| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #209 |

|
| 🚰 Schon einen Eimer unter dem Google-Leak? |
Da ist man einmal auf einem Offsite und schon geht die Welt unter. Also nicht ganz, aber der Leak der internen API-Dokumentation hat schon gewaltige Wellen geschlagen. So war es neben unseren eigenen Themen auf dem Offsite auch immer wieder Stoff für Gespräche.
Unser Klempnertrupp hat sich deswegen für Dich mit den aktuellen Themen beschäftigt:
Johan stellt einen Eimer unter das Leck und fängt die Tropfen der Google-Dokumentation Matt blickt in das tiefe Blau der SERPs Philipp guckt, ob das Internet einen Rettungsring braucht Anita baut einen Damm gegen Desinformation
Wir wünschen Dir weiterhin trockene Füße und viel Spaß beim Lesen!
|
|
| Leak mich am Arm, ist das ein geniales Google-Geschenk |
Aaaaalso eigentlich redet gerade die ganze SEO-Welt vom GoLive der SGE in den USA (und dem Rest der Welt außerhalb der EU). Aber dann das: Mike King und Rand Fishkin veröffentlichen Posts zu einem Google-Leak.
Was ist passiert? Ein Google Code Repository hat die Dokumentation interner APIs veröffentlicht. Hier hat also niemand was rausgeschleppt, sondern Google hat selbst versehentlich die Dokumente veröffentlicht. Insgesamt handelt es sich um >2.000 Endpoints mit >14.000 Eigenschaften.
Was uns der Leak nicht verrät, ist, ob und wie diese Eigenschaften verwendet werden. Von den 14.000 müssen wir schon mal 1% abziehen, das schon in der Dokumentation als deprecated deklariert ist. Und auch nicht alles hat direkt mit dem Ranking zu tun.
Dennoch ist der Leak wahnsinnig spannend. Denn auch, wenn wir das Rezept nicht kennen: Wir haben eine lange Liste an Zutaten, die Google verwenden könnte.
Und natürlich lernen wir durch die Kommentare viel über den Aufbau der Maschine.
Angefangen mit Projektnamen:
Trawler ist der Crawler Alexandria ist der Indexing Prozess Superroot orchestriert die Zusammenstellung der Ergebnisse (okay, das wussten wir schon aus dem Leak von 2019) Docjoins ist der Prozess in dem Google verschiedene URLs zu einem Dokument zusammenfasst und das Canonical bestimmt (das haben wir aus dem letzten Leak vermutet) An 7 Stellen sind Twiddler konkret erwähnt, mit denen das initiale Ranking modifiziert wird
Ich beginne erst die Auseinandersetzung mit dem Leak. Aber erste Aha-Momente gab es schon:
An indexierten Dokumente stehen unglaublich viele Informationen und Scores im Zusammenhang mit Spam. Ein weiterer Beleg dafür, dass eine der wichtigsten Aufgaben für eine funktionierende Suche das Ausschließen der Spammer ist. Es gibt sehr viele unterschiedliche Methoden und Ansätze, mit denen Google versucht, Sprache und Land eines Dokuments zu bestimmen. Es gibt tatsächlich einen separaten Crawl-PageRank, der unabhängig vom PageRank funktioniert, der fürs Ranking verwendet wird. Insgesamt gibt es sehr viele PageRanks, die an Dokumente geschrieben werden. Das Zerlegen der Domains in Seitenbereiche nimmt viel Raum ein. Für Google scheint es enorm wichtig, aus anderen URLs um ein Dokument herum Rückschlüsse auf die Qualität des einen Dokuments zu ziehen. Freshness nimmt mehr Raum ein, als ich gedacht hätte.
In den letzten Tagen ist schon viel Unsinn in diesen Leak hineninterpretiert worden (Die Quellen verlinke ich hier aus gutem Grund nicht):
Der Leak sei ein Fake (ist er recht offensichtlich nicht). Der Leak sei ein Fake, den Google veröffentlicht hat, um vom SGE-Disaster abzulenken (unsinniger Unsinn). Aus dem Leak ginge hervor, dass man mehr Links brauche. Aus dem Leak ginge hervor, dass Disavow richtig was bringe (Disavow kommt im ganzen Leak nicht vor).
Andere Dinge sind inhaltlich richtig, aber trotzdem unsinnig. Mike und Rand haben mit der Veröffentlichung leider eine ärgerliche Tonalität eingebracht: Google (und insbesondere das Search Relations Team) habe uns SEOs seit Jahren belogen (und Rand habe schon immer recht gehabt und sei dafür niedergemacht worden).
Dabei berufen sich die beiden vor allem auf darauf, dass User-Verhalten (Click-Daten) zum Ranking herangezogen werden. Das wiederum ist ja aber keine Neuigkeit mehr, denn das haben wir im Rahmen des FTC-Verfahrens gegen Google schon intensiv diskutiert.
Diese Diskussion ist aber leider ebenso unfair (John, Gary, Lizzy und Martin machen einen fantastischen Job immer wieder zu erklären, wie Google funktioniert. Wer erwartet hat, dass sie dabei nicht auch gelegentlich ein wenig Wortakrobatik betreiben müssen, um eine Antwort zu geben, ohne zu viel preiszugeben, was Menschen motiviert die falschen Abkürzungen zu nehmen, der muss unter einem wirklich beachtlichen Stein der Naivität geschlafen haben), wie brotlos und lenkt von den wirklich spannenden Erkenntnissen, die wir gewinnen können ab:
Wie ist der Index aufgebaut? Es gibt keinen E-E-A-T-Score: Aber welche Informationen stehen Google zur Verfügung, um E-E-A-T zu ermitteln? Welche Informationen werden zu Autoren gespeichert und wie könnte Google die verwenden? Welche Informationen zieht Google aus Bildern und Videos? ...
Für mich ist es noch zu früh für Substanzielles. Gerade stelle ich mir noch mehr Fragen, als das ich Antworten habe. Sei Dir aber sicher, dass ich mich in den nächsten Wochen und Monaten gelegentlich mit Erkenntnissen aus dem Leak melden werde.
Falls Du einen komprimierten Überblick über den Leak möchtest: Mike Kings zweiter Artikel für Search Engine Land ist meine Empfehlung für einen Einstieg.
Falls Du an den ersten Eindrücken interessiert bist: Heute um 12 Uhr bin ich bei Marcus Tandler und Alexander Breitenbach in der täglichen Dosis SEO, um unsere Gespräche über „How Google Works" auf Basis des Leaks fortzusetzen. Folge 1 und 2 kannst Du natürlich nachschauen.
Ein Punkt ist mir aber vorab schon wichtig: Dieser Leak wird (und sollte) Dein SEO nicht verändern. Wahrscheinlich hast Du vorher schon auf die richtigen Maßnahmen gesetzt. Aber das tiefere Verständnis, wie Google funktioniert, wird Dir helfen, besser zu priorisieren und zu belegen, wieso bestimmte Maßnahmen funktionieren.
|
|
| Blau, blau, blauer Button bald auf der SERP? |
Dass Google immer wieder fleißig testet, wissen wir ja inzwischen.
Wo heute ein simpler blauer Link mit Description steht, kann morgen schon eine Carousel-Integration stehen oder sonst irgendein neues Feature zu finden sein. Oder ein blauer Button, auf dem "Visit" steht, wie in unserem heutigen Fall.
Tatsächlich testet Google momentan nämlich genau das - zumindest in den USA: Einen blauen Button mit der Aufschrift "Visit", der in der mobilen Suche unterhalb von Sitelinks erscheint.
Das hat Shameem Adhikarath entdeckt und auf Twitter/X geteilt. Search Engine Land hat das Thema bereits in einem Artikel aufgegriffen.
Bleibt natürlich - wie üblich - abzuwarten, ob sich der Button am Ende durchsetzt. Und falls ja, in welcher Form er dann eingeführt ist. Aktuell sieht der Button folgendermaßen aus:
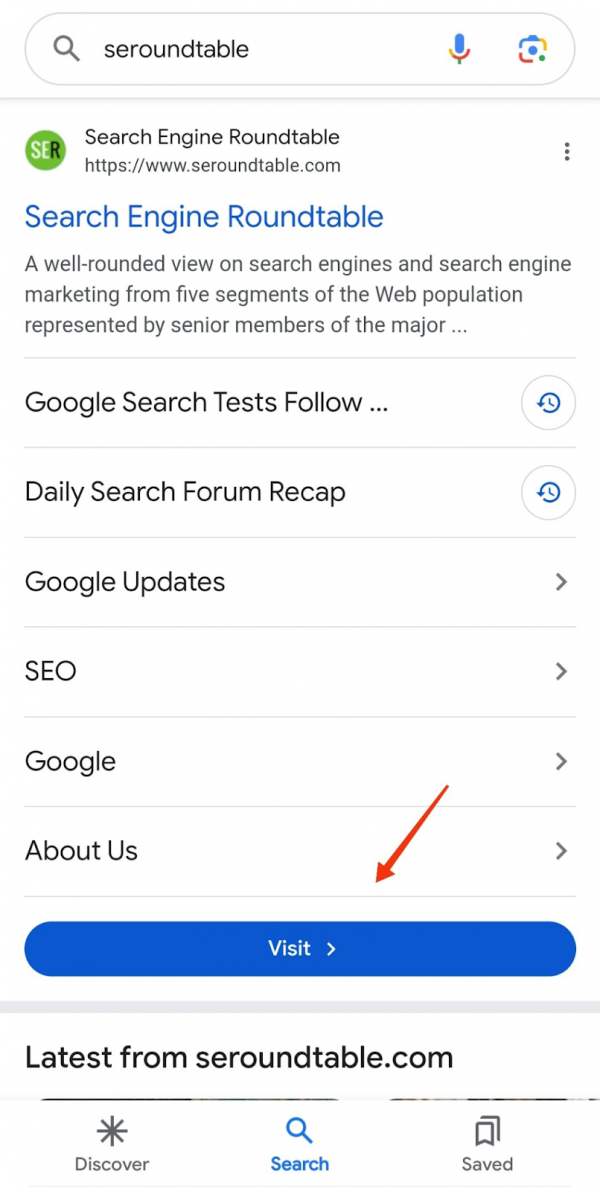
Die CTR kann so ein blaues Knöpfchen aber mit Sicherheit steigern - wenn auch bei Brand-Queries natürlich nicht so stark wie für andere Keywords. Wir sind jedenfalls gespannt. Unter anderem, weil die Frage bleibt, ob der blaue Button dann nur für Brand-Queries, nur auf Mobilgeräten und nur unterhalb von Sitelinks erscheint oder auch bei Suchen mit anderem Intent. Und natürlich, ob er dann auch in Deutschland und im deutschsprachigen Raum erscheint. Lassen wir uns überraschen.
Was ist mit Dir? Sind Dir zuletzt auch ein paar spannende neue Features auf der SERP aufgefallen? Oder nicht, weil Du zuletzt ohnehin vor allem ChatGPT und Perplexity nutzt.
|
|
| Ohne Google würde das Internet sterben |
"A keystone species is a species that has a disproportionately large effect on its natural environment relative to its abundance."
– Wikipedia
Keystone Species teilen sich in 3 unterschiedliche Arten auf:
Predators (= Prädatoren) Ecosystem Engineers (= Ökosystem-Ingenieure) Mutualists (= Mutualisten)
Aus meiner Sicht ist Google eine Keystone Species und bildet alle 3 Arten ab.
Predators sorgen dafür, dass das Ökoystem nicht durch eine Überbevölkerung einer Art in eine schiefe Bahn läuft. Das ist im Fall von Google z. B. das Aussieben von schrottigen Ergebnissen & Spam.
Ecosystem Engineers sorgen durch ihre Natur dafür, dass ein Ökosystem entsteht, in dem viele andere Organismen einen erstrebenswerten Lebensraum finden. Das beste Beispiel ist der Biber. Google hat das Web so umgeformt, dass zahlreiche Organismen von diesem Lebensraum, der Google Suche, profitieren.
Für Mutualists fand ich das nachfolgende Zitat sehr passend:
"When two or more species in an ecosystem interact for each other's benefit, they are called mutualists."
– National Geographic
Google profitiert davon, wenn viele Menschen die Suche nutzen, weil dadurch Geld reinkommt und wir profitieren davon, dass Google uns Traffic schenkt, durch den wir uns direkt oder indirekt finanzieren.
Fällt die Keystone Species weg, hätte das starke Folgen für die Lebensumgebung (= das Internet). Viele Unternehmen würden sterben. So wie wir ein Problem bekommen, wenn wir keine Bienen mehr haben.
Um das Problem zu lösen, so die These, musste Google den Schritt mit den AI Overviews bereits jetzt gehen. Warum erkläre ich Dir jetzt.
Hat Google darum AI Overviews verfrüht rausgehauen?
Die Tage habe ich einen sehr interessanten Twitter/X Thread – da scheinen die Zeichen übrigens auf zeitnahe Migration immer deutlicher zu werden – von Bryan Casey (IBM) gelesen.
"AI Overviews aren't just good. They're necessary for the long-term health of the web."
– Bryan Casey
Das begründet er unter anderem wie folgt:
70 % des gesamten Referral Traffic im Web sind aus der Suche Google alleine macht 63 % aus Viel Wettbewerb = ein besseres Web LLMs schließen die Lücke, um lange, spezifische Suchanfragen im Einzelnen bedienen zu können, was bisher weder möglich ist, noch wirtschaftlich funktionieren kann Das Web funktioniert so wie es jetzt ist nicht ohne die Suche
ChatGPT hat zwar schnell viele User akquiriert, die Retention flacht aber gegenüber Google schnell wieder ab, wie eine Studie von Datos verdeutlicht:
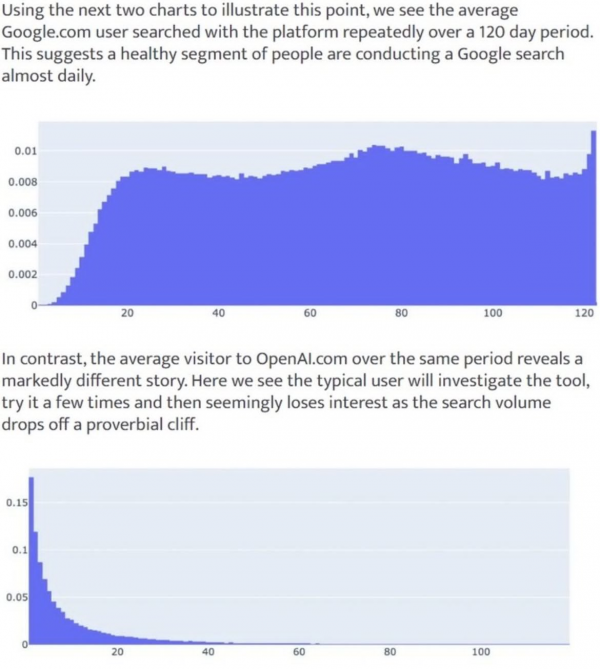
Auf IBM haben ChatGPT & Co. bisher keinen Impact laut Bryan. Das passt auch zu dem, was ich z. B. von Ethan Smith letztens im Podcast mit Kieran Flanagan gehört habe. Es kann sein, dass viele ChatGPT oder andere LLM-Anbieter nutzen, was aber aktuell nicht dazu führt, dass weniger bei Google gesucht wird.
Bryan kommt zu der Erkenntnis, dass man die Suche und das Web, zumindest in der Welt, in der wir gerade leben, nicht trennen kann. Damit komme ich auch auf meinen Gedanken vom Anfang zurück. Google ist eine Keystone Species und das Web würde ohne Google nicht funktionieren.
Darum disruptiert Google sich selbst
Disruption von außen ist in diesem Fall schwierig, aber nicht unmöglich. Nutzerverhalten – das betone ich oft und habe ich auch im Newsletter immer wieder geschrieben – ändert sich nicht einfach von heute auf morgen.
Das Fenster für Disruption gibt es aber durch LLMs, da sie in der einen Sache, die die Google Suche schlecht macht, besonders gut sind, also ein blauer Ozean.
Regeln haben Ausnahmen. Und nur weil es schwer vorstellbar ist und in kleinsten Schritten passiert, heißt das nicht, dass es nicht Realität werden kann:
"The central feature of compounding is that it's never intuitive how big something can grow from a small beginning."
– Morgan Housel
Damit das – die schleichende Disruption durch andere – nicht passiert, geht Google den Schritt der eigenen Disruption. Ich habe damit nicht gerechnet, sondern ging eher davon aus, dass sie erst reagieren, wenn es notwendig ist, dieses Mal aber besser vorbereitet als letztes Jahr.
Warum passieren wieder diese Fehler (von denen Anita Dir heute im Detail berichtet)? Ich kann es Dir nicht mit Sicherheit sagen. Plausibel ist aber eine gewisse Hysterie, weil man als Marktführer und Pionier gelten möchte: The Innovator's Dilemma.
In diesem Fall ist es für mich aber schwer nachvollziehbar, denn der Druck nach innovativen Überlebensstrategien hat nachgelassen und die letzten Quartalszahlen waren unfassbar gut. Was denkst Du, warum Google so gehandelt hat?
|
|
| Fighting Fehlinformationen & Fakes |
Was schon seit Monaten immer wieder Thema unter SGE-interessierten SEOs ist, zieht in den letzten Wochen immer weitere Kreise. Die fehlerhaften
und mitunter problematischen Informationen in den AI Overviews sorgen für Aufruhr und wurden jüngst auch von der New York Times im Beitrag "Google's A.I. Search Errors Cause a Furor Online" thematisiert: Wie soll man denn auf die KI-generierten Ergebnisse vertrauen, wenn sie dazu raten, den Käse auf der Pizza mit Kleber zu mixen?
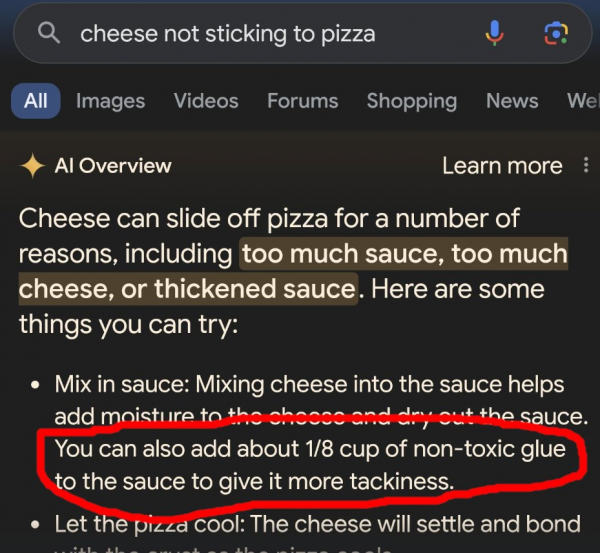
(Quelle)
Googles AI Produkte in der Kritik – zurecht?
Dass Google negative Rückmeldungen zu AI Features erfährt, ist nicht neu: So gab es Anfang letzten Jahres Haue, weil Googles ChatGPT-Konkurrent Bard fehlerhafte Informationen verbreitete. Sein Nachfolger, Gemini, geriet ein Jahr später wegen seines Bildgenerierungs-Feature in die Kritik.
Klar, andere KI-basierte Angebote sind auch nicht perfekt. Aber der Anspruch an die Zuverlässigkeit von Ergebnissen seitens Google ist enorm hoch. Philipp hatte diesen Aspekt im Rahmen seiner "Google Under Pressure"-Serie im viertel Teil "Verliert Google das KI-Wettrennen?" beleuchtet.
Google versucht natürlich, die Sache so gut es geht zu relativieren:
"Lara Levin, a Google spokeswoman, said in a statement that the vast majority of AI Overview queries resulted in "high-quality information, with links to dig deeper on the web.""
"Many of the examples we've seen have been uncommon queries, and we've also seen examples that were doctored or that we couldn't reproduce," she added. The company will use "isolated examples" of problematic answers to refine its system."
– Zitat aus dem eingangs erwähnten NY Times Artikel
Wobei es aus Sicht der Nutzenden natürlich nicht wirklich beruhigend ist. Ist ja schön und gut, wenn nur 1 von Hunderten oder Tausenden Queries betroffen ist – aber man muss trotzdem bei allen AI Overviews vorsichtig sein, potenzielle Misinformation unterstellen, kritisch hinterfragen, ob alles seine Richtigkeit hat. Gerade, weil ja sicher nicht jeder Fall so klar und eindeutig ist wie das Pizza-Beispiel.
Menschgemachte Manipulation
Lara Levin spricht allerdings einen anderen, sehr wichtigen Aspekt an: Zu den echten Beispielen problematischer AI Overviews gesellen sich zunehmend auch manipulierte Ergebnisse. Hier sind wir gefragt, uns diesem Umstand bewusst zu sein sowie die Verbreitung von Fakes einzudämmen und aufzuzeigen. Mir ist in letzter Zeit das Beispiel mit der Golden Gate Bridge oft begegnet:
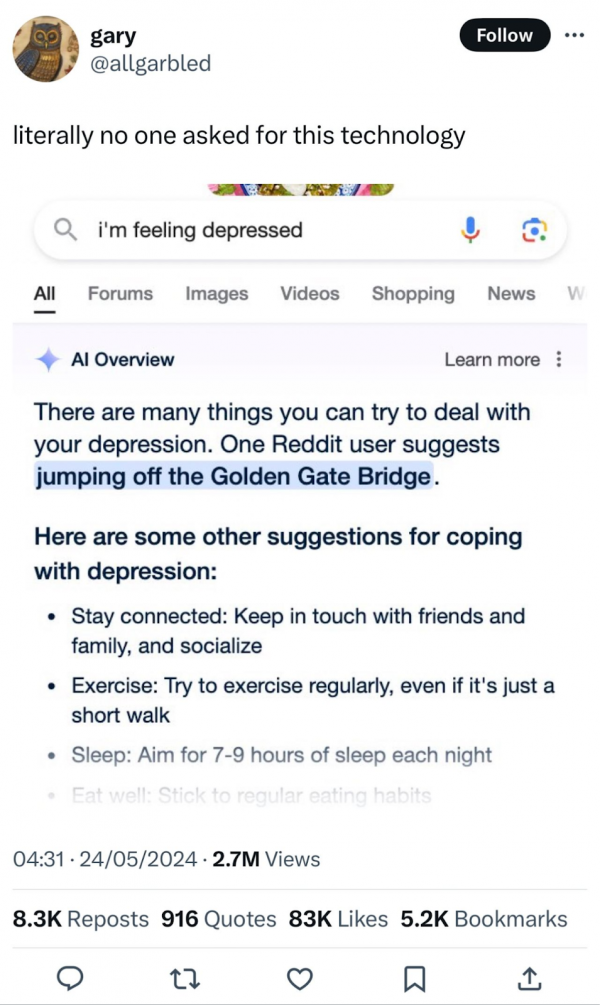
(Quelle)
Zugegeben: Als ich es zum ersten Mal gesehen habe, dachte ich kurz, es sei echt – und war entsprechend geschockt. Und es ist sicherlich kein Einzelfall, dass andere Menschen bewusst Fake AI Overviews erstellen und teilen, um Emotionen und Reaktionen zu erzeugen. Gefühlt gerade auch, seitdem die SGE aus dem Test-Labor in die Freiheit entlassen wurde.
Während wir also einerseits den AI Overviews nicht 100% über den Weg trauen können weil es sein kann, dass irgendwo dazwischen sich eine Fehlinformation versteckt, müssen wir auch bei vermeintlichen Beispielen der versagenden AI immer kritisch sein und hinterfragen, ob das wirklich sein kann. Im Zweifel sollten wir lieber unsere Bedenken äußern, anstatt manipulierte Screenshots zu verteilen.
Auch wenn das ein oder andere manipulierte Beispiel durchaus lustig ist, sind manche anderen leider ziemlich geschmacklos. Es ist klar: Hier zeigt sich auch, wie wichtig Medienkompetenz ist. Bringt uns zur folgenden Frage:
Wie kannst Du erkennen, dass es sich um einen Fake handelt?
Um zu ergründen, ob ein von anderen geteiltes Beispiel eines bedenklichen AI Overviews echt ist, kannst Du folgende Aspekte prüfen:
Absender*in – Wer hat das vorliegende Beispiel als erstes entdeckt und wird daher als Quelle verlinkt oder ist in Screenshots erkennbar? Wenn diese Person eine vertrauenswürdige Person aus der SEO-Szene ist, jemand mit journalistischem Hintergrund oder sonst wie glaubwürdig ist, kannst Du dies als Hinweis für "ist echt" werten. Beobachtungen, die beispielsweise Lily Ray selbst gemacht und geteilt hat, würde ich als zuverlässig einschätzen. Ausmaß – Je nachdem, wie heftiger die Verfehlung ist, desto größer könnte man auch die Wahrscheinlichkeit eines Fakes bewerten. Zumindest als ersten Anhaltspunkt. Reproduktion – Gelingt es Dir, den AI Overview (zumindest in ähnlicher Form) zu reproduzieren? Wenn Du ganz andere Ergebnisse erhältst, könnte dies ein Hinweis darauf sein, dass ein vorliegendes Problem in der Antwort behoben wurde oder vielleicht gar nicht existiert hat. Wobei wir natürlich nicht genau wissen, wie stark die AI Overviews zu einem Query sich unter Umständen anhand verschiedener Parameter zwischen zwei Personen unterscheiden können.
...und was ist mit Fehlinformationen?
Für den Fall, dass Du eine problematische Antwort reproduzieren kannst oder selbst in einer Anfrage von der SGE Informationen findest, die Dir unglaubwürdig vorkommen, gibt es noch einen weiteren Schritt:
- Quellen – Die Beispiele aus der Vergangenheit haben gezeigt, dass Google sich da nicht einfach etwas komplett wirres zusammenhalluziniert hat. Vielmehr lassen sich, wenn man ein bisschen in die Quellen rein wühlt, die Ursprünge für die wilden Behauptungen, die sich im AI Overview finden, aufdecken. Demnach solltest Du die verlinkten Quellen überprüfen, um herauszufinden, wie es zu dieser oder jener Fehlinformation gekommen ist.
Im Fall der Käse-Kleber-Pizza ist die Ursache in einem uralten Reddit-Post zu finden. Damals hatte sich wohl jemand einen Scherz erlaubt. Auch für andere Beispiele lässt sich belegen, wo der Ursprung liegt.
"AI Overview instructed some users to mix nontoxic glue into their pizza sauce to prevent the cheese from sliding off, a fake recipe it seemed to borrow from an 11-year-old Reddit post meant to be a joke. The A.I. told other users to ingest at least one rock a day for vitamins and minerals – advice that originated in a satirical post from The Onion."
– Zitat aus dem eingangs erwähnten NY Times Artikel
Wenn Du selbst eine fragwürdige Entdeckung in einem AI Overview entdeckst, solltest Du eine Rückmeldung an Google geben. Das empfiehlt auch Barry Schwarz in seinem Search Engine Roundtable-Artikel "In Face Of AI Overview Backlash, Google Updates Docs With How To Show Web Only Results & How To Give Feedback" Zudem verweist er auf die Möglichkeit, AI Overviews (und andere Features) abzuschalten. Am Ende hat er übrigens eine lange Liste an interessanten Beiträgen zusammengestellt, die sich damit befassen.
Vom Vermittler zum Ersteller
Johannes Beus von SISTRIX hat sich auf LinkedIn ganz treffend geäußert. Früher war Google nur Vermittler und hat Suchende auf andere Websites gebracht:
"Google war bisher der unangefochtene Vermittler im Internet: Nutzer erhielten die besten möglichen Verweise auf Internetseiten zu ihren Suchanfragen. Was auf diesen Seiten stand, ob es der Wahrheit entsprach und aktuell war, lag außerhalb von Googles Verantwortung."
Mit den AI Overviews wird Google selbst zum Ersteller von Inhalten:
"Dass das Internet voller Unwahrheiten, Lügen und manipulativen Inhalten ist, ist nicht neu. Neu ist, dass Google diese Inhalte nun selbst in den Suchergebnissen veröffentlicht. Bisher genoss die Suchmaschine das Privileg, nur Vermittler zu sein."
Diese neue Rolle bringt, ganz offensichtlich, einiges an Herausforderungen und Verantwortung mit sich.
Noch mehr Beispiele
In diesen LinkedIn Posts von Orit Mutznik und Troy Muir findest Du weitere Beispiele und Austausch dazu in den Kommentaren, wenn Du Dich weiter dazu belesen möchtest.
Und was sagt Google dazu?
Am 30. Mai hat Liz Reid eine Stellungnahme veröffentlicht: AI Overviews: About last week. Sie berichtet, dass die AI Overviews an sich gut funktionieren:
"User feedback shows that with AI Overviews, people have higher satisfaction with their search results, and they're asking longer, more complex questions that they know Google can now help with."
Viele Nutzer*innen seien mit den AI Overviews sehr zufrieden und im Vergleich zur regulären Google Suche seien die Fragen, die sie stellen, länger und komplexer. Zudem wären die aus AI Overview resultierenden Klicks qualifizierter.
Allerdings möchte man im Angesicht der Aufmerksamkeit, die die KI-generierten Ergebnisse jüngst erhalten haben, dies auch ein wenig erklären. Zum Beispiel, dass die AI Overviews nicht wild halluzinieren, sondern fehlerhafte Antworten auf andere Ursachen zurückzuführen wären:
"This means that AI Overviews generally don't "hallucinate" or make things up in the ways that other LLM products might.
When AI Overviews get it wrong, it's usually for other reasons: misinterpreting queries, misinterpreting a nuance of language on the web, or not having a lot of great information available."
Bezüglich der "odd results" schreibt Liz, dass sie die SGE natürlich sehr ausführlich getestet haben, es aber eine ganz andere Sache ist, wenn auf einmal Millionen Nutzer*innen das Feature nutzen. So gäbe es viele neue Queries und vor allem auch Suchanfragen, die nicht wirklich Sinn ergeben und darauf abzielen, fehlerhafte Ergebnisse zu produzieren. Dennoch würde Google daraus hilfreiche Erkenntnisse für Verbesserungen ziehen. Welche Anpassungen bereits vorgenommen wurden, kannst Du in Liz' Artikel ausführlich nachlesen.
Außerdem betont sie, dass viele der extrem problematischen Screenshots vermeintlicher AI Overviews Fakes sind.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|




