| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #277 |
|
|

|
| 🍂 Goldene Blätter & graue To-do-Listen |
Der Oktober ist da und mit ihm die Jahreszeit, in der man endlich guten Gewissens alles ein bisschen langsamer angeht. Der Kaffee ist heißer, die To-do-Listen länger und plötzlich fühlt sich Prokrastination nach Selbstfürsorge an.
Während draußen die Blätter fallen, decken unsere Autor:innen diese Woche wieder jede Menge spannende Themen auf:
- Bratapfel-Behrend entfacht im bunten Blättermeer des DMA die heißen Streitthemen
- Laub-Lars liefert Gedanken zur Keyword-Kannibalisierung, die so geschmeidig sind wie Glühwein im Spätherbst.
- Nebelwald-Nora bringt Herbstlicht in Rich Results
- Frost-Florian wirbelt mit einem heißen Apfelpunsch in der Hand das Agentic-Shopping-Laub auf.
- Jacken-Johan zieht die W3C Web Sustainability Guidelines wie herbstlichen Nebel über die SEO-Landschaft.
Also: Kuschelsocken an, Laptop auf, Kürbissuppe bereitstellen und viel Spaß beim Lesen! 🍁
Deine Wingmenschen 🫖
|
|
| DMA: Drängeln, Murren, Angst machen |
Google, Apple und Meta mögen den Digital Markets Act nicht.
Die großen Digitalkonzerne mögen ein EU-Gesetz nicht, dessen Zweck es ist, die Macht großer Digitalkonzerne auf dem europäischen Markt zu beschränken?
Nein... Doch... OHH!
Die Taktiken, die nun dagegen angewendet werden, fasse ich auch als DMA zusammen: Drängeln, Murren, Angst machen.
The DMA should be repealed while a more appropriate fit for purpose legislative instrument is put in place, [...]
– Drängelt Apple
It’s caused us to delay some new features in the EU.
– Murrt Apple
A recent study on the economic impact of the DMA estimates that European businesses across sectors could face revenue losses of up to €114 billion.
– Macht Google Angst
Falls Dir das zu viel Business-Englisch war, frei übersetzt heißt das: "Mimimi". Ich maße mir nicht an, die Ökonomie des Internets umfänglich zu verstehen, aber mir drängt sich das Sprichwort "getroffene Hunde bellen" auf.
In Apples Fall war der Treffer wohl die Entscheidung der EU-Kommission, keine Ausnahme für Apple zu machen und Meta hat sich vor ein paar Wochen auch schon am DMA abgearbeitet.
Während Apple droht, nicht mehr in die EU zu liefern, hat Google schon vor ein paar Wochen die Weichen gestellt, dass sie, auch wenn sie Konkurrenz zum PlayStore erlauben, weiter kontrollieren können, wer Android Apps anbietet… Mal sehen, wie das langfristig gewertet wird.
Aber nicht nur von den Konzernen selbst, das Thema wurde auch beispielsweise bei heise oder LTO aufgegriffen.
Ein anonymer Autor vom Börse Express, dem “führenden Finanzportal" (sagen sie zumindest ganz bescheiden von sich selbst, ich hab vorher noch nie was von denen gehört) hat sogar dieses tendenziöse Stück Agitprop (nicht vergessen, Verlinkung immer mit passenden Keywords im Ankertext 🧐) verfasst.
Wenn ich die dafür bezahlt hätte, ich würde ja mein Geld zurück verlangen:
Sechs Absätze lang wird fleißig argumentiert, dass nur die offiziellen App-Stores sicher seien und alles andere voller Malware und Viren. Der böse DMA verhindere, dass die edlen Betreiber von AppStore und PlayStore ihre User vor der Dunkelheit schützen könnten und dann... reißt der unbekannte Autor die so sorgsam aus dem Zusammenhang gerissene Argumentationskette wieder mit dem Arsch ein und schreibt:
Selbst in offiziellen App-Stores tauchen mittlerweile schädliche Programme auf.
Gefolgt von einer Anzeige, die dem Leser bzw. Leserin versucht, irgendwelche dubiosen Android-Sicherheitstipps anzudrehen.
Platte Propaganda ist ja schon schlimm genug, aber die eigenen Argumente widerlegende Propaganda regt mich wirklich auf!
Aber genug der Medienkompetenzschulung. Warum haben Google, Meta und Apple Grund, so heftig gegen den DMA zu pöbeln?
Die großen Tech-Konzerne haben alle eine Gemeinsamkeit. Sie sind Gatekeeper.
Zum Gatekeeper wird ein Konzern, indem er sein Geschäftsmodell (erfolgreich) auf einem Lock-In-Effekt basiert – Dunning-Kruger-Disclaimer: Das ist meine vereinfachte Laien-Definition, (ich glaube, das trifft den Kern ganz gut, aber vielleicht sieht das auch nur von Mount Stupid aus so aus…) – und die Maßnahmen des DMA zielen darauf ab, genau diesen den Lock-In-Effekt auszuhebeln. Das ist natürlich schlecht fürs Geschäft und entsprechend unglücklich sind die Gatekeeper darüber. Vielleicht habe ich zuviel von Cory Doctorow gelesen, aber ich glaube eher nicht, dass es unserer Gesellschaft schadet, den Prozess der Enshittification zu bekämpfen. Im Gegenteil!
Abgesehen davon ist für uns Online-Marketing-Menschen das Thema DMA auf jeden Fall auch beruflich hochspannend. Was Google zur Einführung des DMA in den SERPs umgesetzt hat, hat Johannes Beus damals direkt analysiert. Das ist aber nicht in Stein gemeißelt und kann durch politische und juristische Entscheidungen beeinflusst werden.
Dazu kommt, dass nicht nur die Suche betroffen ist, sondern dass Google, Meta und Co auf diversen Ebenen in die Regelungen des DMA fallen:
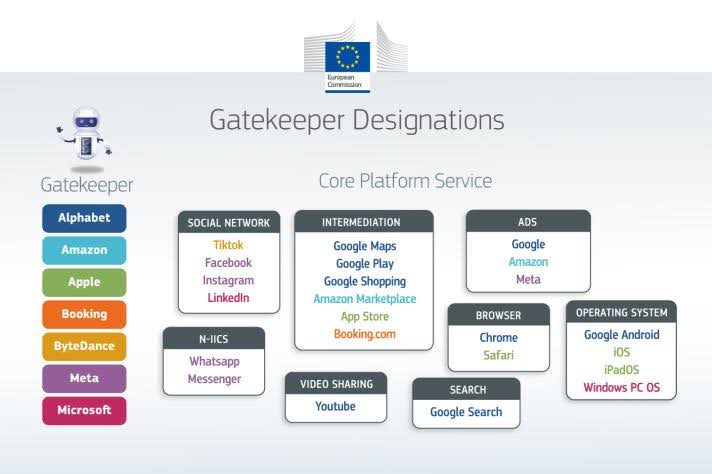 Quelle
Quelle
Neben der organischen Google Suche (inklusive Maps und Shopping) sind auch
- Google Ads
- Meta Ads
- Amazon
- die sozialen Netzwerke von TikTok bis LinkedIn
- und sogar WhatsApp
designierte Gatekeeper. Und wenn es nach europäischen Cloudanbietern geht, gehören Google Cloud, Microsoft Azure und AWS auch bald dazu. Der DMA hat also potenziell direkten Einfluss auf so ziemlich alle Deine Online Marketing Aktivitäten.
Abgesehen von den Vorteilen für unsere Gesellschaft und den Einfluss aufs Online Marketing, hoffe ich auch ganz persönlich auf den Digital Markets Act. Ich erinnere mich an Zeiten, als ich Miranda auf dem Rechner hatte und es mir egal sein konnte, ob meine Freunde mit mir über ICQ, MSN-Messenger oder IRC chatteten. Heute sitze ich da mit einem halben Dutzend Messenger Apps und muss mir Metas illegalen Tracking-Methoden gefallen lassen, weil zu viele andere auf WhatsApp als Kommunikationskanal festgelegt sind. Wenn der DMA durchgesetzt wird, kommen diese guten alten Zeiten vielleicht wieder. Jetzt darf die EU nur nicht einknicken, sondern muss das einfach mal durchziehen.
|
|
| Keyword-Kannibalisierung gibt es nicht, aber sie zeigt Dir die wahren Probleme Deiner Website |
In der SEO-Szene ist Keyword-Kannibalisierung ein großes Thema, das gerne angeführt wird, wenn eine Website zu einem Thema nicht gut aufgestellt ist, aber mehrere URLs zu dem Keyword in der Search Console zu finden sind. Auch viele SEO-Tools haben Berichte zu diesem Punkt. Googelst Du nach Keyword-Kannibalisierung, findest Du zahlreiche Beiträge zu dem Thema, die Dir sagen, dass dieses Phänomen die Qualität der gesamten Website beeinträchtigt.
Hier setzen John Mueller und Martin Splitt an und bescheinigen uns, dass das nicht so ist. Vielmehr sieht John Mueller Keyword-Kannibalisierung als ein "catchall phrase", die noch nicht die wahren Probleme identifiziert. Search Engine Journal schreibt dazu:
"Keyword cannibalization is just a catchall phrase that is applied to low-ranking pages that are on similar topics.
The problem with saying that something is keyword cannibalization is that it does not identify something specific about the content that is wrong. That is why there are people asking John Mueller about it, simply because it is an ill-defined and unhelpful SEO concept."
Mueller hatte Bezug zu dem Thema genommen, da im Zusammenhang mit dem num=100 Parameter die Frage aufgekommen ist, wie es zukünftig möglich sei, Keyword-Kannibalisierung zu vermeiden, wenn man nur noch die Top 20 Positionen sieht. Diese werden natürlich weiterhin angezeigt. Das Problem sei ein anderes: die SEO-Urangst vor Duplicate-Content und den postulierten negativen Folgen für die gesamte Website. Diese negativen Folgen für eine Website gibt es aber nicht. Dies stellt Martin in dem Video SEO Made Easy - How to avoid Duplicate Content noch einmal explizit heraus. Search Engine Journal fasst das Video noch einmal gut zusammen. Herausfordernd für SEOs ist es, dass Martin zwar sagt, es gibt kein Problem, dennoch finden wir in der GSC gleich drei Reports, die sich diesem Thema annehmen:
- “Duplicate without user-selected canonical”.
- “Alternate page with proper canonical tag”.
- “Duplicate Google chose different canonical than user”.
Ganz generell fällt die Einordnung des Themas schwer, da Martin auch sagt, wenn Du sehr ähnlichen Content hast, ist es vielleicht ratsam, diesen zusammenzufassen. Es ist aber auch nichts, was Dir schlaflose Nächte bereiten sollte.
Mueller weiter im X-Thread zu der ursprünglichen Frage und dem Punkt Kannibalisierung:
"All that said, I don't know if this is actually a good use of time. If you have 3 different pages appearing in the same search result, that doesn't seem problematic to me just because it's "more than 1″. You need to look at the details, you need to know your site, and your potential users.
Reduce unnecessary duplication and spend your energy on a fantastic page, sure. But pages aren't duplicates just because they happen to appear in the same search results page. I like cheese, and many pages could appear without being duplicates: shops, recipes, suggestions, knives, pineapple, etc."
Nimmt man alle Aussagen der beiden Google Advokaten zusammen, dann ist der erste Eindruck, dass diese wieder sehr schwammig sind:
- Duplicate Content hat keine negative Auswirkung auf Deine Website.
- Keyword-Kannibalisierung ist kein Issue.
- Google Systeme haben das im Griff, Lösung durch Canonicals.
- Trotzdem bietet es sich an, ähnliche Inhalte zusammenzufassen.
- Es ist nicht schlimm, wenn wir mehrere URLs ins Rennen schicken, aber Du musst Deine Audience kennen.
Nicht eindeutige Aussagen sind wir von Google gewohnt. Aber in diesem Fall sind sie gar nicht so schwammig. Für mich ist es vielmehr ein Votum, die echten Probleme der Website anzugehen, anstatt zu sagen, dass Duplicate Content das Problem ist. Letztendlich gibt es eine Vielzahl von Punkten, die dazu führen, dass eine Seite nicht rankt:
- Die Seiten sind zu lang und folglich nicht fokussiert.
- Die Seiten enthalten themenfremde Passagen.
- Die Seiten sind unzureichend intern verlinkt.
- Die Seiten sind dünn, haben zu wenig Inhalt.
- Die Seiten sind praktisch Duplikate der anderen Seiten in der Gruppe (dies nur ein Thema, wenn die falsche URL rankt).
Einfach 4 von 5 Seiten abschneiden, die sich zum Thema XYZ aufgestellt haben, ist hier nicht die Lösung. Wir sollten uns die Frage stellen, warum wir zu einem uns wichtigen Thema in der Suche nicht stattfinden. Wenn wir ein Shop sind, warum ranken wir mit unserem Ratgeber? Sieht Google uns als Shop? Haben wir die relevanten URLs durch interne Verlinkung entsprechend priorisiert? Ist unser Content organisch gewachsen? Kennen wir unser URL-Inventar? Entsprechen die Inhalte dem, was der User erwartet? Ist unser Inhalt fokussiert?
Wenn wir das Gefühl haben, hier liegt Duplicate Content oder Keyword-Kannibalisierung vor, dann ist dieses Gefühl vermutlich nicht falsch. Aber dann müssen wir erst recht genau hinschauen und die wirklichen Probleme erkennen. Die Ausführungen von John Mueller und Martin Splitt machen sehr deutlich, welche Anforderungen Google an die Organisation des Contents und auch den Aufbau der gesamten Website stellen. Keyword-Kannibalisierung ist hier zu kurz gedacht.
|
|
| Bye-bye Rich Results? Google räumt auf 🧹 |
Google hat wieder aufgeräumt, diesmal bei einigen Rich Results. Seit dem 9. September 2025 werden sechs strukturierte Datentypen nicht mehr in der Search Console gemeldet. Sie verschwinden außerdem aus dem Rich Results Test und den Search Appearance-Filtern.
Betroffen sind:
- Course Info
- Claim Review
- Estimated Salary
- Learning Video
- Special Announcement
- Vehicle Listing
Was heißt das konkret?
Wenn Du eines dieser Markups nutzt, musst Du nichts entfernen, Dein Ranking bleibt unverändert. Die Daten erscheinen lediglich nicht mehr im Reporting oder als Rich Result.
Die API liefert die Daten noch bis Dezember 2025, aber spätestens ab Oktober werden die entsprechenden Felder im Bulk Data Export als NULL ausgegeben. Google empfiehlt, Deine BigQuery-Queries mit IS-Operator umzuschreiben, sofern Du die entsprechenden Spalten noch auswertest.
Warum macht Google das?
Offiziell will Google die Suchergebnisse vereinfachen. Viele dieser strukturierten Daten seien selten genutzt und würden keinen relevanten Mehrwert mehr bieten. Ich glaube, oft sind das auch Tests. Was mögen Nutzer:innen? Was erzeugt Aufmerksamkeit? Am Ende kann die SERP aber auch nicht zu bunt angepinselt werden, dann siehst Du den Wald vor lauter Bäumen nicht mehr.
Was du jetzt tun solltest
- Prüfe, ob Du eines der betroffenen Markups nutzt.
- Passe Deine Dashboards und Datenabfragen an, damit sie nicht ins Leere laufen.
- Behalte den Fokus auf strukturierten Daten, die noch aktiv unterstützt werden.
Strukturierte Daten bleiben zwar wichtig für Verständnis und Kontext, aber nicht mehr automatisch für optische Aufwertung in den SERPs.
Ich sehe das gelassen – wer gute Inhalte mit klarer semantischer Struktur liefert, profitiert trotzdem. Nur eben etwas unauffälliger. 😉
|
|
| Chattest Du noch oder kaufst Du schon? |
ChatGPT hat jetzt Agentic Shopping freigeschaltet. Das heißt Nutzer:innen können Produkte direkt im ChatGPT-Interface entdecken und kaufen, ohne den Chat verlassen zu müssen.
Zum aktuellen Stand gilt das Angebot zunächst nur für US-Nutzer:innen. Der Startpartner ist Etsy und der technische Checkout-Prozess läuft über Stripe. OpenAI plant jedoch, Shopify-Händler und weitere Plattformen sowie andere Länder in Zukunft einzubinden.
Der Checkout-Prozess soll dabei wie ein normaler Chat stattfinden, sodass Nutzer:innen aus einer Produktrecherche direkt einen Kauf tätigen können. Zum Thema Datenschutz und Sicherheit: OpenAI gibt nach eigenen Angaben nur die für den Kauf notwendigen Informationen weiter. Die Kundenbeziehung bleibt beim Händler.
Wichtig für Nutzer:innen
- Agentic Shopping ist auch für ChatGPT-Free-User freigeschaltet, nicht nur für Premium Accounts.
- Kann über ganz normale Fragen ausgelöst werden; kein extra Modus erforderlich.
- Keine Extrakosten für Käufer:innen.
- Einschränkungen: Aktuell ist nur der Einzelproduktkauf möglich (kein Warenkorb).
Wichtig für Händler:
- Händler müssen sich über ein Bewerbungsformular registrieren. Hier kann man sich dafür bewerben.
- OpenAI verlangt einen Produktfeed. Strukturiert, mit Preis, Verfügbarkeit, Bildern etc. Ähnlich wie der Google Shopping Feed für das Merchant Center.
- Händler zahlen eine “kleine” Provisionsgebühr. Wie viel lässt sich bisher nirgends transparent herauslesen.
- Technische Basis: Agentic Commerce Protocol (ACP), entwickelt gemeinsam mit Stripe.
- Andere Zahlungsanbieter können über Delegated Payments integriert werden.
- Die Kundenbeziehung bleibt dabei zwischen Kunde und Händler. Verträge und Zahlungen werden also nur zwischen den beiden Parteien geschlossen und OpenAI hat damit offiziell nichts zu tun.
Wichtig für uns SEOs
- Neuer Kanal für Produkte-Entdeckung/Verkäufe und als Spielwiese zur Optimierung.
- Sich mit Feeds vertraut machen, kann sich nun doppelt auszahlen.
- Augen offen halten für den möglichen Launch in der EU.
Offene Punkte & Ausblick
- Internationale Ausweitung (Europa, Deutschland etc.) ist geplant, aber ohne konkreten Zeitplan.
- Rechtliche Themen (DSGVO, Steuern, Verbraucherschutz) sind in Europa noch nicht abschließend geklärt.
- Zukünftig könnte ein eigenes Ranking-System für Agentic Shopping entstehen, ähnlich Google Shopping, nur im Dialog-Kontext.
Auch wenn ChatGPTs Agentic Shopping derzeit nur in den USA verfügbar ist, bleibt die Entwicklung spannend. Könnte Agentic Shopping Google und Amazon einen Teil des E-Commerce-Markts streitig machen? Was denkst Du?
|
|
| W3C Web Sustainability Guidelines |
Letzte Woche habe ich noch über Cloudflares eigenmächtige Standards gepöbelt.
Heute möchte ich einen neuen Standard-Draft des W3C highlighten. Sandra hat über die Arbeitsgruppe bereits vor einem Jahr berichtet, aber jetzt wurde der erste Draft zur Diskussion gestellt: Die Web Sustainability Guidelines (WSG)
Da das Internet und seine Nutzung je nach Berechnung für 2-5% der klimaschädlichen Emissionen verantwortlich ist, ist es eine gute Idee, sich Gedanken darüber zu machen, welchen Beitrag jeder von uns leisten kann.
Nicht allein, damit wir Performance Tickets in die Nachhaltigkeitsbemühungen des Konzerns einarbeiten können und die Arbeit gemacht wird, ohne unser SEO-Umsetzungsbudget zu belasten, sondern auch, weil nachhaltiger Umgang mit Ressourcen oft zu einer Fokussierung auf die Dinge führt, die wirklich wichtig sind. Die Autoren betonen ebenfalls:
Web sustainability addresses more than just environmental issues [VARIABLES]; intersectional issues such as accessibility, privacy, and security can impact the sustainability of a project.
Die Guidelines behandeln unter anderem:
- Hosting & Infrastruktur: Nachhaltige Host-Provider wählen; Caching, Kompression, CDN sinnvoll einsetzen (! besonders viel Impact hier).
- UX / Nutzerführung: Minimiere unnötige Inhalte, Interaktionen, Schritte.
- Design & Assets, Nutze dekorative Elemente nur, wenn sie einen Mehrwert bringen. Assets (Bilder, Animationen) optimieren.
- Navigation & Architektur: Struktur und Navigationswege klar und effizient gestalten.
- Code & Entwicklung: Nicht notwendigen Code entfernen; lazy loading einsetzen; Redundanzen vermeiden.
- Business-Strategie: Nachhaltigkeitsziele definieren, Rollen zuweisen, Impact transparent machen.
- Messen & Auditieren: Negative Faktoren identifizieren & offenlegen; regelmäßige Tests & Messungen einplanen.
- Vermeidung von Manipulation: Dark Patterns, invasive Werbung, unnötiges Tracking entfernen.
- Wiederverwendbarkeit & Dokumentation: Komponenten, Interfaces und Assets dokumentieren und modular gestalten.
Alle diese Punkte helfen nicht nur der Umwelt, sondern entlasten User von kognitivem Aufwand (und verbessern damit Conversion) und reduzieren Prozess-Overhead im Unternehmen.
Jono Alderson hatte neulich ein schönes Bild dazu: Wenn wir es noch nicht mal schaffen, Webseiten schnell zu machen, obwohl der positive Business-Impact immer wieder bewiesen und unstrittig ist und die Maßnahmen auf der Hand liegen, wie wollen wir dann in einer AI-Welt bestehen, die Agilität und Umsetzung unter Unsicherheit von uns verlangt.
Vielleicht ist das Durcharbeiten und Umsetzen dieser Guidelines also ein Weg AI-Readiness herzustellen?
Ich werde hier auf jeden Fall noch mal tiefer eintauchen.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





