Lesen ist wichtig und richtig. Aber auch die anderen Sinne brauchen regelmäßig guten Stoff.
Am Wochenende habe ich mir unter anderem das Gespräch von Tim Soulo (Ahrefs CMO) und Peep Laja (Founder von CXL, Wynter und Speero, aktuell CEO von Wynter) im Ahrefs Podcast angehört. Fast 2 Stunden haben die beiden gesprochen – das kam mir kürzer vor. Es ging vor allem am Anfang um Content.
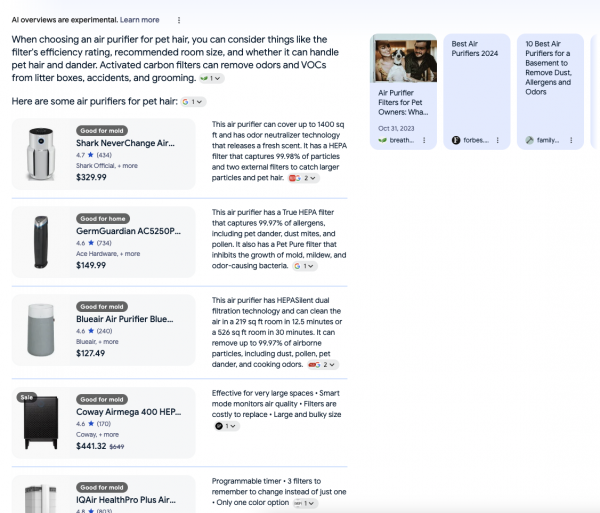
Es wird immer mehr darüber gesprochen: Copycat Content und durchschnittliche Inhalte von Menschen oder der KI, denen Expertise und Erfahrung fehlt, um glaubwürdig und vertrauenswürdig zu sein.
Seit Jahren haben wir das Problem, dass Google uns häufig (noch) dafür belohnt, bereits bekannte Informationen in einer Form von Arbitrage wiederzukäuen. Das ist meistens kein guter Content, aber er rankt gut bei Google. Ich möchte Dir zeigen, was Du tun kannst, um besseren Content zu schreiben.
Welche Erfahrungen haben Tim und Peep mit Content bei Ahrefs und CXL gemacht?
Peep hat in den ersten 10 Minuten ein sehr direktes Statement rausgehauen:
"Before Content Marketing was a thing, idiots did not publish content. You wouldn't write encyclopedia articles without knowing anything. Now, we created a perverse incentive for any idiot to write about anything. We sit in a mountain of garbage."
– Peep Laja
So läuft es bei klassischem SEO-Content häufig ab:
Menschen ohne Themenerfahrung recherchieren die Suchergebnisse, schauen sich Konkurrenzinhalte an, fragen vielleicht noch ChatGPT für einen Überblick aus und am Ende entsteht ein ziemlich austauschbarer Inhalt.
Auch Mordy Oberstein hat vor ein paar Wochen zu dem Thema (fehlendes Incentive für gute Inhalte) etwas passendes geschrieben:
"There's a lack of incentive to create good content. Part of that is due to Google not being able to reward "good content" so we get into a vicious cycle."
– Mordy Oberstein
Peep sieht das ähnlich, denn gute Inhalte von kleinen Domains haben keine Chance, wenn HubSpot die Maschine anwirft und eins von 9.183.119 generischen Listicles raushaut. Einen Tag später sind die "guten Inhalte" dann von Top-Positionen verschwunden.
Copycat Content isn't going to cut it anymore
CXL – eines der Unternehmen, die Peep gegründet hat – war mal eine Agentur, die sich auf Conversion Rate Optimierung spezialisiert hat. Dieser Fokus wurde aufgebrochen. Heute ist CXL vor allem ein Kursanbieter für digitales Marketing.
Grundsätzlich hat sich an der Mission und dem Anspruch an den Content von CXL laut Peep nichts verändert: Es muss der beste Content (in dieser) Nische sein.
Er beschreibt, wie sie von diesem Weg abgekommen sind und die Content-Produktion an eine Content-Agentur abgegeben haben. Der Content soll "fine" gewesen sein.
"Nobody links to just fine content, it needs to be killer-good."
– Peep Laja
Man könnte jetzt denken, dass das ein Edge Case ist. Aber auch Tim hat ähnliche Erfahrungen mit Ahrefs gemacht. Der Content sollte skalierbarer sein, auch ohne viel Involvement von Tim (als ein Beispiel für Themen rund um Marketing).
Ich fand die Inhalte von Ahrefs in der Vergangenheit oft "gut", aber nicht herausragend. Seit der zweiten Jahreshälfte in 2023 lese ich die Inhalte aber wieder ganz gerne.
Was hat sich geändert? Ahrefs hat einen klugen Director of Content Marketing mit Ryan Law an Bord geholt (der vorher bei Animalz war) und die Sichtweise auf Content hat sich gewandelt. Ahrefs versucht (wieder) mehr in Richtung "killer-good Content" zu kommen.
Wie entsteht "killer-good content"?
Peep sagt im Gespräch unter anderem folgendes:
"You cannot have writers write expert content. It needs to be a true practitioner, who does what he does for a living. A writer can edit, make the story flow better, but the original idea needs to come from the practitioner."
– Peep Laja
Tim spricht von einem Catchphrase, den er oft verwendet:
"To create good content, the most qualified person in the company for this topic needs to create this content."
– Tim Soulo
Als Beispiel vergleicht er sich selbst als Marketing-Experten und Patrick Stox, der Experte in technischer SEO ist. Es macht keinen Sinn, wenn jemand wie Tim über technische SEO oder Patrick über Marketing schreibt.
Es wäre 1) fachlich schlechter, 2) weniger zielgruppenspezifisch und 3) nicht glaubwürdig.
Jetzt würde jemand(™) vermutlich sagen: "Die Experten und Expertinnen zu den einzelnen Themen in unserem Unternehmen haben dafür keine Zeit" und da liegt auch das Problem.
Die, die erfolgreich sind, nehmen sich diese Zeit. Und wenn kein Buy-In vorhanden ist, müssen wir dafür sorgen, dass der Wert verstanden wird. Es gibt für wiederholbaren Erfolg keinen Cheat Code, bei dem man den Schritt "hart arbeiten" überspringen kann.
Klingt hart, ist es auch. Aber ich habe noch ein paar Ideen, damit Du bessere Inhalte zaubern kannst, auch wenn die Zeit knapp ist.
3 Funken Hoffnung, um (mehr) besseren Content zu produzieren
Eigene Erfahrungen sammeln
Schreibe über Themen, bei denen Du Erfahrungen aus erster Hand hast.
Theoretische Erfahrung ist gut, praktische Erfahrung ist besser. Autofahren lernst Du, wenn Du im Auto sitzt. Natürlich brauchst Du theoretische Erfahrung bzw. sie hilft Dir. Aber um zu wissen, wie sich das wirklich anfühlt, musst du selbst hinterm Steuer gesessen haben.
So ist es auch mit guten Inhalten. Du interessierst Dich für TikTok SEO und möchtest darüber einen glaubwürdigen Inhalt schreiben? Lade Dir die App herunter, konsumiere Inhalte und probiere am besten auch selbst aus, was funktioniert und was nicht.
Die gesammelten Erfahrungen machen Deinen Inhalt besser. So weißt Du bei einer Recherche auch, was in den SERPs zu dem Thema theoretische Worthülsen ohne Substanz sind.
Was ist aber, wenn Du bei einem Thema fachfremd bist? Dann musst Du Dir Informationen aus dem Team einholen.
Content-Meetings abhalten
Ahrefs hat regelmäßige Content-Meetings, in denen sie sich gemeinsam über Content-Ideen austauschen, neue Ideen generieren und so auch Personen, die weniger Zeit haben, in den Content integrieren können.
Das sehe ich als ersten Schritt, um überhaupt erstmal an Input zu kommen. In der Vergangenheit war das für mich eine der größten Herausforderungen: Input von Experten und Expertinnen einsammeln. Wenn es hierfür keinen Buy-In auf Führungsebene gibt, ist das ein Kampf gegen Windmühlen.
Falls das schon gut klappt, gibt es eine noch bessere Möglichkeit: Interviews führen.
Interviews mit Expertinnen und Experten führen
Ryan Law und Nia Gyant haben hervorragende Argumente, warum es Sinn macht, für guten Content – ohne selbst SME (Subject Matter Expert) zu sein – Interviews zu führen:
"The search results are getting more crowded by the day, stuffed with copycat content written by authors with no real experience in the topic. Firsthand experience is the most powerful differentiator at your disposal. In an ocean of theoretical arguments and armchair commentators, readers want to listen to the experts."
– Ryan Law in "How to Interview Someone for an Article"
"Bland, impersonal, and lacking authority. Much of the content writers and marketers produce today fits that description. This is largely a result of people regurgitating existing content."
– Nia Gyant in "How to Interview Someone For an Article: Step-By-Step Guide"
Neben vorherigen beruflichen Anlaufstellen gab es auch in meinem Studium unterschiedliche Projekte (inklusive meiner Masterarbeit), in denen ich Interviews führen musste, um Insights zu gewinnen. Das heißt nicht, dass die schreibende Person – in diesen Fällen ich – keine Ahnung haben muss.
Um eine Recherche kommt man nicht herum, um die richtigen Fragen im Interview zu stellen und um am Ende die Worte des Experten oder der Expertin in eine logische Reihenfolge zu bringen, die überzeugt.
"SEO content and AI content can be quite dull to read. But writing can be magical and words can transform into weapons of persuasion."
– Zitat von mir in "Content Arbitrage: What it is & how Generative AI puts the concept on skates"
|