| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #247 |
|

|
| 🎭 Vorhang auf für die SEO-Bühne dieser Woche! |
Ob großes Drama, leise Töne oder laute Paukenschläge: In der SEO-Welt wird täglich ein neues Stück aufgeführt. Google als unberechenbarer Regisseur, die Algorithmen als wandelbares Drehbuch und wir alle mitten im Geschehen. Doch keine Sorge, wir haben das Programmheft für Dich und liefern Dir die spannendsten Akte direkt ins Postfach!
Diese Woche auf der Bühne:
- Matt enthüllt die Anzahl der Google-Suchanfragen im Laufe eines Jahres.
- Florian berichtet über die, die absichtliche Verschlechterung der Google-Suchergebnisse zur Erhöhung der Suchanfragen.
- Cleo erklärt Dir, wie Du Deine Sichtbarkeit durch Bildoptimierung verbesserst.
- Johan erzählt von Deep Research.
- Nils navigiert Dich durch die Haftung für Snippets.
Lehn Dich zurück, genieße die Vorstellung und wie immer:
Viel Spaß beim Lesen!
Deine Wingmenschen 🎭
|
|
| There are 5 Trillion Annual Queries in Google Search |
Nachdem es dazu schon eine Weile keine aktuellen Informationen gab, hat nun Google wieder einmal ein paar Zahlen veröffentlicht, wie viele Suchanfragen im Laufe eines Jahres denn aktuell so zustande kommen. Die Antwort: 5 trillion searches, also 5 Billionen Suchen. Das ist eine Menge! Nicht zu verwechseln übrigens mit 5 Trillionen, was in Deutschland noch sechs weitere Nullen bedeuten würde.
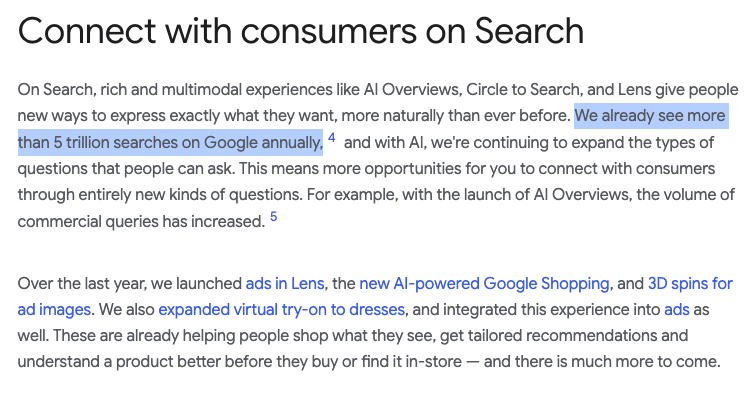
Es ist verwirrend, ich weiß… Zumal zumindest bei mir die Vorstellung, was das konkret bedeutet, ohnehin irgendwo zwischen Millionen und Milliarden verschwimmt. Ich kann die Zahl auch nicht an den gern gewählten Fußfeldern oder sonst irgendeinem konkreten Beispiel festmachen, also gibt es sie hier nun einfach einmal in voller Pracht ausgeschrieben:
5.000.000.000.000, also eine 5 mit 12 Nullen. Ganz schön beeindruckend! Im Vergleich dazu sehen die Zahlen von Perplexity, ChatGPT und DuckDuckGo geradezu mickrig aus. Hier noch einmal zum Vergleich:
Sieht auf den ersten Blick nach einer klaren Nummer aus (im wahrsten Sinne des Wortes). Und das ist es genau genommen auch. Allerdings darf man nicht vergessen, dass Perplexity erst seit August 2022 am Start ist. Und dass ChatGPT seinen großen Durchbruch erst im November 2022 hatte. “Damals” knackte der Chatbot innerhalb von 5 Tagen die 1.000.000 Nutzerinnen und Nutzer. Definitiv ein raketenhafter Anstieg! Zum Vergleich: Google ist seit September 1997 im Rennen. Dazu kommt, dass Googles weltweiter Marktanteil zuletzt erstmals seit zehn Jahren unter 90% liegt (mehr dazu findest Du in diesem Artikel von Flo Hannemann).
Halten wir also fest: Aktuell dominiert Google die Suche nach wie vor deutlich. Trotzdem sollten wir realistisch sein: Die klassische Suche wird an Bedeutung verlieren. Vielleicht nicht heute, vielleicht auch noch nicht morgen oder übermorgen. Aber irgendwann kommt der Tag, an dem die Anna Normalverbraucherin ihre Suche nach neuen Schuhen oder dem Rezept für einen Apfelkuchen nicht mehr bei Google beginnt, sondern auf Social Media oder bei einem KI-Tool ihres Vertrauens.
Schon jetzt schauen viele beim Shoppen direkt bei Amazon vorbei. Und gerade die jüngere Generation kauft lieber über TikTok oder Instagram. Passend dazu ein Kommentar unter dem Artikel Google: 10% Of Younger Google Searches Start With Circle To Search:

Muss dieser Verlauf ein Nachteil sein? Nein! Im Gegenteil: Google dominiert eigentlich schon viel zu lange allein das Feld. Das mag im ersten Moment sehr angenehm sein, immerhin muss man dann nicht für zehn Tools gleichzeitig optimieren.
Also alles gut. Zumindest bis Du eines Morgens aufwachst und mit heruntergeklappter Kinnlade feststellst, dass das neue Core Update Deiner jahrelangen Arbeit über Nacht das Licht ausgeknipst hat. Uups, dann ist der Urlaub dieses Jahr wohl gestrichen. Und 500 Stellen noch dazu.
Oder anders formuliert: Vermutlich ist es ganz gut, wenn sich das einstige Monopol nach und nach auf mehrere Schultern und Tools verteilt. Denn wo jemand alleine herrscht, da ist zumindest theoretisch die Chance vorhanden, dass der eigene Vorteil dieses Unternehmens noch stärker in den Mittelpunkt rückt als “das Wohl der Nutzerinnen und Nutzer”.
Die Frage ist also nicht, ob die klassische Suche abgelöst wird, sondern wann. Und wie die neue Form der Suche aussehen wird. Ein Chat-Format wie bei ChatGPT? Eine Technologie wie bei Google Lens? Oder doch eine ganz neue Art, die wir vielleicht noch gar nicht auf dem Schirm haben.
Zum Abschluss noch der Hinweis: Schau Dir auch unbedingt noch den Artikel von Flo Hannemann in dieser Ausgabe an. Der nimmt die 5 Billionen Suchen nämlich noch einmal aus einem anderen Blickwinkel in Augenschein und fragt sich: Wird Google eigentlich absichtlich schlechter?
|
|
| Mehr Suchen, besseres Google? |
In einem neuen Blogpost hat Google bekannt gegeben, dass sie mittlerweile mehr als 5 Billionen Suchen im Jahr bedienen. Das bedeutet, runtergebrochen etwa 158.548 Suchen in der Sekunde. Ich weiß nicht, wie es Dir geht, aber mir fällt es schwer, sich das schiere Ausmaß vorzustellen. Matt hat Dir in seinem Artikel noch genauer erklärt, wie absurd groß diese Zahl ist und wie Google damit im Vergleich zur Konkurrenz dasteht.
Für mich ist die Zahl vor allem in Anbetracht der Tatsache, dass Google nach Schätzungen 2015 noch etwa 1,2 Billionen Suchanfragen hatte, sehr beeindruckend. Damit hat sich die Anzahl der Suchen über Google in 10 Jahren mehr als vervierfacht.
Woher aber kam der starke Anstieg?
Googles Marktanteil ist seitdem eher marginal gewachsen und in den letzten 2 Jahren sogar rückläufig. Google musste allerdings kein starkes Wachstum hinlegen, weil der Markt das für sie getan hat. Die Anzahl der Personen mit Internetzugriff ist von 3,27 auf 5 Milliarden gewachsen. Bei ~90% Google Nutzer:innen ist das schon beachtlich.
(Fast) eine Verdoppelung an Nutzer:innen ist zwar schon ein großer Schritt in Richtung Suchanfragen-Anstieg, erklärt aber noch nicht das enorme Wachstum. Hier ist nämlich Google selbst der Grund.
Es wird oft darüber geredet, dass Google in den letzten Jahren schlechter geworden ist. Das ist jedoch nicht nur Linkedin-Geschwafel, sondern lässt sich auch belegen. 63% der Nutzer:innen fanden Google-Ergebnisse früher besser, Ads nehmen mehr und mehr Platz ein und es gibt dutzende Beispiele von schlechten Ergebnissen.
Die schlechtere Qualität von Google ist jedoch kein Zufall, sondern Teil eines gezielten Plans zur Traffic-Steigerung.
Wieso sollte Google absichtlich schlechter werden?
Ganz einfach: Google möchte mehr Umsatz. Ein Großteil von Googles Umsatz kommt aus Ads. Der Umsatz, der mit Ads erzielt wird, setzt sich wie folgt zusammen:
Umsatz = Price x Anzahl queries
Der Preis, den Unternehmen für ihre Ads zahlen, ist gegeben. Selbst wenn Google da mit dem Drehen von internen Parametern noch ein paar mehr Cent in die eigenen Taschen spülen kann, ist der Wert relativ starr. Wenn man also den Umsatz aus Ads erhöhen möchte, bleibt nur an der Anzahl der Queries zu schrauben.
Dass dies ein gezielter Plan von Google war, lässt sich auch aus den internen Dokumenten und E-Mails erkennen, die im Rahmen des Verfahrens United States v. Google LLC (2020) veröffentlicht wurden.
In diesem Mail-Verlauf wird ersichtlich, wie sehr das Ads-Team damit zu kämpfen hatte, ihre Quotas zu erfüllen und die Schuld dafür auf mangelnde Kooperation des Search-Teams geschoben haben. Sie taten alles, um ihren Teil der Umsatzgleichung zu erfüllen, aber das Ziel des Search-Teams lag verständlicherweise nicht darin, künstlich die Anzahl an Suchanfragen zu erhöhen.
Das Search-Team wollte zufriedene Nutzer:innen und wie es der Zufall so will, sind Nutzer:innen in der Regel nicht zufrieden, wenn sie mehrere Suchen tätigen müssen. Die internen Ziele bei Google passten also nicht zusammen.
In weiteren Mailverläufen wird direkt eine gezwungene Steigerung an Queries diskutiert, um die damaligen Quartalsziele zu erreichen. Kurz darauf wurde ein Code Yellow im Hause Google ausgerufen, um das “mangelnde Wachstum” an Suchanfragen zu bekämpfen. Aller Wahrscheinlichkeit nach wurde hier dann eine Verschlechterung der Suche angegangen. Etwas, das sich auch in internen Positionen durch die Beförderung Prabhakars widerspiegelte.
Falls die absichtliche Verschlechterung zu Zwecken der Umsatzsteigerung etwas weit hergeholt klingt (schließlich streben wir doch alle zufriedene Nutzer:innen an): Aus dem Verfahren ging auch hervor, dass Google bereits vorher angetestet hat, wie eine Verschlechterung des Indexes und der Ergebnisse sich auf den Umsatz auswirken würde. In dem Beispiel würde das Entfernen von Informationen im Wert von etwa 2 Wikipedia aus dem Index sich weniger als 1% auf Ads Revenue auswirken.
Google wusste also, dass sie durch schlechtere Ergebnisse eher mehr Umsatz als weniger Umsatz einfahren würden. So kontraintuitiv es auch klingt, die schlechtere Qualität der Google Ergebnisse über die letzten Jahre war kein Zufall, sondern eine geplante Strategie.
Falls Du noch tiefer in das Thema eintauchen willst, empfehle ich Dir diesen Artikel von Ed Zitron oder diesen Google Quality Issues Artikel von Wallethub. Im Artikel von Wallethub findest Du unten auch eine Sektion mit einigen SEO-Experten Meinungen zum Thema. Hier ist die Verschlechterung von Google fast einstimmig anerkannt.
Ob die kurzfristige Steigerung von Einnahmen über Ads im Austausch für Qualität in der Welt mit aufholenden Konkurrenten wie Bing und Yandex, sowie AI als neuem Player am Markt der richtige Weg war, wird sich zeigen.
|
|
| Das passt ins Bild |
Bilder beeinflussen nicht nur die Optik einer Seite, sondern auch Rankings in der Google-Suche, Google Discover und Google News. Wenn sie falsch eingebunden sind, riskierst Du unter anderem langsame Ladezeiten und eine schlechte Performance in den Core Web Vitals. Lass uns einmal zusammen schauen, wie Du diese Risiken vermeiden kannst.
Warum ist Bildoptimierung so wichtig?
Google bevorzugt schnelle, zugängliche Inhalte. Besonders in Discover und Google News sind hochwertige Bilder Faktoren für die Leser und für die Ausspielung. Wichtig sind dabei korrekte Bildgrößen, moderne Formate und schnelle Ladezeiten. Google Discover setzt für große Vorschauen eine Mindestbreite von 1.200 Pixeln voraus. Damit diese Bilder in den Feeds erscheinen, muss außerdem max-image-preview: large in den Meta-Tags gesetzt sein.
Neben der Sichtbarkeit in den Feeds ist auch die Ladegeschwindigkeit entscheidend. Google misst sie in der GSC unter "File Type: Image". Ein guter Wert für Bilder liegt bei unter 50ms Ladezeit. Alles darüber ist meh. Bilder mit modernen Formaten, effizienter Kompression und korrektem Lazy Loading sind hier definitiv der Gold-Standard.
Die richtigen Bildformate wählen
Google empfiehlt WebP und AVIF, da sie kleinere Dateigrößen bei hoher Qualität ermöglichen.
- WebP ist weit verbreitet, spart im Vergleich zu JPEG etwa 30 % Dateigröße und wird von modernen Browsern unterstützt.
- AVIF komprimiert noch stärker, wird jedoch nicht von jedem Browser verarbeitet. Hier lohnt sich eine schrittweise Implementierung mit Fallbacks.
Mit f_auto wird das optimale Bildformat automatisch anhand des Browser-Supports (also dem Format das der Browser unterstützt) ausgeliefert. Das vermeidet überflüssigen Code und spart Bandbreite. Wenn ein Nutzer eine Website aufruft, sendet sein Browser im HTTP-Header eine Accept-Anfrage, die angibt, welche Bildformate unterstützt werden. Der Server analysiert diese Anfrage und liefert dann die optimale Version des Bildes aus:
- WebP, falls vom Browser unterstützt (Chrome, Edge, Firefox, neuer Safari)
- AVIF, falls vom Browser unterstützt (neuere Chrome-, Edge- und Safari-Versionen)
- JPEG oder PNG, falls WebP oder AVIF nicht unterstützt werden
Das bedeutet, dass ein Nutzer mit Chrome ein WebP-Bild erhält, während ein älterer Browser wie Internet Explorer ein JPEG bekommt, ohne dass separate Bilddateien verwaltet oder eingebunden werden müssen.
Was ich mich in dem Zuge unter anderem gefragt habe, ist ob die dynamische Bildauslieferung als Cloaking gewertet werden könnte. Das ist aber nicht der Fall. Cloaking liegt nur dann vor, wenn unter derselben URL für Nutzer und Suchmaschinen völlig unterschiedliche Inhalte ausgeliefert werden. Die dynamische Bildauslieferung verändert aber nur das Format oder die Größe des Bildes, nicht den eigentlichen Inhalt und solange sie nicht per robots.txt gesperrt sind, gibt es hier auch keine Crawl-Probleme.
Zusätzlich zur Formatwahl hilft die dynamische Bildoptimierung, Bilder in der richtigen Qualität, Größe und im passenden Format auszuliefern:
- q_auto passt die Bildqualität automatisch an, um die Balance zwischen Dateigröße und sichtbarer Qualität zu optimieren.
- c_fit stellt sicher, dass das Bild auf verschiedenen Geräten korrekt skaliert wird, ohne das Seitenlayout zu verzerren.
Anders als bei der clientseitigen Lösung (srcset, <picture>) erfolgt die Bildauswahl serverseitig über ein Image-CDN, bevor der Browser das Bild überhaupt lädt. Da f_auto als Parameter eine eigenständige URL erzeugt, kann die On-the-fly-Generierung je nach Serverauslastung zu Verzögerungen führen. Daher ist ein durchdachtes Caching wichtig, um Performanceprobleme zu vermeiden. An dieser Stelle greifen die 5 Ps: Proper Preparation Prevents Poor Performance. Wenn diese Aspekte im Vorfeld richtig bedacht werden, ist f_auto möglicherweise eine effiziente Methode, um moderne Bildformate automatisch bereitzustellen. Hast Du schon Erfahrungen damit? Melde Dich gerne bei mir!
Ladegeschwindigkeit und Lazy Loading
Bilder sollten so schnell wie möglich geladen werden, aber nur dann, wenn sie auch sichtbar sind. Lazy Loading (loading="lazy") sorgt dafür, dass Bilder erst dann geladen werden, wenn sie im sichtbaren Bereich erscheinen. Das spart Bandbreite und verbessert die First Contentful Paint in den Core Web Vitals. Hannemann hat letzte Woche einen tollen Artikel zum Lazy Loading geschrieben. Dynamische Bildauslieferung mit f_auto oder srcset hat darauf keinen Einfluss: Lazy Loading bleibt trotzdem aktiv.
Barrierefreiheit und Alt-Texte
Ein optimales Bild ist nicht nur schnell, sondern auch zugänglich. Alt-Texte sind ein MUSS (mit Ausnahmen) für die Barrierefreiheit und helfen den kleinen Crawlern, den jeweiligen Bildinhalt zu verstehen.
- Alt-Texte müssen präzise und beschreibend sein
- Dekorative Bilder sollten mit alt="" versehen werden, damit Screenreader sie ignorieren.
Passen Deine Bilder schon in dieses Bild?
|
|
| Depri Search: Deep Research gar nicht so deep |
Wir sind es ja gewohnt, dass es mit der Genauigkeit manchmal nicht so genau genommen wird. Manchmal aus Dummheit, manchmal aus Faulheit und manchmal, weil jemand Interessen mit der Falschdarstellung verfolgt.
Gerade sehen wir von vielen LLM / GenAI / Search-Anbietern Beta-Versionen, Prototypen und finale Systeme, deren Versprechen ist: Du gibst uns eine Frage und wir recherchieren, untersuchen die Zielseiten und erstellen Dir einen fertigen Report.
Ich hab mir ein paar dieser Systeme angesehen. Mein Prompt war einfach:
What are the most important takeaways from the Google leak of 2024? Please provide a detailed analysis along with a summary of 20 specific lessons.
Diesen Prompt habe ich verschiedenen Tools gegeben:
You.com
You.com besticht mit einer allgemeinen und nichtssagenden Einleitung. Um dann Ranking Faktoren im Leak zu finden. Dabei wissen wir, dass keine Rankingfaktoren in den Modulen stehen.
You.com hat außerdem Security-Probleme hineinfabuliert: „Vulnerabilities in OAuth Authentication” und „Following the leak, there has been a notable increase in cybersecurity investments across the tech industry. Security budgets have grown by an average of 6% in 2023“ → Durch den Leak 2024 sind also die Budgets 2023 gestiegen. Im Leak wurden also Zeitreisen gefunden. Dieses Detail hat die SEO-Community definitiv noch nicht im Leak entdeckt. Ursache ist das Verwechseln von verschiedenen Leads. Da hilft dann auch nicht, wenn man reportet, dass ach so viele Quellen genutzt worden sind.
In der aktuellen Form ist das Feature unbrauchbar. Tatsächlich ist mit 3-4 Nachfragen das Ergebnis am Ende aber auf dem Niveau eines Schülerpraktikanten. Aber der bräuchte natürlich deutlich eher 3-4 Tage für das gleiche Ergebnis. Anleitung und Fachkenntnis brauchen beide.
Link zur unzureichenden Analyse
ChatGPT-DeepResearch
ChatGPT hat deutlich weniger Quellen herangezogen (15 URLs). Zitiert wird aber nur von brandwell, ovative, slashdot, goelement.
Von diesen Quellen gibt es eine brauchbare Summary. Aber die Artikel sind mir bisher nicht aufgefallen als die besten Summaries des Leaks.
Auf diesem Weg schafft es ChatGPT aber eine Summary zu erstellen, die ich auch von einem Trainee in den ersten Monaten erwarten würde.
Als Feedback würde ich aber den Hinweis auf ein paar gute Artikel geben. Und darum bitten, dass man sich die Originalquellen noch mal ansieht, was wirklich drin steht und ob das, was in den Artikeln geäußert wird, wirklich so aus dem geleakten Material zu lesen ist.
Einem Junior Consultant würde ich dieses Ergebnis nicht durchgehen lassen. Dazu fehlt das Verständnis der Suchmaschine, die Einordnung und Diskussion der Faktoren und die kritische Auseinandersetzung, damit, dass es sich nicht um Rankingfaktoren handelt.
ChatGPTs Summary
Perplexity
Perplexity kriegt direkt einen Pluspunkt dafür, dass es von potential ranking factors spricht. Den braucht Perplexity auch. Denn wegen reißerischer Sprache war Perplexity schon nach dem ersten Halbsatz im Minus.
Perplexity gibt trotz der reißerischen Note einen guten Überblick über die Entwicklung und handelnden Personen. Auch zu ein paar Key-Findings und es sieht auch alles erstmal richtig aus.
Von den 20 gefundenen Quellen werden 8 für den Artikel herangezogen. Es wäre aber gut gewesen, wenn vielleicht noch weitere Quellen zitiert worden wären. Dann wäre vielleicht auch der Anteil mit den 20 Insights geglückt. So taugt der Artikel für einen Überblick an ein allgemeines Online Marketing Publikum. Für ein Fachpublikum fehlt leider die Deepness dieses Deep Research pieces.
Link zu Perplexitys Versuch
Grok
Auf das LLM des Fake News Kings Doge-Dompteurs war ich gespannt. Bisher hat es Grok noch nicht geschafft, mich zur Nutzung zu motivieren.
Grok nimmt sich 88 (!) Quellen. Gut gefällt mir, dass vor der Summary noch die Key Points aufgelistet werden. Die Key Points sind aber in der Formulierung und Auswahl schon diskussionswürdig.
Google likely makes frequent small adjustments, known as "twiddlers," impacting site rankings.
Das klingt etwas mehr nach statischen Anpassungen, als nach einer dynamischen Komponente, die bei jeder Anfrage ausgeführt wird.
Insgesamt ist die Analyse sehr fokussiert darauf, ob aus den Faktoren Kontroversen entstanden sind.
Grok ist trotz der an sich guten Liste der interessanten Punkte des Leaks ebenfalls eher auf der schwächeren Seite. Die Quellenangaben sind sparsam (oder gar broken).
Link zu Groks Ansatz
Fazit
Wie bei allen LLM-Geschichten ist es im ersten Moment beeindruckend. Da läuft ein System los, recherchiert im Netz und stellt mir etwas zusammen, was mich selbst mehrere Stunden Arbeit gekostet hätte.
Wie immer bei der „Arbeit“ mit unseren lustigen neuen Spielzeugen entscheidet die Qualität des Promptings mit über die Qualität des Ergebnisses.
Und natürlich ist es auch gemein nach dem Leak zu fragen, wenn doch die meisten Artikel zum Leak, die für die Systeme zugänglich sind, auch von mittelmäßiger Qualität sind.
Trotzdem:
- Nicht ein Report hat auf das Originalmaterial verlinkt.
- Bis auf You.com haben alle es geschafft, den Leak von anderen Leaks zu unterscheiden.
- Der Überblick ist teilweise recht gelungen. Oft aber reißerisch und weit entfernt von dem, was ich als Deep Research betrachten würde.
Long story short: Unsere statistischen Papageien kriegen hier teilweise brauchbare Zusammenfassungen hin. Benutzbar sind die aber nur, wenn:
- Einem die Qualität des Ergebnisses egal ist.
- Man sich in dem Thema gut genug auskennt, um einen sehr guten Prompt zu schreiben, die Quellen kuratiert und Nachfragen stellt.
Die Nase vorn hat aktuell ChatGPT.
Aber: Das war jetzt ein einzelnes Experiment mit einer Frage.
Lust auf einen großen Vergleich habe ich noch nicht. Dafür müsste die Qualität schon besser sein.
Wiedervorlage in 6 Monaten.
|
|
| Achtung, Seiteninhaber haften für ihre Snippets |
Obligatorischer Disclaimer: Wir sind keine Juristen, wenn Du eine rechtssichere Auskunft brauchst, frag einen Spezialisten. Dennoch wollen wir Dich gerne darauf hinweisen, was an deutschen Gerichten so entschieden wird und wieso das für Dich interessant sein könnte.
So hat das Landgericht Köln in einem jetzt bekannt gewordenen Urteil vom 22. Januar entschieden, dass Publisher für irreführende Snippets in der Google-Suche haften können. Aktenzeichen 28 O 252/24 für alle, die es ganz genau wissen wollen.
In diesem Fall hatte die “Bild” berichtet. Über die Ergebnisse von Lebensmittelüberwachungskontrollen in zwei Franchise-Filialen einer Imbisskette. Von “Schmutz, Fake-Fleisch und Hygienemängel” ist die Rede gewesen. Laut Auffassung der Richter konnte dabei durch die Nichterwähnung, dass es sich um Franchises handelte, bei Lesenden der Eindruck entstehen, alle Restaurants der Kette seien betroffen. Damit verletze das Snippet die Unternehmenspersönlichkeitsrechte der Franchisegeberin.
Damit macht das Gericht den Verleger dafür haftbar, dass Google den von ihm erstellten Meta-Tag des Artikels wörtlich übernahm. Du denkst bestimmt direkt das gleiche wie ich: Was aber, wenn das Snippet von Google geändert wird, wie es so oft vorkommt? Dann, so der Anwalt Jörn Claßen, müsste Google dafür haften. Das Urteil ist aktuell noch nicht rechtskräftig und ich teile die Einschätzung des Autoren des Heise-Artikels, dass es vermutlich auch nochmal zu einem OLG gehen wird.
So oder so, zeigt die Situation vor allem zwei Dinge:
- Clickbait kann teuer werden und ist nach wie vor keine herausragende Idee.
- Nach dem Leistungsschutzrecht ein weiterer Fall von Kopfzerbrechen, das europäische Gerichte und in diesem Fall die deutsche Justiz den Freunden bei Google bereitet.
Nicht verwunderlich, dass Google auf Gedanken kommt, was eigentlich wäre, wenn sie den Newsanbietern gar keinen Traffic mehr rüberschaufeln würden. Dann müssten sich alle in diesem Sektor aber ganz schnell umsehen. Hoffen wir also, dass Google geduldig bleibt.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





