Damit Suchmaschinen eine Seite ranken können, müssen sie die Seite crawlen und verstehen. Um das Crawling betriebswirtschaftlich effizient zu gestalten geben Suchmaschinen jeder Domain nur ein gewisses Maß an Ressourcen für Crawling und Verarbeitung. Dieses Budget bemisst sich an der Prominenz einer Domain. Geht es Dir darum, eine Sitemap einzurichten, um die Userführung zu unterstützen, dann ist eine HTML-Sitemap für Dich interessant.
Verantwortest Du eine große, prominente Domain, dann benötigst Du eine XML-Sitemap zur Steuerung des Crawlers. Denn Seiten mit vielen URLs müssen mit ihren Ressourcen haushalten. Für kleine Domains ist dies in aller Regel kein Problem. Bei großen Domains, mit Hunderttausenden oder Millionen URLs, können Sitemaps Google und anderen Suchmaschinen helfen die Prioritäten beim Crawling richtig zu setzen. John Müller von Google sagt dazu (Youtube):
Gerade bei größeren Seiten macht das Sinn. Bei kleineren Websites — Ich sag mal beliebig — bei 1.000 oder 10.000 Seiten, wenn das kleiner ist, dann würde ich vielleicht auf eine Sitemap verzichten.
— John Müller, Google Webmaster Hangout 02. Juli 2015 Sitemaps selbst verbessern kein Ranking, aber sie helfen Suchmaschinen die relevanten, rankingwürdigen Inhalte zum richtigen Zeitpunkt neu zu crawlen. Je größer eine Seite ist, desto komplexer wird die Sitemap-Thematik und um so wichtiger wird es zu verstehen, welche Potenziale Sitemaps bieten, was zu beachten ist und wo Fallstricke liegen. Dieser Post soll dabei helfen.
Brauche ich eine Sitemap? Und wenn ja: Wie viele? — Ein anonymer SEO in einem komplexen Projekt
Inhalt des Artikels:
- Wann und warum brauche ich Sitemaps?
- Welche Links sollten in eine XML-/oder TXT-Sitemap aufgenommen werden?
- Was muss ich bei einer XML-Sitemap beachten?
- Sitemaps einreichen, beziehungsweise in Suchmaschinen anmelden
- Wie erstelle ich eine Sitemap?
- Wie oft sollte ich eine Sitemap aktualisieren?
- Der Sitemap-Dateiname
- Wo muss eine Sitemap gespeichert werden?
- Sitemaps und Subdomains
- HTTPs und HTTP in Sitemaps. Brauche ich separate Sitemaps?
- Die Lösung für mehrere Domains/Subdomains/Protokolle in einer Sitemap
- Welche XML-Tags sollte ich in einer XML-Sitemap angeben?
- Indexierungsmonitoring für Einzel-URLs mit XML-Sitemaps
- Sitemap-Analyse und Validierung
- XML-Sitemaps für andere Suchmaschinen
- XML-Sitemap-Fehler-Hall-Of-Fame
Wann und warum brauche ich Sitemaps?
Sitemaps sind nicht für jede Seite notwendig. In den folgenden Abschnitten findest Du Informationen, die Dir helfen zu beurteilen, ob Du Sitemaps benötigst und welche Implementierungsoptionen Du hast.
Was ist eine XML-Sitemap? Welche Vorteile bringt eine XML-Sitemap?
Eine XML-Sitemap ist ein strukturierter, maschinenlesbarer Index über alle relevanten URLs einer Seite. Dabei können zusätzliche Informationen mitgegeben werden, die Suchmaschinen helfen können die Informationen auf der Seite einzuordnen. Für überschaubare Domains mit nur wenigen Hundert oder Tausend URLs hat die Verwendung von XML-Sitemaps nur wenig Vorteile. Für Domains ab 5.000 **indexierbaren** URLs ist eine Sitemap unserer Meinung nach Pflicht. Die Verwendung von Sitemaps hilft Google das Crawling-Budget auf aktualisierte oder neue Inhalte zu konzentrieren und die indexierten Inhalte aktuell zuhalten. XML-Sitemaps bieten außerdem die Möglichkeit in der Google Search Console nachzuvollziehen wie viele URLs aus der Sitemap in den Index aufgenommen worden sind.
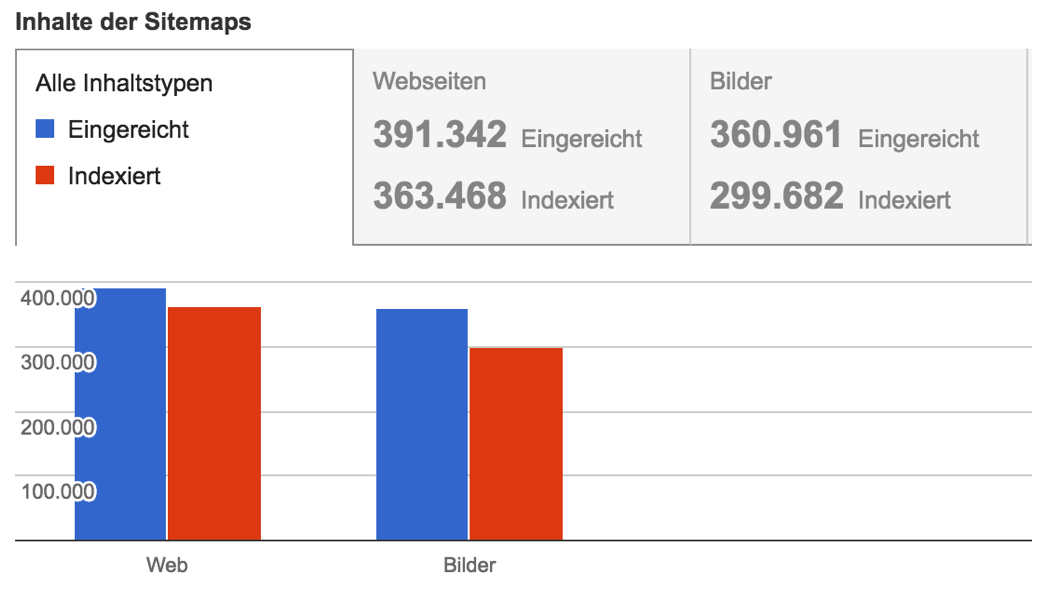
Gerade bei der Indexierung oder Deindexierung insbesondere ganzer URL-Gruppen ist diese Übersicht enorm hilfreich. Mehr dazu im Artikel ideale Sitemapstruktur planen.
Welche Links sollten in eine XML-/oder TXT-Sitemap aufgenommen werden?
In eine Sitemap sollten nur URLs aufgenommen werden, die indexiert werden sollen, also den folgenden Kriterien entsprechen:
- Vollqualifizierte URL inklusive Protokoll (http/https), Subdomain (sofern vorhanden), Domain und der komplette Pfad der URL
- HTTP-Status der URL sollte 200 sein
- Meta-Robots-Tag: index, follow oder nicht gesetzt
- X-Robots-Tag: index, follow oder nicht gesetzt
- Canonical-Tag auf sich selbst oder nicht vorhanden
- X-Canonical-Tag auf sich selbst oder nicht vorhanden
- URL ist nicht durch die Robots.txt gesperrt.
Ausnahme von der Regel sind natürlich Spezial-Sitemaps zum schnelleren Crawling von Weiterleitungen oder zur Deindexierung von Inhalten.
Was muss ich bei einer XML-Sitemap beachten?
XML-Sitemaps folgen den Vorgaben auf http://www.sitemaps.org/protocol.html. Zusammengefasst musst Du auf Folgendes achten:
- Maximal 50.000 URLs pro XML-Sitemap (Ausnahme News-Sitemap)
- Maximal 50MB entpackte Dateigröße pro Sitemap (gerade bei umfangreichen Bilder- oder Hreflang-Sitemaps kann das ein Problem werden)
- Maximal 2.048 Zeichen pro URL (Zugegeben, wer das Limit überschreitet hat neben der Crawlability auch andere Probleme)
- XML-Steuerungszeichen müssen HTML-Entity-escaped werden:
- “&” → “
&“ - ”‘” → “
'“ - ”“” → “
"“ - ”>” → “
>“ - ”<” → “
<“
- “&” → “
- UTF-8. Die Datei selbst sollte als UTF-8 codiert sein
- Umlaute und Sonderzeichen können URL-encoded werden. Google akzeptiert aber auch UTF-8 URLs, sofern die oben genannten Steuerungszeichen entity-escaped sind
- Werden Sonderformate wie News oder Bilder verwendet dann müssen die entsprechenden idspaces referenziert werden
Spätestens bei Überschreitung der Größenlimits (50.000 URLs, 50MB) sollten die Inhalte in mehrere Sitemaps aufgesplittet werden. Zum vereinfachten Management mehrerer Sitemaps gibt es die Möglichkeit eine Indexsitemap zu verwenden.
Sitemaps einreichen, beziehungsweise in Suchmaschinen anmelden
Es gibt verschiedene Methoden, um Sitemaps bei Suchmaschinen anzumelden. Jede Suchmaschine bietet in ihren Webmaster Tools eine Möglichkeit eine Sitemap anzumelden. Bei Google sieht das folgendermaßen aus:
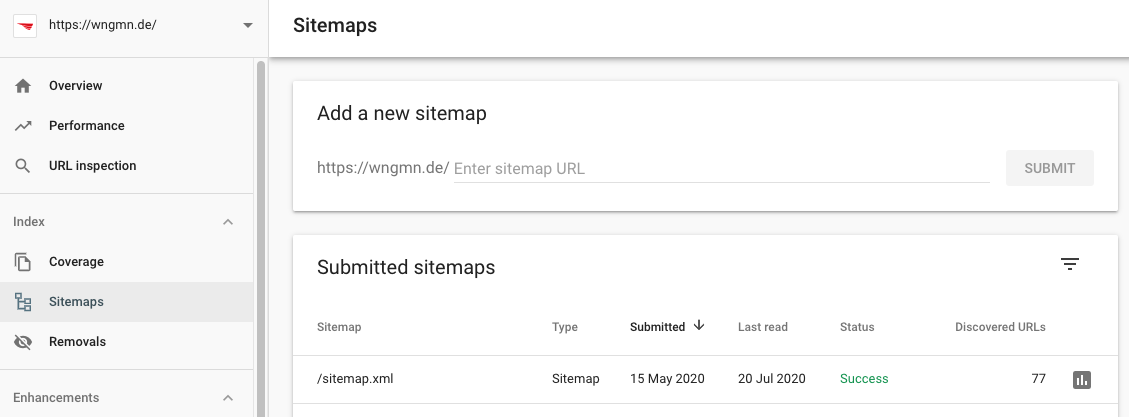 Einfach den URL-Pfad angeben unter der die Sitemap liegt, das war's.
Einfach den URL-Pfad angeben unter der die Sitemap liegt, das war's.
Muss eine Sitemap bei jeder Aktualisierung neu eingereicht werden?
Kurze Antwort: Nein. Lange Antwort: Eine Neu-Einreichung ist nicht erforderlich. Wird eine Index-Sitemap verwendet, sollte allerdings das Last-Modified-Datum der Sitemap mit Änderungen in der Index-Sitemap aktualisiert werden. Wird eine neue Sitemap erstellt und nicht in einer bereits eingereichten oder in der Robots.txt referenzierten Index-Sitemap gelistet, so muss diese natürlich eingereicht werden.
Aktualisierung einer Sitemap an Google melden
Eine Aktualisierung der Sitemap kann händisch an Google gemeldet werden, indem die Sitemap in der Search Console erneut eingereicht wird. Eine automatische Meldung ist ebenfalls möglich, indem ein GET-Request an
_http://google.com/ping?sitemap=http://www.example.com/my\_sitemap.xml_geschickt wird. Damit wird der Googlebot beauftragt die Sitemap erneut zu holen. Diese Meldung sollte natürlich nur vorgenommen werden, wenn die Sitemap auch wirklich neue Informationen enthält.
Sitemap in der Robots.txt referenzieren
Einfacher ist allerdings das Referenzieren der Master-/Index-Sitemap aus der Robots.txt. Hierzu wird in der Robots.txt eine Zeile mit _Sitemap: http://example.com/master\_sitemap.xml_ angegeben. In der Robots.txt können prinzipiell auch mehrere Sitemaps referenziert werden. Ist eine Master-/Index-Sitemap verfügbar, ist dies meist allerdings nicht notwendig. Achtung: Manche Unternehmen legen Wert darauf, dass ihre Sitemaps nicht durch Jedermann eingesehen werden können. Gerade im News-Bereich machen die News-Sitemaps es möglich Republishing-Strategien und Veröffentlichungsfrequenzen einfach zu analysieren. In einem solchen Fall ist ein Referenzieren der Sitemaps in der Robots.txt kontraproduktiv, da durch jeden einsehbar.
Eine Master-/Index-Sitemap dient der Organisation mehrerer Sitemaps. Für besonders große Seiten empfehlen wir die Verwendung einer Index-Sitemap. Hier findest Du weiterführende Informationen zum Anlegen von mehreren Sitemaps und speziell zur Index-Sitemap.
Muss eine Sitemap indexierbar sein?
Nein, eine Sitemap muss nicht im Google-Index auftauchen. Wichtig ist, dass Google die Sitemaps crawlen darf. Die Sitemap darf also nicht durch die Robots.txt gesperrt sein. Häufig kommt Google selbst auf die Idee, dass die Sitemap für Nutzer nicht relevant ist. Wenn Du die Indexierung verhindern möchtest, empfiehlt es sich die Sitemaps mit dem X-Robots-Tag im Dateiheader von der Indexierung auszuschließen:
_HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT (…) X-Robots-Tag: noindex_Wie erstelle ich eine Sitemap?
Grundsätzlich sollte eine Sitemap nur in Ausnahmefällen manuell erstellt werden (beispielsweise bei Relaunches, NoIndex-Sitemaps, etc.). Für jedes Content-Management-System gibt es mehr oder weniger sinnvolle Lösungen out of the box. Bei komplexen Setups empfiehlt es sich aber auf eine komplette Eigenentwicklung zu setzen.
Sitemap Generator | Sitemap-generator aus URL-Liste
Der einfachste Weg eine Sitemap schnell zu generieren dürfte die Verwendung des Screaming Frog SEO Spiders sein. Crawling anwerfen, URLs filtern und im Reiter Sitemaps die Kriterien wählen. Allerdings ist das natürlich nur etwas für statische Seitenbereiche oder Einmalaktionen, kein Ersatz für eine hilfreiche Sitemap-Struktur. In der Regel gibt es für alle gängigen CM-Systeme entsprechende Plugins, die die automatische Erstellung oder Aktualisierung Deiner Sitemap übernehmen.
Wie kann ich eine Sitemap entfernen?
Soll eine Sitemap wieder entfernt werden, ist der erste Schritt die Löschung der Sitemap-Datei. Gleichzeitig sollte die Datei nicht mehr in der Index-Sitemap referenziert werden. Ist die Sitemap-Datei auch in der Robots.txt referenziert, ist auch diese Referenz zu entfernen.
Wie oft sollte ich eine Sitemap aktualisieren?
Eine Sitemap sollte immer aktualisiert werden, wenn sich an den in ihr referenzierten Inhalten etwas ändert. Entsprechende Änderungen können sein:
- Bisher in der Sitemap referenzierte URLs erfüllen nicht mehr die zur Aufnahme notwendigen Kriterien und werden gelöscht.
- Neue URLs wurden in die Sitemap aufgenommen.
- Inhalte der URLs, die bisher in der Sitemap standen wurden aktualisiert und das Last-Modified-Tag muss aktualisiert werden.
- Das HTML-Template der referenzierten URLs wurde deutlich überarbeitet und daher wird das Last-Modified-Tag in der Sitemap aktualisiert.
Sitemaps (abgesehen von News-Sitemaps) müssen dabei nicht den sekundengenauen Status abbilden. In der Regel ist dies technisch schwer umsetzbar. Es empfiehlt sich allerdings die Sitemaps täglich einmal neu zu generieren. Bei großen Systemen kann es auch praktikabel sein Sitemaps mit Inhalten, die sich selten ändern in noch größeren Abständen zu generieren.
Der Sitemap-Dateiname
Es gibt keine besonderen Anforderungen an den Dateinamen, außer dass die Namen sich nicht mit jeder Aktualisierung ändern sollten (beispielsweise durch einen Timestamp). Es hat sich aber bewährt die Funktion der Sitemap im Dateinamen anzugeben. Zusätzlich sollte ein Index enthalten sein, der darüber informiert, dass dies nicht die einzige Sitemap dieses Typs ist, sondern die Inhalte auf mehrere Sitemaps verteilt wurden. Ein simples Dateinamenkonzept könnte also etwa so aussehen:
- master_sitemap.xml
- index_sitemap_index_01.xml
- default_sitemap_produkte_index_01.xml
- default_sitemap_produkte_index_02.xml
- default_sitemap_kategorien_index_01.xml
- images_sitemap_produkte_index_01.xml
- images_sitemap_produkte_index_02.xml
- images_sitemap_produkte_index_03.xml
- images_sitemap_produkte_index_04.xml
Das System folgt folgendem Aufbau:
- _default__sitemap_produkte_index_01.xml Typ der Sitemap: Handelt es sich um eine Index-Sitemap, eine Standardsitemap, oder eine Sitemap, die Bilder- und/oder Videos integriert. Übersicht der verschiedenen Sitemap-Typen
- defaultsitemapprodukte_index_01.xml Sitemap, um noch mal deutlich zu machen, dass diese Datei eine Sitemap ist. Kann natürlich entfallen, ist aber ein wenig abhängig davon, wo die Sitemap abgelegt wird. Werden die Sitemaps im Root-Verzeichnis angelegt, dann können Dateien leicht identifiziert werden. Noch wichtiger wird dies, wenn beispielsweise txt-Sitemaps genutzt werden, da in dem Verzeichnis auch weitere txt-Dateien liegen könnten.
- default_sitemapprodukteindex_01.xml Welche Inhalte werden in der Sitemap referenziert (Templates, Produkte, etc.)
- default_sitemap_produkteindex01.xml Welche Funktion erfüllt die Sitemap (Indexierung, De-Indexierung, Weiterleitung, Neue URLs)
- default_sitemap_produkte_index_01.xml laufender Index: Die wie vielte Sitemap nach diesem Schema ist dies.
- default_sitemap_produkte_index01.xml_ Das Dateiformat: In aller Regel .xml. Es gibt aber auch andere mögliche Formate.
Ausnahme davon ist die Master-Sitemap, die alle Index-Sitemaps steuert. Prinzipiell ist es auch möglich die Index-Sitemaps in Kategorien zu unterteilen. Häufig ist dies aber Aufwand, der nicht notwendig ist. Dieses System ist kein allgemeiner Standard, aber eine Konvention, die wir unseren Kunden gern zur Übersichtlichkeit empfehlen.
Wo muss eine Sitemap gespeichert werden?
XML-Sitemaps sollten im Root-Verzeichnis der Domain liegen. So ist sichergestellt, dass alle Suchmaschinen und Systeme, die Sitemaps verwenden die angegebenen URLs auch crawlen. Der Sitemap-Standard sagt, dass eine Sitemap nur Dateien referenzieren kann, die im selben Verzeichnis oder einem Unterverzeichnis liegen. Wenn also www.example.com/sitemaps/sitemap.xml als Speicherort gewählt würde, dann dürften nur URLs angegeben werden, die unterhalb von www.example.com/sitemaps/ liegen. Google ist hier liberaler und akzeptiert durchaus Referenzen von Unterordnern auf andere Ordner. Wie immer bist Du auf der sicheren Seite, wenn Du dem Standard folgst. Daher empfehlen wir weiterhin das Ablegen der Sitemaps im Root-Folder /www-root.
Sitemaps und Subdomains
Wie für jede (projektierte, relevante) Subdomain eine eigene Robots.txt angelegt werden muss, muss auch für jede Subdomain ein eigenes Sitemap-System aufgebaut werden, wenn Du dem Standard folgen möchtest. Google akzeptiert auch hier Abweichungen. Da Sitemaps aber auch anderen Suchmaschinen helfen sollen, empfiehlt es sich für jede Subdomain ein eigenes System aufzubauen.
HTTPs und HTTP in Sitemaps. Brauche ich separate Sitemaps?
Wie für Ordner und Subdomains gilt auch für Sitemaps, dass nur URLs referenziert werden dürfen, die dem selben Protokoll folgen. Wir empfehlen grundsätzlich alle URLs einer Domain über HTTPs zu referenzieren, dann ist auch bei Sitemaps kein weiterer Sitemap-Kreis notwendig. Für Weiterleitungs-Sitemaps im Rahmen einer Umstellung von HTTP auf HTTPs ist das Referenzieren von HTTP-URLs aus einer HTTPs-Sitemap ausreichend. Auch für die Protokolle gilt: Google legt den Sitemap-Standard vergleichsweise liberal aus.
Die Lösung für mehrere Domains/Subdomains/Protokolle in einer Sitemap
Der Sitemap-Standard erlaubt sogenannte Cross-Submits. Das heißt, dass eine Sitemap URLs auf einer anderen Domain referenzieren darf, sofern die robots.txt dieser Domain auf die Sitemap verweist. Sollen etwa URLs der folgenden Domains aus einer Sitemap referenziert werden, dann könnte das Setup wie folgt aussehen:
Sitemap liegt unter http://s3.amazonaws.com/meine_index_sitemap.xml Dann müssten folgende Robots.txts vorhanden sein und mit “Sitemap: http://s3.amazonaws.com/meine_index_sitemap.xml” auf die Zentral-Sitemap verweisen:
- http://www.domain1.de/robots.txt
- https://www.domain1.de/robots.txt
- http://xyz.domain1.de/robots.txt
- http://www.domain2.de/robots.txt
Dieses Vorgehen wird von Bing, Google und Yandex unterstützt.
Aufbau einer XML-Sitemap
Eine XML-Sitemap besteht aus einer einleitenden Zeile, die Informationen über die XML-Datei (XML-Version, Dateicodierung) enthält:
<?xml version="1.0" encoding="UTF-8"?>Als nächstes wird das urlset-Tag geöffnet, dass spezifische Informationen darüber enthält, welcher Typ von Sitemap hier angelegt wird. Für eine Standard-Sitemap lautet diese Zeile:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">Unterhalb des <urlset>-Tags können jetzt die einzelnen URLs angegeben werden. Die einfache Angabe einer URL wird dabei in einen <url>-Tag gefasst, wobei die URL selbst als <loc> (für Location) angegeben wird.
<url>
<loc>http://www.example.com/url.html</loc>
</url>Innerhalb des URL-Tags können auch weitere Informationen zur URL mitgegeben werden. Häufigster Fall für diese Möglichkeit ist die Angabe der letzten Modifikation der URL, beziehungsweise des Inhalts der URL:
<url>
<loc>http://www.example.com/url2.html</loc>
<lastmod>2005-01-01</lastmod>
</url>Am Ende muss das urlset noch geschlossen werden.
</urlset>Wenn wir beispielsweise Bilder in die Sitemap mit aufnehmen wollen, dann sehen die notwendigen Namespace-Angaben in der urlset-Zeile wie folgt aus:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1">Damit wird der zusätzliche Namespace “image” angelegt, womit wir für die einzelnen URLs auch eingebundene SEO-relevante Bilder angeben können. Wenn wir für unsere URL2 aus dem Beispiel oben zusätzlich Bilder referenzieren würden, dann würde das so aussehen:
<url>
<loc>http://example.com/url2.html</loc>
<lastmod>2005-01-01</lastmod>
<image:image>
<image:loc>http://example.com/image.png</image:loc>
</image:image>
</url>Natürlich kann auch das image-Tag weitere Informationen bekommen. Du siehst deutlich die image:-Syntax, die darauf hinweist, dass hier Image-spezifische Elemente aus dem Image-Namespace referenziert werden:
<url>
<loc>http://example.com/url2.html</loc>
<lastmod>2005-01-01</lastmod>
<image:image>
<image:loc>http://example.com/image.png</image:loc>
<image:caption>Toller Untertitel für ein fantastisches Beispielbild.</image:caption>
</image:image>
</url>Natürlich können wir für eine URL auch mehrere Bilder (bis zu 1.000 Bilder pro <loc>-Tag) hinterlegen:
<url>
<loc>http://example.com/url2.html</loc>
<lastmod>2005-01-01</lastmod>
<image:image>
<image:loc>http://example.com/image.png</image:loc>
<image:caption>Toller Untertitel für ein fantastisches Beispielbild.</image:caption>
</image:image>
<image:image>
<image:loc>http://example.com/image2.png</image:loc>
<image:caption>Beispie-Untertitel für ein weiteres Beispielbild.</image:caption>
</image:image>
</url>Welche XML-Tags sollte ich in einer XML-Sitemap angeben?
In den oberen Beispielen haben wir schon verschiedene Attribute zu URLs hinzugefügt. Neben dem Pflicht-Tag
- lastmod: Datum der letzten Änderung an der URL. Wingmen empfiehlt dieses Attribut immer zu setzen. Eine korrekte Angabe erleichtert es Suchmaschinenbots Dokumente vor allem dann zu crawlen, wenn es Änderungen gab. Damit wird Crawlingbudget effizienter eingesetzt.
- changefreq: Häufigkeit der Änderung (mögliche Werte: always, hourly, daily, weekly, monthly, yearly, never). Wingmen empfiehlt dieses Attribut nicht zu verwenden. Aufwand einer korrekten Implementierung steht selten im Verhältnis zum zusätzlichen Nutzen.
- priority: Interne Priorität des Dokuments (wird von Google ignoriert). Wingmen empfiehlt dieses Attribut nicht zu setzen.
Du magst gelegentlich hören, dass Du Keywords oder Titles mit in Sitemaps angeben könntest. Das ist in der Standard-Sitemap nicht der Fall.
Hinweise zum Lastmod-Tag-Datumsformat:
Wann sollte das Datum des Lastmod-Tags angepasst werden?
Das <lastmod>-Tag ermöglicht die Angabe der letzten Änderung eines Dokuments. Wir empfehlen den Wert dieses Tags immer dann anzupassen, wenn Änderungen am Hauptcontent der Seite vorgenommen worden sind (auch kleine Änderungen, wie Title-Anpassung, Rechtschreibkorrektur, Anpassung interner Links aus dem Artikel), oder wenn im größeren Umfang am HTML-Template der Seite gearbeitet wurde.
Wie muss das Datum im Lastmod-Tag ausgezeichnet werden?
Die Datumsangabe des Lastmod-Tags muss den Vorgaben des w3c zu Datumsangaben folgen.
Angabe des Lastmod nur mit einem Datum
<url>
<loc>http://example.com</loc>
<lastmod>2042-01-01</lastmod>
</url>Angabe des Lastmod mit Datum und Uhrzeit
Minimal sollte der Tag angegeben werden (Format: YYYY-MM-DD). Bei Inhalten, die besonders häufig Änderungen unterliegen, oder News-Charakter haben, kann zusätzlich die Uhrzeit angegeben werden. Bei der Angabe der Uhrzeit können Sekunden und Millisekunden entfallen. Die Angabe der Uhrzeit erfolgt dabei in 24 Stunden, nicht a.m. / p.m. Achtung: Die Zeitangabe kann entweder in UTC erfolgen (dann endet die Zeitangabe mit einem großen ‘Z’), oder als Lokalzeit mit einer Angabe zur Abweichung von UTC in +hh:mm oder -hh:mm. Wenn die Verwendung von Lokalzeit genutzt wird, muss die Abweichung von UTC bei jeder Sommer-/Winterzeitumstellung korrigiert werden. Angabe des Timestamps als UTC
<url>
<loc>http://example.com</loc>
<lastmod>2042-01-01T08:09:10Z</lastmod>
</url>Angabe des Timestamps als Lokalzeit Berlin (Winterzeit)
<url>
<loc>http://example.com</loc>
<lastmod>2042-01-01T07:09:10+01:00</lastmod>
</url>Angabe des Timestamps als Lokalzeit Berlin (Sommerzeit)
<url>
<loc>http://example.com</loc>
<lastmod>2042-01-01T07:09:10+02:00</lastmod>
</url>Wer noch etwas tiefer in die Schwierigkeit von Zeitangaben in Computersystemen einsteigen will, dem sei dieses Video empfohlen: https://www.youtube.com/watch?v=-5wpm-gesOY
Was Du noch über das XML-Sitemap-Format wissen solltest
Damit Google eine XML-Sitemap korrekt einlesen kann, sollte das Dokument im XML-Format samt XML-Tags vorliegen.
Wichtig ist, dass es dabei nicht darauf ankommt, wie eine XML-Sitemap im gerenderten Zustand im Browser aussieht. Für eine schickere Darstellung im Browser werden immer mal wieder XSL Style Sheets im Sitemap-Dokument hinterlegt, sodass es wie ein HTML dargestellt werden kann und auf den ersten Blick gar nicht wie eine XML-Sitemap im XML-Format aussieht:
Lass Dich davon nicht irritieren, denn Google versteht, dass bei einem XML-Format das Dokument nicht gerendert werden soll. Wenn Du also mal auf anders aussehende XML-Sitemaps stößt, dann prüfe immer erst einmal den Quellcode! Triffst du dann auf das XML-Sitemap-Format ist alles gut und Google versteht dann auch, dass es sich um eine Sitemap handelt.
Fun Fact: Manchmal liegt diese andere Darstellung einer XML-Sitemap auch an einem XML-Lese-Plugin in Deinem Browser oder an einem Browser, der nativ XML lesen kann.
Indexierungsmonitoring für Einzel-URLs mit XML-Sitemaps
Sebastian Erlhofer gibt den Tipp, für jede URL eine eigene Sitemap anzulegen, um die Indexierung auf URL-Basis zu überwachen. Für kleinere Seiten ist das eine Möglichkeit. Bei größeren Seiten kannst Du diesen Ansatz aber nicht ohne Weiteres übernehmen, da sonst die Anzahl der zu crawlenden Sitemaps zu viel Crawl-Budget aufbrauchen könnte.
Sitemap-Analyse und Validierung
Der XML-Standard ist strikt. Entsprechend wichtig ist die korrekte Validierung der XML-Sitemaps. Die einfachste Variante zur Validierung von Sitemaps ist das Testen der Sitemap-Validität mit der Google Search Console. Dazu muss die Sitemap bereits auf dem eigenen Server hochgeladen sein. Etwas komplexer, aber in aufwändigen Setups sinnvoll, ist das eigene Testen mit Hilfe von XML-Schema-Definitions (XSD). Dabei wird ein XML-Parser mit den korrekten möglichen Tags und Attributen gefüttert und die Datei getestet, ob diese Werte auch eingehalten werden.
Wingmen Sitemap-Checkliste
Validierung des XML
XML-Dateien lassen sich mit XML-Schema (XSD) validieren. Dafür muss die entsprechende Schema-Datei in der XML-referenziert werden. Danach kann ein Parser die Sitemap auf Entsprechung dieser Kriterien überprüfen. Zur Validierung des XMLs von XML-Sitemaps können folgende XSDs genutzt werden:
- Standard-Sitemap: http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd
- Index-Sitemaps: http://www.sitemaps.org/schemas/sitemap/0.9/siteindex.xsd
- Sitemaps mit Bildern: http://www.google.com/schemas/sitemap-image/1.1/sitemap-image.xsd
- Sitemaps mit Videos: http://www.google.com/schemas/sitemap-video/1.1/sitemap-video.xsd
- Sitemaps für Feature Phones: http://www.google.com/schemas/sitemap-mobile/1.0/sitemap-mobile.xsd
- Google News Sitemaps: http://www.google.com/schemas/sitemap-news/0.9/sitemap-news.xsd
- HREFLANG-Sitemaps: https://www.w3.org/2002/08/xhtml/xhtml1-strict.xsd
Mit Hilfe der XSDs wird geprüft, ob nur angegebene Felder referenziert werden und ob die angegebenen Werte der Tags den Anforderungen entsprechen (etwa korrektes Datumsformat). Zusätzlich sollten alle Sitemap Dateien geprüft werden auf:
- Korrektes UTF-8
- Korrektes Entity-Escaping
- Maximal 50.000
<loc>-Tags - Maximal 50MB (unkomprimiert)
Für Google News Sitemaps:
- Maximal 1.000
<loc>-Tags
Validierung des XML-Inhalts
Sind diese Kriterien erfüllt, sollten die inhaltlichen Kriterien für jede angegebene URL geprüft werden (auch für Bilder oder Videos):
- URL
- Enthält Protokoll, Subdomain, Domain, Top-Level-Domain und Pfad (validiert nach RFC-3986 und RFC 3987)
- Ist nicht durch die Robots.txt vom Crawling gesperrt
- HTTP-Header
- Status-Code ist 200 (Ausnahme: Deindexierungs- / Weiterleitungssitemaps)
- Location nicht gesetzt (Ausnahme: Weiterleitungssitemaps)
- X-Robots-Noindex ist nicht gesetzt, oder “index”
- X-Canonical nicht gesetzt, oder zeigt auf die exakt gleiche URL
- HTML
<link rel="canonical" href="">zeigt auf sich sich selbst (exakt gleiche URL) oder nicht angegeben<meta name="robots" content="">steht auf Index, oder ist nicht angegeben (Ausnahme: Deindexierungssitemap)
Für Google News-Sitemaps: Das <news:publication_date> sollte nicht älter als 48 Stunden sein. Für HREFLANG-Sitemaps: Weitere Sprachangaben der referenzierten URL sollten den Angaben im HREFLANG nicht widersprechen. Etwa lang-Attribute oder HTTP-Language-Header oder HTTP-Equiv-Angaben im HTML.
Google Search Console Validierung
Sind die XML-Dateien hochgeladen, können die Dateien in der Google Search Console geprüft werden: https://www.google.com/webmasters/tools/sitemap-list Dabei wird allerdings nur die Korrektheit des XMLs geprüft. Nicht, ob die angegebenen URLs auch wirklich in der Sitemap enthalten sein sollten.
Online Checker
Es gibt Online-Checker für Sitemaps, denen häufig eine Datei hochgeladen werden kann, oder sogar das XML per Copy/Paste eingefügt werden kann. Hast Du nur eine einfache Standard-Sitemap und legst keinen Wert auf die Prüfung des Sitemap-Inhalts, kann ein solcher Check hilfreich sein. Wir sind allerdings keine großen Fans davon. Zusätzlich gibt es einige Broken-Link-Checker. Wir empfehlen allerdings die URLs aus dem XML zu extrahieren und mit einem Crawling (beispielsweise mit dem Screaming Frog SEO Spider) zu validieren.
URL-Extraction | Extrahieren von URLs aus XML
Um URLs aus XML-Dateien zu extrahieren gibt es verschiedene Methoden. Die Einfachste dürfte sein die Sitemap herunterzuladen und in den Screaming Frog SEO Spider zu laden.
XML-Sitemaps für andere Suchmaschinen
Google ist (Ketzerei!) nicht die einzige Suchmaschine da draußen und auch andere benötigen Unterstützung.
Sitemaps für Bing
Bing unterstützt die Standard-XML-Sitemap und das Google-Image-Format. Sofern also keine Videos in den Sitemaps referenziert sind, sollte Bing keinerlei Probleme haben die XML-Sitemaps, die Google validiert auch korrekt zu verarbeiten. Bing hat zusätzlich ein eigenes erweitertes Bilder-Sitemap-Format. Wenn ich viele, ansprechende Bilder habe und damit relevanten Traffic ziehen kann, dann kann es sich lohnen eine spezielle Bing-Sitemap mit Bildern bereit zu stellen. Diese Bildersitemaps ermöglichen sehr ausführliche Angaben zu einem Bild mitzugeben. Beispielsweise Ratings, Copyright-Inhaber, Kommentare und Nutzerinteraktionen, sowie Thumbnails. Das Format ist ein bisschen speziell, aber bei vielen, attraktiven Bildern und einer Zielgruppe, die auch auf Bing unterwegs ist, kann sich der Aufwand einer Entwicklung für dieses Format lohnen: https://www.bing.com/webmaster/help/image-feed-specification-0573ecfd Bing versteht auch TXT-Sitemaps.
Sitemaps einreichen bei Bing
Der einfachste Weg Bing über eine Sitemap zu benachrichtigen ist die Sitemap-Referenzierung in der Robots.txt. Die Sitemap kann aber auch in den Bing-Webmaster Tools angemeldet werden. Bing bietet auch die Möglichkeit einen Ping an Bing zu schicken, wenn eine Sitemap neu erstellt oder aktualisiert wurde: http://www.bing.com/ping?sitemap=http%3A%2F%2Fwww.example.com/sitemap.xml.
Sitemaps für Yandex
Yandex versteht die Standard-Sitemaps. Allerdings nicht die Bilder-Erweiterungen. Yandex versteht auch TXT-Sitemaps. Ebenfalls können Sitemaps über die Robots.txt referenziert werden. Auch Yandex ermöglicht eine Anmeldung in deren Webmaster Tools. Für Yandex scheinen Priority- und Frequency-Tags nicht irrelevant zu sein, sofern sie angegeben sind. Wir vertrauen aber weiter auf eine konsistente Angabe des Lastmod-Tags. Yandex unterstützt außerdem Cross-Submits für Sitemaps. Das heißt, dass eine Sitemap auf einer anderen Domain (example2.com) liegen und URLs von example1.com angeben kann, sofern example1.com die Sitemap-URL auf example2.com referenziert. Mehr dazu auf Sitemaps.org
Sitemaps für Baidu
Baidu versteht Sitemaps ebenfalls. Allerdings scheint die Einreichung von Sitemaps noch ein private beta-Feature zu sein: https://chineseseoshifu.com/blog/submit-urls-to-baidu-in-style.html das scheint auch schon seit mehreren Jahren so zu sein: http://webmasters.stackexchange.com/questions/59851/how-to-submit-sitemap-to-baidu
XML-Sitemap-Fehler-Hall-Of-Fame
Wie wir gesehen haben, sind Sitemaps durchaus komplex. Hier die Fehler, die uns am Häufigsten in der Beratung aufgefallen sind:
- Nicht qualifizierte URLs aufgenommen: URLs, die nicht indexiert werden sollen, in der Sitemap referenziert
- Relative URLs referenziert: Sitemaps funktionieren nur mit absoluten Pfaden
- UTF-8: Datei nicht UTF-8 kodiert
- XML nicht valide: Insbesondere die Verwendung von Attributen, die im Namespace nicht vorgesehen sind
- Falsche Timestamps (Bonus: Sommer- und Winterzeit)
- Sitemap durch Robots.txt gesperrt
- Sitemaps werden nicht aktualisiert
- Sitemaps werden angelegt, aber nicht in die Index-Sitemap aufgenommen, Suchmaschinen bekommen sie also nicht zu sehen
- URL mit relativem Pfad in Robots.txt angegeben
- URL auf anderen Domains angegeben, ohne dass diese mit der Robots.txt zurückverweist.
- Fehlerhafte .gz-Komprimierung