| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #179 |

|
| 💯 5 weitere Thesen (für Deinen SEO-Erfolg) |
Es ist Reformationstag! Zumindest für alle Hamburger und einige weitere Bundesländer Deutschlands. Wenn Du jetzt Panik bekommen haben solltest, dass wir Dich also diese Woche Newsletter-technisch leer ausgehen lassen, dann kannst Du jetzt beruhigt aufatmen. Hier ist er!
Luther nagelte einst seine Thesen an die Tür der Schlosskirche – wir sliden diskret in Deine DMs, ähm, in Dein Postfach und hoffen, dass Du keine 95 SEO-Fehler auf Deiner Website findest:
Kardinal Philipp kreiert kühn konkrete Regex-Tipps Priester Johan proklamiert prioritäre Problemstellungen Nonne Jolle nennt zum Beispiel den schönen Fall eines Fallbeispiels Bischof Behrend behebt behände mit "Clarity" die GA4-Belastung Reformator Nils predigt von der Grausamkeit mancher Google Updates
Und nun, lass Dir den Pumpkin Spice Latte schmecken und viel Freude beim Lesen 🎃🌶️🥤
Deine Wingmenschen
|
|
| 🚪🔐🔣 RegExit Games |
Passend zum Halloween-Anlass habe ich heute mal Regular Expressions mitgebracht. Oft helfen sie einem aus dem Horror-Datenhaus oder dem Keyword-Kerker zu entkommen.
Lass uns mal schauen, wofür RegEx gut sind:
Das Horrorhaus der Zeichenketten
Stell Dir ein altes, knarrendes Haus vor, das am Rande einer verlassenen Stadt liegt. Die Legende besagt, dass nur diejenigen, die die Zeichen kennen, aus diesem Horrorhaus entkommen können. Die Wände des Hauses sind mit rätselhaften Buchstaben und Symbolen bedeckt, und nur mit dem richtigen Zauberspruch -- dem Regex -- kannst Du fliehen.
1. Das Zimmer der verlorenen Seelen
Du betrittst einen dunklen Raum, in dem leise Stimmen flüstern. An der Wand siehst Du mehrere Namen: anita, annemieke, bob, justus und jonas ... Du weißt, Du musst einen Namen finden, der mit einem "a" beginnt, um die Tür zum nächsten Raum zu öffnen.
Dein Regex-Zauberspruch: **^a.***
Mit diesem Zauberspruch leuchten die Namen anita und annemieke auf und zeigen Dir den Weg.
💡 ^ signalisiert in einer RegEx, dass dies der Anfang sein muss. Der Punkt . steht für irgendein Zeichen, egal welches. Das * signalisiert, dass irgendein Zeichen beliebig oft vorkommen kann. Wir suchen also alles, was mit a anfängt und egal, was darauf folgt.
2. Der Korridor der Schatten
Ein langer, düsterer Korridor erstreckt sich vor Dir. Jede Tür hat eine Zahl: 13, 666, 77 und 999. Du hörst ein Flüstern, das Dir sagt, Du musst eine Tür mit einer dreistelligen Zahl wählen, um nicht in eine Falle zu geraten.
Dein Regex-Zauberspruch: ^\d{3}$
Dank des Zauberspruchs erkennst Du, dass die Türen 666 und 999 sicher sind.
💡 Erneut verwenden wir das Dach, um den Anfang zu signalisieren. \ ist ein Escape. Da das "d" ein normaler Buchstabe ist, wir ihn aber als einen Teil der RegEx verwenden wollen, müssen wir ihn "escapen". Das macht man mit dem Backslash . Das kleine d mit dem \ steht für eine Zahl. Die geschweifte Klammer {}, wenn nur eine Zahl darin vorkommt, symbolisiert, dass das vorangegangene Zeichen, irgendeine Zahl, dreimal vorkommen muss. Das $ signalisiert das Ende.
Wir schauen also nur auf Strings, die mit 3 Zahlen anfangen und nicht mehr enthalten.
3. Das Labyrinth der Verwirrung
Nachdem Du den Korridor der Schatten verlassen hast, findest Du Dich in einem endlos scheinenden Labyrinth wieder. Wände aus Buchstaben und Symbolen erstrecken sich in alle Richtungen. In der Mitte des Labyrinths befindet sich eine riesige Steintafel.
Auf dieser Tafel sind Sätze eingraviert, die sowohl Buchstaben als auch Zahlen enthalten. Einige Sätze sind in Klammern, andere nicht. Du spürst, dass Du einen spezifischen Satz finden musst, der mit einem Wort beginnt.
Dieses Wort ist "wngmn". Darauf müssen ein Satzzeichen, ein Leerzeichen und eine vierstellige Zahl in Klammern folgen. Das ist eine Stufe schwieriger als vorher.
Dein Regex-Zauberspruch lautet: ^wngmn\w\s(\d{4})$
💡 Was bedeutet das alles?
^wngmn = Wort, das mit "wngmn" beginnt \w = nicht-alphanumerisches Zeichen (z.B. ein Satzzeichen) \s = Leerzeichen ( = Klammer auf, die wir mit \ escapen müssen, da Klammern normalerweise in einer RegEx für Capture Groups stehen \d = eine Zahl {4} = das vorherige Zeichen (= eine Zahl) muss viermal vorkommen ) = Klammer zu, die wir mit \ escapen müssen $ = Ende unserer Abfrage
Auf der Steintafel leuchtet auf: "wngmn! (3110)". Ein Teil der Wand des Labyrinths schiebt sich zur Seite und enthüllt einen versteckten Gang. Juhuuuuu, Du hast es geschafft.
RegEx sind Dein Freund und Helfer, wenn es um Daten geht
RegEx einfach erklärt: Finde im Datenwust, was Du suchst. Das kann beispielsweise in Google Sheets, Knime, Sublime Text, Google Collab, Sistrix, Google Search Console und auch Google Analytics sein.
Du siehst, da sind viele Tools bei, die in der SEO-Welt häufig verwendet werden und darum lege ich Dir ans Herz, RegEx zu lernen. Ich bin auch noch ein Padawan und staune nicht schlecht, wenn manche meiner lieben Wingmenschen, ohne auch nur mit der Wimper zu zucken, den Avada Kedavra der RegEx raushauen, um die Daten zu bezwingen. 🪄
Wie kannst Du RegEx lernen? Sehr gut geeignet finde ich RegEx Learn. Dort findest Du zwei unterschiedliche Spiele. Eins davon hilft, RegEx kennenzulernen und die nächste Stufe ist auf SEO bezogen. Das hat mir gut gefallen.
Und weil Halloween ist, schlage ich Dir auch das Slash & Escape Game vor.

Bevor jetzt jemand um die Ecke kommt: ChatGPT kann Dir mit RegEx helfen. Ja, definitiv. Aber wenn Du nicht beurteilen kannst, ob die RegEx richtig ist, kannst Du am Ende Probleme bekommen. Weil Du den Fehler nicht findest. Oder die RegEx vielleicht falsch ist und Du es nicht erkennst.
Es kommt teilweise regexemplarischer Quatsch als Output heraus, wie Johan vor einigen Monaten feststellen musste.\
ChatGPT ist besser geworden. Allerdings nicht fehlerfrei. Also: Lerne RegEx zu verstehen und nutze ChatGPT & Co., um Deine Arbeitsabläufe zu beschleunigen, und nicht um Deinen Kopf abzustellen. Du bist kein Zombie! 🧟
|
|
| 🥇🥈🥉 Hast Du ein Prioritäten-Problem auf dem Index? |
Wenn man so alt aussieht wie ich schon lange professionell SEO betreibt, dann wundert man sich manchmal, was für einen selbst selbstverständlich ist und für andere große Neuigkeiten.
Ammon Jones (der sieht noch älter aus als ich, gegen den bin ich ein Frischling in der Branche, hat daher einen kleinen Thread gemacht zu Priorisierungssystemen für Crawling und Indexierung.
Der Thread ist aus meiner Sicht recht vollständig und beschreibt, wie Googles System zur Priorisierung des Crawling-Backlogs und des Indexierungs-Backlogs funktioniert.
Was aus meiner Sicht noch deutlicher herausgestellt werden darf:
Es handelt sich nicht um ein Backlog, sondern um zwei voneinander unabhängige Priorisierungssysteme: Natürlich muss eine URL erst gecrawlt werden, damit sie indexiert werden kann. Aber das Indexierungsbacklog hat eine eigene Priorisierung:
Weil es ganz andere Wettbewerber gibt. Die ganzen Noindex-URLs spielen jetzt beispielsweise keine Rolle mehr. Weil es mehr Signale gibt, die auswertbar sind. Eine Weiterleitung ist beispielsweise weniger Aufwand für die Indexierung, als ein PDF-Dokument mit 15MB, da sie „nur" als alternative URL in die Canonical-Gruppe mit eingetragen werden muss. Ein 404 oder 410 Status Code lässt sich auch schneller prozessieren, als das Parsen einer vollständigen 200er URL. Wenn 404/410 Status Codes nicht ohnehin in ein unabhängiges (de-)-Indexierungsbacklog wandern.
Googles Kostenrechnung hat sich verändert
Außerdem schreibt Ammon zu Recht, dass sich um das Crawling reichlich gekümmert wurde in der Vergangenheit (nicht, dass viele Leute wirklich wüssten, wie das Crawling optimiert wird, aber immerhin). Was aber deutlicher sein könnte, ist, dass Googles Kosten sich geändert haben. Früher war das Crawling im Verhältnis ähnlich teuer wie die Indexierung. Heute ist der Indexierungsprozess deutlich teurer und der Wettbewerb um die Indexierungs-Pipeline viel größer als um Crawling Ressourcen. (Und das, obwohl durch JS-Crawl die Crawling-Kosten sich verzehnfacht haben dürften).
Wie sieht's mit Qualität aus?
Was ich außerdem noch ergänzen würde: Als wesentliche Priorisierungs-Faktoren nennt Ammon Links, Demand, Volume.
Was fehlt ist Qualität: Qualität der anderen URLs, die in der jüngeren Vergangenheit gecrawlt (und indexiert) worden sind. Und leider fehlt auch der Hinweis, dass diese Qualität nicht nur global für eine Domain, sondern auch für Seitenbereiche/ URL-Muster separat bestimmt werden kann.
Und wo ich das zusammenschreibe, habe ich noch einen weiteren Gedanken unter meiner ergrauten Kopfhautbedeckung: SPAM-Signale. Wenn Deine URLs aussehen, wie Paginierungs-URLs, dann wird es schwieriger sie crawlen zu lassen. Wenn Deine URLs auf einem SPAM-Host liegen, dann wird Google weniger crawlen.
Und wenn Deine URL-Muster aussehen wie SPAM-URLs, dann wird es schwieriger, Deine URLs mit hoher Priorität zu crawlen. Von Indexierung brauchen wir da gar nicht erst sprechen.
Trotzdem: Der Reminder, dass Google priorisieren muss und wie Google priorisieren könnte, ist enorm wichtig für Dein SEO 2024.
(Deshalb spreche ich auch auf der SMX 2024 über dieses Thema. Anmelden lohnt sich. Auch für den Tech-SEO-Workshop, wo wir uns ebenfalls mit solchen und vielen anderen Themen in der Tiefe beschäftigen werden.)
|
|
| 🌐📦 Case Study: Domain-Konsolidierung im internationalen Website-Geflecht |
Website-Relaunches, Migrationen, Domain-Umzüge: Viele Begriffe für einen neuralgischen Punkt im Lebenszyklus von Webseiten, bei dem SEO-seitig alles bergab oder so richtig bergauf gehen kann.
Edgar Gunt von Bloofusion hat uns mit seiner "Relaunch Fallstudie: Domain-Umzug wedi.de -- wedi.net" ein Geschenk gemacht. Er nimmt uns mit in die Gedanken, Ziele und Hindernisse mehrerer (Sub-) Domain-Umzüge und zeigt, was es am Ende gebracht hat.
Unterschiedliche Relaunch-Arten
Es lohnt sich, einmal klar zu haben, um welche Art von Relaunch es hier ging. Es gibt nämlich grundsätzlich verschiedene:
Design-Veränderung (Revamp) System-Umzug (zum Beispiel von WordPress zu Hubspot) Umzug von einer Domain/Subdomain zu einer anderen Umzug von einem Verzeichnis der Domain zu einem anderen derselben Domain Großangelegte Inhaltskonsolidierung/-ergänzung (Aktualisieren, Löschen, Zusammenführen, Weiterleiten, Hinzufügen von Content) Und sämtliche Mischformen
Toll! Endlich mal nur ein Aspekt isoliert betrachtet: Der Domainumzug
"Wenn wir das angehen, dann machen wir es direkt richtig", hören wir oft im Beratungsgeschäft. Und manchmal lässt es sich gar nicht verhindern. Wenn Du auf ein anderes System umziehst, verändern sich oft notgedrungen die URLs, so dass Du Dir den Verzeichnisumzug gleich mit einbrockst. Auch kommt dann direkt ein neues Design ins Spiel. Und wenn Du schon beim Redirect-Mapping bist, fällt Dir anhand der Leistungsdaten pro URL auf, dass Du Dir das Umziehen vieler URLs direkt sparen kannst, weil sie keinem Zweck dienen.
Das ist sehr verständlich, macht es Suchmaschinen wie Google aber unendlich viel schwerer, die Signale und Rankings der alten URLs eindeutig und korrekt auf die gewünschten neuen zu übertragen. Auch deshalb bin ich ganz begeistert von der Fallstudie.
Hier wurde der Inhalt bis auf ein paar "Hygienemaßnahmen" weitgehend in Ruhe gelassen und auch von Redesign oder Systemumstellung habe ich nichts gelesen.
Zentraler Ansatz trotz Internationalisierung
In der reinen SEO-Lehre plädieren wir häufig für so wenig Domains und Microsite-Konstrukte wie möglich. Schließlich muss sich jede Domain ihr eigenes Standing, E-E-A-T-Signale, Backlinks, Markenwert aufbauen und das ist für eine Website leichter als für sieben.
Was könnte gegen eine zentrale Domain sprechen?
Völlig unterschiedliche Themen oder Zielgruppen Genügend Ressourcen, um eine SERP-Dominanz-Strategie zu fahren und mit mehreren Brands die Suchergebnisse zu besetzen (siehe MediaMarkt und Saturn) Internationale Märkte, die einer generischen Top-Level-Domain nicht genügend Vertrauen entgegenbringen Verschiedene Märkte, die von völlig unabhängigen Teams bespielt werden
Obwohl "wedi" in vielen Ländern der Welt vertreten ist, haben sie sich entschlossen, von einer Multi-Domain-Strategie auf eine zentrale Lösung umschwenken (vorerst bis auf die Ausnahmen von Portugal und Spanien).
Der Umzug konkret
Links findest Du die alte, rechts die neue URL-Struktur:
Alle URLs des alten Hosts/Verzeichnisses wurden entsprechend auf die neue generische Top-Level-Domain umgezogen und per 301-Redirect weitergeleitet. Die URL-Pfade am Ende blieben jedoch jeweils gleich.
Das Ergebnis
Laut Edgar hat Bloofusion zur Erfolgsmessung den Sichtbarkeitsindex von Sistrix im jeweiligen Land herangezogen und Leistungsdaten aus der Google Search Console verglichen. In die GSC-Daten bekommen wir keinen Einblick, aber für sämtliche Umzüge findest Du im Artikel den passenden Vorher-Nachher-Vergleich von Sistrix.
Ich habe hier mal alle betroffenen Domains in der Zusammenschau betrachtet:
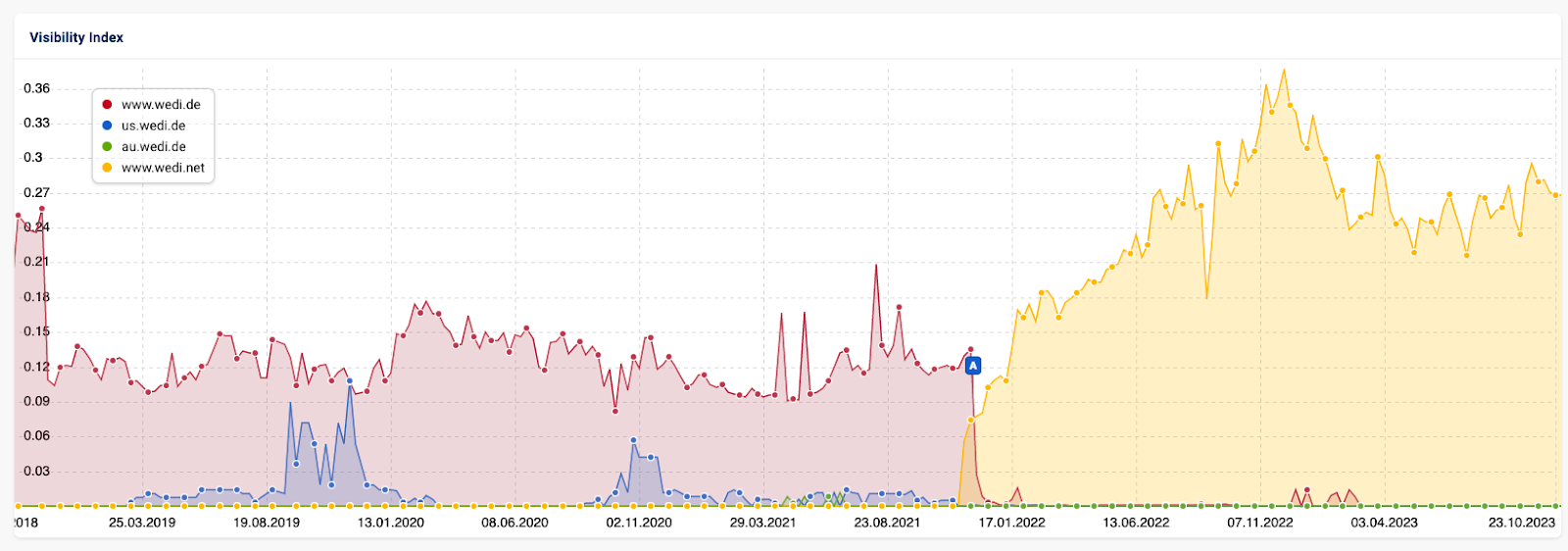 \
Das Ergebnis: Der Sistrix-Sichtbarkeitsindex von www.wedi.net ist nach dem Domainumzug mehr als der von www.wedi.de, us.wedi.de und au.wedi.de zusammen. \
Das Ergebnis: Der Sistrix-Sichtbarkeitsindex von www.wedi.net ist nach dem Domainumzug mehr als der von www.wedi.de, us.wedi.de und au.wedi.de zusammen.
Das hat super funktioniert, würde ich sagen.
Der entscheidende Faktor
Im Artikel werden einige genannt, doch der mit Abstand wichtigste scheint mir dieser zu sein:
Die Vorbereitung sämtlicher 301-Weiterleitungen aller alten URLs auf die neuen in Form eines Redirect-Mappings inklusive Crawling-Tests in einer Testumgebung noch vor dem Golive. Hier konnten Fehler, die es unweigerlich gegeben hat, abgeräumt werden, bevor das Ganze liveging. 👏👏👏
Offene Fragen?
Natürlich kann die Fallstudie nicht sämtliche Interna offenlegen. Mich interessiert natürlich brennend Folgendes:
Wie international/zentral war das Team, um die Migration länderübergreifend aus einem Guss hinzubekommen? Hatten schon vorher alle Domains dieselbe technische Basis? Wenn das Verzeichnis /en ursprünglich als Default-Lösung für internationale Nutzer bestimmt war, die keiner spezifischen Sprachversion zuzuordnen sind, und wenn das Verzeichnis /uk nur für den britischen Markt dienen sollte, es aber inhaltlich keine Unterschiede zu /en gab, wieso wurden dann trotzdem auf wedi.net/en und wedi.net/uk gesetzt?
In Summe eine tolle Datengrundlage für die Entwicklung einer Domainstrategie. Vielen Dank dafür!
|
|
| 🥽🦊 Clarity schafft tierische Transparenz |
Ich habe in meinem Beitrag von letzter Woche Clarity erwähnt. Wenn Du die jetzt auf der Liste von GA4-Alternativen hast, hol nochmal Deinen Datenschutzbeauftragten und nehmt Euch ein gutes Getränk und sorg am besten dafür, dass der oder die DSB stabil sitzt.
Ich habe mir endlich mal Zeit genommen, Clarity genauer anzusehen. Netterweise gibt es (ähnlich wie bei Google Analytics) ein Demo-Konto für Clarity zum Testen.
Zunächst ans Oberflächliche
Die UX ist erstmal schön übersichtlich, auch wenn ich mich frage, warum da ein Fuchs ist und warum kein Frontend Developer berücksichtigt hat, dass es bei mehrsprachiger Darstellung unterschiedlich lange Metrik-Namen gibt.
 Screenshot aus Microsoft Clarity-Demo-Property
Screenshot aus Microsoft Clarity-Demo-Property
Auch die Sortierung von Ländern ist verwirrend, bis man erkennt, dass die Werte zwar übersetzt, aber vor der Übersetzung sortiert wurden:
 Screenshot aus Microsoft Clarity-Demo-Property
Screenshot aus Microsoft Clarity-Demo-Property
Aber bei einem kleinen Web-Analyse-Startup wie Microsoft wollen wir mal nicht so sein. Es ist ja nicht so, als wären die einer der größten IT-Konzerne weltweit und hätten Jahrzehnte an Erfahrung in UX... Okay, vielleicht finden wir es doch zumindest ein bisschen peinlich...
Aber wer ein bisschen in GA4 rumspielt, findet auch da im Frontend Darstellungsfehler. Nur halt kein Füchse ¯\_(ツ)_/¯ ... und keine Möglichkeit zu sehen, wie viele Einstiege über eine bestimmte Quelle kamen (siehe mein Beitrag von letzter Woche).
Jetzt ans Eingemachte
Aber das ist nicht der Punkt, warum Dein Datenschutzbeauftragter stabil sitzen sollte. Das sind dagegen die Menüpunkte "Aufnahmen" und "Heatmaps".
Clarity ermöglicht es, für einzelne Sitzungen die Mausbewegungen nachzuverfolgen und detailliert zu tracken, wo wie geklickt wurde. Außerdem werden Scroll- und Click-Positionen erfasst und ähnlich wie bei Hotjar als Heatmaps dargestellt.
Microsoft behauptet zwar, dass Clarity DSGVO-konform ist, hat leider das Gegenteil einer datenschutzfreundlichen Best Practice in der Clarity Demo Property dargestellt:
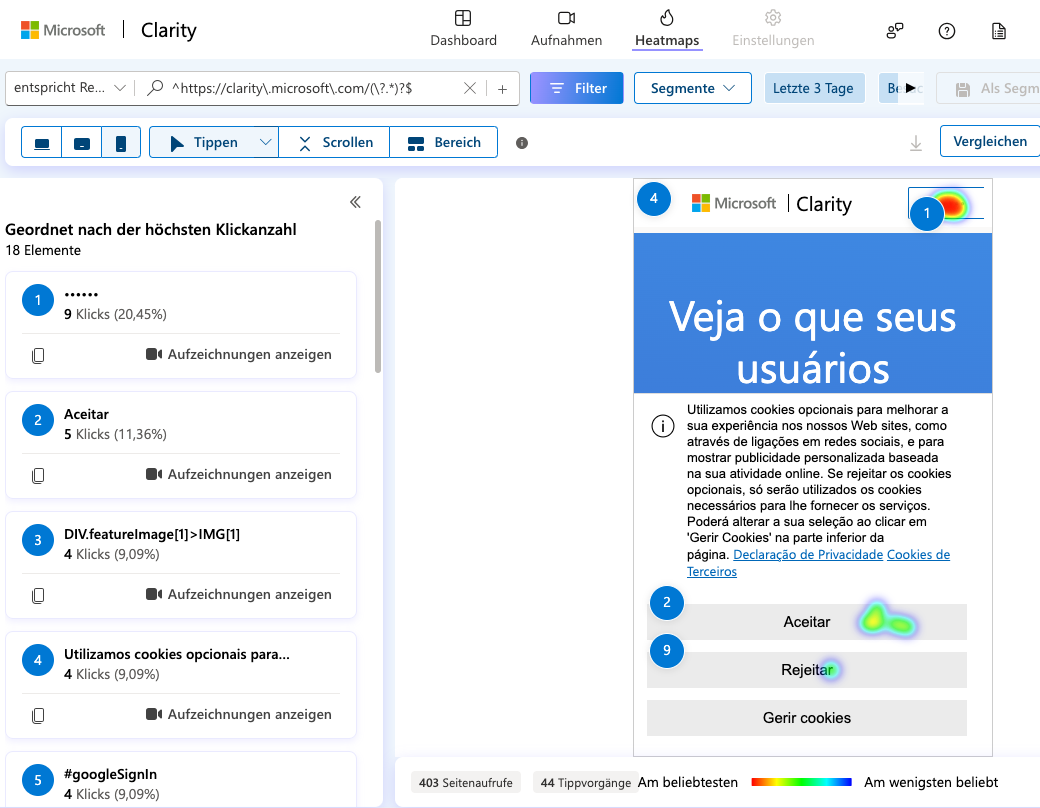 Screenshot aus Microsoft Clarity-Demo-Property Screenshot aus Microsoft Clarity-Demo-Property
So eine Heatmap von einem Consent Banner ist datenschutzrechtlich mehr als nur ein bisschen problematisch. Vielleicht kann Microsoft argumentieren, dass alle Datenbanken dieser Property von Microsoft selbst betrieben und keine personenbezogenen Daten mit einer Third Party geteilt werden...
Also außer die Clarity-IDs bei den Session-Aufzeichnungen, die dort für alle Welt einsehbar sind. Das ist tendenziell auch mit Consent ein Problem. Vielleicht findest Du ja den Nutzer mit der Client-ID "hyemz", das war ich beim Schreiben dieses Artikels.
Zugegebenermaßen konnte ich es nicht aus den Requests extrahieren, sondern habe drei MacOS-Sessions zum passenden Zeitpunkt aus Deutschland durchgucken müssen, um meine wiederzuerkennen... Trotzdem: Max Schrems ick hör dir trapsen...
Möglich, aber nötig?
Grundsätzlich halte ich es für vorstellbar, solche Funktionen datenschutzkonform umzusetzen. Aber es muss gewährleistet sein, dass die Trackingdaten strikt von personenbezogenen Daten getrennt werden. Dazu müsste aber, beispielsweise über ein Server-Side Tagging mit umfangreicher Anonymisierung und sauberem Consent-Management gewährleistet werden, dass keine Informationen ohne Consent fließen und dass die IDs noch einmal so pseudonymisiert werden, dass weder Microsoft, noch wir selbst oder irgendjemand anderes Clarity-IDs einem konkreten Nutzer zuordnen können.
Das ist allerdings mindestens so aufwendig, wie es klingt, ohne dass diese Funktionen einen wirklich großen Mehrwert für unsere Arbeit bieten.
Vielleicht klammern wir Clarity mal lieber aus der Auswahl aus... Ach übrigens: Hab ich erwähnt, dass das Universal Event Tracking für Bing Ads per Default auch Clarity Daten sendet? Falls Du also das Bing-Ads-Tracking nutzt, hast Du wahrscheinlich automatisch die beschriebenen Features. Ganz einfach und ohne Aufwand Deinerseits.\
So und jetzt geh Deinen Datenschutzbeauftragten beruhigen. Tief in der Dokumentation ist sogar beschrieben, wie Du Clarity im UET Tag deaktivieren kannst.
|
|
| 🕊️🔨 Innocentia nihil probat |
Ich hatte in der Schule nie Latein, aber als Teilzeit-Nerd ist mir dieses Zitat mit der wunderschönen Übersetzung "Unschuld beweist nichts" im Warhammer 40.000 Universum über den Weg gelaufen. Ich verspreche Dir, dass das am Ende etwas mit SEO zu tun hat ;)
In diesem dystopischen Sci-Fi-Setting ist die Menschheit in der fernen Zukunft extrem fanatisch geworden. Das Motto der imperialen Inquisition, einer Organisation mit nahezu uneingeschränkter Macht, ist das besagte Zitat. Wenn Du erstmal ins Visier gerätst und der Ketzerei bezichtigt wirst, hilft es Dir nicht mal mehr, solltest Du tatsächlich unschuldig sein. Beruhigend, oder?
Manchmal hat man ja das Gefühl, dass es auch mit den Rankings so funktioniert. Da kommt ein Core Update, Spam Update, Helpful Content Update und am Ende sind die eigenen Rankings weg. Dabei versucht man doch schon, nach bestem Wissen und Gewissen Content zu erstellen, keine Schund-Links aufzubauen und im Idealfall auch noch, sich als Experte oder Autorität zum Thema zu positionieren. Trotzdem macht der Sichtbarkeitsgraph den Tiefflug.
Hier nun der Gedanke, der mich zu dem gesamten Exkurs bewegt hat: Wenn Dich so ein Update erwischt, kannst Du zunächst ja gar nichts anderes machen, als zu spekulieren. Die eingängigen Kanäle prüfen, was die Kerninhalte des Updates womöglich waren, Deine Seite nochmal genau unter die Lupe nehmen (Die These, dass alle anderen gewonnen haben, mal außen vor).
Das ist doch irgendwie frustrierend. Selbst wenn Du Maßnahmen umsetzt, beispielsweise Dich bemühst, E-E-A-T-Aspekte auf Deiner Seite zu stärken, Quellen einzubeziehen, Autoren abzubilden und so weiter. Der Erfahrung nach ist der Weg zurück an die Spitze ein mühsamer und selten so rasch wie der Absturz. Es sei denn, ein weiteres Update kommt um die Ecke und spült Dich wieder nach oben. Denn wenn Du nichts verbrochen hast (und das auch gewissenhaft geprüft hast), dann sind die Chancen tatsächlich nicht schlecht, dass ein weiteres Update die Dinge wieder gerade rückt.
Geduld ist ja ohnehin eine Eigenschaft, die wir als SEOs häufiger beweisen müssen. Da können wir uns dann auch noch etwas Frustrationstoleranz und Optimismus aneignen. Damit Du gleich Bescheid weißt, wann Deine nächste Chance ist, möchte ich Dir das Google Search Status Dashboard ans Herz legen. Hier siehst Du zum einen alle Updates und Probleme, die gerade in der Suche auftreten, zum anderen gibt die History einen ganz praktischen Überblick über die zurückliegenden.\
Wenn Du ein Mensch bist, der noch RSS-Feeds abonniert, kannst Du dich über die Entwicklungen in der Google Suche sogar direkt benachrichtigen lassen. In der Zwischenzeit lass uns doch wissen, wie Du mit einem Nackenschlag in Deinen Projekten umgehst!
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





