| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #177 |

|
| 🍂 SEO-ktober: Mögen die Blätter fallen, Deine Rankings aber nicht |
Der Oktober ist in vollem Gange. Die Blätter färben sich und strahlen in den buntesten Farben. Die Tage werden kürzer, die Nächte länger und dunkler und inzwischen haben sogar die Temperaturen langsam begriffen, dass der Sommer vorbei ist.
Damit Du in dieser kühlen Jahreszeit genug Lesestoff hast, präsentieren wir Dir natürlich auch diese Woche wieder die frischesten und heißesten Themen aus dem SEO-Ofen.
Also hol dir eine Tasse Tee, wickel dich in deine Kuscheldecke und dann wirf einen Blick auf unsere fünf Artikel. Diesmal mit von der Partie sind:
Philipp, der von der bunten Vielfalt der SGE (und einem kochenden Wasserschwein) begeistert ist Hannah, die von ihren goldenen Learnings und Einblicken der diesjährigen NESS berichtet Jolle, der beim Blick in die GSC gelegentlich fast die Glotzebömmelchen aus dem Antlitz gleiten Johan, der Dir unter anderem verrät, was Bots und der Flugverkehr gemeinsam haben Nochmal Philipp, der sich die philosophische Frage "Sitemap oder nicht Sitemap" stellt
Wir hoffen, unser heutiger Newsletter wird Dich ebenso verzaubern wie die goldenen Oktober-Landschaft draußen vor Deinem Fenster. In diesem Sinne:
Viel Spaß beim Lesen!
Deine Wingmenschen
|
|
| Die SGE wird zum Schweizer Taschenmesser |
Am Donnerstag Abend unserer Zeit hat Google nochmal einen für die SGE rausgehauen. In Kurzform habe ich dazu etwas auf LinkedIn geschrieben, die längere Form bekommst Du jetzt hier serviert.
Bilder in der SGE generieren
ChatGPT hat ebenfalls letzte Woche eine Funktion zur Bildgenerierung mit DALL-E bekommen.
Kaum integriert, kündigt Google eine ähnliche Funktion an. Ähnlich wie bei Midjouney und anderen Tools gibt es vier Ergebnisse für Deinen Prompt:
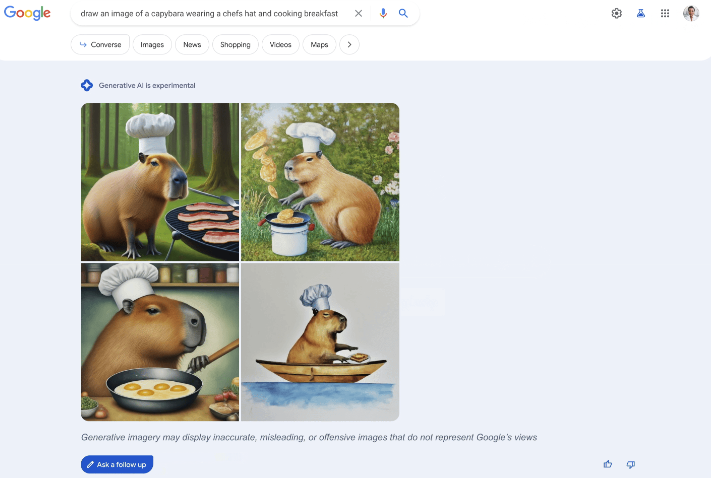
Ich habe direkt am Donnerstag und auch gestern Abend probiert, die Funktion zu nutzen. Sie war für mich (noch) nicht verfügbar. In der Ankündigung war der Wortlaut folgender:
"So beginning today, we're introducing the ability to create images with our generative AI-powered Search experience (SGE)."
"Today" ist bei Google also ein dehnbarer Begriff. Ausgerollt wird dieses Feature in den USA (als Teil des SGE Search Lab Testings) und nur für Nutzer:innen, die 18 Jahre oder älter sind.
Die Funktion soll auch in der Google Bilder-Suche verfügbar sein. In einer Kachel wird auf die neue Funktion hingewiesen:
Google schreibt, dass es Sicherheitsmechanismen geben wird, die die Erstellung von irreführenden und gefährlichen Inhalten vermeiden sollen. Bei vielen AI-Themen hat genau das hin und wieder nicht funktioniert und durch Tricks konnten derartige Sicherheitsmechanismen ausgehebelt werden. Beispielsweise wurden Hitler & Co. als großartige Anführer der Menschheit gelistet. Bei ChatGPT lassen sich auch Ergebnisse provozieren, wenn man nur weiß, wie der Prompt geformt sein muss. Mal schauen, ob das bei der Bildgenerierung in der SGE besser gelingt.
Was ich auch erwähnenswert finde:
"Every image will have metadata and embedded watermarking to add transparency that the images were created with AI."
Ich würde mir bei Texten und Bildern wünschen, dass bei problematischen Outputs (wie z. B. diesem "optimierten Bild") hergeleitet werden kann, wie dieser zustande kam. Und woher die Informationen stammen. Das wird es aber vermutlich nie geben. KI muss sich also in dem Fall vor keinem Gericht verantworten.
Ähnlich wie in den Suchergebnissen, bei denen man ein "About this result" abrufen kann, sollen auch die Bilder ein derartiges Feature erhalten. Damit kannst Du nachvollziehen, ob ein Bild oder ähnliche Varianten bereits auf einer anderen Website verwendet werden.
Was ich an dem Feature insgesamt richtig cool finde: Du kannst eins der vier erstellten Bilder auswählen und direkt in der SGE editieren durch weitere Prompts. 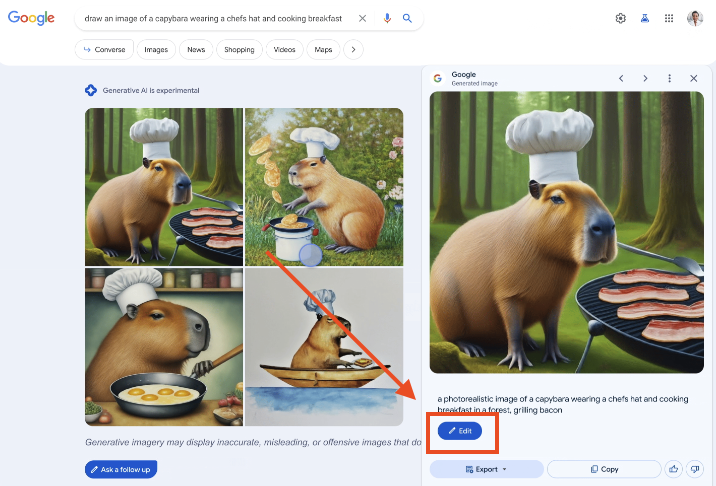
Edit Button im Suchergebnis der SGE
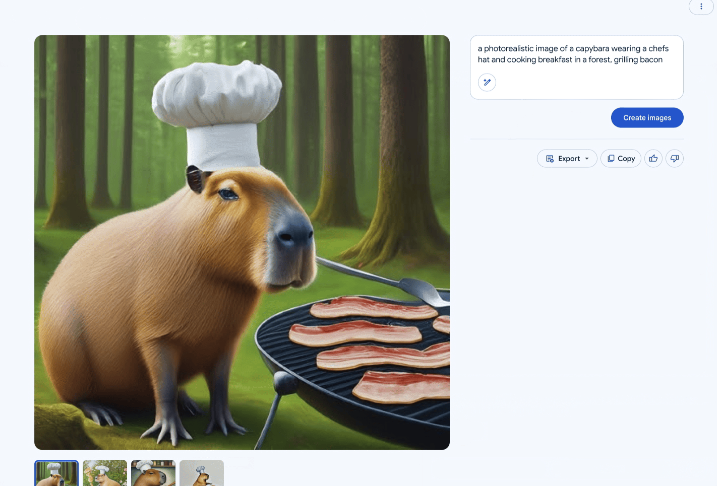
Edit Interface im Suchergebnis der SGE
Wenn Du möchtest, dass Menschen etwas tun, dann mache es ihnen so einfach wie möglich. Das ist eine der Hauptbotschaften, die ich aus dem Buch Nudge mitgenommen habe. Und alles in einer Applikation zu tun ist einfacher, als mehrere Applikationen gleichzeitig zu nutzen.
Drafts in der SGE schreiben
Die KI-gestützte Erstellung von Texten wird auch Teil der SGE. Du kannst in der SGE (ab sofort -- wie gesagt ein dehnbarer Begriff für Google 😅) Drafts anfertigen. Um für mehr Convenience zu sorgen, kannst Du die Texte direkt in Google Docs oder Gmail exportieren und damit weiterarbeiten.
Weitere News zur SGE
Google hat eine neue robots.txt Crawling-Direktive veröffentlicht mit dem Namen Google-Extended. Damit kann unter anderem ausgeschlossen werden, dass Inhalte Deiner Website in Bard auftauchen. Für die SGE funktioniert das aber nicht, wie Google sagt:
"SGE is a Search experiment so website administrators should continue to use the Googlebot user agent through robots.txt and the NOINDEX meta tag to manage their content in search results, including experiments like Search Generative Experience."
Ob sich daran etwas ändert, müssen wir abwarten. Über das Thema, ob Du z. B. OpenAI vom Crawling Deiner Seite ausschließen solltest, habe ich hier für Dich thematisiert.
Zu guter Letzt: Vergangene Woche hat Search Engine Land einen Artikel von mir veröffentlicht. Es ging darum, wie Du Dich erfolgreich auf die SGE vorbereiten kannst. Das Feedback bisher war großartig, daher spreche ich eine Leseempfehlung aus.
Du erfährst unter anderem
Ich empfehle auf jeden Fall, dass Du Dir die SGE mal anschaust und Dich mit ihr vertraut machst. Wie Du in die SGE kommst, hat Anita an dieser Stelle für Dich zusammen geschrieben.
Es bleibt spannend. Ich werde die Augen für Dich offenhalten und Dir berichten, sobald es zu wichtigen Veränderungen kommt.
|
|
| Kurzes Recap der NESS - News & Editorial SEO Summit |
Ich war dieses Jahr wieder virtuell auf der NESS. Barry Adams und John Shehata haben wieder tolle Speaker:innen zusammen getrommelt und ich konnte sehr viel mitnehmen. Ein bisschen was habe ich diese Woche für Dich mitgebracht.
AI nutzen, um besser zu werden in dem, was Du tust
Der unumgängliche Punkt AI war natürlich in fast jeder Session vertreten.
Es wurden mehrere Varianten gezeigt, wie Tools genutzt werden können, um die Ergebnisse zu verbessern. Die Speaker:innen haben dazu ermutigt, AI zu nutzen, um die eigene Arbeit besser zu machen.
Allerdings auch aufgezeigt, wie viel Arbeit es zunächst macht und betont, dass man dran bleiben soll. Kevin Indig hat beispielsweise über mehrere Tage an einem Prompt gearbeitet, bis er endlich zu einem zufriedenstellenden Ergebnis gekommen ist. Diesen Prompt kann er aber jetzt immer wieder abwandeln und nutzen, um dann wiederum schnell an Ergebnisse zu kommen, um seine Arbeit zu erleichtern. Barry nutzt AI beispielsweise, um sich inspirieren zu lassen und Lücken aufzudecken.
Beispielsweise zu neuen Themen, um einen leichteren Einstieg zu bekommen und dann selbst etwas schreiben zu können. So stellt er sicher, dass er Content-Lücken schließt. Ich habe mich dazu mit ein paar Teilnehmern ausgetauscht und die Möglichkeit, verschiedene Artikel von anderen Publishern mit dem eigenen Artikel zu vergleichen, findet großen Anklang. Die meisten nutzen hierfür ChatGPT. Hierbei nimmst du Deinen Artikel und lässt diesen mit besser rankenden Artikeln vergleichen und herausarbeiten, welche Aspekte Deinem Artikel fehlen und von den anderen beleuchtet werden, oder aber, dass die anderen mehr Bilder, Tabellen usw. haben. Diesen Promt können sie immer wieder nutzen, lediglich die URLs müssen angepasst werden.
LLMs ausschließen - ja oder nein?
Super spannend fand ich die Abschlussdiskussion am zweiten Tag, bei der noch einmal diskutiert wurde, ob News-Seiten LLMs per robots.txt ausschließen sollten oder nicht. Jes Scholz ist davon überzeugt, dass ein Ausschluss keinen positiven Effekt bringt und vertrat somit eine andere Meinung, als die anderen Gesprächsteilnehmer:innen. Sie sagt, auch wenn Du jetzt die Blockierung erstellst, wird Deine Brand trotzdem auftauchen und Deine bereits erstellten Inhalte genutzt werden. Sie sieht es als positiven Aspekt an, dass Nutzer:innen sich dadurch zu Deiner Seite navigieren können.
Jes geht sogar noch ein Stück weiter und sagt, sie würde, wenn sie die Zeit zurückdrehen könnte, die Machine Learning Systeme auch dann nicht aussperren. Der meiste Content von Publishern ist nämlich nicht unique und wenn Du die Bots aussperrst, dann bekommen sie die Nachrichten trotzdem - nur von einer anderen Quelle. Und dann hast Du überhaupt keine Chance mehr, als Quelle genannt zu werden.
Weiterhin sagt Jes, Journalismus solle immer eine persönliche Note enthalten und die Stories so geschrieben sein, dass Leser:innen diese auch trotz SGE und Chatbots lesen wollen. Weil sie Dich als Autor:in schätzen - Deine Meinung, Deinen Schreibstil etc. Wenn ein Artikel keinen Mehrwert bringt und easy von AI zusammengefasst, selbst geschrieben oder auch von anderen Publishern so rausgebracht werden kann, dann ist es auch egal, ob Maschinen Deinen Inhalt "klauen", denn dann stichst Du mit Deiner Arbeit ohnehin nicht heraus.
Kevin Indig sieht das komplett anders: Er ist der Meinung, dass Nutzer, wenn sie über SGE die Antwort auf ihre Frage erhalten haben, nicht auf die Quelle klicken. Die Antworten von ChatGPT sind noch nicht perfekt und es kommt sehr auf die Qualität der Fragestellung an. Je genauer Deine Frage ist und je besser Du beschreibst, was für eine Antwort du möchtest, desto besser wird das Ergebnis. Die Ergebnisse sind bereits jetzt aber schon besser und ausführlicher, als Google sie bisher geben konnte. Mit SGE werden die Inhalte verschiedenster Seiten zusammengeführt und passend zur Frage aufbereitet. Je mehr Trainingsdaten Seitenbetreiber den Maschinen zur Verfügung stellen, desto besser werden diese Inhalte werden. Publisher geben ihre wichtige Position laut Kevin mit der Bereitstellung der Daten aus der Hand, weshalb es wichtig sei, die Bots auszusperren.
John Shehata bringt als einen weiteren wichtigen Punkt mit in die Diskussion, dass die Aufmerksamkeitsspanne immer weiter abnimmt. Aufgrund dessen sind immer mehr kurze Videos und Inhalte erfolgreich. Kurze aufbereitete Informationen in SGE werden laut John ausreichen und Nutzer:innen werden sich nicht unbedingt weiter navigieren, um ausführliche Inhalte einer bestimmten Quelle zu lesen. Ich kann die verschiedenen Argumente verstehen und würde sagen: it depends. Wir wissen nicht, ob Google SGE weltweit ausrollen wird - auch hier gehen die Meinungen auseinander. Glenn Gabe hat beispielsweise gesagt, dass er nicht daran glaubt. Momentan können wir die Auswirkungen von SGE nicht messen, die GSC hilft da laut Jes auch nicht, da die Daten nicht gesondert einfließen. Wenn Du Dir also unsicher bist, ob Du die Bots ausschließen sollst oder nicht (die SGE kannst Du nur ausschließen, wenn Du den Googlebot blockst), sei gewiss: Du bist mit Deiner Unsicherheit nicht alleine.
Back to Basics
Ein weiteres heiß diskutiertes Thema war, wie man es schafft, die Redaktion, Geschäftsführung und Devs auf seine SEO-Seite zu ziehen. Eventuell wurde auch darüber berichtet, wie Devs mit Donuts auf die eigene Seite gezogen wurden 😀
Die Speaker:innen sind sich einig, dass regelmäßige Schulungen unumgänglich sind. Der wichtigste Part sei für Redaktionen die perfekte Überschrift und die Differenzierung zwischen Überschriften für Discover und Search. Während die Überschriften für die organische Suche klar auf einen Query ausgerichtet sein müssen, haben wir in Discover keine Suche, sondern Vorschläge für die Nutzer:innen. Darum müssen die Überschriften catchy und emotional ansprechend sein.
"What's your number 1 SEO Priority when it comes to Articles?"
– Frage aus dem Publikum, bei jedem Panel und zahlreichen Sessions.
– Barry Adams
|
|
| Wenn Dir das GSC User Interface mehr Fragen als Antworten gibt 🤔 |
Ich liebe es, für den schnellen Check von Such-Performance-Daten in das User Interface der Google Search Console (GSC UI) zu gehen. Ranken verschiedene Seiten zu einem Thema? Korreliert ein Sichtbarkeitsverlust mit rückläufigen Rankings? In der GSC kriege ich schnell Klarheit. Jedenfalls meistens. Oder tendenziell. Ein bisschen...
Denn wie uns Behrend in seinem GSC-Fuckup-Artikel erklärt, gibt es viele Unstimmigkeiten, Einschränkungen und Überraschungen der kontraintuitiven Art im GSC UI, die ich über die API oder über BigQuery nicht habe. Neulich bin ich mal wieder in zwei Situationen geraten, bei denen mir fast die Glotzebömmelchen aus dem Antlitz geglitten wären.
Augenschlackern 1: GSC UI Tabelle gibt andere Daten aus als die über das UI exportierte Tabelle
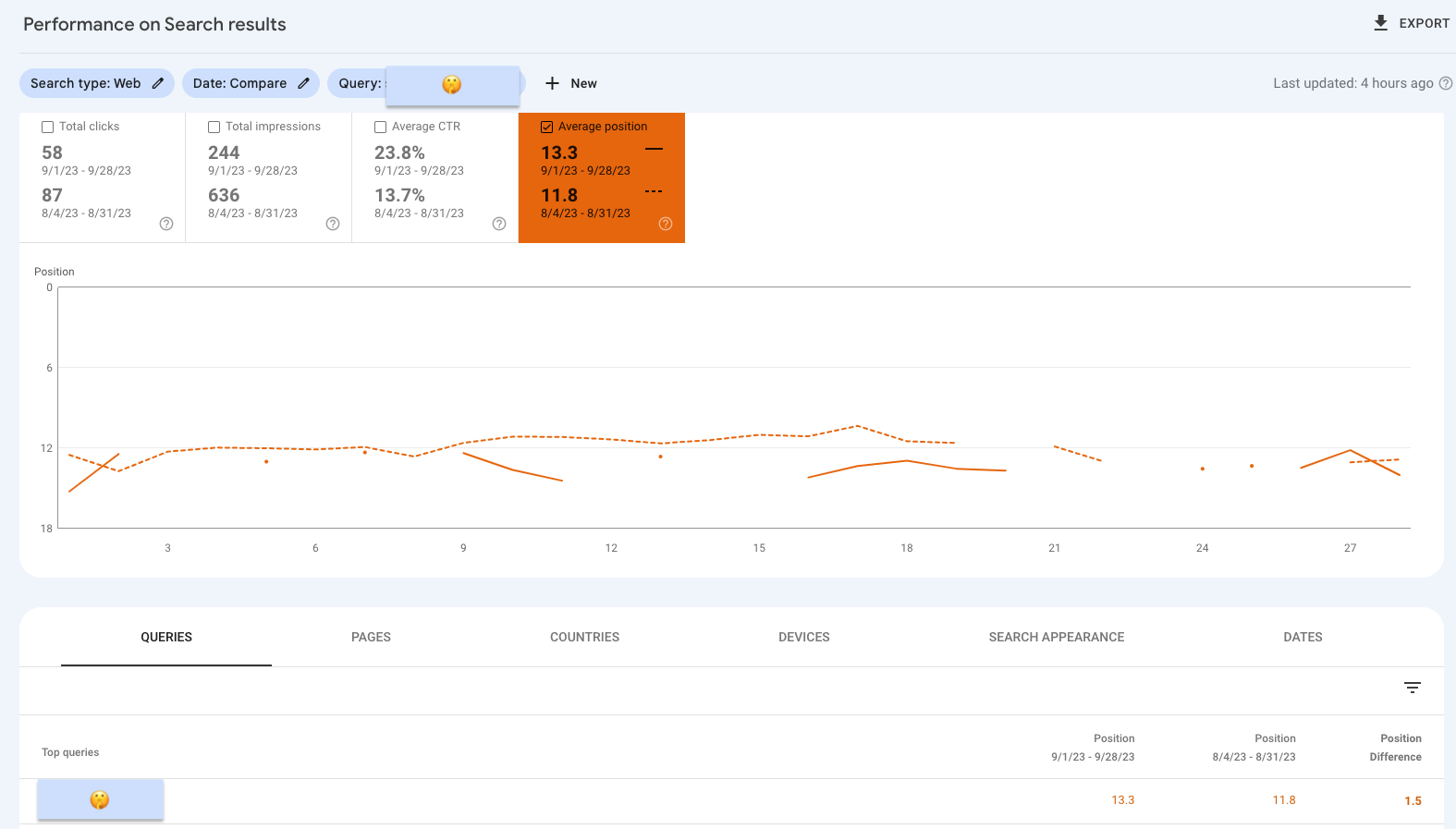
In der Tabelle unterhalb des Graphen im GSC UI ranken die URLs der betrachteten Domain im Schnitt auf Position 13,3.

Wenn ich mir über den "Export"-Button oben rechts in der GSC die Daten ziehe und in Sheets aufbereite, habe ich angeblich im Vorherzeitraum keine Rankings und somit bei allen Performance-Angaben eine Null. Mein Keyword war wohl grad nicht im Sample 😬...
Augenschlackern 2: GSC UI unterschlägt Tage mit Performance-Daten
Gefiltert nach "contains [keyword]" schien es Tage zu geben, an denen mindestens eine Seite der Domain in der Suche ausgespielt wurde und auch Klicks bekam. An anderen Tagen nicht.
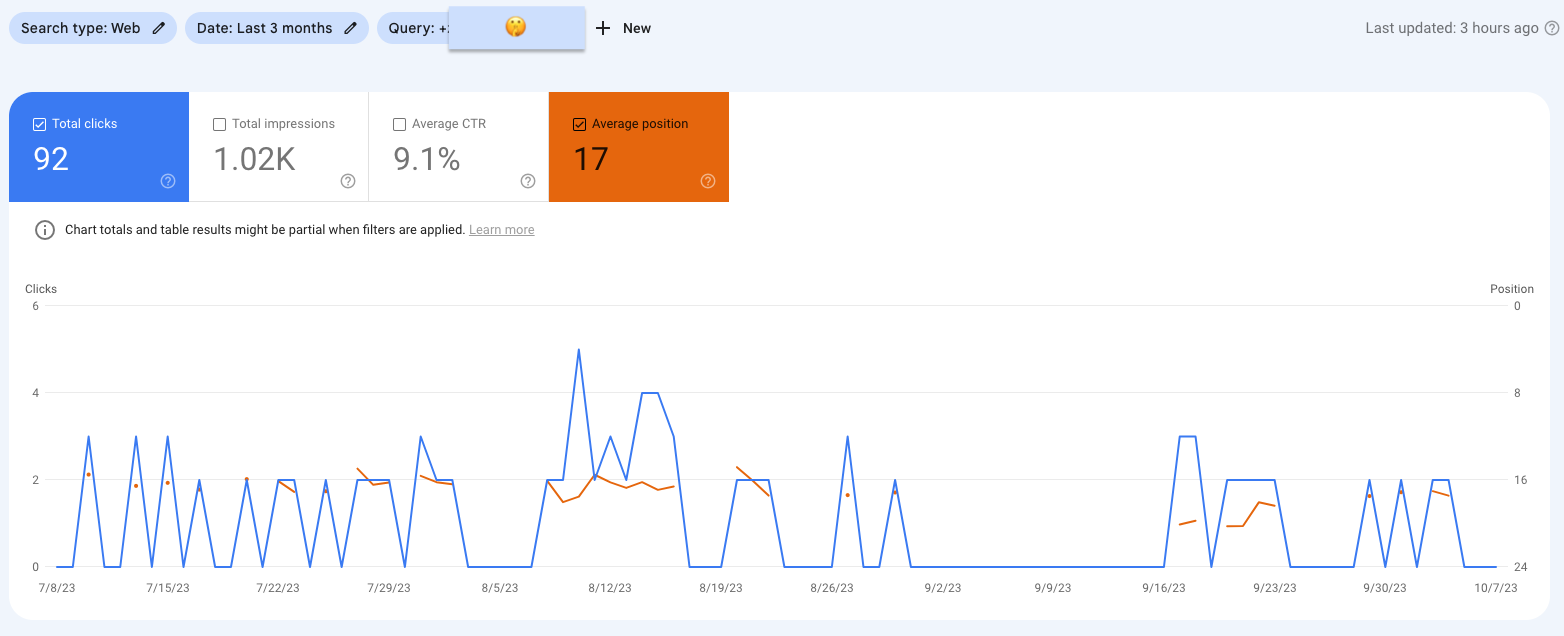
Kann das stimmen? Kann schon sein, aber der Gegencheck mit Daten aus der GSC-API spricht eine andere Sprache:
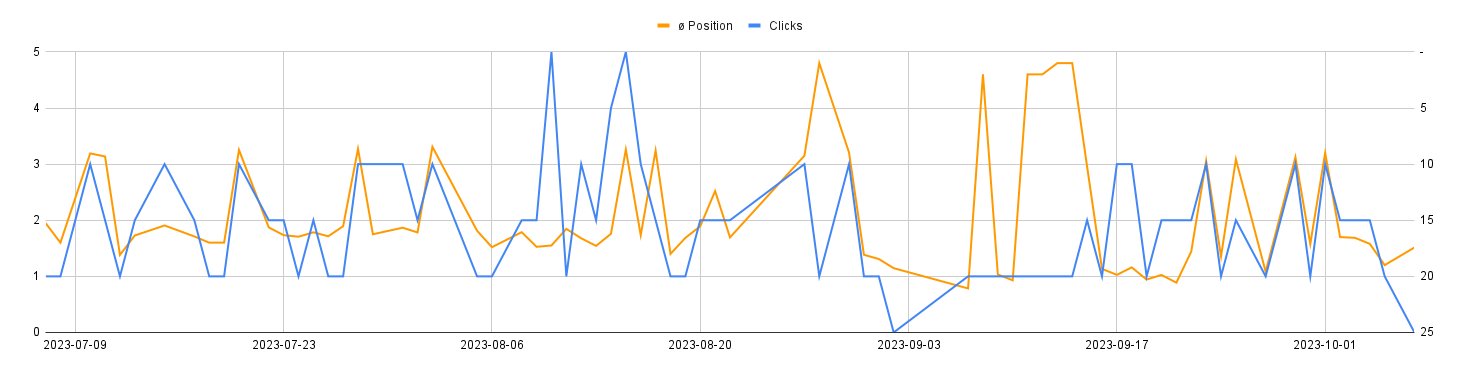
Klicks gab es zwar nicht immer, Rankings auf den Positionen zwischen 20 und 1 aber schon.
¯\_(ツ)_/¯
Fazit: Das GSC-Interface ist nicht der richtige Ort für belastbare Analysen
Deshalb weiche ich für meine Analysen, die über einen ersten Smell Test hinausgehen, immer auf unser internes Tool-Setup aus, für das uns vor allem Heiko die Daten via Schnittstellen anzapft und abfragbar macht. So können wir mit unseren maßgeschneiderten Analysen Erkenntnisse und Empfehlungen für unsere Kunden ableiten, statt uns am Hinterkopf zu kratzen.
Welche Freak-Ergebnisse hat Dir die GSC schon ausgespuckt? Lass uns schaudern.
|
|
| Bad Bots, Bad Bots, watcha gonna do? |
Wäre das Internet ein Land, dann hätte es den viertgrößten CO2 Ausstoß aller Länder.
Wir können davon ausgehen, dass wir Ende nächsten Jahres schon über 7% des CO2 Ausstoßes durch das Internet verursachen.
In jedem Fall verursacht das Internet schon jetzt deutlich mehr Emissionen als der Flugverkehr. 🤯
Dabei wird der größte Teil (ca. 85%) von Datencentern verbraucht. Die User-Endgeräte machen nur 4% aus (allerdings dürfte dabei die Produktion nicht berücksichtigt sein).
Am Ende spielt es keine Rolle: Das Internet ist wichtig. Wir brauchen das (unter anderem um den Klimawandel zu bekämpfen).
Das bedeutet aber nicht, dass wir alles davon brauchen:
Die Schätzungen gehen auseinander, aber zwischen 47% und 64% des Internet-Traffics kommt von Bots. 🤯 🤯
Das bedeutet, dass Bots schätzungsweise so viel CO2 produzieren, wie der Flugverkehr. 🤯 🤯 🤯
(Zugegeben: Das kommt nicht ganz hin. Die ganzen Videos kommen noch dazu, wahrscheinlich ist Bitcoin mit eingerechnet, aber in jedem Fall ist der Ressourcenverbrauch durch Bots beachtlich).
Daher möchte ich noch mal auf eine Idee verweisen:
Wie wäre es, wenn wir nicht mehr allen Bots den Zugriff erlauben, sondern allen den Zugriff verbieten und dann nur noch denen erlauben, die wir unbedingt haben wollen?
Wir schreiben die Robots.txt also etwa so (natürlich noch nicht exakt so, sondern an Deine Bedürfnisse angepasst):
```
User-Agent: /
Disallow: /
```
```
User-Agent: Googlebot #Main Googlebot
User-Agent: Bingbot #Main Bingbot
User-Agent: duckduckbot #Main DuckDuckGo
User-Agent: ia_archiver #Main Web Archive
User-Agent: archive.org_bot #Web Archive
User-Agent: Googlebot-Image
User-Agent: AdsBot-Google
Disallow:
Disallow: *.woff2 #Bots brauchen keine Schriftarten
Disallow: /store-api/ #Bots brauchen keinen Zugriff auf das Warenkorb-JSON
...
```
Was würde Dich von diesem Ansatz abhalten?
Und welche Bots würdest Du noch den Zugriff erlauben?
Und natürlich hast Du recht: Das hält nur die Bots ab, die sich auch an die Regeln halten. Viele tun das nicht. Manche, weil sie es nicht wissen. Manche, weil es ihnen egal ist und andere (wie beispielsweise Facebook oder Slack) weil sie meinen, dass sie ja nur für einen User agieren.
Aber auch hier kann man noch was machen: Du könntest beispielsweise Deinem CDN beibringen, nur Zugriffe von Bots zuzulassen, wenn dieser Bot in der Robots.txt für diese URL freigeschaltet ist.
|
|
| Ob Du eine Sitemap brauchst, siehst Du, wenn Workflows baust |
Vorab: Nicht jede Website braucht eine Sitemap. Was sagt Google zu dem Thema?
Laut Google brauchst Du eine Sitemap, wenn:
Deine Seite groß ist Deine Seite neu ist und wenige externe Links hat Deine Seite viele Videos oder Bilder hat (die für die organische Suche relevant sind), oder in Google News angezeigt werden soll
Das heißt Du brauchst keine, wenn:
Deine Seite klein ist (< 500 Seiten) Deine Seite intern gut verlinkt ist Du wenige Videos, Bilder oder News-Seiten hast
Was heißt jetzt "groß" ist die Frage? Google sagt: Mittelgroß bis größer sind mehr als 10k Seiten. Groß ist alles, was mehr als 1 Mio. URLs hat.
Je nachdem, wen Du fragst, wirst Du aber unterschiedliche Antworten bekommen.
So kannst Du prüfen, ob Du eine Sitemap brauchst
Ganz wichtig: Eine korrekte Sitemap zu haben, schadet keiner Website. Wenn Du aber einige potenzielle Maßnahmen auf dem Tacho hast und Dir nicht sicher bist, worin Du deine Energie jetzt stecken sollst, dann hilft Dir der folgende Denkanstoß sicherlich.
Wenn wir die Größenangaben zu Websites mal ausblenden und von Google News absehen, dann kannst Du folgendermaßen prüfen, ob Deine interne Verlinkung es hergibt, ohne Sitemap zu fliegen:
Crawle Deine Website (mit Sitemaps) – beim ScreamingFrog kannst Du das unter Configuration ➞ Spider ➞ Crawl einstellen und dort Deine Sitemaps eintragen Prüfe, welche Seiten nur Links
Wichtige Seiten müssen möglichst schnell und mit internen Links von indexierbaren Seiten auffindbar sein. Wenn dem so ist, brauchst Du nicht unbedingt eine Sitemap.
Was Du durch diesen Test auch findest: Baustellen der internen Verlinkung.
Nicht jeder Link ist gleichwertig. Das haben Martin Splitt und John Müller auch schon unterschiedlich kommentiert. Wir wissen aber aus Erfahrung, dass es definitiv Unterschiede zwischen Main Content und z. B. der Navigation gibt.
Und wenn Du darüber nachdenkst, ob Infinite Scrolling etwas für Dich ist, dann hilft es auch zu wissen, ob manche Produkte nur aus der Paginierung erreichbar sind. Das muss geändert werden, bevor Du die Paginierung durch Infinite Scrolling austauschst, wenn durch das Inifinite Scrolling keine Produkte mehr ohne Interaktion in Deinem HTML verlinkt sind!
Zeit sparen, indem Du einen recyclebaren Workflow verwendest
Du kannst am Ende das Tool verwenden, womit es Dir am einfachsten fällt.
Ich rate Dir aber: Mache Dir diese Arbeit beim nächsten Mal einfacher. Mit Knime und einfachen Nodes wie einem CSV Reader, Row Filter, Joiner & Co. kannst Du Dir sowas ganz leicht selbst zusammenbauen.
Was Du außerdem brauchst: Alle internen Verlinkungen aus einem Crawl.
So baust Du dir das jetzt zusammen:
Lese die beiden Dateien internal_all und all_inlinks mit dem CSV Reader ein Optional filterst Du auf einen Bereich Deiner Seite, z. B. alle Produkte in beiden Listen (URLs und Linkziele) Jetzt filterst Du aus der all_inlinks alle Links heraus, die als Quelle die Sitemap haben Filtere zusätzlich alle Verlinkungen von einer Seite auf sich selbst heraus (Mit der Rule Engine kannst Du dafür eine neue Spalte schreiben, die Links auf sich selbst kennzeichnet; Der Row Filter hilft Dir, diese Zeilen dann zu löschen) Der Value Counter Node zählt, wie viele Verlinkungen jede URL bekommt Mit einem Joiner verbindest Du dann die beiden Listen und lässt Dir die Werte ausgeben, die in in der internal_all auftauchen, nicht aber in der gefilterten all_inlinks
Der Workflow dafür sieht so aus:
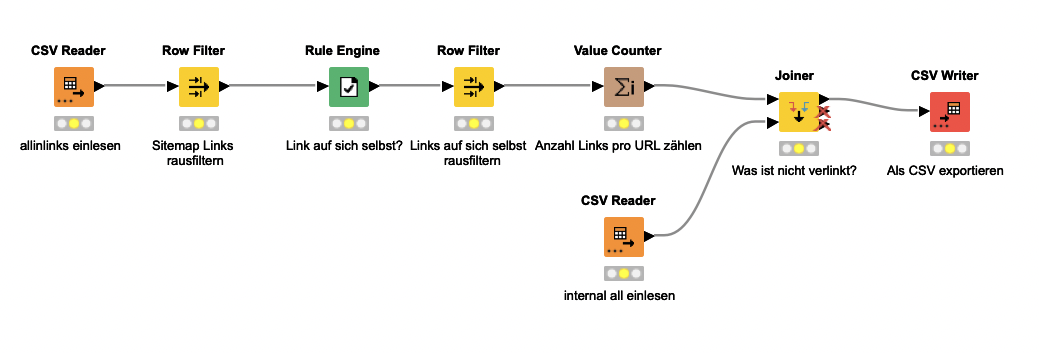
Schritt 3 kannst Du wie oben beschrieben weiter verfeinern und beispielsweise
alle Verlinkungen aus der Navigation und dem Footer oder der Paginierung entfernen und so schauen, wie erreichbar Deine URLs wirklich sind.
Idealerweise liefert Dein Endergebnis 0 URLs aus, die nicht auffindbar sind.
Wenn es doch unauffindbare URLs gibt, die relevant für die organische Suche sind, und das einen Großteil Deiner Website betrifft, dann lohnt sich eine XML-Sitemap. Und: Du musst unbedingt an Deiner internen Verlinkung arbeiten.
Gerne kann ich Dir helfen, das zu überprüfen und mit Dir Pläne schmieden, wie wir Deine interne Verlinkung aufpeppen können.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|




