| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #169 |

|
| 👋 Bye Bye Büro |
Letzte Woche war mal wieder einiges los. Einige der Themen, die die SEO-Welt (oder zumindest uns im SEO-Kontext) beschäftigt haben, findest Du auch diese Woche wieder in unserer sommerlich-frischen Ausgabe. Aber auch organisatorisch hat die Mitte des Augusts ein paar Entwicklungen für uns mit sich gebracht.
Jolle zeigt Dir ein nützliches Tool, mit dem Du die CrUX History API anzapfen kannst Philipp teilt (nicht nur) seine Gedanken hinsichtlich der Frage, wie man mit Open AI Bot & Co umgehen sollte, mit Dir Johan entdeckt Traffic-Potenzial mit Hilfe von Bing Nils versucht, den KI-generierten Ergebnissen einen Namen zu verpassen Ich greife den Betreff der heutigen Ausgabe auf
Übrigens haben wir uns nicht nur von unserem Office, sondern leider auch von Andreas verabschiedet -- der zieht weiter beziehungsweise wieder zurück in die Inhouse-Welt. In beiden Fällen gilt: Wir werden uns wieder sehen und Bedanken uns für die schöne gemeinsame Zeit.
Viel Spaß beim Lesen
Deine Wingmenschen
|
|
| Core-Web-Vitals-CrUX-Daten, geschnitten oder am Stück? |
Was für Rankings relevant ist, sind echte CWV-Userdaten aus dem Chrome-Browser. Was für SEO- und Dev-Teams leichter zu kontrollieren und zu testen ist, sind reproduzierbare Labordaten wie wir sie im Performance- oder im Lighthouse-Test der Chrome DevTools finden oder unterhalb der Felddaten auch bei den PageSpeed Insights.
Harry Roberts versichert uns in "Core Web Vitals for Search Engine Optimisation: What Do We Need to Know?", dass wir alles, was wir über die Core Web Vitals für Suchmaschinenoptimierung wissen müssen, in der Google Search Console (GSC) finden und Lighthouse sowie PageSpeed Scores ignorieren sollten.
Dave Smart hat jetzt allerdings nochmal ein hübsches Tool mit uns geteilt, das uns erlaubt, echte CrUX-Daten wochenweise im zeitlichen Verlauf zu monitoren – und zwar auch dann, wenn wir wie bei der Konkurrenzanalyse keinen Zugang zur GSC haben.
Er zapft die CrUX History API an, so dass wir für Domains (origin) oder spezifische URLs, sofern es genügend CrUX-Daten gibt, Charts und CSVs angeboten bekommen, um das Abschneiden wochenweise zurückverfolgen zu können.
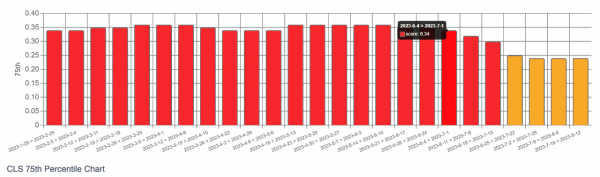
Der schwarze Kasten im Bild markiert den Zeitpunkt, an dem das Dev-Team auf der Domain fehlende Höhen- und Breitenangaben für Bilder eingebaut hat. In den Wochen darauf sehen wir, dass die laut der CWV-Ampellogik "schlechten" Seiten (rot) abnehmen und schließlich zu Seiten werden, die nur noch "verbesserungswürdig" (gelb) sind.
Das Tool hat Dave für uns alle unter https://tamethebots.com/tools/cwv-history nutzbar gemacht und genauere Hintergründe sowie seinen Test-Case, aus dem der Screenshot stammt, in einem Blogartikel ausgeführt.
Toll finde ich, dass wir uns hier nicht nur die typischen 75-%-Perzentile angucken können, bei denen Google für die Core Web Vitals den Cut macht, sondern wir tatsächlich die prozentuale Verteilung der Nutzerinnen und Nutzer geliefert bekommen.
Schau gerne mal drauf, ob das Tool Dir nicht auch zumindest beim Wettbewerbs-Check eine nützliche Ergänzung sein kann.
|
|
| DU kannst nicht VORBEI! |
Letzte Woche gab es spannende Neuigkeiten zum Thema "OpenAI Bot kann ausgesperrt werden". Da musste ich an Gandalf aus Herr der Ringe denken, wie er den Balrog auf der Brücke davon abhalten möchte, diese zu passieren.

Bereits zuvor wurde von verschiedenen Möglichkeiten berichtet, um die Schranke für diverse Crawler zu schließen. 🙅 Neben dem GPTBot gibt es ja auch noch diverse andere Maschinen, die Inhalte unserer Websites herunterladen, speichern und möglicherweise damit andere Sprachmodelle trainieren oder trainiert haben.
Vielleicht hast Du auch mitbekommen, dass es bei Zoom Diskussionen gab, inwieweit mit Nutzerdaten KI trainiert wird beziehungsweise trainiert werden darf:
"Zoom's [terms of service] now demand that they use AI to train on audio, face and facial movements, even private conversations without recourse, unconditionally and irrevocably."
Es kommen immer wieder – berechtigterweise – Fragen zum Thema Urheberrecht sowie Persönlichkeitsrechten und KI auf (Behrend hat sich dazu auch schon geäußert in Newsletter #156 und #157). Aber was solltest Du jetzt tun? Den GPTBot aussperren, oder lieber "passieren lassen"?
Unterschiedliche Meinungen
Auch die LinkedIn- und SEO-Welt tauscht sich aus und berichtet. 📰 So haben Andé Goldmann und Christoph Burseg beispielsweise versucht zu analysieren, welche der großen (und/oder im SEO erfolgreichen) Websites die Anweisung in der robots.txt gegeben haben, den GPTBot nicht crawlen zu lassen.
André Goldmann verweist zusätzlich darauf, dass man nicht nur den GPTBot für Trainingsdaten aussperren kann, sondern auch eine Schranke für Plugins setzen kann, wenn diese Inhalte der Website in ChatGPT abrufen wollen (Beispiel Linkreader). Der User-Agent dafür heißt ChatGPT-User.
Auch unter einem Post von Johannes Theberath wird diskutiert. Die beiden Lager – GPTBot aussperren vs. GPTBot nicht aussperren – argumentieren in der Regel mit folgenden Begründungen:
✅ ChatGPT darf rein: ChatGPT (und andere Sprachmodelle) sollte ich nicht ausgrenzen, damit meine Inhalte und meine Website hier bei Anfragen relevant sein können. Sperre ich beispielsweise den GPTBot aus, könnte ich in Zukunft, einen Nachteil haben.
versus
⛔ ChatGPT darf nicht rein: Wenn ich ChatGPT (und anderen Sprachmodellen) die Erlaubnis gebe, mit meinen Inhalten und Daten zu trainieren, wird sich an meinem Inventar bereichert ohne dafür eine Gegenleistung zu liefern. Das könnte in Zukunft zu einem Nachteil werden, wenn potenzielle Nutzer*innen meine Website nicht mehr ansteuern, weil Antworten direkt aus der Such- beziehungsweise Antwortmaschine kommen. Zusätzlich können sich Dritte langfristig womöglich an meinen Inhalten bereichern, wenn ChatGPT mit diesen Daten trainiert wurde.
Mein Take
Ich kann beide Seiten gut verstehen. Das Argument, dass solange Tools wie ChatGPT nicht vollständig von der Masse adaptiert werden, keine großen Vorteile existieren, finde ich dabei sehr wichtig. Vor allem in Bezug auf ChatGPT.
Bei anderen Tools wie Bard, dem Bing Chat Bot & Co. gibt es einen gesünderen Werteaustausch.🤝 OpenAI trainiert mit Daten von Websites (bekommt also Wert), gibt im Umkehrschluss aber keinen Wert zurück. Das stößt einigen logischerweise übel auf.
Klar, in der SGE rappelte es auch zum Start, weil hier keine Quellen an den Textbausteinen aufgetaucht sind. Das wurde als Feature in der SGE getestet (Anita hat darüber berichtet) und wird vermutlich auch zum offiziellen Start als Feature notwendig sein, damit die Unternehmen/Websites nicht auf die Barrikaden gehen. Aktuell tauchen im Text allerdings keine Quellen mehr auf.
Ich hatte vor kurzem über die tolle Auffindbarkeit sämtlicher New York Times Artikel berichtet und die Tage gab es zur New York Times eine Meldung, dass möglicherweise eine große Klage im Raum steht. Die New York Times ist nicht damit einverstanden, dass OpenAI einfach massig Inhalte "nimmt" und diese monetarisiert, ohne einen Gegenwert zu liefern.
Dabei stechen folgende Aussagen besonders heraus:
"If judges believe that the materials A.I. spits out are new creations, or that they significantly transform the works they're based on, they're likely to see its treatment of copyrighted works as fair use.
If, on the other hand, they believe the A.I. is simply copying and regurgitating others' works, they could find its use illegal, and force OpenAI to destroy all copies of those works in its dataset."
Wenn Fall 2 eintritt, würde das wohl eine Welle auslösen.
Gerade vor wenigen Tagen gab es zwei spannende Berichte (von The Atlantic und Gizmodo) zum Books3 Datensatz, mit dem einige Sprachmodelle trainiert wurden. Dabei geht es mehr oder weniger um die gleichen Probleme.
Die großen Konzerne bereichern sich an Inhalten Dritter. Je mehr über die Daten, mit denen trainiert wurde, bekannt ist, desto größer ist die Chance, dass eine Klage droht oder andere ähnliche KI-Modelle bauen. Genau dafür war Books3 ursprünglich mal gedacht: Eine große Datenbasis Open Source bereitstellen, damit alle eine Chance haben, gleichwertige KI-Modelle zu bauen.
Die Idee hinter Books3 ist natürlich interessant und mag von der Absicht her gut sein. Aber der Zweck heiligt nicht die Mittel – wir können nicht einfach ohne die Berechtigung Inhalte anderer nehmen und uns daran bereichern. Weder im Open Source-Bereich, noch auf Ebene großer Unternehmen.
Leider ist es wie so oft bei neuen Technologien ein Fall, bei dem die Gesetzgebung (weltweit) nicht hinterherkommt. Ich hoffe, dass hier möglichst schnell mehr Klarheit besteht, was geht und was nicht geht. Ansonsten befinden wir uns im Wilden Westen 🤠, in dem es keine Spielregeln gibt. Und das funktioniert einfach nicht.
|
|
| Das Ding mit Bing |
I don't always google with Bing. But when I do...
Ich habe ja immer mal meine don't google Wochen, in denen ich versuche, andere Suchmaschinen zu nutzen. Die Ergebnisse lassen mich dann immer wieder zu Google zurückkehren.
Das geht aber nicht allen Menschen so. Und daher solltest Du Deine Zielgruppe noch mal anschauen. Ist Deine Zielgruppe tendenziell älter und arbeitet eher in größeren Unternehmen? Oder hast Du eher hochpreisige Produkte? Dann solltest Du Dir Deinen Bing-Traffic nochmal anschauen. Vor allem, wenn Du ein B2B-Geschäftsmodell hast.
Wie groß der Marktanteil von Bing ist, variiert. Wir sehen teilweise 1%, teilweise 20% des Google-Suchvolumens auf Bing. Es kann also durchaus auch bei Dir so sein, dass Du für 100 Impressions bei Google 20 Impressions bei Bing machen könntest. Bei häufig einer höheren CTR und vor allem einer höheren Conversion / Warenkorb-Werten. Wie sich das in Zukunft entwickeln wird, bleibt abzuwarten.
Jetzt kommt das große Aber: In den letzten Monaten habe ich mehrere Seiten analysieren dürfen, deren Bing-Traffic bei den 2-5% lag, den die meisten erwarten würden. Ein Blick in die Bing Webmaster Tools führte aber erstaunliches zu Tage:
Unvollständige Indexierung: Bing hat in einem Fall nur 1% der URLs indexiert, die Google im Index hatte Schlechtes Ranking: Die CTR war in 2 Fällen wesentlich niedriger als die CTR bei Google Kein Brand-Ranking: In einem Fall hat die Domain für den eigenen Brand auf Position 4 gerankt. Überall Fehler: Bei 2 Domains wurde gemeckert, dass fast alle Seiten keine <h1> hatten.
Die Ursache ist in vielen Fällen die Gleiche: Bing kann mit JavaScript nicht so gut um wie Google. Natürlich sind das harte Fälle. Die Sitemaps funktionieren nicht sauber. Server Side Rendering ist aus Gründen nicht, oder fehlerhaft implementiert, oder die Seite verwendet Web Components und/oder Shadow DOM. Techniken, mit denen Bing nicht klar kommt. (Aktuelle Lese-Empfehlungen: Web Components Usage, Shadow DOM Accessibility.)
Das führt dann zu leeren Kategorieseiten, fehlenden <h1>en, kaputter interner Verlinkung und anderen SEO-Horror-Stories.
In einem Fall konnten wir jetzt sehr gut nachweisen, wie groß das Traffic-Potenzial ist: Es gab einen Seitenbereich, den Bing verarbeiten konnte und einen, den nicht. Im Vergleich der Bereiche mit der Performance bei Google konnten wir eine Versechsfachung des Traffics in Bing prognostizieren. Das entspräche bei der Domain einem Uplift von 10% bei Google bei einer 30% höheren Conversion des Bing-Traffics.
Und entgegen den sonstigen Einschränkungen ist das zu fast 100% sicheres Wachstum. Die einzige Unwägbarkeit ist, ob der Longtail sich im Verhältnis Google / Bing ebenso verhält, wie der Shorthead. Und natürlich die Frage, wie stark Google dadurch noch zulegt. Und wir haben nur Bing ausgewertet. Die auf Bing basierenden Suchmaschinen kommen ja noch dazu.
Der Vergleich zwischen Bing Webmaster Tools und Google Search Console lohnt also. Hier das schnelle Vorgehen:
Performance: Wie ist das Suchanfragen-Verhältnis von Google zu Bing? Hier kannst Du meist die Impressions einfach verwenden, wenn Du bei Google/Bing stabil auf Seite 1 rankst. Wie verhalten sich Impressions, Klicks, CTR zueinander? Wie sieht das in einzelnen technisch unterschiedlichen Seitenbereichen aus? Indexierung: Wie verhalten sich die indexierten Seiten in einzelnen Bereichen? Das kannst Du in Bing Webmaster Tools einfach filtern. In der GSC musst Du ein wenig mit Daumenwerten arbeiten, wenn Du keine Folder-Properties hast. Rendering: Du suchst pro Template eine URL, die in Google und in Bing indexiert ist. Dann kopierst Du das indexierte HTML beider Seiten in jeweils eine lokale Datei. Beide Varianten kannst Du jetzt vergleichen (erst optisch, indem Du beiden im Browser öffnest und nebeneinander legst, dann bei Bedarf auch das gerenderte HTML)
Vor allem, wenn Du die Fragen im zweiten Absatz mit "Ja" beantworten konntest, solltest Du Dir also möglichst bald einmal die Zeit nehmen, hier einen Abgleich zwischen Google Search Console und Bing Webmaster Tools zu fahren. Es könnte sich lohnen!
Wenn wir zusammen drauf schauen sollen, dann such Dir einfach einen Termin aus.
|
|
| CHERP! |
Jetzt darfst Du raten: Handelt es sich um
ein neues Akronym aus der SEO-Branche einen zufällig ausgewählten Ausruf, um die Aufmerksamkeit des Lesers zu erhalten das Geräusch eines Vogels im Stimmbruch
Hast Du 1. gewählt, dann liegst Du richtig. Wobei Du auch den Vorteil des Kontexts hast, gerade einen SEO-Newsletter zu lesen ;)
Jedenfalls bin ich heute das erste Mal der Abkürzung CHERP begegnet. Wenn Du da jetzt eine Parallele zu SERP gezogen hast, liegst Du erneut richtig. Letzteres ist die uns gut bekannte Search Engine Result Page. Mit den Neuerungen in der Suche rund um KI, SGE und das neue Bing betritt ein neuer Akteur die Bühne.
CHERP steht als Abkürzung für CHat Experience Result Page. Zumindest sagt das Danny Goodwin in seinem Artikel bei SearchEngineLand. Vermutlich wäre CERP von der Aussprache her ein Albtraum in der Unterscheidung zur bisherigen gewesen, weswegen man das H noch dazu zog.
Inhaltlich beschreibt CHERP in den Fällen von Google und Bing die durch KI generierten Inhalte, die derzeit über der konventionellen SERP angezeigt werden. Wie Anita uns im letzten Newsletter verriet, nennt Google das "AI Overview". Bei ChatGPT wäre die CHERP schlicht die Antwortfläche. Während es sich aktuell noch sehr ungewohnt anhört – was nach Jahren der ausschließlichen Verwendung von SERP auch klar ist – finde ich den sprachlichen Kniff ganz nett.
Zumindest dürfte CHERP langfristig einfacher zu verwenden sein, als jedes Mal "Die KI-Ergebnisse oben auf der SERP" zu sagen. Obgleich die Frage ist, ob sich ähnlich wie im Falle von "etwas googeln" nicht mit "AI Overview" oder "SGE" das Google-Wording für sämtliche Integrationen dieser Art durchsetzen wird. Wobei ich letzteres persönlich sehr belastend fände, da dies bei mir bereits synaptisch mit Eintracht Frankfurt belegt ist. Google scheint das eigentlich auch so zu sehen.
Was meinst Du? Klingt CHERP nach etwas, das Du in Deinem Wortschatz aufnehmen würdest? Oder sollten wir einfach alles SGE nennen und dann ist das abgehakt?
|
|
| Ciao Kakao |
Der letzte Donnerstag war der erste Tag in der Wingmen-Firmengeschichte ohne Büro. Vor 6 Jahren sind wir von Altona in den Berliner Bogen umgezogen. Seit März 2020 ist das Büro aber eher dünn besetzt. Am Dienstag noch den letzten Kundentermin dort abgehalten. Am Mittwoch dann gemeinsam fleißig alles ausgeräumt.

Letzter Kundentermin: Franzbrötchen und Kaffee auf dem Tisch, Matt ist remote am Start, die Kunden sind auf dem Weg.
Das einzige, was wir von dort glaube ich wirklich vermissen werden, wird unsere selbst gezimmerte Bar sein. Die haben wir im Oktober 2017 im Rahmen eines Team-Events gemeinsam zusammengeschraubt. Seitdem haben wir dort wohl das ein oder andere Getränk in den unterschiedlichsten, stets illustren, Runden getrunken.

Nur 2 von vielen Bildern: Im April 2018 mit dem Team und im März 2019 inklusive Ines an der Bar.
Und jetzt? Jetzt sind wir erstmal Out of Office. Also literally. Es ändert sich trotzdem erstmal nicht viel: Nach wie vor sitzen wir wild in der Gegend verteilt im Home Office. Unsere Adresse am Anckelmannsplatz bleibt erhalten. Wir freuen uns darauf, unsere Zusammenarbeit in Zukunft weiter an unsere Bedürfnisse anzupassen und Dinge auszuprobieren.

Wir sind dann mal weg: Unsere Möbel und Pflanzen bleiben für unsere Nachmieter da.
Das nächste Team-Offsite, die nächste Workation und der nächste gemeinsame Konferenz-Besuch kommen bestimmt!
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|




