direkt bei Dave
an. Abschauen können wir uns alle die klare Struktur und sorgfältige Dokumentation des Experiments. Was meinst Du?
|
|
|
Ohne Wikipedia Eintrag kein Knowledge Panel? 🧐
|
|
Gefühlt jeder bekannte Serientäter oder Prominente hat eins - Das Knowledge Panel. Aber die haben halt auch einen Wikipedia Eintrag und ohne gibt es kein Knowledge Panel, oder?
It depends - Denn Du kannst auch ohne einen Wikipedia Eintrag ein Knowledge Panel bekommen.🎉 Rein technisch kann Google Informationen für das Knowledge Panel nämlich von jeder crawlbaren Webseite verwenden. Wichtig ist hier nur, dass die Informationen korrekt, strukturiert und konsistent vorliegen und Wikipedia hat sich hier als zuverlässige Quelle für Google bewiesen. Wie Du jetzt ohne den Wikipedia-Eintrag ein Knowledge Panel bekommen kannst, zeigt John McAlpin in seinem Artikel
"How I earned a knowledge panel without a Wikipedia page"
.
Dafür gibt er folgende Tipps:
-
Du brauchst eine "Über-mich-Seite", die die wichtigsten Informationen zu Deiner Person und Deinen letzten Projekten enthält. 🧑
-
Wenn Du noch in anderen Projekten, Unternehmen oder Netzwerken aktiv bist, ist es gut, wenn diese untereinander verlinkt sind und so die Expertise und die Glaubwürdigkeit Deiner Hauptseite stärken. 🔗
-
Mithilfe von strukturierten Daten kannst Du dann die verschiedenen Informationen und Seiten miteinander verknüpfen. Dafür bietet sich das
Person-Markup
an. Falls Dich dieses Thema mehr interessiert, gibt es weiter unten auch noch einen kleinen Video-Tipp für Dich. 😉
-
Als letzten Tipps empfiehlt John McAlpin einen
Eintrag in die Datenbank von Crunchbase
.
Auch wenn Du all diese Tipps beherzigst, gibt es leider keine Garantie, dass Google ein Knowledge Panel ausspielt. Außerdem solltest Du eine Menge Geduld mitbringen.
Wie sich ein Knowledge Panel dann über die Zeit entwickeln kann, kannst Du in dem Artikel von John McAlpin oder in dem Blogbeitrag
"How to build a Knowledge Panel for your name or brand"
von Gus Pelogia nachlesen. Hast Du Dich eigentlich mal gefragt, was der Unterschied zwischen dem Knowledge Graph und dem Knowledge Panel ist? 🤔
Exkurs: Was ist eigentlich der Unterschied zwischen dem Knowledge Graph und dem Knowledge Panel?
Der
Google Knowledge Graph
ist eine riesige Datenbank mit Milliarden Fakten über Personen, Orte und Dinge. Zu diesen Entitäten speichert Google die Fakten und (wenn vorhanden) die jeweiligen Beziehungen untereinander. Wie das zu einem Query ausschaut, kannst Du Dir übrigens über die
Knowledge Graph API
ausgegeben lassen. Die Informationen aus dem Knowledge Graph können dann als Knowledge Panel in den Suchergebnissen auftauchen. Das kannst Du Dir auch nochmal in diesem
kurzen Video von Google zum Knowledge Graph
anschauen. 🎥
|
|
|
Futter für Deine Video-Playlist 🍿
|
|
Wenn Dein SEO-Hunger noch nicht gestillt ist, dann haben wir hier zwei Video-Tipps aus der letzten Woche für Dich:
-
Hannah und Nora waren mit ihrem Vortrag von der diesjährigen Contentixx bei
Alex Breitenbach
von RYTE in der täglichen Dosis SEO zu Gast. Hier kannst Du Dir die Aufnahme anschauen:
LinkedIn
/
YouTube
. Live(stream) ist Dir lieber? Dann merk Dir schon mal das SEO Meetup Hamburg für November vor!
-
Im SEO Meetup Hamburg durfte Anita gemeinsam mit
Florian Elbers
die geschätzte
Johanna Maier
von DEPT mit ihrem Vortrag zur Programmable Search Engine begrüßen. Auch davon gibt es
eine Aufzeichnung
.
Also pack' schon mal das Popcorn aus! 🍿
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an
[email protected]
oder
ruf uns einfach kurz an:
+49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





