| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #136 |

|
| 💪 Ärmel hochkrempeln zum Jahresendspurt |
Die Erfahrung zeigt: Das Jahr geht schneller rum als Du denkst.
Es sind nur noch 12 Monate bis 2024, und auf Deiner To-do-Liste stehen jetzt noch die ganzen Kleinigkeiten, für die 2022 dann plötzlich doch keine Zeit mehr wahr. Also lass Dich nicht von diesem Januar Gefühl einlullen, sondern zieh die guten Vorsätze durch und hau die Hacken in den Teer.
Wir haben auch schon losgelegt und Dir folgende Neujahrsgrüße mitgebracht (einen Teil haben wir heimlich letztes Jahr schon geschrieben, aber psst 🤫):
Johan hat weiter mit Chat GPT gespielt und selbstverständlich Verbesserungsvorschläge für RegEx Andreas bringt Ideen zur Subdomain-Nutzung mit Hannah erklärt Dir was zum Spam-Update Jolle nimmt für Dich das nofollow-Attribut unter die Lupe - Behrend hat brisante Bingbot-News für Dich
In diesem Sinne: Wir wünschen Dir ein frohes, produktives und hoffentlich friedliches Neues Jahr,
Deine Wingmenschen
|
|
| ChatGPT = RegExemplarischer Quatsch |
Hach. Auch nach der ersten Euphorie ist ChatGPT ein tolles Spielzeug. Weniger um nutzbaren Content zu generieren, sondern eher, um erste Ideen zu sammeln und den Kopf freizubekommen.
Lily Ray hat ChatGPT genauso benutzt: „Schreib mir eine RegEx für die Search Console, mit der ich alle URLs filtern kann, die im Folder /news/ liegen und "2022" enthalten."
Das hat gar nicht sooo schlecht funktioniert. ChatGPT hat mit einer RegEx und einer Erläuterung geantwortet:
✅Es ist eine funktionierende RegEx
✅Es gibt eine Erläuterung zu den einzelnen Bestandteilen
✅Es gibt 3 Testfälle
Aber, wenn Du Dir die RegEx ansiehst, dann fällt Dir sicher auch direkt auf, dass das nicht so richtig funktioniert:
^https?:\/\/(www\.)?[^\/]*\/news\/[^\/]*2022[^\/]*
Denn die RegEx funktioniert zwar, aber von den drei Testfällen, die die RegEx angeblich lösen soll, funktioniert einer nicht:
http://www.example.com/news/category/article-2022.html
Aber warum?
Das http ist kein Problem. Aber der Folder /category/ ist nicht vorgesehen von der RegEx. Die sucht nämlich direkt unterhalb von /news/ nach 2022 (weil mit [^\/]* nicht nach dem Vorkommen aller Zeichen außer / Unterordner und deren Ausschluss, sondern nur nach Vorkommen von 2022 direkt nach /news/ gesucht wird).
Wir können die RegEx deutlich einfacher schreiben:
1) Wir kennen Protokoll und Subdomain, also fangen wir damit an, dass wir das eindeutig machen und am Beginn der URL (^) danach suchen:
^https://www.example.com
2) Dann suchen wir nach „irgendwas" gefolgt vom Ordner /news/:
.*/news/
3) Danach darf wieder irgendwas kommen, gefolgt von 2022:
.*2022
Die vollständige RegEx sieht also vereinfacht (und ohne das für die GSC unnötige escapen der / ganz einfach aus:
^https://www.example.com.*/news/.*2022
Und das ist doch so einfach, dass wir das auch ohne ChatGPT auf 90% der Alltags-Use-Cases adaptieren können.
Unser Learning: ChatGPT prüft seine Aussagen nicht auf Korrektheit, sondern baut nur etwas, das statistisch nach einer passenden Antwort aussieht. Selbst wenn uns ChatGPT Testfälle zur Verfügung stellt, müssen wir schauen, ob das auch wirklich funktioniert. Wenn wir das nicht selbst sehen, dann gibt es zum Glück großartige Testing-Tools wie regex101.com, die uns dabei helfen:

|
|
| Frohe neue Hostnames |
In meinem kleinen Artikel möchte ich Dich heute einmal in meine Gedanken mitnehmen auf eine lustige Reise durch die Welt der Subdomains.
Es gibt viele Gründe eine Subdomain anzulegen. Seien sie gerechtfertigt oder auch nicht, werden sie für Blogs, Ticketsysteme, ein Extranet oder auch für CDNs (Content Delivery Network) gerne genutzt.
Wir leben in Zeiten, in denen Dein Server eigentlich längst mit HTTP2 laufen sollte und es für HTTP1.1 nur wenige Ausreden von Deinem Systemadministrator geben kann, die ich noch gelten lassen würde. Subdomains sind für CDNs in der Regel kontraproduktiv, da der erneute Verbindungsaufbau zum neuen Server den Ladevorgang eher ausbremst, anstatt hilfreich zu sein.
Dazu kommen weitere Punkte, die Du bei Subdomains beachten solltest. Zum Beispiel die Einrichtung von so genannten Wildcard-Subdomains (*.meinedomain.tld). Diese Art der Subdomains führt dazu, dass egal, was der Benutzer vor .meinedomain.tld eingibt, zu einer bestimmten IP-Adresse aufgelöst wird. Diese Konfiguration sehe ich eher als problematisch an, denn hier müssen wir Folgendes beachten:
Wir müssen die Subdomains im Blick behalten, für alle benötigten Subdomains muss ein virtueller Server die richtige Website ausliefern und für jegliche andere (nicht gewollten Subdomains) muss eine entsprechende 301-Weiterleitung eingerichtet sein, um unerwünschte Nebeneffekte zu vermeiden.
Denken wir z.B. einmal daran, dass eine solche Weiterleitung fehlt und alle nicht benötigten Subdomains auf unserem eigentlichen Onlineshop auflösen. Ich kann unseren Onlineshop also unter meinedomain.tld und auch www.meinedomain.tld genauso wie test123.meinedomain.tld aufrufen. In jedem Fall wird der Inhalt mit dem Statuscode 200 (OK) ausgeliefert. Geschieht dies, so erzeugen wir Potenzial für Duplicate Content und Dir nicht so positiv zugewandte Personen könnten versuchen, die Inhalte unter einer Subdomain wie mist-kauft-man-bei.meinedomain.tld oder anderen kreativen Subdomains zum Ranken zu bekommen, in dem sie einfach Links auf solche Inhalte setzen und Google verwirren.
Um der Wildcard-Problematik zu entkommen, empfehle ich Dir stattdessen, mit den Domain-Records im DNS eine Art Inventar der Subdomains zu haben. Neue Subdomains werden klassisch in der IT "beantragt" und nur solche Subdomains werden dann auch zu einer IP-Adresse aufgelöst. Wir SEOs können so nicht mehr von Subdomains überrascht werden und kennen das Portfolio unserer Domain.
Also, alles paletti sollte man annehmen, oder? Nicht ganz, denn auch in diesem Fall müssen wir die Subdomains im Blick behalten. Subdomains, für die es nach einem Relaunch keine Inhalte mehr gibt und auch kein Webserver mehr antwortet, darf es so nicht geben. In so einem Fall sollte eine Subdomain so konfiguriert werden, dass es für wichtige URLs noch sinnvolle 301-Weiterleitungen gibt oder die Subdomain gelöscht wird.
In meinem Beispiel wurde über 4. Mio. Mal in einem Zeitraum von 3 Monaten versucht, die robots.txt einer Subdomain abzurufen, was jedoch nicht gelang, da die Subdomain auf eine IP-Adresse zeigte, auf dessen Server kein Webserver mehr ausgeführt wurde. Kurz vor Weihnachten wurde die Subdomain gelöscht, da es auf dieser keine wichtigen URLs mehr gab, die weitergeleitet werden konnten.
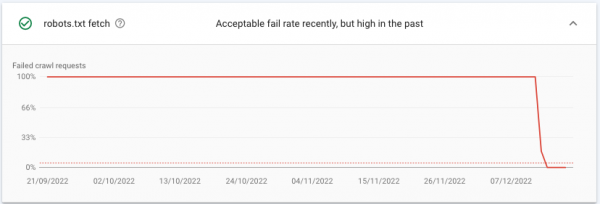
Wie wir sehen, bestanden fast 100% der Anfragen von Google darin, die robots.txt- Datei abzurufen.

Und über den Tag verteilt wurde zwischen 32.000 und 72.000 Mal versucht, die robots.txt abzurufen.
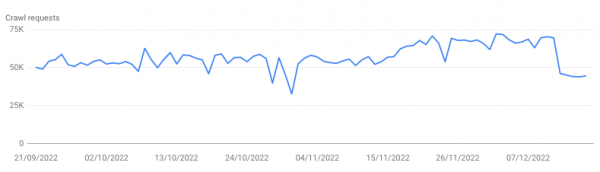
Dies summiert sich in drei Monaten locker auf über 4 Mio. Requests, die Google nicht verarbeiten kann, da der Server nicht mehr antwortet. All dies sind unnötige Crawl Requests, die dazu führen, dass unnötig Energie verbraucht wird, aber auch dazu führen kann, dass andere – wichtigere – Dinge nicht gecrawlt werden.
Fazit
Subdomains machen von Fall zu Fall noch Sinn, gerade wenn CMS oder CMS vom Shop-System voneinander getrennt gehostet werden sollen. Als alter Admin rate ich meist sogar dazu, da es gleich sehr viele Kompatibilitätsprobleme und Wechselwirkungen zwischen den Systemen erst gar nicht entstehen lässt. Denn sehr viele Probleme mit Software- und Systembibliotheken treten dann auf, wenn CMS A ein Update erfordert, Shop-System B aber noch nicht mit den neuesten Bibliotheken umgehen kann. Daher gilt auch hier „Es kommt drauf an" und eine pauschale Aussage kann es nicht geben. Nur der Hinweis, dass wir SEOs bei Subdomains lieber ein oder zweimal mehr hinschauen sollten.
|
|
| Happy new Spambrain |
Am 14. Dezember hat Google ein Link Spam Update ausgerollt – dieses soll den Impact von Linkbuilding relativieren. Google soll in der Lage sein, gekaufte Links und Seiten, die nur für Linkbuilding erstellt sind, zu erkennen. Hierfür nutzt Google SpamBrain, das AI-System, das seit 2018 Herzstück von Googles Spamerkennung ist. Google kündigte an, dass dies zu Rankingveränderungen führen kann, da die Auswirkungen der Links neutralisiert werden. Bisher konnte ich bei meinen Kunden nichts erkennen – aber wir Wingmen sind ja auch seit jeher absolut gegen unnatürliches Linkbuilding.
Im Zuge des Updates möchte ich Dir noch einmal die von Google empfohlenen Vorgehensweisen, Links zu kennzeichnen nahelegen. Google bezieht nicht nur die auf Deine Seite zeigenden Links bei dem Update mit ein, sondern auch, wie Du Links markierst, die nach außen zeigen.
Affiliate-Links markierst Du mit einem rel="sponsored" Tag.
Links in Gastbeiträgen markierst Du mit rel="nofollow". Dazu erfährst Du unten mehr im Artikel von Jolle.
Was kannst Du also tun, wenn zu viele künstliche Links auf Deine Seite zeigen? Mit einer Disavow-Liste in der GSC kannst Du Google mitteilen, dass Du nicht möchtest, dass Links von den Seiten für Dich zählen. Das hilft Dir allerdings nicht, wenn Google das vor Dir entdeckt hat und die Links eh schon durch den Algorithmus neutralisiert wurden. John Mueller hat auf Mastodon gesagt "If you've built the foundation of your site on bad links for a longer period of time, that will have a lasting effect even if you suddenly fix some things." und vergleicht eine Linkbuilding-Strategie mit einem Kartenhaus – wenn die Karten entfernt werden, hat das Haus kein stabiles Fundament mehr. Möchtest Du eine langfristige Strategie für Deine Seite, dann setz bitte nicht auf gekaufte Links, PBNs und andere unnatürliche Linkbuilding-Maßnahmen.
Das Update war für zwei Wochen angekündigt, dauert nun aber ein wenig länger, da aufgrund der Feiertage mehr Zeit benötigt wird.
|
|
| Falls Du dem Nofollow-Attribut noch nicht ganz folgen kannst… |
... hat Dir Mark Williams-Cook einen kleinen Guide bei Wix zusammengeschrieben. Mark ist der Mann hinter dem alsoasked.com-Tool und womöglich hat er es für seinen Blogpost eingesetzt:
Das Nofollow-Attribut für Links gibt es schon seit 2005 und wurde eingeführt, um Linkspam zu bekämpfen. Gerade die Kommentarspalten von Blogs sind damals regelmäßig mit Links übergelaufen, mit denen Spammer Traffic auf ihre Seiten zu holen versuchten. Die Blogbetreiber wollten aber keinesfalls für diese Links von ungewisser Qualität gerade stehen und konnten per rel="nofollow"-Direktive Suchmaschinen signalisieren, dass sie dem Link nicht zu folgen brauchen.
Da Linkkauf von Google aus verboten, der Linktausch zwischen Partnern, Sponsoren & Co. jedoch durchaus üblich ist im Netz, bietet das Attribut die Möglichkeit, mit offenen Karten zu spielen, um nicht als Linkspammer missverstanden zu werden. Das empfiehlt Google jedenfalls in seiner Spam-Policy.
2019 kamen die Präzisierungen "ugc" und "sponsored" dazu. Links zu Partner und Sponsoren können seither das "sponsored"-Attribut bekommen. User Generated Content wie Kommentare und Bewertungen qualifizieren sich für das "ugc"-Attribut. Es besteht aber keinerlei Notwendigkeit "ugc" und "sponsored" statt "nofollow" zu verwenden.
Indexierungs-Hinweise trotz "nofollow"
Die bedeutende Änderung von 2019 war aber folgende: Google behält es sich vor, "nofollow"-Links als Hinweis für die Entscheidung zu verwenden, welche URLs im Suchindex auftauchen und welche nicht. Auch wenn Seitenbetreiber:innen die Links nicht direkt empfehlen wollen.
"Links contain valuable information that can help us improve search, such as how the words within links describe content they point at. Looking at all the links we encounter can also help us better understand unnatural linking patterns. By shifting to a hint model, we no longer lose this important information, while still allowing site owners to indicate that some links shouldn't be given the weight of a first-party endorsement."
Daraus folgt auch, dass Google den Links nach Gutdünken durchaus folgt, um neue Inhalte im Internet zu entdecken und anhand der Linktexte zu ermitteln, worum es auf den Seiten geht.
Sind "nofollow"-Links ein Problem?
Mark weist darauf hin, dass eine Mischung aus Links ohne besonderes Attribut einerseits und "nofollow"-Links andererseits die Regel und völlig natürlich ist. Du solltest also nicht extra versuchen, "nofollow"-Links auf Deiner Seite zu entfernen oder Links dieser Art auf Deine Seite zu vermeiden.
Und auch wenn sich Linkbuilder regelmäßig ärgern, wenn sie einen Link von einer anderen Publikation ergattern konnten, dieser aber auf "nofollow" gesetzt ist: Traffic, der über diesen Link auf Deine Seite kommt, ist auch ohne die Linksignale nützlich. Echter Traffic ist echter Traffic, auch wenn er aus irgendeiner Kommentarspalte eines Forums kommt.
Alle Links auf "noindex"-Seiten werden früher oder später als "nofollow" interpretiert
Theoretisch ist es möglich, das Meta-Tag im Header einer Seite auf "noindex, follow" zu setzen, um zu signalisieren: Die URL soll nicht in den Suchergebnissen auftauchen, die verlinkten Seiten können aber gecrawlt und indexiert werden.
In der Praxis interpretiert Google das Meta-Tag aber über kurz oder lang so, als wäre es auf "noindex, nofollow" gesetzt. Inwiefern Google den Links dann doch noch nachgeht und ihnen Bedeutung beimisst, entscheidet wiederum Google selbst.
"nofollow"-Links auf interne Seiten?
Mark sieht darin keine Nachteile:
"There is no specified downside to using nofollow on internal links to give Google further hints about which pages may not be important."
Da bin ich anderer Meinung: Wenn ich bestimmte Seiten aus der Suche ausschließen oder mein Crawlbudget sinnvoll einsetzen möchte, dann sind robots.txt, noindex per Meta- oder X-Robots-Tag die besseren Werkzeuge. Alles andere lenkt vom eigentlichen Hebel ab.
Oder wie siehst Du das? Ich freue mich über Dein Feedback.
|
|
| Neues Jahr, neuer Bingbot User Agent |
Genau genommen hat Microsoft die User Agent Änderung für den Bingbot schon vor Jahren angekündigt. Aber was soll ich machen, es ist der erste Newsletter des Jahres, da ist ein Neujahrsbezug in der Überschrift unabdingbar.
Und immerhin hat Microsoft, dank einer sehr konzernigen Umsetzungsgeschwindigkeit, jetzt auch ein Neujahrsthema für 2023 draus gemacht. Frei nach dem Motto „was lange währt, wird endlich gut" hat man im Juli 2022 tatsächlich damit begonnen, den neuen User Agent ausrollen. Ähnlich vorsichtig wie Google beim Evergreen Googlebot wurde auch das Crawling des Evergreen Bingbot vorsichtig und Stück für Stück hochgefahren.
Wie Barry Schwartz kurz vor Weihnachten berichtete, hatte der Evergreen Bingbot im Herbst 50% des Crawlings übernommen. Damit das Bingbot-Crawling-Team beruhigt seine Feiertage genießen konnte, hat man dann die endgültige Umstellung ins neue Jahr geschoben. Lob und Anerkennung an die Verantwortlichen, dem Crawling-Team keinen Go-live vor Weihnachten und Neujahr aufzunötigen.
Nun, wenn alle so langsam das Immergrün wieder aus dem Wohnzimmer verbannen und die Feiertagssaison sich dem Ende neigt, kann es aber losgehen. Wir sind gespannt.
Und was bedeutet das für Dich?
Hast Du Bingbot auch von irgendwelchen Paywalls ausgeschlossen oder so? Dann aber fix prüfen, ob das für den neuen Bingbot noch so klappt, wie gewohnt. Wie Bing mit Paywall-Inhalten umgeht, hat sich Anita übrigens auch einmal genauer angeschaut. Und falls Du Publisher bist, solltest Du Dir auch unbedingt mal die Bing News PubHub Integration anschauen, die Dir Nora vorgestellt hat.
Ein Blick in Deine Bing Webmaster Tools kann nicht schaden, denn das tut man ohnehin zu selten. Das kann natürlich aber nachträglich noch zu Deinen Vorsätzen für 2023: Bing Webmaster Tools nicht immer vergessen.
Es mag nicht so viel Traffic über Bing kommen, aber die Bing Webmaster Tools können Dir Fehler aufzeigen, die Dir in der GSC vielleicht nicht auffallen.
Anita hat in ihrem Artikel „Spotlight auf die BWMT" schon einige Vorteile der Bing Webmaster Tools für Dich zusammengefasst. Falls Du aber noch mehr Gründe brauchst, Dir die Bing Webmaster Tools einmal anzuschauen, dann hat Hannah Bing und Google für Dich miteinander verglichen.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|




