|
Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #103
|

|
|
🥧 Kann denn SEO Sünde sein?
|
|
Und ich sah: Ein SEO stieg aus dem Datenmeer, mit zehn Keywords und 7 Rankings und eines davon wurde visualisiert mit einem Tortendiagramm... wait WHAT?
Gut, so ein bisschen Ketzerei diesdas schön und gut, aber TORTENDIAGRAMME?
Wir sind hier doch nicht bei Track Dir was!
Du siehst schon, in dieser Woche kochen die Gemüter bei uns hoch. Nicht nur weil wir uns am kommenden Montag mal wieder in echt sehen, sondern weil in dieser Ausgabe - wie wir finden - besonders viele Denkanstöße zwischen den Zeilen für Dich und Dein SEO-Gewissen zu finden sind.
In dieser Ausgabe:
-
Serviert Saskia die Sinnhaftigkeit von Tortendiagrammen eiskalt ab
-
Kredenzt Johan Dir Google I/O Gerichte.
-
Tischt Jolle ihre Erkenntnisse zum Thema Contentüberarbeitung auf.
-
Verpflegt Anita Dich mit SEO-Paywall-Proviant.
-
Bringt Behrend ein Dessert mit den Core-Web-Vital-Neuerungen auf den Tisch.
Jetzt aber: Löffel raus, Tiramisu rausgeholt, in die Texte eingetaucht und die SEO-Süßigkeiten genossen.
Ach ja - unsere Werkstudentin Chrissi beschäftigt sich im Rahmen ihrer Bachelorarbeit mit dem Thema E-Mail Marketing.
Sie würde sich gern ein Stück von Deiner Newsletter-Torte abschneiden:
3 Minuten und 42 Sekunden kannst Du bestimmt erübrigen, um an ihrer Umfrage
teilzunehmen.
Das wäre zuckersüß. Sahnehaubenmäßig!
Und jetzt: Guten Appetit! 🥧
Deine Wingmenschen
|
|
|
Die Sache mit den Tortendiagrammen 🍰
|
|
Sie kommt ja immer mal wieder auf. Die Frage der Fragen, die zumindest als die Wingmenschen sich noch gesammelt im Büro befunden haben, für Reaktionen von einem leichten Raunen bis hin zum Kaffeetasse fallen lassen, geführt hat. Und auch jetzt kommt sie im gegenseitigen Austausch doch gelegentlich wieder auf:
"Können wir das nicht in einem Kreisdiagramm darstellen?"
...Oder die noch schönere Variante:
"Man könnte dafür doch ein Tortendiagramm verwenden?"
Die einzige Antwort auf diese Frage sollte grundsätzlich NEIN lauten. Klar, Ausnahmen bestätigen die Regel, aber in diesem Fall sind die Ausnahmen so minimal, dass sie fast nicht erwähnenswert sind. Aber fangen wir von vorne an, warum diese Frage die Wingmenschen und diverse Experten aus dem Gebiet der Verarbeitung von Daten in Rage versetzt und wir diese Frage eigentlich begraben möchten, dazu haben wir mal Argumente gesammelt.
-
Menschen sind sehr schlecht darin, Winkel einzuschätzen und entsprechend ungenau sind die Erkenntnisse, die man beim Anschauen eines Kreisdiagramms mitnimmt.
-
Ein Balkendiagramm ist immer die genauere Variante
-
Durch einen vollständigen Kreis entsteht die Illusion eines Ganzen. Rohdaten stützen diese Illusion selten.
-
Kreisdiagramme bieten keinerlei Barrierefreiheit.
-
Versucht man viele unterschiedliche Positionen darzustellen, stößt man zwangsläufig an die Grenzen der sinnhaften Darstellungsfähigkeit .
-
Ein Kreisdiagramm funktioniert häufig nur aufgrund seiner Farbgebung, allerdings haben unterschiedliche Farben die Angewohnheit, die Größenwahrnehmung der Flächen zu beeinflussen, ergo funktioniert das Kreisdiagramm doch nicht so richtig.
-
Tiefere Ebenen/Subkategorien machen das Kreisdiagramm nur noch unübersichtlicher und sorgen dafür, dass sie sich unkontrolliert potenzieren.
-
Es ist durchaus anzunehmen, dass eine Korrelation besteht zwischen absichtlicher Irreführung der Wahrnehmung von Personen, die sich ein Kreisdiagramm anschauen und der schwierigen Lesbarkeit, die Kreisdiagramme von Haus aus mitbringen. Man könnte sie also als aktive Betrugshelfer bezeichnen.
Und um auch noch den letzten Kreisdiagramm-Hardcore-Fan zu überzeugen, bitteschön, hier sehen wir ein Kreisdiagramm, wie es in der freien Wildbahn häufiger anzutreffen ist:
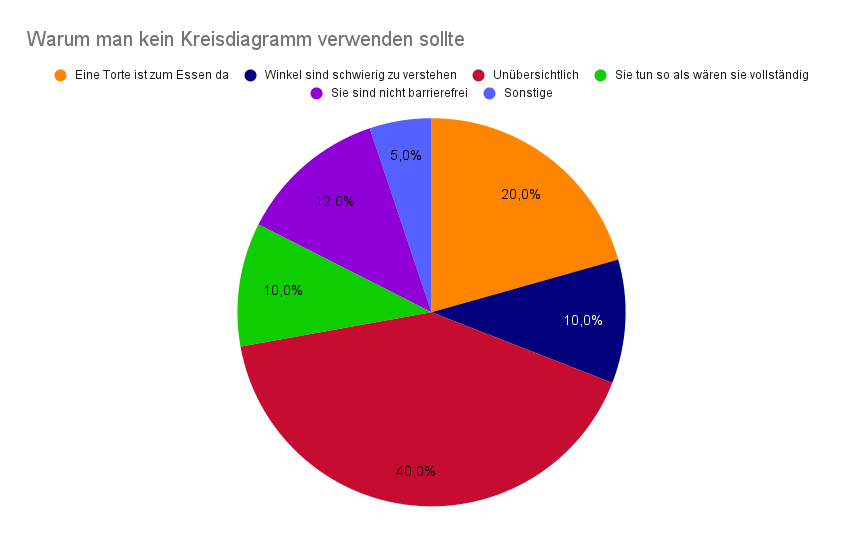
Schrecklich schön unpräzise... Oder, um es mit Johans Worten wiederzugeben: "Torten sind zum Essen da".
|
|
|
Oh, Oh, Google I/O
|
|
Irgendwie kam diese Google I/O plötzlich. Die Hardware hat mich nicht interessiert, aber aus der Software-Ecke waren spannende Dinge dabei. Hier meine persönlichen Highlights:
-
Google Workspace kriegt mehr AI. Damit können wir
Dokumente zusammenfassen lassen
und
das Ringlight ausmustern
.
-
Google Glass kommt zurück als
Echtzeit-Übersetzer
.
-
Scene Exploration klingt fancy
: Google möchte Google Lens als AR-Applikation etablieren. Beispielsweise Dir helfen, das für Dich richtige Produkt im Supermarkt zu finden. Damit das klappt, muss die Lens-Erkennung deutlich besser werden. Aber vielleicht helfen dabei die sich ändernden Blickwinkel der Kamera in dem AR-Use Case?
-
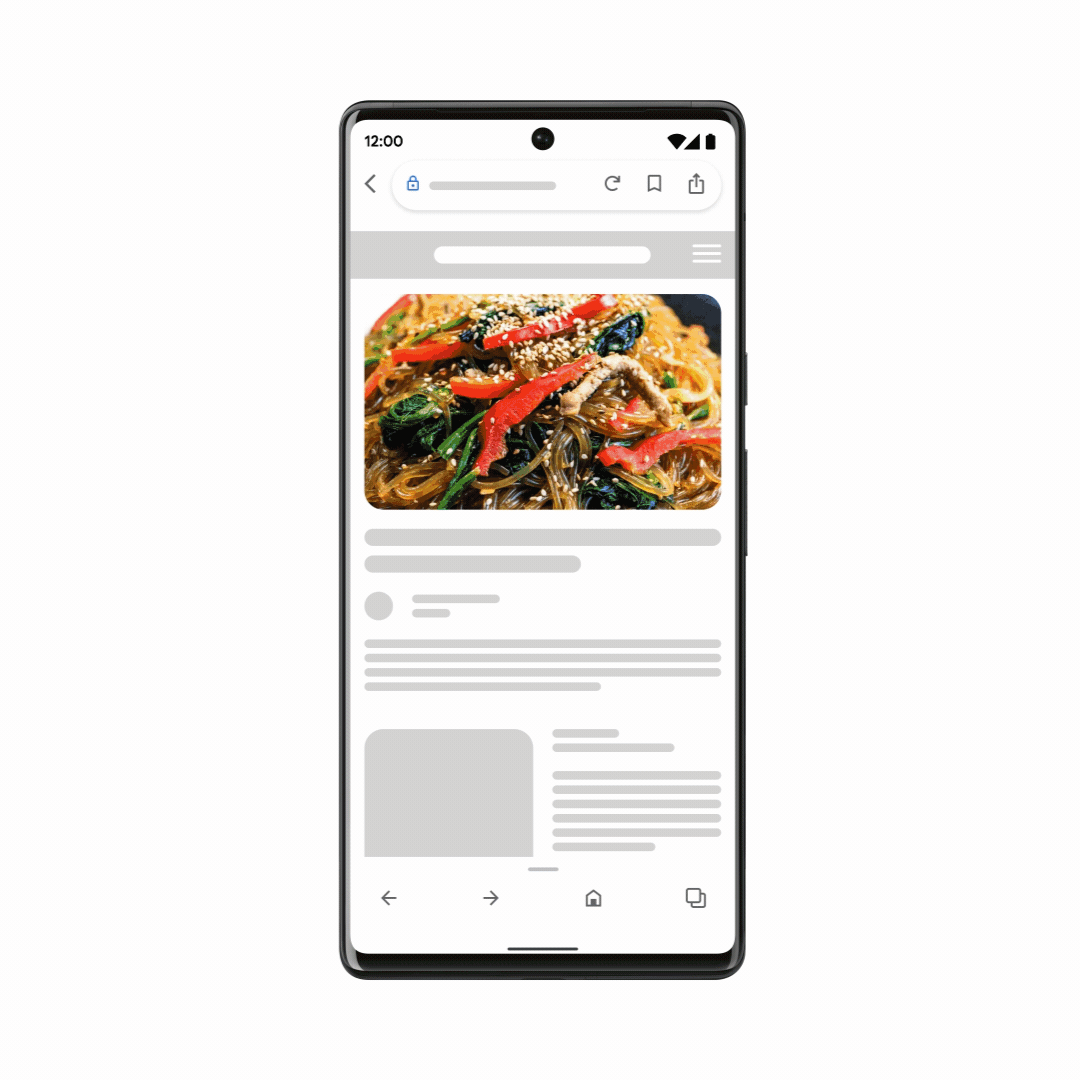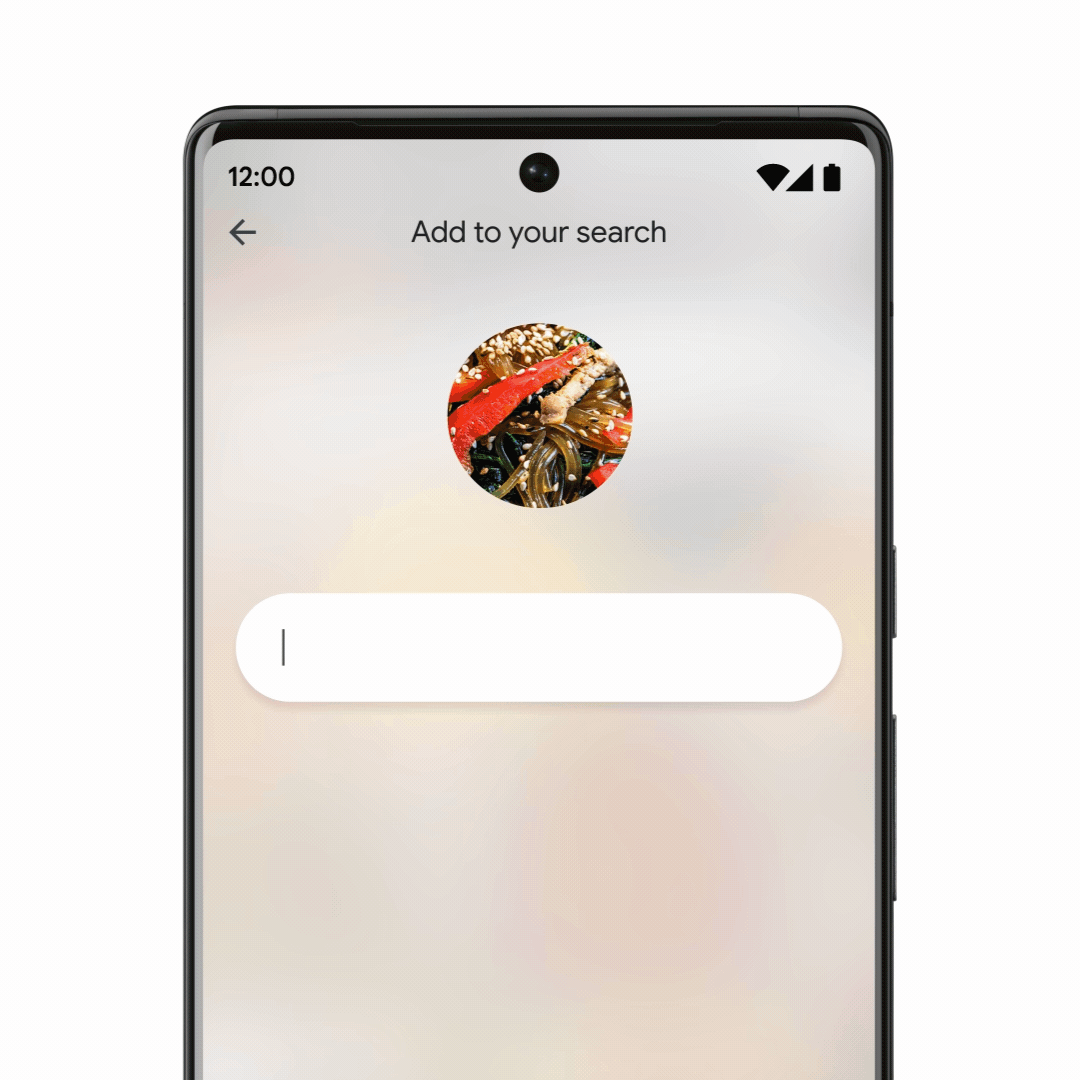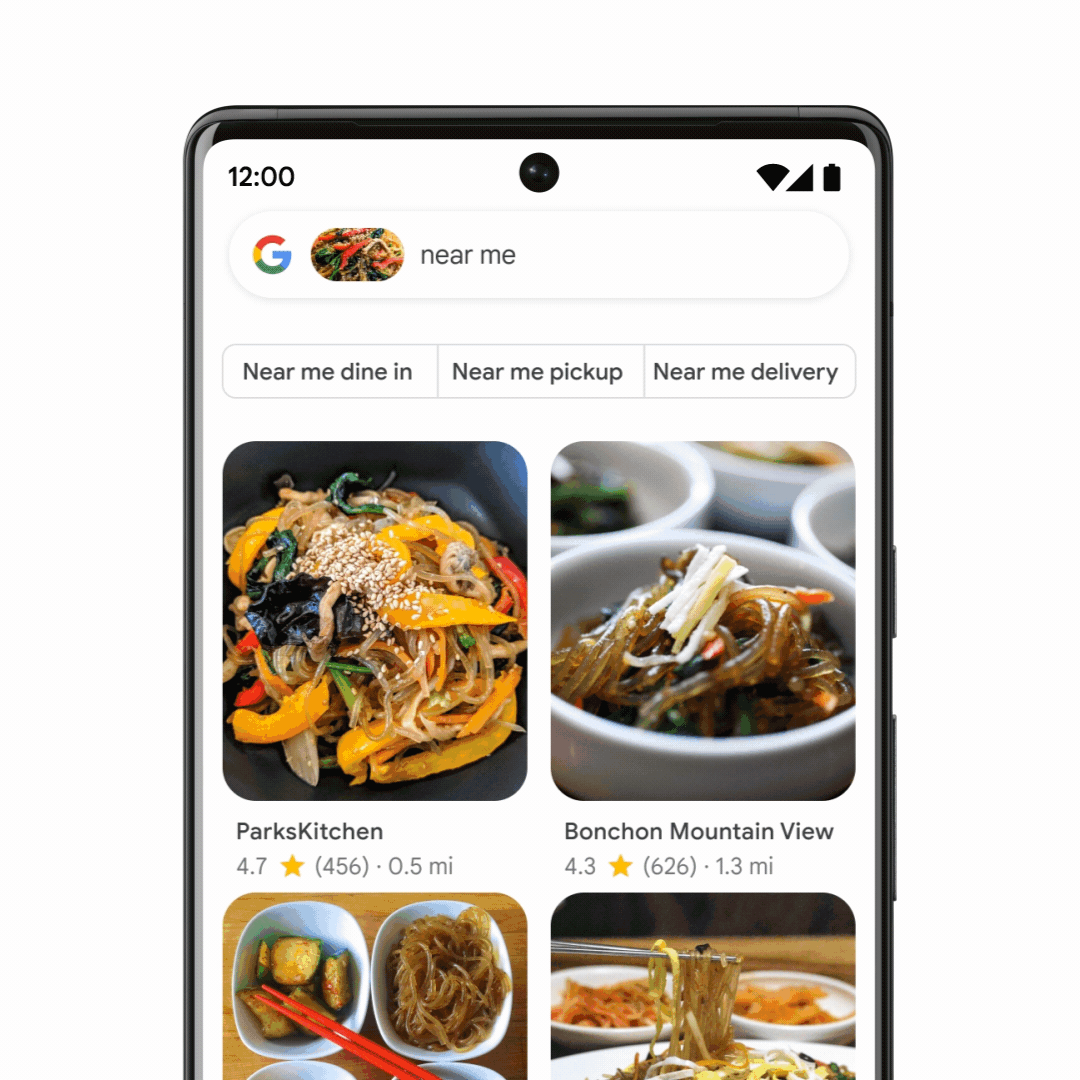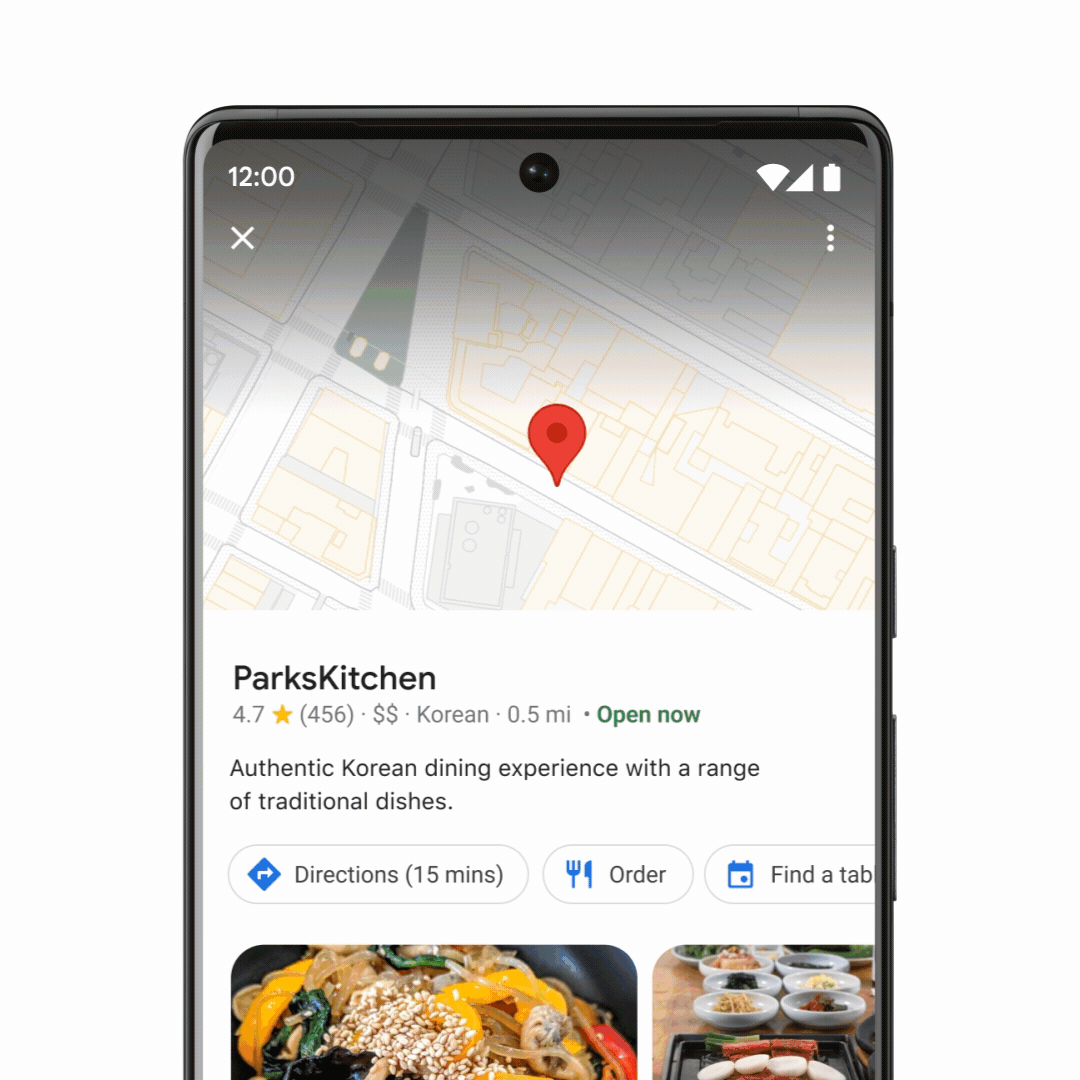
Google zeigt noch mal
Multisearch
. Jetzt mit
einem local Use Case
. Bei Multisearch geht es darum, mehrere Faktoren zu kombinieren. Beispielsweise ein Bild von einem Gericht mit der Frage, in welchem Restaurant in der Nähe man dieses Essen bestellen kann.
-
Google Wallet kommt zurück
und
Chrome kriegt virtuelle Kreditkarten
.
-
Zu Privacy gab es einige Announcements
, von denen vieles schon aus den letzten Wochen bekannt war, wie etwa
die Search Result Removals
. Neu ist das
My Ad Center, in dem User Einfluss nehmen können, welche Werbung ihnen angezeigt werden soll
. Dazu gibt es
aber direkt umfangreiche Kritik
(auf einer Seite, die mit der ganzen Werbung ganz schön auf den Akku geht.).
Auf jeden Fall gilt weiter: Regelmäßig einen Blick auf
https://adssettings.google.com/
zu haben, ist sicher sinnvoll (und interessant. Angeblich interessiere ich mich gerade für Acapulco, Katzen und Celebrities. Das ist schwer nachzuvollziehen. Dafür bin ich (laut Google Ads) zwischen 25 und 54 Jahren alt. 🎉).
-
Machine Learning für Hautfarbe wird jetzt mit 10 statt 6 Hauttönen trainiert
. Bildersuche soll Hautfarbe stärker berücksichtigen. Bilder weniger häufiger Hauttöne könnten also Rankingfaktor für die Bildersuche werden.
"One of the things we're doing is taking a set of [image] results, understanding when those results are particularly homogenous across a few set of tones, and improving the diversity of the results," Google's head of product for responsible AI, Tulsee Doshi, told The Verge. Doshi stressed, though, that these updates were in a "very early" stage of development and hadn't yet been rolled out across the company's services.
-
Für Language Models gibt es jetzt ein Test-Umfeld
, um Biases und Probleme früher zu identifizieren. Solltest Du zu den ausgewählten Köchen der AI Test Kitchen gehören, gib mir bitte unbedingt Bescheid.
Zum Einfluss der AI Test Kitchen und LAMDA2 hat theverge ein paar lesenswerte Sätze geschrieben
.
-
Google Maps bekommt jetzt
Unterstützung von Satellitenbildern
: Von Google Live StreetView 3D sind wir aber noch ein Stückchen entfernt.
Spannend sind ja nicht nur die Announcements nach dem Motto „Wir sind die dollsten Developers im Silicon Valley", sondern auch die Talks über die vielen Spezialthemen. Viele sind schöne Zusammenfassungen und immer mal gibt es auch ein paar spannende Neuigkeiten. Beispielsweise in der Keynote zum Web:
Laut Google erfüllen 65% aller URLs und 50% aller Domains die Core Web Vitals (Minute 25)
. Uff.
Ansonsten hat das
Programm der Google I/O
noch andere spannende Talks bereit:
Auch ganz interessant klangen:
Neben Google LAMDA2 als Marshmallow-Vulkan fand ich aber die Google Translate Ankündigung am spannendsten:
Google Translate kann 24 neue Sprachen. Vermutlich MUM in Action
:
"Sanskrit, used by about 20,000 people in India"
Genug Material, um Translates für 20k Menschen anzubieten. 💥
Wahrscheinlich historische Trainingsdaten, aber: WOW!
"This is also a technical milestone for Google Translate. These are the first languages we've added using Zero-Shot Machine Translation, where a machine learning model only sees monolingual text --- meaning, it learns to translate into another language without ever seeing an example."
Natürlich gab es auch unterhaltsames. Beispielsweise
die Pinball Flutter-Demo
. Jetzt ist so eine Google I/O immer ein ganz schön dickes Brett. Was sollte ich mir Deiner Meinung nach auf jeden Fall nochmal im Detail ansehen?
|
|
|
Über die Blogposts kannst Du auch noch mal rübergehn mippm Lappm🧼
|
|
Publisher und Corporate Blogs teilen ein Problem. Sie leben nach der Barney Stinson Regel Nummer 1: "New is always better".
 Quelle: theodysseyonline.com
Quelle: theodysseyonline.com
Wir brauchen Klicks, wir brauchen Augenpaare, wir brauchen einen neuen Beweis dafür, dass wir produktiv sind und deshalb brauchen wir: neuen Output! Neuen Content!
Dass wir "Die besten Eisdielen der Stadt" schon im letzten Sommer mit einer Bildergalerie präsentiert haben, hilft uns zwar beim Brainstorming, hält uns aber in der Regel nicht davon ab, das Thema in diesem Sommer unter einer weiteren URL erneut zu spielen. Leider. Denn so läuft man schnell in die
Duplicate-Content-Falle
. Besser ist es aus SEO-Sicht, man hält den Bestands-Content durch regelmäßige Updates aktuell.
Doch wieviel Aufwand muss man eigentlich betreiben, um alte Artikel aufzufrischen, so dass sie (wieder mehr) SEO-Ertrag bringen?
Travis McKnight hat diese Frage anhand des
Portent Blogs
untersucht und
aufgeschrieben
. Bestehende Blogposts wurden mit unterschiedlich viel/wenig Aufwand aufgefrischt:
-
"High-effort blog post rewrites"
umfassten eine komplett neue Keywordrecherche. Artikel wurden teilweise komplett neu geschrieben, zumindest aber Überschriften und alte Infos angepasst, Visualisierungen und neue Inhalte ergänzt und die interne Verlinkung ausgebaut.
-
Beim Mittelweg
"Medium-effort updates"
wurde neben neuem Title, Description, H1 und Einleitung genau so viel investiert, dass keine veralteten Informationen mehr enthalten waren. Der Rest des Artikels blieb gleich.
-
"Low-effort updates"
waren die reine Erneuerung des Veröffentlichungsdatums.
Das Publishing Date wurde in allen drei Fällen aktualisiert.
Anschließend hat Travis u.a. verglichen:
-
Wieviel (neue) Keywords ranken in den Top 100 und Top 10?
-
Wieviele Backlinks haben die Blogposts dazugewonnen?
-
Haben die Blogposts Featured Snippets oder sonstige spannende SERP Features bekommen?
Fokus bei den Ergebnissen lag auf den dazugewonnenen Keyword-Rankings.
Das Ergebnis?
Schon das pure Updaten des Veröffentlichungsdatum kann Erfolge aufweisen. Aufwand und Ertrag bringen beim Mittelweg die besten Ergebnisse. Die ressourcenintensive Grunderneuerung zahlt sich dagegen nicht mehr aus als der Mittelweg.
Welche Lehren Travis für seinen SEO-Ansatz daraus zieht, fasst er am Ende des Artikels zusammen.
Ich persönlich nehme Folgendes mit:
-
Die Aussagekraft von SEO-Studien sind immer begrenzt, weil sie nur selten unter Laborbedingungen stattfinden, sondern in der Wirklichkeit. Sind die drei Gruppen der Artikel wirklich miteinander vergleichbar? Wie hätten sie sich ohne redaktionelle Updates entwickelt? Wurden die Änderungen vergleichbar schnell von Google entdeckt und verarbeitet? Funktionieren die verschiedenen Update-Varianten bei allen Artikeltypen gleich gut?
-
Aber SEO findet nun mal im echten Leben statt. Genau deshalb finde ich es toll, dass Travis einen pragmatischen Ansatz gefunden hat, um seine Intuition mit der Realität abzugleichen.
-
Es gibt nun wirklich gar keine gute Ausrede mehr, die Erkenntnisse, die wir Wingmenschen im Alltag gewinnen und diskutieren, nicht auch in unsere
Wissensartikel
einfließen zu lassen, nur weil man keine Zeit für die Komplettüberarbeitung hat.
Wie gut uns das gelingen wird? Vermutlich eher so semi... Schleuder uns also gerne alles entgegen, wo wir aus Deiner Sicht nochmal drüber gehen sollten... mit dem Lappen.
|
|
|
Paywall - mal so, mal so?
|
|
Gerade wenn Du im Bereich (News-)Publishing unterwegs bist, kennst Du bestimmt
Googles Sicht auf Abo- und Paywall-Inhalte
.
Suchmaschinen haben ein Interesse, den Content hinter der Paywall zu sehen, um eine korrekte Ranking-Bewertung vornehmen zu können. Damit bekommen Suchmaschinen aber andere Inhalte ausgeliefert als die meisten User. Üblicherweise
nennt man das Cloaking
.
Mit Hilfe von JSON-LD können Publisher Google erklären, dass und vor allem welche Teile des Inhalts nicht frei zugänglich sind:
"This structured data helps Google differentiate paywalled content from the practice of cloaking, which violates our guidelines."
Denn natürlich ist es für die Bewertung und das Ranking der Inhalte relevant, eine ungefähre und im Idealfall verlässliche Idee zu haben, was da hinter der Paywall versteckt ist. Üblicherweise sieht man ja außerhalb der Bezahlschranke außer Headline, Bild und 1-2 Sätzen nicht viel, was Google als Grundlage für ein Ranking heranziehen kann.
Bing hingegen scheint da etwas lässiger zu sein und an das Gute im Menschen bzw. Publisher zu glauben. In ihrem
Best Practice Beitrag
erläutern ihr
bevorzugtes Vorgehen.
Der Bingbot soll alles sehen dürfen, ohne eine weitere Erklärung, warum hier gecloaked wird.
"The first step is to allow search engines, like Bing, to see the full content that normally resides behind a paywall or a subscription. By accessing the full content, search engines will be able to index more text which will help match more customer queries."
Wie Google empfiehlt auch Bing,
noarchive
zu verwenden, um Suchmaschinen zu verbieten, den Content aus dem Suchmaschinen-Cache anzuzeigen.
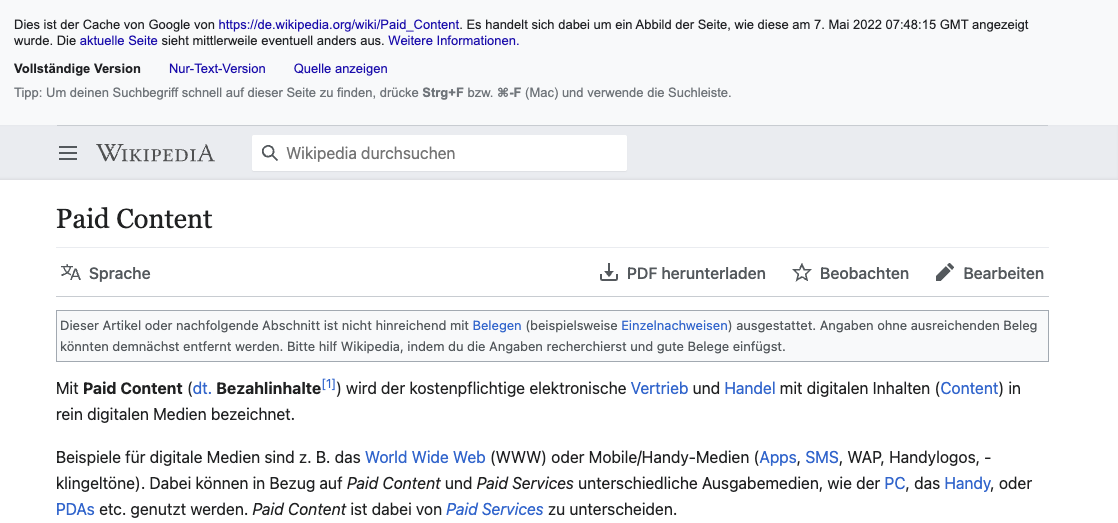
Bei Bing sieht
eine gecachte URL übrigens so aus
.
Bing erwähnt außerdem das
nocache
-Attribut für Dein Meta-Robots oder X-Robots-Tag. Von
Google wird dieses aber nicht unterstützt
:
"To prevent search engines from exposing publisher subscription-based or paywall content in search engines cache pages, publishers can control whether search engines show a cached page of a document by using a special robots meta tag in the
<head>
section of the web page or, alternatively, by using a customer HTTP response header returned to the search engines crawler for each URL."
Also sollte Dein Setup, wenn es die Richtlinien von Google erfüllt, automatisch auch für Bing passen – so lange Du noch dafür sorgst, dass der Bingbot alles sehen kann, ist alles bestens!
|
|
|
Nicht nur der erste Input zählt
|
|
PageSpeed Insights hat seit Kurzem –
genauer gesagt dem 11.05.2022
– eine neue Darstellung der Core Web Vitals. Neben der Ergänzung der Time To First Byte ist besonders auffällig, dass nun eine neue Metrik angezeigt wird:
Interaction to Next Paint oder kurz INP
.
Dass die Core Web Vitals sich weiterentwickeln, wurde von Anfang an versprochen. Dazu werden auch immer mal wieder neue Metriken diskutiert und getestet. Neuester Kandidat ist jetzt also INP. Vereinfacht ausgedrückt ist INP eine Variante des
First Input Delays (FID)
, bei der nicht nur der erste Input zählt, sondern auch die folgenden.
INP misst die Responsiveness der Seite, wobei Responsiveness in diesem Fall nichts mit der Anpassung der Darstellung auf die Viewport-Größe zu tun hat, sondern mit der Reaktion auf die Nutzerinteraktion. Es geht hier darum, wie lange es von einer Nutzerinteraktion (wie einem Klick) dauert, bis sich etwas in der Darstellung ändert. Lass Dich also nicht davon verwirren, dass hier im Englischen zufällig das gleiche Wort verwendet wird!
Noch steht in den Sternen, ob INP Teil der Core Web Vitals wird, aber für Deine Nutzer ist es schon heute schön, wenn Deine Seite auch reagiert, wenn sie zum Beispiel auf den Kaufen-Button klicken. Wenn Du also beim nächsten Blick in die
PageSpeed Insights
schlechte Werte für INP siehst, dann ist das kein Grund zur Panik, aber natürlich auch nicht zur Entspannung. Du bist in guter Gesellschaft. Schließlich kommen aktuell die großen JS Frameworks alle noch kaum auf gute INP-Werte
und google.com selbst hat auch noch Luft nach oben
.
Wenn Du dazu mehr wissen willst, hat das Team von web.dev
getestet, welche Frameworks hier besonders gut oder schlecht dastehen
. Dabei haben sie auch noch ein wenig erklärt, wo man mit dem Debugging ansetzen kann, und welche Maßnahmen die großen JS-Frameworks planen, um bessere Reaktionszeiten liefern zu können.
Die Hinweise sind natürlich recht allgemein, können aber nicht nur für INP sondern auch für die Optimierung des FID Denkanstöße geben. Und wenn das nicht reicht, dann sind wir auch gerne für Dich da 😉
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an
[email protected]
oder
ruf uns einfach kurz an:
+49 40 22868040
Bis bald,
Deine Wingmen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





