| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #156 |

|
| 🤌 Smells like SEO Spirit |
Neeva gonna let you down, neeva gonna make you cry… Tja, leider nix mehr mit come as you are und ein weiterer "Google Killer" hat ins Gras beißen müssen. Fieses Google! Mehr über die Hintergründe erfährst Du im Artikel von Don Johan, der umringt wird von weiteren spannend-mafiösen Artikeln von:
- Padre Behrend, dessen Anwälte openAI den Prozess machen
- Capo Jolle, die ihre mafiöse Erfahrung über Tests am Objekt stellt
- Capitane Johan über die Enttarnung eines neuen Google Bots
- Buchhalterin Nora entlarvt den User Agent innerhalb ihrer Billanz
- Consigliere Caro darüber, wie man die Konkurrenz um ihre ungerechtfertigten Featured Snippets bringt.
Ciao!
Deine Wingmenschen
|
|
| Trainieren geht über Kassieren |
Ja... wieder was über AI ¯\_(ツ)_/¯
Die Entwicklung des Internets hat schon mehrfach massive Probleme Herausforderungen mit dem Urheberrecht ausgelöst. Vor etwas mehr als 20 Jahren beispielsweise hat Napster der Welt vor Augen geführt, dass das Urheberrecht mit dem Internet völlig neue Aufgaben lösen muss. Und seit mittlerweile über zehn Jahren wird diskutiert, ob Suchmaschinen News-Publisher dafür bezahlen müssen, sie zu verlinken. Beides ist auch nach Jahren nur so leidlich geklärt, sowohl gesellschaftlich als auch juristisch...
Jetzt kommt das Thema AI-Modelle und Trainingsdaten noch dazu: Dürfen Inhalte ohne Zustimmung des Urhebers/Rechteinhabers genutzt werden, um KI zu trainieren?
Open AI und Co. sind davon wohl ausgegangen und haben ihre bahnbrechenden Modelle erstmal auf allem trainiert, was das Internet zu bieten hatte. Wir haben schon ein paar Beispiele dafür in unserem Newsletter erwähnt und das Thema wird auch außerhalb der Tech Bubble diskutiert.
Insbesondere für Bilder ist hier die Diskussion schon vor Gerichten gelandet. Ob ein konkreter Inhalt verwendet wurde, ist in der Regel schwer nachzuweisen. Das Wasserzeichen von Getty Images ist da eher die Ausnahme. Wie die Verarbeitung von Inhalten durch die KI, die den eigentlichen Inhalt nicht speichern, sondern lediglich das Modell davon beeinflussen lassen (so wie ein menschlicher Künstler sich von einem Inhalt inspirieren lassen würde?) bewertet wird, ist noch völlig offen.
Daher versuchen die Rechteinhaber, eher die Bereitstellung der Trainingsdaten anzugehen. Das Portal haveibeentrained.com gibt Dir die Möglichkeit herauszufinden, ob Deine Inhalte bereits in Trainingsdatensätzen Verwendung finden.
Der Fotograf Robert Kneschke hat sich auf der Basis mit dem LAION e.V. angelegt und berichtet über seine Sichtweise der Dinge. Interessant finde ich den Kniff von LAION, nicht die Bilder selbst bereitzustellen, sondern nur die URLs. Mein laienhaftes Rechtsverständnis befürchtet, dass entsprechende Urteile auch abseits von KI-Themen rechtliche Auswirkungen auf das Setzen von Links haben (gute oder schlechte).
Auf der anderen Seite versucht beispielsweise Shutterstock mit lizenzierten Trainingsdaten Geld zu verdienen, was mäßig gut bei den Inhalteerstellenden anzukommen scheint.
Und auch wenn sich im deutschen Recht oder gar auf EU-Ebene ein Konsens findet, wie damit umgegangen wird, heißt das nicht, dass andere Teile der Welt dem folgen. Wenn sich beispielsweise El Salvador schon versucht, als KI-Steueroase zu positionieren, wäre es schließlich kontraproduktiv, das mit restriktiver Urheberrechtsauslegung zu torpedieren. Hier verbergen sich eine nicht definierte Zahl moralischer Dilemmata (Dilemmen? Dilemmas? Hey Bard, wie schreib ich das richtig?) zwischen den Chancen, die moderne AI-Modelle bieten, und den Rechten der genauso modernen Menschen, deren Arbeit geklaut, kopiert, überlagert oder lohngedumpt wird, weil AI so viel schneller skaliert.
|
|
| SEO-Erfahrung > Tests? 👵🔮😵💫 |
Wieder eine spannende Case Study von SearchPilot. Du weißt schon. Die Bande, die auf großen Websites mit genügend vergleichbaren Seiten-Templates A-/B-Testing betreibt, um den Effekt von Maßnahmen auf organische Rankings und Klicks systematisch zu bestimmen.
Was SearchPilot nicht müde wird zu betonen: Ihnen geht es nicht um Wissenschaft, sondern ums Geschäft. Deshalb plädieren sie dafür, Maßnahmen auch dann umzusetzen, wenn die Testergebnisse vielleicht nicht statistisch signifikant sind, aber trotzdem in die richtige Richtung gehen: "Default to deploy". Schließlich zeigt so ein Testresultat auch, dass man zumindest die Bestands-Performance nicht kaputt macht. Und auch kleine Vorteile addieren sich auf.
Der Test: Article-Markup auf Artikeln einer Service-Review-Page
Die neueste Case Study ist vor diesem Hintergrund dennoch bemerkenswert. SearchPilot hat getestet, welchen Effekt das Auszeichnen von Artikeln auf einer Seite mit "Service Reviews" (also nicht im Newsbereich) mit strukturierten Daten (Article-Schema-Markup) auf den organischen Traffic hat. Bei all den Review-Updates der letzten Zeit super spannend.
Das Ergebnis?
Nicht eindeutig, aber in der Tendenz negativ.
Die Konsequenz?
Sie implementieren das Article-Markup dennoch seitenweit.
Die Begründung?
"Default to deploy" heißt bei unschlüssigen Ergebnissen generell, dass SearchPilot lieber implementiert, als untätig zu bleiben. Für Schadensbegrenzung reicht das nicht allzu negative Ergebnis aus. SearchPilot verweist zudem darauf, dass Google sich generell für strukturierte Daten ausspricht, um Artikel besser zu verstehen. Sie erhoffen sich durch diese "Kooperation" mit Google langfristig einen positiven Effekt. Eine Wette auf die Umbrüche durch Künstliche Intelligenz
"With AI becoming an ever-growing part of how search engines understand content to deliver answers to user queries, schema markup can help crawlers become more efficient in understanding the context and purpose of pages.
While the direct impact of this is harder to measure, it's an important factor to consider when deciding whether or not to implement article schema."
— Rida Abidi, SearchPilot
Was halten wir davon?
Wir können davon ausgehen, dass SearchPilot bei eindeutig negativen Testergebnissen von der Implementierung der Maßnahmen absieht. Denn wenn sie Entscheidungen darüber allein aus gängigen Best Practices und Vorgaben von Google ableiten würden, gäbe es keinen Mehrwert ihrer Testing-Strategie.
Zur Wahrheit gehört auch, dass wir SEOs in vielen Szenarien nicht die Bedingungen zum Testen vorfinden und deshalb viele unserer Empfehlungen aus diesen zwei Quellen ableiten: unsere Erfahrung und die vom (immer noch) größten Player auf dem Markt festgeschriebenen Regeln.
Die Verknüpfung zur KI finde ich einigermaßen windig. Richtig ist, dass wir Google mit strukturierten Daten dabei helfen, unseren Content besser zu verstehen und so Fehlinterpretationen und Ungenauigkeiten zu vermeiden. Die Hoffnung ist berechtigt, dass Google die Crawling-Dividende nicht einfach durch eingesparte Ressourcen einstreicht, sondern Seiten im Gegenzug mit guten Rankings belohnt, sofern Qualität und Inhalt passen.
Eine zweite Hoffnung versteckt sich darin: Aktuelle Tests geben nicht wieder, wie sich das Web und SEO weiterentwickeln werden. Hier in Übereinstimmung mit Erfahrung, Best Practices und den Hinweisen von Google zu arbeiten, sollte uns die grobe Richtung weisen, um zukunftssichere Entscheidungen zu treffen, statt immer nur dem aktuellen Update nachzujagen.
Aber die Versuchung, dass wir nicht passende Testergebnisse rationalisieren und uns in die eigene Tasche lügen, ist groß. Diesen Test würde ich also gerne in sechs Monaten und in zwei Jahren nochmal wiederholen, um die Entwicklung im Auge zu behalten.
Was wir zudem nicht wissen:
Wie vollständig waren die im Markup abgelegten Informationen (Autor, Thema, Überschriften etc.) bereits im unstrukturierten Text enthalten und wie gut konnte eine saubere HTML-Struktur dafür sorgen, dass Suchmaschinen die Daten auch ohne Markup sauber extrahieren konnten? Denn HTML ist Pflicht, Schema ist Kür. Aber vielleicht bin ich schon viel zu sehr in die Rationalisierungsfalle getappt... Was meinst Du?
|
|
| Neeva build a business on third party data |
Neeva schließt den Endkundenbereich. Über Neeva haben wir im Newsletter mehrfach berichtet. Neeva war angetreten, den Weg zu einer Paid-Suchmaschine anzutreten.
Jetzt konzentriert man sich auf das B2B- und Enterprise-Segment und will die Erfahrungen, Suche und Large Language Models zu kombinieren, dort einbringen.
Woran ist Neeva gescheitert?
Im Blogpost heißt es:
"But throughout this journey, we've discovered that it is one thing to build a search engine, and an entirely different thing to convince regular users of the need to switch to a better choice.
From the unnecessary friction required to change default search settings, to the challenges in helping people understand the difference between a search engine and a browser, acquiring users has been really hard.
Contrary to popular belief, convincing users to pay for a better experience was actually a less difficult problem compared to getting them to try a new search engine in the first place."
Im Kern läuft es auf 3 Probleme hinaus:
User sind nicht auf der Suche nach einer Alternative zu Google. Man muss den Menschen beibringen, dass sie eigentlich eine bessere Suche haben könnten. Das ist richtig aufwändig. LLMs kosten Geld und machen die Suche teuer. Neeva verweist darauf, dass sie günstige Varianten bauen können, aber genau das ist ein Beleg für die These. Zusätzlich ist „Die Suche mit AI" kein Alleinstellungsmerkmal mehr, wo Bing es eingebaut und Google es angekündigt hat. Neeva hat keinen eigenen Index gehabt, sondern die Ergebnisse von Bing lizenziert. Im Februar kam raus, dass die Lizenzierung der Ergebnisse von Bing massiv teurer wird.
In Kombination sind diese Probleme schwer zu lösen. Es ist schade, dass hier ein Innovator die Segel streichen muss. Es ist aber auch ein Beleg dafür, dass:
Eine Suchmaschine zu bauen komplexer ist, als viele denken. Du den Kern Deines Produktes selbst in der Hand haben und nicht von Dritten einkaufen solltest (bravo brave). Ein eigener Index es aber schwer macht, gute Ergebnisse zu liefern. Es unheimlich schwer ist, einen USP gegenüber Google aufzubauen, der auch strategisch hält.
Passenderweise hat gleichzeitig Perplexity neue Features angekündigt. Trommelwirbel: AI-Chatbot an der Seite der Ergebnisse.
Anita hat ja gerade erst eine Liste unserer Artikel zu alternativen Suchmaschinen zusammengestellt. Was meinst Du? Sollten wir die Übersicht über Google-Alternativen aktualisieren? Die Übersicht ist ja noch ohne Neeva und You.com (beispielsweise).
|
|
| Ungerechtfertigte Featured Snippets von Konkurrenten entfernen |
Wusstest Du schon, dass Du Deinen SEO-Konkurrenten zwischenzeitlich das Featured Snippet entziehen und damit vielleicht sogar deren Rankings drücken kannst?
Verrückt oder? Aber wahr.
Und so könnte es gehen:
Bei Deinen Konkurrenten nach einem Unterschied zwischen gecachtem Content und Live-Content suchen und finden (zum Beispiel über "cache:beispiel.de/beispiel-url/" in Deiner Browser-Zeile eingeben). Das Ganze via https://search.google.com/search-console/remove-outdated-content reporten. Zack: Durch das Reporting fliegt das Featured Snippet sofort raus. Die Seite bleibt vermutlich im Index, Rankings können jedoch darunter leiden. Google wird erneut crawlen und evaluieren. Sollte durch das Recrawling festgestellt werden, dass das Featured Snippet doch verdient war, wird es auch wieder auftauchen.
Google hat dazu entsprechende Informationen im Help Center hinterlegt.
In der Comment Section scheinen sich derzeit Publisher darüber zu beschweren, dass dieses Tool, das jeder öffentlich nutzen kann, missbraucht werde, sodass zum Teil sehr viele Requests gestellt werden und ihre Rankings darunter leiden.
Allerdings wirkt es auch so, als würde das Recrawling sehr zeitnah stattfinden, sodass bei ungerechtfertigten Requests der vorherige Zustand sehr schnell wieder hergestellt wird.
Selbstverständlich solltest Du diese Requests nur stellen, wenn es tatsächlich gerechtfertigt ist. Sonst: Karma-Konto im Keller!
Wenn Dir selbst sowas mal zu unrecht passieren sollte, kannst Du Dich dagegen wehren (und solltest es auch):
Dazu benötigst Du lediglich den Zugriff auf die GSC Deiner Domain und gehst auf den Removals-Bericht und dann auch den "Outdated Content"-Tab:
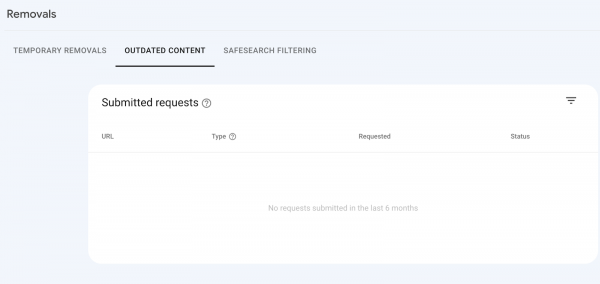 Removals-Bericht der GSC im "Outdated Content"-Tab
Removals-Bericht der GSC im "Outdated Content"-Tab
Dort kannst Du im zweiten Schritt den Request über die drei Punkte canceln, wie hier im Screenshot von Oliver Mason zu sehen:
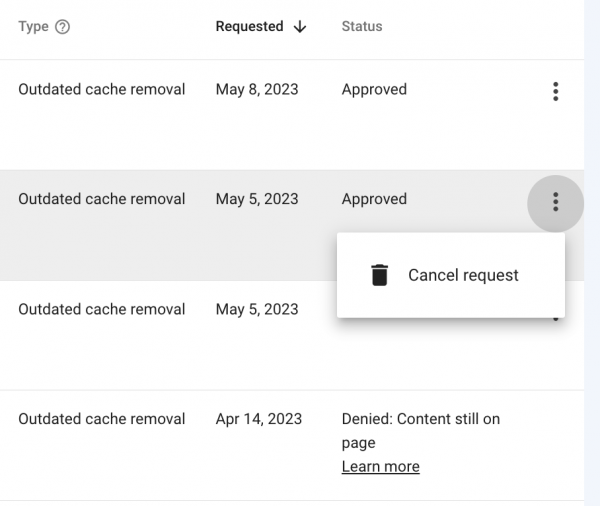 Option für das Canceling von Outdated Cache Removal Requests
Option für das Canceling von Outdated Cache Removal Requests
Google listet hier Gründe, warum ein Removal Request abgelehnt werden könnte.
Solltest Du Dich fragen, wer denn stattdessen das Featured Snippet erhalten würde, wenn Google das aktuelle Featured Snippet kickt, hilft Dir eine Negativ-Site-Search weiter:
Mit -site:beispiel.de Keyword kannst Du die Domain ausschließen, die es aktuell für ein bestimmtes Keyword inne hat. Auf der SERP dieser Site-Search kannst Du dann sehen, welche Domain stattdessen im Featured Snippet angezeigt wird.
Ein paar Tipps zur generellen Erreichung von Featured Snippet hatte Anita Dir in dieser Ausgabe mal aufgezeigt.
Ist Dir so ein solcher Outdated Cache Removal Request in Deiner Search Console schon einmal aufgefallen? Wenn ja, war es gerechtfertigt? Welche Auswirkungen konntest du beobachten?
|
|
| Inspektor Gadget wird enttarnt 🕵️ |
Bislang waren von außen die Abrufe des URL Inspection Live Tests und des Rich Result Tests der Google Search Console nicht von denen des normalen Googlebots zu unterscheiden.
Damit ist nun Schluss. Gary Illyes hat mitgeteilt, dass es einen neuen Google User Agent gibt und verweist auf den neuen Abschnitt "Google-InspectionTool" in der User Agent Dokumentation:
Statt [crawler version](compatible; Googlebot/2.1; +http://www.google.com/bot.html) heißt es für die Inspection-Tools in Zukunft [crawler version](compatible; Google-InspectionTool/1.0).
Für die meisten Domains macht das keinen großen Unterschied
Schließlich sollte der Googlebot nicht anders behandelt werden als normale Nutzer. Auch lauscht der neue User Agent in der robots.txt nicht nur auf seinen Namen (Google-InspectionTool), sondern auch auf Googlebot.
Die SEOs vieler Publisher betrifft das aber schon
Zum Beispiel, wenn:
Sie Inhalte hinter der Paywall haben, die Googlebot vollständig sehen soll. Das Consent-Banner über eine eigene URL leitet, von der der Googlebot tunlichst ausgeschlossen gehört, da er schließlich niemals den Consent akzeptieren kann.
In beiden Fällen ist das normale Crawling nicht beeinflusst, aber das Inspection Tool wird wahrscheinlich nicht mehr so behandelt, wie der reguläre Googlebot.
Für die oben genannten Beispiele bedeutet das
Technisch versierte Nutzer können sich nicht mehr über den Rich Result Test an der Paywall vorbeischleichen, sondern sehen auch dort erstmal nur noch die Paywall oder das Consent-Banner, wie hier beim Spiegel:
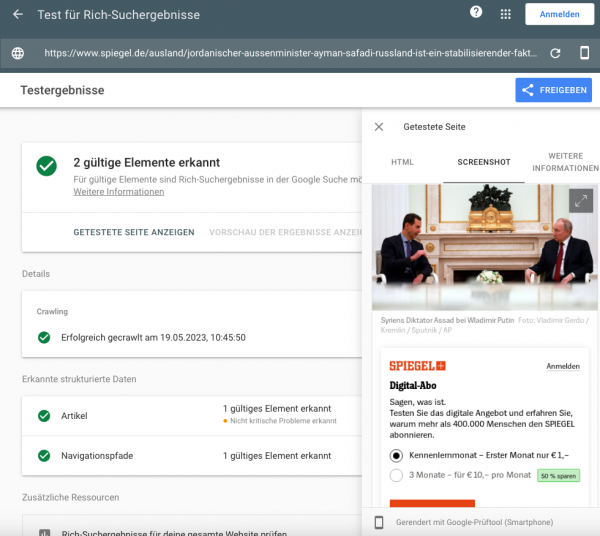 Du als SEO in der Search Console siehst im Live-Test im Zweifel nur noch das Consent-Banner.
Ersteres ist möglicherweise der Hauptgrund für diese Anpassung, auch wenn das vermutlich kein massiv genutztes Schlupfloch für Gratislesepiraten war. So oder so, wenn Deine Domain irgendwo eine Sonderbehandlung für Googlebot vorsieht, solltest Du klären, wie Du damit umgehen willst.
Möglicherweise ist es am einfachsten, den neuen User-Agent genauso zu behandeln wie Googlebot. Alternativ könntest Du vorbereiten, den Inspector kurzfristig für das Debugging freischalten zu können. Denn wenn Probleme mit Paywall, Consent oder Ähnlichem plötzlich die Indexierung der Inhalte blockieren, ist ein schnelles Debugging bares Geld wert. 🤑
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





