| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #178 |

|
| 🌧️ ☔ Wir lassen Dich nicht im SEO-Regen stehen |
¯\_(ツ)_/¯ Während draußen der stete Tropfen die Melodie des Herbstes spielt und Pfützen sich zu kleinen Seen formieren (oder auf gut Deutsch: Es ist nass und a****kalt), hoffen wir, dass die "flutenden" Google-Updates Dich nicht allzu nass gemacht haben.
Denn Google hat unjüngst den Abschluss des Oktober 2023 Spam Updates sowie des Oktober 2023 Core Updates verkündet.
Um sicherzustellen, dass Du und Deine Website nicht im SEO-Wolkenbruch untergehen, präsentieren wir Dir diese Woche diese tropfend frischen Themen:
Matt hat sprudelnde Tipps, wie Du Deine Thementropfen so kombinierst, dass sie keine riesige Pfütze ergeben Hannah lässt endlich die Wolken der Ratlosigkeit verschwinden und teilt den finalen Part ihres Tagseiten-Monsuns Behrend packt die Gummistiefel aus und analysiert die Nutzbarkeit des windigen Tools GA4 Wolkenbrecherin Anita cached für Dich im Trüben und sorgt für klare Sicht Jolle aka Cloudy-Aaaah hat sich für Dich durch den "The State of Content SERPs"-Report von Glen Allsopp gearbeitet
Wir hoffen, Du bleibst im SEO-Herbststurm standfest und erreichst ohne weitere Schauer die sonnigen Spitzen der Suchergebnisse.
Pack den Regenschirm aus und viel Vergnügen beim Durchnässen der Inhalte.
Viel Spaß beim Lesen!
Deine Wingmenschen
|
|
| Wie war das nochmal mit Topic Clustern und Pillar Pages? |
Aktuell spricht jeder über Künstliche Intelligenz und SGE. Und zwar zurecht! Trotzdem lohnt es sich natürlich, hin und wieder auch noch einmal den Blick auf andere Bereiche zu richten.
Darum bekommst Du von mir heute etwas zu Topic Clustern. Ja, das mit den Pillar Pages... Für viele sicher ein alter Hut, die zahlreichen Kraut-und-Rüben-Strukturen auf einigen Websites da draußen zeigen aber, dass das Thema doch noch nicht überall angekommen ist.
Also gibt es hier und jetzt eine Schritt-für-Schritt-Anleitung, wie das mit den Pillar Pages, Cluster-Inhalten und der internen Verlinkung bei Topic Clustern idealerweise aussehen sollte. Pack ma's:
Schritt 1: Themenrecherche
Ganz am Anfang jedes Topic Clusters steht (idealerweise) erst einmal eine ausgiebige Recherche. Für viele da draußen sicher der leidigste Part, weil es Tage oder manchmal sogar Wochen dauern kann, die richtigen Themen und Keywords zu identifizieren. Aber wie das häufig so ist: Ohne solide Basis wird das nichts. Also doch ein paar Tage durch die SERPs und Tools wie Sistrix oder Ahrefs wühlen.
Schritt 2: Erstelle Deine Pillar Page
Ist das Fundament in Form einer ordentlichen Themenrecherche erst einmal gelegt, geht's ans Eingemachte. Heißt konkret: Erstellen einer umfassenden Pillar Page, die das zentrale Thema detailliert behandelt: von A bis Z, von links nach rechts und von oben nach unten. Üblicherweise ist das ein Shorthead-Keyword wie "Gesunde Ernährung". Dazu jetzt noch eine umfassende und informative Seite basteln, die alle (oder zumindest die wichtigsten) Punkte und Fragen dazu abdeckt und fertig. Geheimtipp: Sprungmarken und "Back-to-Top"-Button nicht vergessen! Niemand scrollt gerne vier Minuten, um wieder an den Anfang einer Seite zu kommen.
Schritt 3: Erstelle Cluster-Inhalte
Sobald die Pillar Page glänzt und funkelt, ist es an der Zeit, die einzelnen Cluster-Inhalte zu erstellen. Dabei handelt es sich üblicherweise um Longtail-Keywords, die sich auf einen bestimmten Teilbereich des zentralen Themas konzentrieren. Um bei unserem Beispiel "Gesunde Ernährung" von vorhin zu bleiben: "Gesunde Snacks und Mahlzeiten für unterwegs" und "Proteine und ihre Rolle in einer ausgewogenen Ernährung" wären hierzu einige denkbare Cluster-Inhalte. Natürlich musst Du nicht alle ergänzenden Inhalte auf einmal erstellen, sondern lass das Ganze einfach nach und nach wachsen. Passend zu SEO eben!*
Schritt 4: Interne Verlinkung
Die Pillar Page steht, Cluster-Inhalte sind erstellt. Fehlt natürlich noch die interne Verlinkung zwischen den verschiedenen Inhalten. Wie Du das am besten umsetzt, hängt natürlich immer ein Stück weit von Deiner Seite ab. Grundsätzlich gilt aber: Die Pillar Page verlinkt auf die Cluster-Inhalte. Die Cluster-Inhalte wiederum verlinken auf die Pillar Page und verlinken sich (zum Teil) untereinander. Damit der Linkjuice auch ordentlich fließen und Google (und Nutzerinnen und Nutzer) die thematische Verbindung verstehen kann.
Schritt 5: Aktualisiere und optimiere regelmäßig
Mit dem einmaligen Erstellen ist die Arbeit natürlich noch nicht erledigt. Schön wär's. Die Konkurrenz schläft ja bekanntermaßen nicht und oft kommen im Laufe der Zeit auch neue Informationen zum Thema dazu. Oder es fällt Dir noch ein Teilbereich auf, an den Du bis dato noch gar nicht gedacht hast. Darum steht auch regelmäßiges Aktualisieren und Optimieren auf der To-Do-Liste. Sei es das Hinzufügen einer neuen Statistik, das Streichen eines veralteten Abschnitts oder das Überarbeiten der Struktur generell.
Schritt 6: Überwache und analysiere die Leistung
Deine Pillar Pages und Cluster-Inhalte können noch so schön und ansprechend sein... Wenn sie niemand liest oder findet, waren all die Mühe und Tränen bei der Erstellung umsonst. Darum solltest Du natürlich immer auch einen Blick auf Google Analytics und in die Google Search Console werfen, um die Leistung Deiner Pillar Page und Cluster-Inhalte im Auge zu behalten. Und wer weiß? Vielleicht geht da ja noch mehr...
Und nu?
Ja, das war's auch schon! Sechs Schritte, mit denen Du bei der richtigen Umsetzung Deine Autorität, Sichtbarkeit und Rankings steigern kannst. Falls es Deiner Website bisher also noch (ein bisschen) an Struktur mangelt oder Du Deine Beiträge bisher eher so "nach Gefühl" organisierst: Topic Cluster sind die Lösung! Also Termin für die Themenrecherche in den Kalender eintragen (oder Du meldest Dich bei uns und wir übernehmen das für Dich).
*Übrigens muss die Pillar Page nicht unbedingt vor den Cluster-Inhalten erstellt werden. Häufig ist es auch sinnvoll, zuerst den Longtail anzugehen und die Inhalte dann auf einer Pillar Page zusammenzubringen, also Schritt 2 und Schritt 3 umzukehren. Dann hast Du mit einzelnen Content Pieces schon Relevanz fürs Thema bewiesen und kannst dann den Short Head angreifen.
|
|
| Taggadi, Taggada – Wie aus Tagseiten Themenseiten werden |
In der ersten Ausgabe haben wir uns damit befasst, was Tagseiten eigentlich sind und wozu man sie überhaupt gebrauchen kann. In der zweiten Ausgabe haben wir uns angesehen, wie wir die richtigen Tags für unsere Artikel finden. Aber wie können wir einfache Tagseiten in nützliche Themenseiten verwandeln? Dieser Frage widmen wir uns heute.
Aus manchen Tags wirst Du Themenseiten und/oder Filter erstellen wollen. Andere (beispielsweise "Print Übernahme") sollten nur im Backend einsehbar sein.
Bei der Frage, ob Tagseiten indexiert werden oder nicht, ist es wichtig sicherzustellen, dass Tagseiten nicht automatisch und ohne nochmals überprüft zu werden indexierbar sind. Das ist umso wichtiger, wenn Du die Tags noch nicht normalisierst, clusterst und zusammenführst. Auch automatisierte Indexierungsregeln anhand einer bestimmten Anzahl von Artikeln solltest Du immer mit viel Vorsicht genießen.
Bitte lass immer das SEO-Team oder die/den SEO Deiner Firma über die Seiten schauen und diese optimieren, bevor diese in den Index gepustet werden.
Welche Tagseiten wollen wir indexiert haben?
Möchtest Du mit Deinen Tagseiten ranken, kannst Du sie mit ein bisschen (mehr) SEO-Magie und Liebe von einer simplen Ansammlung an Artikeln zu einer gepflegten Übersichtsseite umgestalten.
Anstatt also alle Artikel auf der Tagseite zu listen – meist ist das chronologisch der Fall – kannst Du die Artikel clustern und entsprechend auf der Seite anordnen. So kannst Du dann beispielsweise verschiedene Module bauen, die wirklich hilfreich sein können. Wie das aussehen kann, schauen wir uns nachfolgend genauer an.
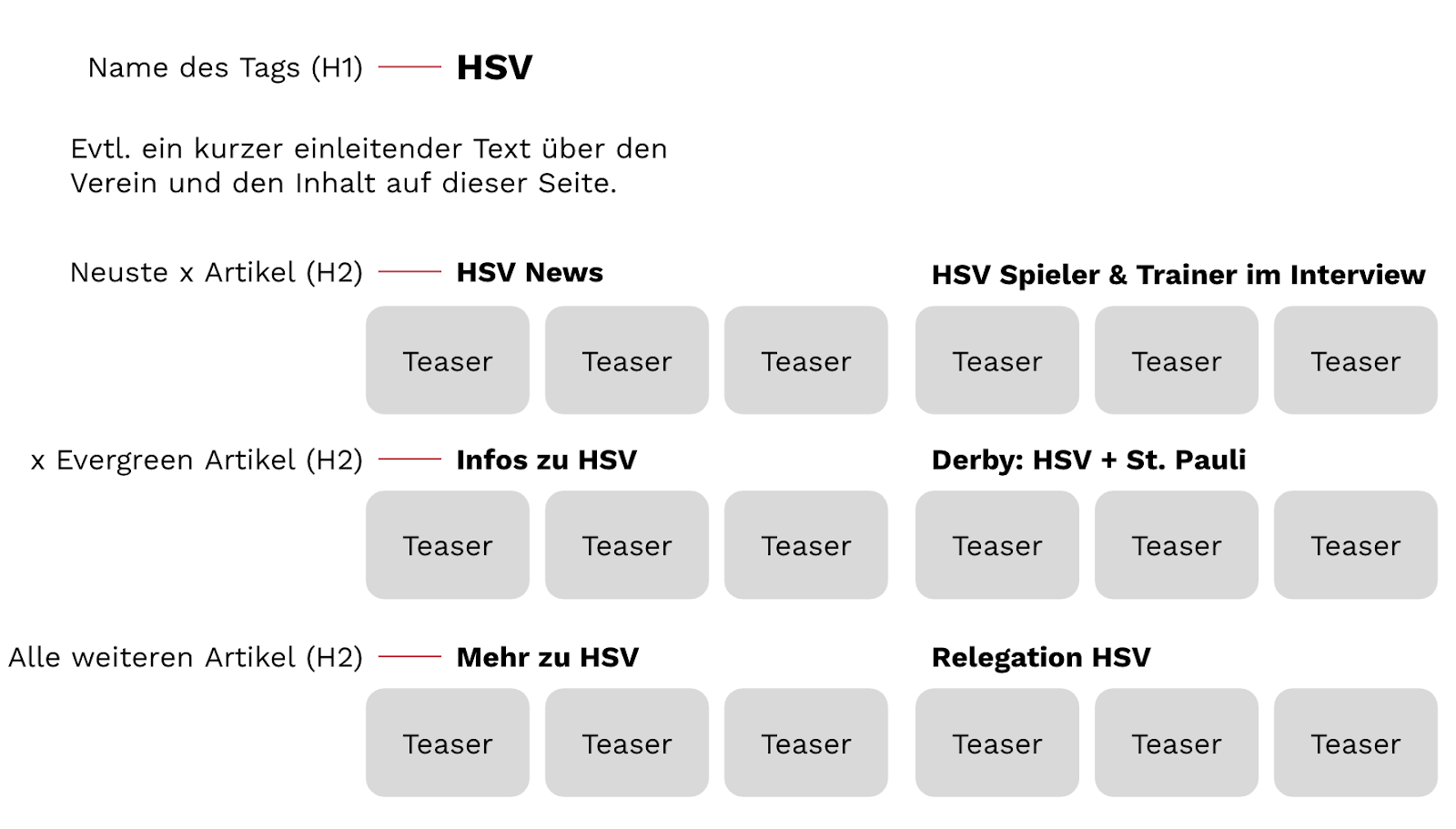
Bild: Veranschaulichung eines möglichen Aufbaus einer Tagseite, aufgeteilt in relevante Abschnitte rund um das Thema HSV. Weitere Abschnitte und Aufteilungen sind möglich, beispielsweise zu den einzelnen Spielern etc.
Ich empfehle Dir, zuerst an Deinen Artikeln zu hinterlegen, ob diese Evergreen-Artikel sind oder News. Denn Newsartikel verlieren relativ schnell an Relevanz, Evergreens sind hingegen zeitlos. Diese können dann einen speziellen Platz auf der Tagseite einnehmen und werden von den immer mehr einlaufenden Newsartikeln nicht auf die hinteren Plätze verdrängt. So wäre es jedoch der Fall, wenn die Artikel auf der Tagseite chronologisch aufgeführt werden. Und wir wissen ja, dass je weiter hinten ein Artikel verlinkt ist, desto weniger Relevanz hat dieser.
Weiterhin kannst Du die Artikel segmentieren nach der Art des Artikels, beispielsweise Meinungsartikel, Interview oder How-To-Anleitung.
Als nächsten Schritt kannst Du auf den Themenseiten Module für die interne Verlinkung bauen, indem Du Tags zusammenfasst, aber auch Themen gesondert darstellen. Beispielsweise:
"Angela Merkel" + "Bundeskanzlerin" oder "HSV" + "Derby" + "St.Pauli" und immer wieder auch "HSV" + "Relegation", oder auch "Heidi Klum" + "Bill Kaulitz" und "Heidi Klum" + "Germanys Next Topmodel".
Auch andere Kombinationen sind möglich und können sinnvoll sein, beispielsweise ein Thema + das Tag "Video" oder "Bildergalerie".
Aus diesen Kombinationen können aber auch eigene Themenseiten entstehen, wenn deutlich wird, dass es genügend Input und Nachfrage zu den vereinten Themen gibt. So werden aus Deinen Themenseiten dann zum Beispiel Hubseiten.
Hast Du die Tagseiten gepflegt und optimiert und es liegt Suchvolumen vor (das solltest Du im Idealfall vor der Optimierung prüfen 😉), kommen wir zum spannenden Thema Indexierung: Erst wenn die Seiten gepflegt, angereichert und optimiert sind, sollten diese zur Indexierung freigegeben werden.
Sind die Seiten indexiert, kannst Du sie zur Optimierung der internen Verlinkung nutzen. Vorher sind die Tagseiten lediglich dazu da, Deine Nutzer zu führen, aber nicht, um Pagerank sinnvoll zu verteilen.
|
|
| Wird GA4 noch ein nutzbares Webanalyse-Tool? |
Bei GA4 tut sich nach wie vor einiges. Mit der Einführung des Google Tag Templates für den GTM geht die Umstellung von GA4 Tag auf Google Tag voran.
GA4 Settings Variable
Damit es auch Gründe für eine Umstellung gibt, bekommen wir mit der GA4 Settings Variable ein (trotz Configuration-Tag Schnipp-Schnapps) schmerzlich vermisstes Universal-Analytics-Feature zurück. Ein Grund dafür, ein laufendes Setup anzufassen, ist das freilich nicht. Aber beim nächsten GA4-Setup freue ich mich auf den Einsatz einer zentralen Settings-Variablen.
Data Redaction Feature
Außerdem haben sich die Entwickler von Simo Ahavas guten alten PII Remover für UA inspirieren lassen: GA4 hat nun ein Data Redaction Feature. Wenn Dir die Google-Doku zu trocken ist, hat das Search Engine Journal das Feature für Dich nochmal zusammengefasst.
Damit können Emailadressen und definierte Query Parameter aus Analytics Hits entfernt werden. So kannst Du verhindern, dass versehentlich personenbezogene Daten aus URLs in Deinem GA4 landen. Zudem lassen sich auch unliebsame Parameter, Unique IDs oder Ähnliches sperren, damit sich die "Page & Query" Dimensionen weniger aufblähen.
Aber Achtung: Wenn Du in Deinen URLs irgendwo Elemente hast, die ein @ enthalten und daher einer Emailadresse ähneln, könnte das auch geblockt werden. Leider hat Google nicht veröffentlicht, nach welchem Muster sie genau blocken, sodass man es nur empirisch testen kann.
Ein nettes Feature. Und es ist sogar clientseitig umgesetzt, sodass Google die zensierten Informationen tatsächlich nicht zu Gesicht bekommt. DSGVO-, E-Privacy-konform oder gar ohne Consent einsetzbar wird GA4 damit noch lange nicht, aber es geht in die richtige Richtung.
Kein großer Sprung, grundlegende Features fehlen weiter
Das sind leider alles nur kleine Schritte. Der große Sprung vom Webanalyse-Tool in andauernder Beta-Phase zum benutzbaren Produkt lässt noch auf sich warten.
Charles Farina hat eines der größten Probleme von GA4 auf den Punkt gebracht. Es gibt aktuell keine Möglichkeit, Sessions, die von einer bestimmten Quelle kommen, zu identifizieren. Es gibt diverse Dimensionen zu Attribution, aber wie viele Einstiege von einer bestimmten Kampagne kamen, ist, dank der neuen Session-Logik, mit Bordmitteln nicht ermittelbar.
Du denkst, das sei quasi der grundlegende Zweck einer Webanalyse? Ich stimme Dir zu. Irgendwer bei GA4 scheinbar nicht...
Workarounds gegen den Geist der Dokumentation
Glücklicherweise kann man die Conversion-Attribution in der explorativen Datenanalyse zweckentfremden, um Zahlen dazu zu erhalten. Allerdings ist das von der Dokumentation explizit nicht empfohlen, sodass man sich darauf nicht wirklich verlassen kann.
Kleinigkeiten wie uneinheitliche Dimensionsverfügbarkeiten zwischen verschiedenen Bereichen des Frontends, der explorativen Datenanalyse, der API und Looker Studio sorgen dabei für zusätzliche Frustration.
Google hat sich im Vergleich zu Universal Analytics von der Zielgruppe der Gelegenheits-Web-Analysten klar abgewendet. GA4 gaukelt zwar einfache Analysen vor, braucht aber im Detail viel früher konkrete Fachexpertise. Und viele Standard-Fragestellungen, die in Universal Analytics drei Klicks entfernt waren, brauchen jetzt Rohdatenzugriff via BigQuery-Export.
In Zeiten, in denen Datenschutz weltweit immer stärker durchgesetzt wird, rechnet sich der Business Case wohl nicht mehr, eine Webanalyse für lau anzubieten.
Ein Umstieg auf Alternativen wie etracker, Matomo oder vielleicht sogar Microsoft Clarity ist vielleicht eine gute Überlegung.
Warum Dein Datenschutzbeauftragter aber vermutlich einen Herzinfarkt bekommt, wenn er die Session Aufzeichnungen von Clarity sieht, erzähl ich Dir beim nächsten Mal.
|
|
| Cooles Caching |
"Your Cache Headers Could Probably be More Aggressive" findet Alex MacArthur und beschreibt in seinem Artikel sehr gut verständlich und auf den Punkt, wie man damit aus seiner Sicht am besten umgeht:
Ein Default-Setting, dass für möglichst viele verschiedene Nutzerinnen passt, ist sinnvoll: Cache-Control header = public, max-age=0, must-revalidate zusammen mit einem Etag Es gibt jedoch Ressourcen, bei denen sich extrem selten etwas ändert, weswegen man sie durchaus großzügig cachen kann sollte: Cache-Control header = public, max-age=31560000, immutable Falls sich doch was tut, gibt es Wege, die neueste Version umgehend an den Browser zu bringen, egal was im Caching steht: Fingerprinting for the win!
Wie? Was? Wenn Dir das ein wenig zu schnell ging, hier nochmal etwas ausführlicher:
Durchgreifender Default
Mit public, max-age=0, must-revalidate teilen wir mit, dass die Ressource zwar gecached werden kann. Direkt beim nächsten Aufruf wird jedoch anhand des Etags geprüft, ob es eine neue Version gibt. Falls ja, wird diese dann auch heruntergeladen. Wenn es keine neue Version gibt, bekommen wir einen Status Code 304 Not Modified zurück und der Browser nimmt die Version, die er bereits im Cache hat. Das ist, so Alex, als Default-Setting smart und sinnvoll.
Es gibt Dinge, die sich nie (oder nur sehr selten) ändern: CSS, Fonts, Bilder, JavaSscript. Wenn diese dann mit extrem hoher Wahrscheinlichkeit einen Status Code 304 Not Modified liefern, ist es eigentlich unnötig, diesen Dialog jedes Mal zu durchlaufen. Vorhang auf für public, max-age=31560000, immutable. Nun kann die betreffende Ressource gecached werden und ist quasi ein Jahr haltbar. Dabei bekommt der Browser sogar die ganz klare Vorgabe, unter keinen Umständen nachzufragen, ob es eine neuere Version gibt.
"immutable - the browser is explicitly instructed to NOT reach out to origin/CDN just to check if something newer is available (no more revalidation requests)
Wenn man die Seite also einmal aufgerufen und die Assets geladen hat, kommen sie ab dann immer direkt aus dem Cache. Erst nach Ablauf eines Jahres schaut der Browser wieder, ob es eine neuere Version gibt.
Fingerprinting für Frische
Zum Glück muss man sich keine Sorgen machen, wenn sich doch mal etwas ändert, obwohl man einer Ressource als Caching-Zeitraum ein Jahr mitgegeben hat. Fingerprinting (mancherorts auch "Cache Busting") heißt der Trick. Denn wenn ein neues Asset unter einer neuen URL liegt, dann holt sich der Browser das auf jeden Fall einmal her. Egal, wie lange die vorherige Version der betreffenden Ressource noch gültig gewesen wäre.
Dabei sollte man unbedingt auch den Umkehrschluss ziehen: Ressourcen, deren URL sich in der Regel nicht ändern, sollten vermutlich nicht ewig gecached werden, insbesondere wenn häufigere Änderungen üblich oder zu erwarten sind. Zum Beispiel das HTML der Startseite. Denn diese URL bleibt dauerhaft bestehen und hat sozusagen eine größere "Haltbarkeit" als beispielsweise die leicht veränderbaren URLs von CSS- oder JS-Dateien. In dem Fall also nicht auf Fingerprinting setzen und eher vorsichtig sein beim Caching!
Alex hält in seinem Artikel dann noch ein paar praktische Tipps bereit, wie Du das konkret umsetzen kannst.
Mir hat der Beitrag gut gefallen. Denn Caching ist ein super Hebel, um an den Ladezeit zu schrauben. Trotzdem sieht man da immer wieder große Fragezeichen vor den Augen, wenn es darum geht, was man denn jetzt am besten wie cached. Sicherlich gibt es Fälle, in denen es kompliziert ist. Aber grundsätzlich kommt man mit dem vorgestellten Ansatz schon ganz weit. Also kannst Du am besten gleich mal nachschauen, wie das denn aktuell auf Deiner Webseite gelöst ist...
|
|
| Medienkonglomerate oder Indie-Publisher: Wer dominiert die SERPs? |
Glen Allsopp hat sich mit seinen umfangreichen SEO-Analysen auf detailed.com einen Namen gemacht. Mit seinem neuesten Brett "The State of Content SERPs: A 250,000 Keyword Analysis" ist er dem wieder gerecht geworden.
Die Frage
Erreichen Websites großer Medienunternehmen mehr Top-Rankings als unabhängige Publisher?
Die Datenbasis
250.000 Keywords Englisch Non-Brand Mit Qualifizierern, die redaktionelle Inhalte (statt Shops oder SaaS-Ergebnisse) als Antwort hervorrufen sollten: "Where do", "How should", "Who is", "Review", "How much", "The best", "When is", "Recommended" oder "Where was" Mindestens 3 Terme ø monatliches Suchvolumen von 500-5.000 in den USA
Eigentlich sollten die Treffer der ersten Google-Seite aller 250.000 Abfragen kategorisiert werden. Das wären 173.678 Domains und Subdomains gewesen. Glen hat sich deshalb entschieden, die 5.000 Domains anzuschauen, die am häufigsten vorkommen. Es blieben dann 186.444 Keywords im Datenset übrig, bei denen eine der Top-5.000-Domains auf Platz 1 rankte.
Die Antwort
Von den 186.444 Google-Suchergebnissen, bei denen eine redaktionelle Domain den ersten Platz belegte, entfielen 86,1% der ersten Platzierungen auf Seiten von großen Medienunternehmen. Indie-Publisher erreichten nur 13,9%.
Die Top-20 der redaktionellen Seiten waren komplett im Besitz großer Medienunternehmen wie Red Ventures, New York Times Company, Dotdash Meredith, Walt Disney Company, Hearst, News Corp oder Axel Springer.
Erst auf Platz 49 der redaktionellen Treffer (insgesamt Platz 75) tauchte die erste unabhängige Domain auf: mindbodygreen.com.
Die Ursachen
Aber Moment, könnte das daran liegen, dass große Medienmarken einfach insgesamt viel häufiger im Datenset der 5.000 Domains vorkamen?
Nösn, 54,1%, also mehr als die Hälfte der 5.000 Domains, waren unabhängige Webseiten und trotzdem belegten sie nur in 13,9% der Fälle das Top-Ranking. Je kleiner das Datenset, desto mehr verschiebt sich das Gewicht zugunsten der großen Medienkonglomerate. Bei den Top-500 Seiten waren es nur noch 49 Unabhängige, aber 287 Seiten großer Medienmarken.
Glen hat einen anderen Zusammenhang festgestellt:
Mehr Content, mehr Rankings.
Im Schnitt hatten die ersten 20 Domains, die einer großen Medienmarke angehören, knapp 550.000 URLs laut Ahrefs. Die Kleinste hatte knapp 13.000 URLs.
Bei den Indie Sites waren es im Schnitt 67.000 URLs. Die Kleinste rankte mit 530 URLs laut Ahrefs.
Erkenntnisse am Rande
(Aussortierte) Domains, deren Startseite Software, Downloads oder einen anderen Service anboten, belegten sogar mehr Position-1-Rankings als die Indie-Publisher. Viele Indie-Publisher haben trotzdem ein mehrköpfiges Autorenteam. Viele "Offline-Marken" wie L'Oréal und Sanpellegrino haben sich mit redaktionellen Angeboten in bestimmten Nischen festgesetzt. Dasselbe gilt für Domains, die von Regierungsbehörden betrieben werden. Sowohl große Medienmarken als auch unabhängige Publisher beziehen ihren Traffic zu zwei Dritteln aus der organischen Suche.
Was lernen wir daraus?
Dass große Publishing-Marken im Jahr 2023 die redaktionellen SERPs dominieren, überrascht nicht. Sie haben die Ressourcen und setzen sie mittlerweile gezielt ein, um Inhalte zu veröffentlichen, die in der organischen Suche funktionieren.
Nutzerverhalten und Google belohnen den Aufbau von Marken und somit die Investition in E-E-A-T. Das Qualitätsversprechen von Brands und der Wiedererkennungseffekt eines bekannten Namens geben Orientierung, so dass Menschen gerne auf die Angebote von Marken klicken. Deshalb lohnt es sich auch für Google, diese Ergebnisse hoch zu listen.
Aber im Longtail, in der Nische, haben die unabhängigen Publisher weiterhin die Chance, sich selbst einen Namen zu machen. Die großen Konglomerate zielen auf die breiten Themen mit hohem Suchvolumen ab und überlassen (noch) Liebhaber-Themen für die kleinen Sites übrig, die sich einem spitzen Thema voll und ganz verschreiben.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





