| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #154 |

|
| 🌺 Es grünt so grün |
Es ist Frühling und wie alles in dieser Jahreszeit, wachsen und gedeihen auch die Wingmenschen weiter.
Nein, diesmal verkünden wir, ausnahmsweise, keinerlei Neuzugänge, sondern die frohe Botschaft, dass der eine oder die andere Trainee über ein Jahr gewachsen und vom zarten SEO-Keimling zu einem stattlichen SEO-Pflänzchen herangezogen wurde, dem nun nichts mehr im Weg steht, mal eine ordentliche SEO-Pflanze zu werden.
Matt und ich sind begeistert verkünden zu dürfen, dass wir inzwischen ein wenig mehr vom SEO-Dschungel überblicken, als noch vor einem Jahr und ab jetzt als SEO Junior Consultants weitere Expeditionen und Entdeckertouren unter der Flagge der Wingmen durchführen werden. Dabei freuen wir uns besonders darauf, auch hin und wieder selber die Taschenlampe zu halten. Auch der eine oder andere verschlungene Pfad wird uns nicht aufhalten können, denn auf diesen begleiten uns natürlich die anderen Abenteurer.
Diese waren diese Woche bereits fleißig auf Entdeckertour und haben direkt frisch aus dem Dschungel unseren SEO-Garten mit neuen Themen angereichert:
Canonical-Chrysanthemen von Hannah News-&-Discover-Narzissen und -Dahlien von Matt Qualitative Quantitäts-Quittenbäume von Jolle JavaScript-Johanniskräuter von Anita Relaunch-Rhododendren von Johan
Und nun viel Spaß beim Blumen pfücken!
Deine Wingmenschen
|
|
| It came in like a Cannonball, ähm nein Canonical |
Letzte Woche ging es rund und in der SEO-Welt zerbrachen sich viele die Köpfe über Canonicals und syndizierte Inhalte, sodass Google nochmal ein Statement an die SEJ herausgab. Ich fasse das einmal kurz zusammen:
Wir unterscheiden zwischen verlagsfremder Syndizierung und der innerhalb des Unternehmens.
Um das anschaulich zu gestalten, führe ich Dich anhand eines Beispiels entlang.
Syndizierung innerhalb eines Verlags
Hannahs Wochenzeitung syndiziert Inhalte von Noras Tagesblatt. Beide Seiten gehören zum Verlag Wingmenpost. Ich setze das Canonical.
Google hat noch einmal klargestellt, dass das Canonical weiterhin unterstützt wird, es empfiehlt sich für Cross-Domain-Syndicates aber das noindex-Tag.
Verlagsfremde Syndizierung
Wenn ich (Hannahs Wochenzeitung) jetzt Inhalte von der HSVpost nehme, dann ist das Setzen des noindex-Tags empfehlenswert, denn
Ich bin ein ehrlicher Mensch 🙂 Im Zweifel überträgt das Canonical alle Power meiner Kopie auf das Original beim HSV. Das will ich ja auch nicht. Das Canonical ist lediglich ein weiches Signal und kann ignoriert werden. Das will der HSV nicht, denn schließlich haben die ja Arbeit in den Artikel gesteckt. Das Canonical könnte ignoriert werden und dann stehen die Meldungen in Konkurrenz zueinander.
Wieso der ganze Wirbel? Es gab immer wieder Probleme mit den Canonicals und kleine Publisher hatten häufig keine Chance gegen große Seiten, wenn deren Inhalte syndiziert wurden und der Kopie dann das Canonical zugeschrieben wurde. Wir denken, Google möchte durch die noindex-Empfehlung dieser Problematik aus dem Weg gehen.
Wenn Du also Inhalte an Drittanbieter gibst, kannst Du ihnen die entsprechende Anforderung mit auf den Weg geben.
John Shehata empfiehlt, wenn Du Deine Inhalte weitergibst oder selbst Inhalte von anderen Seiten publizierst:
Bestehe immer auf das Setzen des Canonicals Vermeide das Syndizieren kompletter Inhalte Publiziere syndizierte Inhalte mit einer entsprechenden Verzögerung und beachte hierbei, wie lange Google braucht, um die Inhalte Deiner Seite zu crawlen und zu indexieren
→ Denk hierbei an Dein Karma: Es wäre nicht fair, wenn Dein kopierter Artikel vor der Originalquelle steht Du kannst auch eine Extrazeile "dieser Artikel wurde auf Seite xy veröffentlicht" ergänzen
Sollten Seiten immer wieder ungefragt und ohne Deal Inhalte von Dir kopieren und ohne Angabe von Canonical oder noindex publizieren, kannst Du dafür einen DMCA-Request erstellen, sodass die geklauten Inhalte aus dem Index entfernt werden.
|
|
| Die fünf magischen Überschriften für News & Discover |
Ich weiß nicht, wie es Dir geht, aber wenn ich aus SEO-Sicht an Überschriften denke, fallen mir erst einmal die H-Überschriften und das Title Tag einer Seite ein. Die sind selbstverständlich wichtig, aber in diesem Artikel werde ich Dir nun insgesamt fünf Überschriften vorstellen, von denen einige insbesondere für Google News und Google Discover von größerer Bedeutung sind. Der Ursprungsartikel dazu stammt von Barry Adams.
Vielleicht ist Dir in der Zwischenzeit noch eine weitere Überschrift eingefallen. Ich bin jedenfalls sicher, dass hier auch noch die ein oder andere Überraschung für Dich dabei ist.
1. H1-Überschrift
Ich habe sie eingangs bereits erwähnt, hier sind sie noch einmal: Die H-Überschriften, allen voran natürlich die H1 (<h1>).
Dass Google auf die viel Wert legt, sollte für die wenigsten überraschend sein: Sie dient meist als klassische Überschrift in einem Artikel und gibt Leserinnen und Lesern ebenso wie Google idealerweise bereits eine klare Vorstellung davon, was sie in einem Artikel erwartet.
Die H1-Überschrift (wie auch alle weiteren H-Überschriften) ist in ihrer Länge nicht begrenzt - was nicht bedeutet, dass eine 900 Zeichen lange H1 empfehlenswert ist.
2. Structured Data "headline"
Dieser Punkt ist schon deutlich interessanter als der vorherige. Noch wichtiger als die H1-Überschrift ist für Publisher die Structured-Data-Headline. Kennst Du nicht und auch noch nie gesehen? Kein Wunder, sie versteckt sich nämlich im HTML Code und ist auch sonst auf der Seite selbst nicht sichtbar:
3. Title Tag
Auch das dürfte kein Geheimnis sein: Das Title Tag (<title>) einer Seite ist ebenfalls relevant für Google. Zwar kommt dieser bei Google News in puncto Bedeutung erst hinter der Structured-Data-Headline, aber ein gut optimierter Title ist nicht zu vernachlässigen.
Das gilt insbesondere dann, wenn Du mit Deinem Artikel auch in den organischen Ergebnissen bei Google ranken möchtest. Dort ist der Title schließlich der klickbare Teil des Snippets und sollte demnach funkeln und glänzen, um Besucherinnen und Besucher auf Deine Seite zu locken.
Was die Länge eines Titles angeht: Die sollte ungefähr zwischen 55 und 65 Zeichen liegen, sonst wird er einfach abgeschnitten oder sogar angepasst. Da Google den Title auch für Rankings-Signale ausliest, kann es sich aber lohnen, über das Zeichenlimit hinwegzugehen. Übrigens: Seitdem die Brands im Title einer Seite von Google meist nicht mehr angezeigt werden (Mehr Informationen dazu findest Du in meinem Artikel in unserer Newsletter-Ausgabe Happy 404-Day), hast Du sogar noch ein wenig mehr Spielraum bei den Zeichen.
4. Open-Graph-Title
Eine weitere wichtige Überschrift ist der Open-Graph-Title. Der wurde von Facebook erfunden und ist eigentlich für Social Media gedacht. Genau deshalb spielt er insbesondere für Google Discover eine nennenswerte Rolle, da Google gerne hierauf zurückgreift, wenn ein Artikel im Discover-Feed erscheint.
Ob und wann das passiert, bleibt - wie bei Discover im Allgemeinen - ein Geheimnis. Es kann allerdings für Publisher sicher nicht schaden, auch etwas am OG-Title der Seiten zu feilen, vor allem dann, wenn Du auch schon den ein oder anderen Klick bei Google Discover abgreifen möchtest.
Im HTML findest Du den Open Graph Title im Head-Bereich als <meta property="og:title" content="XYZ" />.
<meta property="og:title" content="Sieben Rote Karten beim Superclásico zwischen River Plate und Boca Juniors in Argentinien">
Noch ein kleiner Tipp zum Abschluss: Der OG-Title darf gerne auch einen Hauch von Clickbait enthalten. Aber bitte wirklich nur einen Hauch! Wenn Deine Leserinnen oder Leser mit den Augen rollen, ist es jedenfalls zu viel.
5. Ankertext-Überschrift
Dir qualmt inzwischen bereits der Kopf vor lauter Überschriften? Durchhalten! Es fehlt bloß noch eine. Und zwar eine, die zwar so gut wie jeder kennt, aber am Ende häufig doch vergessen wird: Die Ankertext-Überschrift.

Die liegt zwar außerhalb des Artikels an sich, ist aber dennoch eine Überschrift, die Du stets mit im Blick behalten solltest. Der Ankertext gibt Google schließlich wichtige Informationen darüber, was auf der verlinkten Seite zu finden ist. Das ist übrigens auch der Grund, wieso Du Deine Seiten nicht mit "Mehr erfahren" oder "Hier klicken" verlinken solltest. Wie Du solche generischen Ankertexte mit dem Screaming Frog entdeckst, hat Dir Sandra übrigens in unserem Newsletter "Willkommen in der SEO Matrix" gezeigt.
Gerade wenn der Platz auf einer Artikel-Übersichtsseite begrenzt ist, müssen die Ankertext-Überschriften unter Umständen noch einmal angepasst werden. Das kann stressig sein, ist aber aus SEO-Sicht ein wichtiger Hebel, der nicht vernachlässigt werden sollte.
Fazit
Neben den H-Überschriften und dem Title Tag gibt es noch weitere Überschriften, auf die insbesondere Publisher und Seiten, die Traffic über Google News und Discover bekommen, achten sollten. Vor allem die Structured-Data-Headline ist eine Überschrift, an die womöglich nicht jeder sofort denkt, gerade weil sie lediglich optional ist. Genau da liegt dann aber auch die Chance, sich von der Konkurrenz abzuheben. In diesem Sinne: Viel Spaß beim Optimieren!
|
|
| Der Qualitätsfaktor Relevanz wird quantitativ erhoben |
"Erstellt gute Inhalte". Das ist im Kern Googles Empfehlung auf die Frage, was Du machen musst, um gute Rankings einzufahren. Mit jeder Entwicklungsstufe von Google hat sich allerdings verändert, was einen guten Inhalt ausmacht.
Dass Keyword-Stuffing noch nie wertvoll für Leserinnen und Leser gewesen ist, darauf können wir uns einigen. Trotzdem wurden diese Schrotttexte anfangs durch gute Rankings belohnt. Die Frage nach der Qualität von Inhalten ist im SEO notgedrungen eng damit verknüpft, was Suchmaschinen als hochwertig erkennen können.
Michael King hat nun mit "Relevance is Not a Qualitative Measure for Search Engines" einen herausragend guten Beitrag darüber geschrieben, wie Google Relevanz misst und leitet daraus ab, dass die gängigen SEO-Tools Aufholbedarf haben, um weiterhin - oder müssen wir sagen: wieder? - valide Hilfestellung für die Content-Optimierung geben zu können.
Von der lexikalischen "Bag of Words" über TF-IDF zu Dense Word Embeddings
Suchmaschinen bewerten Website-Inhalte anhand von mathematischen Formeln. Für das, was Menschen unter Qualität verstehen, sucht Google Stellvertretermetriken, die berechnet und verglichen werden können. Suchanfragen und Website-Inhalte werden jeweils umgewandelt und als Repräsentationen im Vektorraum abgebildet.
Eine Tüte Wörter bitte: Anfangs wurden einfach alle Wörter bzw. deren Wortstamm unabhängig von ihrer Reihenfolge durchgezählt. Je häufiger ein Wort genannt wurde, desto relevanter schien das Wort für den Text und der Text zum Thema oder der Suchanfrage hinter diesem Wort zu sein. Stoppwörter wie "ist, der, die, das" etc. wurden hier anfangs noch rausgeschmissen, weil sie in jedem Text sehr häufig vorkommen.
Dagegen war TF-IDF ein riesiger Schritt: Hier bemisst sich Relevanz daraus, dass bestimmte Wörter häufig in einem Kontext zusammen genannt werden (Kookkurrenz), während sie in anderen Dokumenten weniger häufig vorkommen. Das ist der Stand, auf dem viele Content-Optimierungs-Tools schon heute sind, wenn zum geschriebenen Text Ergänzungsvorschläge für fehlende Begriffe gemacht werden. Wir konnten mit TF-IDF und Tools wie Termlabs gute Ergebnisse erzielen und setzen weiter darauf. Doch es gibt mehr.
Spätestens seit BERT ist Google noch viel weiter. Wortvektoren werden nicht mehr nur anhand einiger Dimensionen, sondern unzähliger Dimensionen gebildet. Es gibt nicht mehr nur "kommt vor" vs. "kommt nicht vor", sondern "kann bis zu einem gewissen Grad im Kontext anderer Wörter auch X oder Y bedeuten". Es gibt keine Stoppwörter mehr. Jedes Detail im Satz, die Reihenfolge der Wörter und die Reihenfolge der Sätze wird mathematisch abgetragen und im Vektorraum abgebildet.
Fokus auf Content-Optimierung oder Linkbuilding?
Mike bringt ein praktisches Beispiel mit und beschreibt ein Gefühl, das wir SEOs nur zu gut kennen. Das eigene Content Piece kommt einem selbst viel relevanter vor als das, was da in den Top-Positionen so rankt. Trotzdem kommt man nicht dagegen an. Aber stimmt das? Oder lohnt sich weiterer Aufwand, um die URL inhaltlich noch weiter auszubauen, zu stärken oder um Elemente wie Grafiken und Videos zu ergänzen? Oder muss ich nicht viel mehr die interne Verlinkung hebeln und versuchen, Backlinks auf die URL zu bekommen?
Präzision ist wichtiger als Genauigkeit 😵💫😅
Mike rät dazu, die rankenden Inhalte auf Vektorbasis zu vergleichen. Schneidest Du mit Deinem Content gut ab, müssen Backlinks her. Hast Du das Thema verfehlt, musst Du an den Inhalt nochmal ran. Mit Orbitwise hat das Team um Mike ein Tool für die Vektoranalyse gebaut. Das rät er der SEO-Branche und vor allem den Toolanbietern ebenfalls. Denn viele Ressourcen der KI-, NLP- und Vektorforschung sind Open Source und somit zugänglich für alle. Bei Wingmen überlegen wir auch schon, wie wir das in unserem internen Tool-Setup abgebildet bekommen.
Aber warte: Wenn ich mir jetzt meine eigene Vektoranalyse aus Open Source zusammenschraube, wer sagt mir denn, dass ich das im Ansatz so mache, wie Google? Wer sagt, dass ich meine Werte dann überhaupt für die Vergleiche benutzen kann?
Mike sagt dazu:
"Since we'll never have exactly what Google has for any SEO use case, we should all agree that SEO tools are about precision, not accuracy. That is to say, even if we're not using the same language model as Google the relative calculations between pages should be similar."
Genauigkeit ist weniger wichtig als Präzision? Wem hier die Ohren bei der Frage schlackern, worin hierbei eigentlich der Unterschied liegt, dem hilft vielleicht diese Skizze:
Präzision drückt aus, wo sich Messpunkte im Verhältnis zueinander befinden. Alle Dartpfeile nah beieinander ist präzise, selbst wenn sie nicht im Zentrum der Zielscheibe liegen Genauigkeit (Akkuratheit) drückt aus, wie nah die Messpunkte am anvisierten Ziel liegen, unabhängig davon, wo die einzelnen Messpunkte zueinander stehen
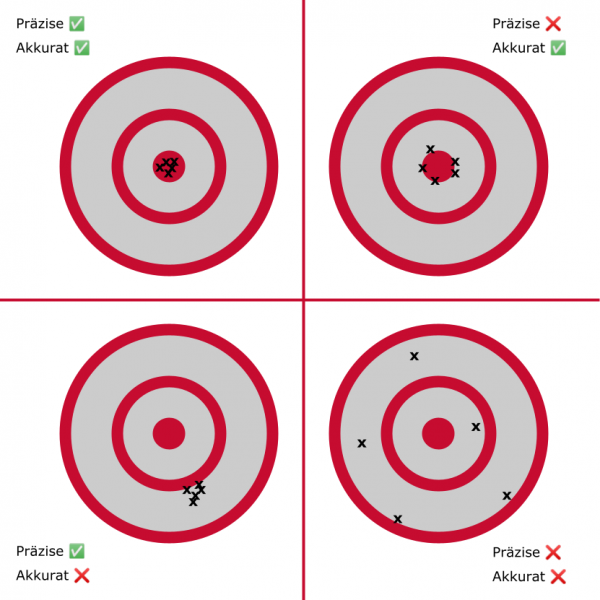
Mike sagt, selbst wenn wir mit unseren Vektormessungen nicht das "Bull's Eye" im Sinne von Google's Vorgehensweise treffen, so werden wir doch sehen, wie Content Pieces in der SERP sich zueinander verhalten (Quadrant unten links) - und daraus unsere Entscheidungen ableiten.
Hier gilt natürlich: testen, testen, testen. Und: Wenn Du das schon heute (oder gleich morgen) machst, während das Gros der Tools noch ausschließlich auf TF-IDF setzt, bist Du der Konkurrenz voraus.
Hast Du schon Erfahrungen mit Tools wie Orbitwise gesammelt? Oder meinst Du, diese Entwicklung wird bald schon durch AI-Answering-Machines überholt sein? Ich freu mich auf Dein Feedback!
|
|
| JavaScript-Jammerei |
Lass uns mal wieder über JavaScript sprechen! Will Nye und Darth Autocrat haben dazu vor einigen Wochen jeweils einen Thread bei Twitter verfasst.
7 JS-Probleme laut Will Nye
Will macht den Anfang und packt die 7 häufigsten Probleme aus, mit denen er in den letzten Audits konfrontiert war:
Wenn anstelle eines richtigen <a> Tags irgendwelche <button> oder <span> Elemente mit JS-On-Click-Events genutzt werden, können Linkmodule aller Art nicht gecrawlt werden. Sofern es also keine sehr guten Gründe und eine bewusste Entscheidung dazu gibt, sollte man hier vorsichtig sein und darauf achten, dass alle relevanten Verlinkungen für Crawler erschließbar sind. Das rund zwei Drittel der von Will untersuchten Seiten hier betroffen waren, ist nicht überraschend, wenn wir davon ausgehen, dass es womöglich systemisch bedingt ist. Quelle Auch doof: Wenn der Content nicht richtig gerendert und dargestellt werden kann, weil dafür erforderliche Ressourcen Timeouts erzeugen oder durch die robots.txt vor dem Zugriff der Crawler "geschützt" werden. Ein gutes Drittel der betrachteten Seiten sind betroffen. Quelle Nicht nur im Kontext von JavaScript ein sehr typisches Problem: Anstatt einen Status Code 404 auszugeben, antworten Seiten mit einem Status Code 200. Das ist laut Will für ein Drittel der analysierten Seiten zutreffend. Quelle Eine weitere schlechte Idee ist es, Linkmodule erst nach einer Nutzerinteraktion in den DOM zu injecten. Denn eine Suchmaschine wird so niemals etwas von den Links mitbekommen. Immerhin auf jeder fünften von Will betrachten Seite war das der Fall. Quelle Alle aus SEO-Sicht wichtigen Elemente wie Titles, Robots-Angaben, Canonicals & Co sollten sich beim Rendern des HTMLs nicht verändern oder um weitere Tags ergänzt werden, die gegensätzliche oder widersprüchliche Angaben machen. Trotzdem findet sich auch dieses Phänomen auf 20% der Seiten in Wills Analysen. Quelle Wenn sich die URL verändert, ohne dass die Suchmaschine durch eine 3xx-Weiterleitung etwas davon mitbekommt, kann sie die neue URL auch nicht gegen die alte in der Suche austauschen. Betrifft immerhin jede 10. betrachtete Seite. Quelle Content, der erst nachträglich in den DOM eingefügt wird, wenn der Nutzer irgendwo geklickt hat, existiert für Suchmaschinen nicht. Was nicht existiert, kann nicht indexiert oder gerankt werden. Kommt zum Glück nur in 5% der Fälle vor. Quelle
3-14 JS-Fallstrick von Darth Autocrat
Darth Autocrat legt nach:
"I think the most common JS issues I encounter on websites are:
1) Crappy designers without a clue
2) Crappy developers without a clue
Fancy/Edgy libraries and effects tend to take priority, over things like UX and SEO."
Danach brennt er ein kleines Feuerwerk mit 14 Punkten ab, die ihm immer wieder unterkommen. Es lohnt sich, diese Liste auch einmal anzuschauen.
Fazit
Am Ende bleibt zu sagen: JavaScript kann für manche Dinge durchaus hilfreich, nützlich oder sinnvoll sein. Es gibt teils richtig gute Sachen, die sich damit realisieren lassen.
Aber wenn man es halt falsch oder schlecht einsetzt, dann ist und bleibt es trotzdem doof.\
Denn eigentlich ist JavaScript für Interaktivität und Applikationen gedacht. Wenn Du JavaScript für die Darstellung von Content verwendest, dann verletzt Du ein Grundprinzip: Dem dummen User-Agent möglichst viel erreichbar zu machen. Das ist ein Grundprinzip für ein resilientes, inklusives Internet. Nimmst Du JavaScript, um Content darzustellen, dann verschwendest Du Ressourcen (Datenübertragung, CPU, RAM) von Usern. Und im Zweifel schließt Du User von der Nutzung Deiner Seite aus (und schadest Deiner Reichweite).
|
|
| Anzeige: Kleiner Relaunch |
Kleinanzeigen hat angekündigt am 16. Mai das Ebay aus dem Namen Ebay Kleinanzeigen zu streichen. Logo, Farbpalette und Domain sollen sich ändern. SEO-Experten werden neugierig drauf schauen.
ebay-kleinanzeigen.de ist mit >1.000 Sichtbarkeitspunkten die viertgrößte Domain im deutschen Google-Index. Und mit ca. 25 Mio. indexierten URLs hat der Googlebot dann einiges zu tun.
Laut Spiegel-Artikel hat man sich entschieden, Teile der Design-Umstellungen schon vorab durchzuführen.
Wir SEOs werden das mit Spannung beobachten: Schnell noch mal einen kleinen Crawl machen und schauen, ob auch alles glatt läuft.
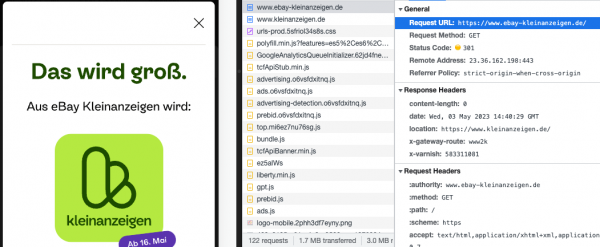
Der User-Traffic wird bereits weitergeleitet:
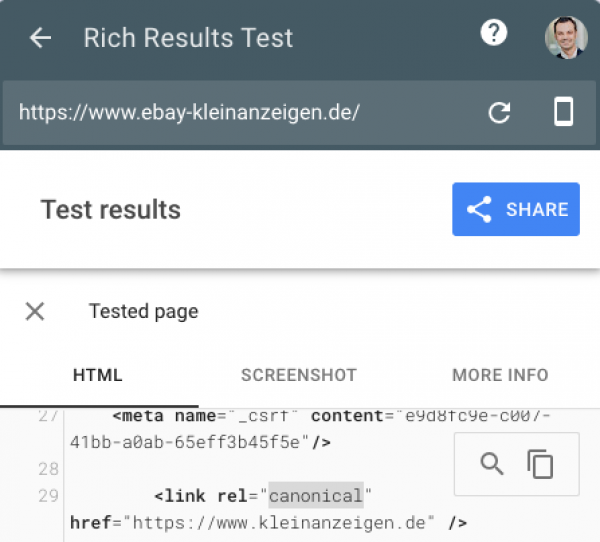
Der Rich-Results-Test zeigt: Die Weiterleitung/das Canonical ist auch schon für Google aktiv:
Seit letzter Woche hat kleinanzeigen.de schon 5 Sichtbarkeitspunkte gewonnen. Aber ebay-kleinanzeigen.de hat bereits 70 Punkte verloren. Das muss einen aber noch nicht unbedingt beunruhigen (wenn man einen Blick auf die Search Console hat und dort validieren kann, was wirklich passiert).
An sich ist der Fahrplan ja einfach:
Vor GoLive:
Sicherstellen, dass URLs und HTML gleich bleiben Sicherstellen, dass interne Verlinkung konsequent angepasst wird 301-Weiterleitungen für alle URLs von alt auf neu (inklusive aller Subdomains, vor allem Bilder) Bilder prüfen und schauen, dass die sich nicht ändern Domain-Migration für alle Subdomains in der GSC bei GoLive GSC für alle Subdomains der neuen Domain anmelden
Bei GoLive:
Robots.txt, Indexierungsregeln prüfen Ancrawlen, um interne Verlinkung sicherzustellen Domain-Migration in GSC für alle Subdomains anmelden
Post-GoLive:
Crawling monitoren Indexierung monitoren Traffic monitoren
Je mehr Informationen sich ändern, desto komplizierter wird es werden und umso größer wird das Risiko. Daher ist es jedes Mal spannend zu beobachten, wie gut Google eine solche Migration verarbeitet (und wie sauber das SEO-Team gearbeitet hat/arbeiten konnte).
Dieser Launch ist noch mal besonders spannend, weil Ebay Kleinanzeigen ein besonders stark fluktuierendes Inventar hat. Die Detailseiten ändern sich täglich. Das macht die Migration noch mal schwieriger als bei einer eher statischen Seite.
Falls Du eine Domain-Migration oder einen Relaunch planst: Wir haben eine sehr umfangreiche Checkliste für Dich (und helfen Dir natürlich auch gern bei der Umsetzung). Schreib uns einfach!
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmen
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





