| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #256 |
|

|
| 💐Ein Strauß frischer SEO-News |
Hand aufs Herz: Wer hat am Sonntag Morgen hektisch gegoogelt, wo der nächste Blumenladen ist oder was ein Strauß inklusive Lieferung im Internet kostet? 😉 Falls Du Dich angesprochen fühlst, keine Sorge: Google Trends zufolge warst Du damit nicht alleine. Blumen sind einfach nach wie vor das Nummer 1 Muttertagsgeschenk. Das sahen auch nahezu die Hälfte aller Teilnehmerinnen und Teilnehmer einer Umfrage im Jahr 2020 so und ich bin mir ziemlich sicher, dass die Blumengeschäfte am Sonntag ebenfalls wieder Rekordumsätze verzeichnen konnten.
Egal ob Du diesmal einen Strauß verschenkt oder erhalten hast (oder Muttertag aus Gründen gar nicht feierst), wir haben heute wie immer einen bunten Blumenstrauß an SEO-News für Dich zusammengestellt.
Die Floristen am Werk in dieser Woche:
- Rosenkavalier Matt berichtet von KI-Halluzinationen.
- Veilchenfreund Philipp fragt sich, ob Google wirklich weniger Traffic sendet.
- Orchideenritter Behrend zerlegt Infos zu JavaScript von Martin Splitt.
- Fliederfreund Florian spekuliert über die Zukunft von Safari.
- Tulpenbote Johan erklärt, was eine gute Entscheidung ist.
Blumige Grüße und viel Spaß beim Lesen!
Deine Wingmenschen
|
|
| Klingt gut, ist aber Schwachsinn! KI und die Halluzinationen |
Die Interaktion mit Chatbots ist schon ziemlich gruselig. Zumindest fühlt es sich so für mich an. Ist ja aber auch kein Wunder: ChatGPT, Gemini und wie sie sonst noch alle heißen, werden (vermeintlich) von Update zu Update klüger. Sie verstehen Zusammenhänge besser, schreiben überzeugendere Texte und erscheinen mittlerweile geradezu menschlich. Wie ein verlässlicher Partner oder eine enge Vertraute. Ein Experte, der weiß, wovon er spricht (beziehungsweise schreibt).
Doof nur, dass der Eindruck manchmal täuscht… Oder eher häufig.
KI ist ein Fiebertraum. Halluzinationen inklusive
Tatsächlich nimmt die Zahl der „Halluzinationen“ nämlich ordentlich zu. Laut internen Tests von OpenAI halluziniert das aktuelle Spitzenmodell GPT-o3 bei ganzen 51 Prozent der allgemeinen Wissensfragen, also bei mehr als der Hälfte. Noch krasser ist es beim kleineren Bruder GPT-o4-mini: Hier liegt die Fehlerrate sogar bei erschreckenden 79 Prozent. Das ist viel. Sehr viel. Zu viel! Zum Vergleich: Bei GPT-o1 waren es noch rund 44 Prozent.
Bei Fragen zu Personen des öffentlichen Lebens sind es übrigens 33 Prozent bei GPT-o3 und 48 Prozent bei GPT-o4-mini. Zwar ein wenig besser. Aber immer noch katastrophal.
Dabei sollen die neuen „Reasoning“-Modelle doch eigentlich der Heilsbringer sein. Statt bloßer Statistik versuchen sie, Probleme Schritt für Schritt zu lösen. Und rennen dabei wohl in die aus dem Matheunterricht längst verdrängten Folgefehler. Jeder Einzelschritt eröffnet eine neue Fehlerquelle und so wird schnell aus einer kleinen Ungenauigkeit totaler Blödsinn. Da hilft es auch nicht, dass ChatGPT Dir den Unsinn in einer schönen Geschenkpackung serviert.
Ironischerweise rätselt auch OpenAI selbst über die genauen Gründe für diesen paradoxen Trend. Klar ist jedoch: Die Spirale dreht sich aktuell in die falsche Richtung.
Shit in, Shit out. Noch mehr Shit in, Bullshit out.
So weit, so schlecht. Doch das ist ja nicht das einzige Problem, das sich daraus ergibt. Stattdessen fluten diese fehlerhaften und allenfalls mittelmäßigen KI-generierten Inhalte zunehmend das Netz. Und die Trainingsdaten für KIs werden knapp. In der Folge fließen statt neuer hochwertiger Texte zahlreiche KI-generierte Schmodderinhalte zurück in die eigenen Datenbanken der KI, was langfristig die Qualität weiter senken dürfte. Ein Teufelskreis.
Diese Entwicklung wirft eine unangenehme Frage auf: Sind wir womöglich schon über den Gipfel hinaus und es geht jetzt langsam wieder bergab mit der KI? Nun, soweit würde ich nicht gehen. Sicher ist aber zumindest eins: Die Zuverlässigkeit lässt aktuell nach, obwohl KI immer intelligenter wirkt. Die Tools wirken oft überzeugend. Und genau das macht sie so gefährlich, wenn es um faktische Genauigkeit geht. “Wird schon passen", denkt man sich. Und dann ab mit dem Rohrreiniger auf die nächste Pizza.
Bei AI Overviews ist übrigens ebenfalls Vorsicht geboten. Auch hier ist die Fehlerquote nach wie vor sehr hoch.
Abschließende Worte
Was heißt das nun wieder? Ganz einfach: Verlasse Dich niemals blind auf KI-Tools. Ganz gleich, wie gut Dein Prompt auch sein mag oder wie souverän ChatGPT, Gemini oder wer auch immer klingt – Du musst trotzdem die Fakten checken. Immer noch! Oder eher: Noch kritischer als je zuvor! Und das nicht mit einem anderen KI-Tool. Nope, hier ist Dein menschlicher Verstand nach wie vor unverzichtbar. Der Faktor Mensch wird auf lange Sicht wohl nicht verschwinden, sondern eher wichtiger denn je.
Gerade in sensiblen Bereichen wie Medizin, Recht oder Bildung kann blindes Vertrauen auf KI verheerende Folgen haben. Es gibt ja bereits genügend Fälle, in denen Anwälte nicht existierende Gerichtsurteile aus ChatGPT zitiert haben. Upps. Das ist natürlich peinlich. Und gefährlich obendrein, um noch einmal zurück auf das Pizza-Beispiel zu kommen…
Okay. Genug der kleinen Weltuntergangsstimmung am Dienstag. Wie gehst Du mit der steigenden Fehlerrate bei KI-Content um? Nutzt Du KI trotzdem intensiv weiter oder hat sich Dein Umgang bereits verändert und eine Art KI-Verdrossenheit eingestellt? Lass es uns gerne wissen →
|
|
| “Google sendet weniger Traffic” und “AIOs klauen fast 35% Traffic” – oder nicht? Warum ich immer ganz genau hingucke |
Immer wieder hören wir, dass Google immer weniger Traffic sendet. SparkToro wird nicht müde zu betonen, dass über die Zeit weniger Suchen in Clicks enden (= Zero Click Searches) und das schon vor AIOs (2022-2024).
“AIOs reduzieren die CTR um 34,5%”
heißt es zusätzlich in einer aktuellen Studie von Ahrefs.
Aber kann man ableiten, dass “wir weniger Google Traffic” bekommen? Nur weil anteilig weniger Clicks passieren, heißt das nicht, dass absolut weniger Traffic ankommt – gerade weil Google wächst.
Also: Kriegen wir mehr oder weniger Traffic durch Google?
“Google sendet 15% weniger Referral Traffic!”
sagt Axios, basierend auf SimilarWeb-Daten (= Clickstream-Daten, die nach unserer Erfahrung gerne mal um 50-200% abweichen) von 500 erfolgreichen News-Seiten.
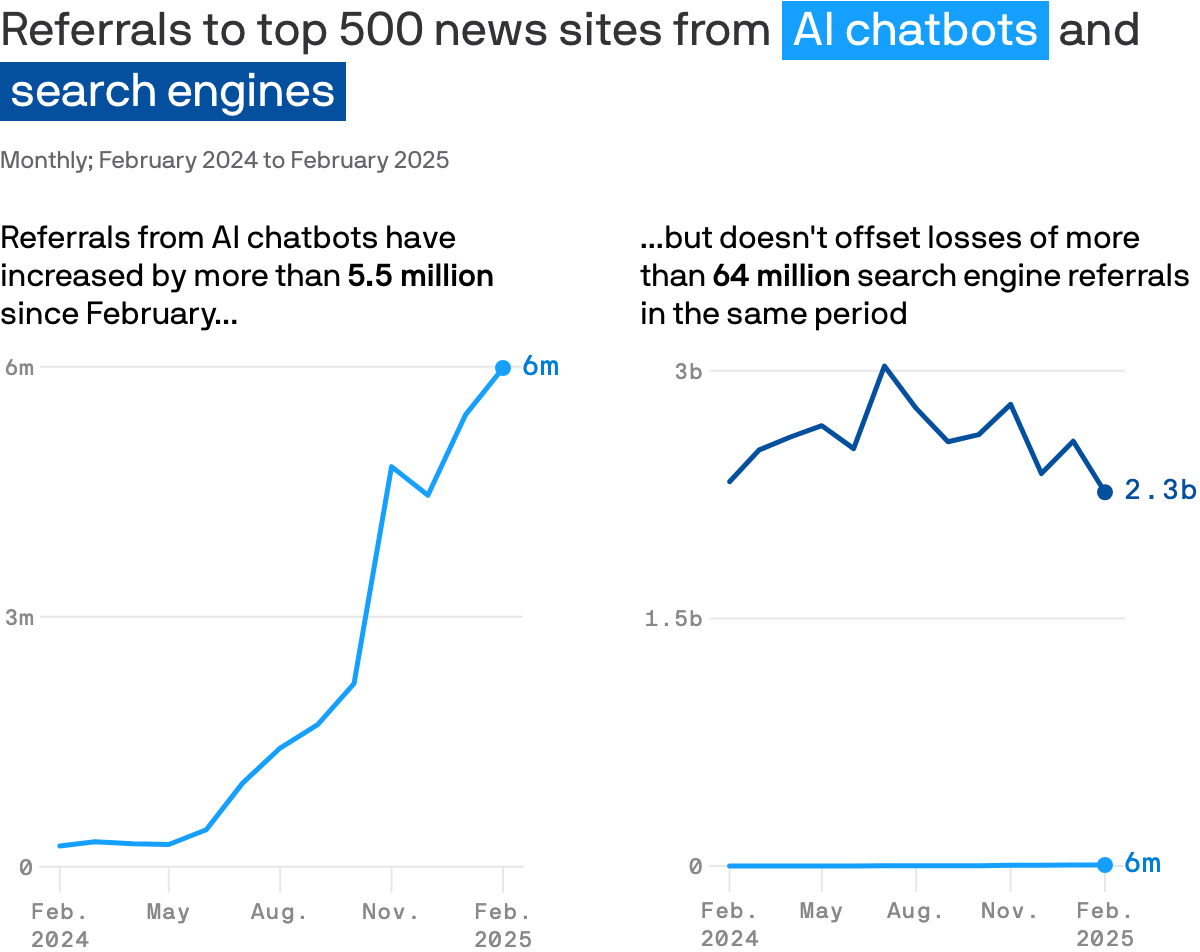
AI Chatbot Referral Traffic hingegen ist massiv gestiegen. Legt man die Graphen nebeneinander, sind das aber weiterhin Peanuts.
Die 15% weniger Traffic stammen aus einem Vergleich von Mai 2024 (AIO Rollout) und Februar 2025. Klingt dramatisch. ABER: Februar hat häufig 3 Tage weniger als andere Monate (ca. 10% Unterschied) und laut ZipTie AIO Monitor gab es über die Zeit immer mehr AIOs und nicht weniger.
Eigentlich müsste der Traffic also kontinuierlich nach unten gehen und nicht bis August steigen, außer es gab hier große Nachfrageschwankungen, die wir in den Daten von SimilarWeb nicht erkennen können und den kompletten Vergleich grundsätzlich infrage stellen würden.
Wie sieht es mit anderen Quellen aus?
Eine weitere Datenquelle kommt zu einem ähnlichen Ergebnis
In einer Datenerhebung von Parse heißt es, dass die Websites in ihrem Netzwerk insgesamt weniger Traffic bekommen. Wenn man aber nur auf Google schaut, dann gibt es seit der AIO-Einführung mehr Traffic.
“Google-referred traffic increased slightly, both in raw numbers and as a percent of total traffic.”
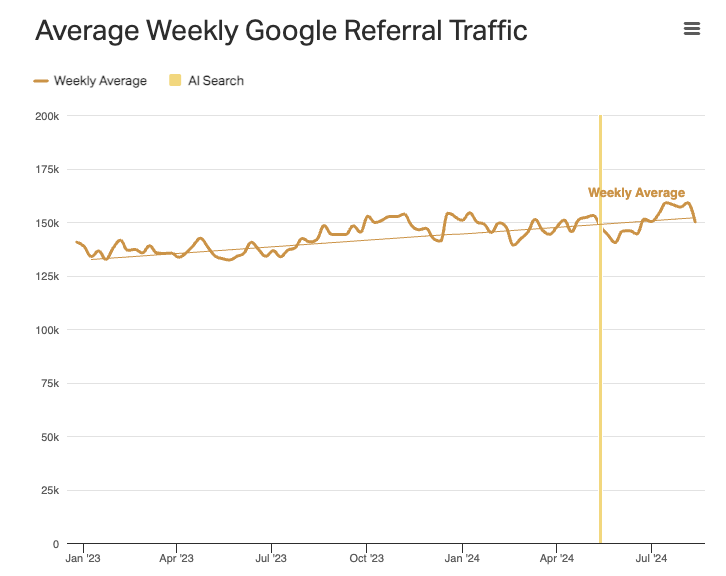
Leider endet der Graph im August 2024. Axios stellt aber auch hier den Höchstpunkt des Traffics in 2024 fest – also kein Widerspruch.
Eine andere Datenquelle: Google sendet insgesamt mehr Traffic
Das Reuters Institute veröffentlicht am Anfang des Jahres regelmäßig einen Report, in dem es um Trends im Bereich Journalismus, Medien, KI und die Suche geht.
Da sie im 2025 Report nicht alle Daten aus dem 2024 Report abbilden, habe ich die Graphen mit ChatGPT und o3 analysiert, die Daten extrahiert und für Dich zusammengeführt (Search und Discover getrennt gab es nur im 2025 Report ab Mitte 2023, wie im Graphen zu sehen ist):
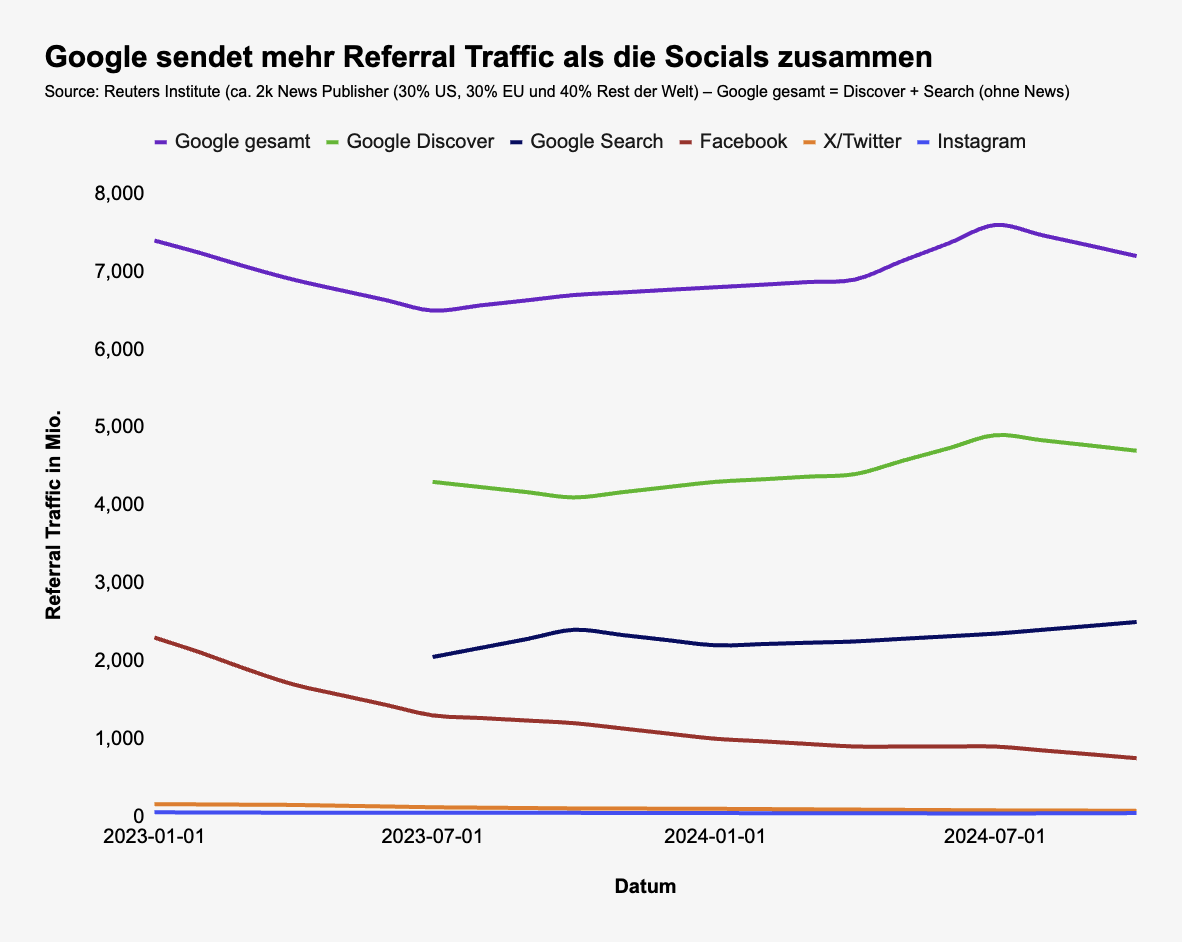
Es handelt sich um ~2.000 News Publisher (aufgeteilt in 30% US, 30% EU und 40% Rest der Welt).
Was kann man hier erkennen?
- Alle Social Networks senden über die Zeit weniger Referral Traffic.
- Google Search und Google Discover wachsen eher, als dass sie schrumpfen.
- Google, egal ob mit Discover oder ohne Discover (und News), sendet mehr Referral Traffic als alle Social Networks zusammen.
Aber: Der Graph endet im Oktober 2024, danach haben wir keine Daten. Wir können aber erkennen, dass Search am Ende wächst und Discover abnimmt.
Axios kann in den SimilarWeb-Daten nicht zwischen Search und Discover unterscheiden. Wenn beides als Aggregat fällt und Discover (die grüne Kurve, die zum 2. Halbjahr 2024 abnimmt) den größeren Teil ausmacht, wovon auszugehen ist, dann könnte die negative Richtung hinkommen.
Können wir also sagen, dass wir (immer) weniger Traffic von Google bekommen?
Nein, wir haben nicht ausreichend Daten und die, die wir haben, sind Clickstream-Daten eines einzelnen Anbieters zu lediglich 500 Websites, die
- aus dem News Vertical kommen, das sich grundsätzlich anders verhält,
- diese Websites erwartbar viel Informational Content haben und
- wir daher mehr AIOs erwarten.
Clickstream-Daten sind außerdem ungenau(er), wenn es viel Mobile Traffic gibt, denn dort haben derartige Tool-Anbieter weniger Potenzial, vernünftige Daten zu sammeln. Da Publisher viel Discover-Traffic bekommen (bis jetzt Mobile only), ist hier von großen Mobile-Anteilen auszugehen.
Reduzieren AIOs die CTR wirklich um 34,5%, wie Ahrefs sagt?
Was ich mich gefragt habe: Warum ist die CTR auf Position 1 bei informationalen Keywords, die sie ausgewählt haben, so gering (5,6% und 7,3%)? Das ist unüblich.
Durch das gratis AWR CTR Tool kann man sich herleiten, was für SERP Features anwesend sein müssen, damit so eine niedrige CTR zustande kommt, z. B.
- Knowledge panel (KP) +
- Featured snippet (FS) +
- weitere Features, die CTR abnehmen können (Local, PAA, etc.)
Hier mal ein paar Beispiele:
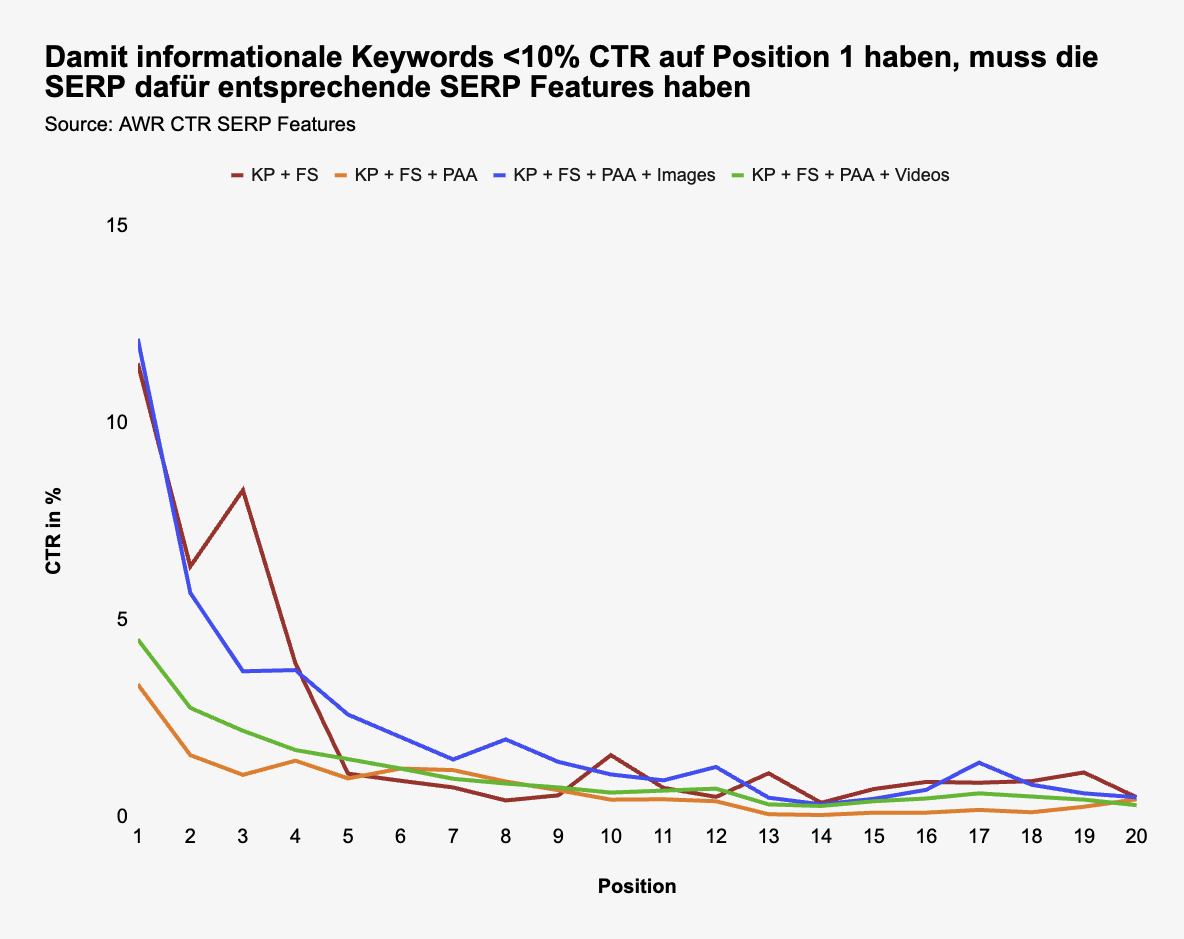
Es wirkt so, als habe man die Daten gewählt, die den größten “Shock Value” haben. Daher auch die spitze Headline:
“AI Overviews Reduce Clicks by 34.5%”
und nicht
“AI Overviews Reduce Clicky by 34.5% but only for low-intent, informational keywords that have a very specific SERP layout”
Und ja, das ist ein großer Unterschied, ob das für alle Keywords im Durchschnitt zutrifft oder nur einen Teil, den man sich sorgfältig ausgesucht hat (und die vorher vermutlich auch nicht besonders hochwertig waren).
AIOs reduzieren die CTR, keine Frage. Aber die Aussage, sie reduzieren die CTR durch die Bank um 35%, ist irreführend. Auch im Hinterkopf zu behalten: Wenn AIOs bei 20% der Keywords auftauchen, heißt das nicht, dass das 20% aller Suchen betrifft. Anzahl Keywords != Anzahl Suchen.
Fazit: Wir müssen vorsichtig mit verallgemeinernden Aussagen sein
Bei Daten, die Du selbst nicht verifizieren kannst, wäre ich immer vorsichtig. Selbst wenn wir Daten selbst erheben können, müssen wir vorsichtig sein.
“The brain is designed with blind spots, optical and psychological, and one of its cleverest tricks is to confer on its owner the comforting delusion that he or she does not have any.”
– Carol Tavris und Elliot Aronson (Autor*innen und Psycholog*innen)
Ein paar Tipps, damit Du (eigenen und fremden) kognitiven Verzerrungen nicht auf den Leim gehst:
- Forme einen ganzheitlichen Blick: Berücksichtige alle Beweise, Daten und Aussagen, nicht nur die, die Dir gefallen.
- Bleibe (so gut es geht) objektiv: Lege Kriterien fest, die Du bei eigenen Erhebungen zugrunde legst und bei der Bewertung von fremden Erhebungen berücksichtigst.
- Lass Dich nicht veräppeln: Hinterfrage kritisch, sei neugierig und bleibe aufmerksam.
Tagtäglich fliegen uns Daten um die Ohren, bei denen eine kritische Grundhaltung wichtig ist, damit wir kein Opfer von Narrativen werden. Ein kleiner (aktueller) Auszug:
P.S. Menschen wie Sam Altman, Mark Zuckerberg, Elon Musk und Sundar Pichai haben Eigeninteressen und Aussagen wie “wir haben unsere Nutzerzahlen in einem Monat verdoppelt” lösen emotionalen Druck aus, nichts verpassen zu wollen und fungieren als Social Proof, einem der stärksten Hebel, um Menschen zu beeinflussen.
“The mentality of a herd makes it easy to manage. Simply get more members moving in the desired direction and the others – responding not so much to the lead animal as to those immediately surrounding them – will peacefully and mechanically go along.”
– Robert Cialdini (Autor und Psychologe)
|
|
| He was pretty Splitt about JavaScript |
I'm pretty Splitt in that
Martin Splitt – Tech SEO Summit 2025
Martin hat gebeten, seine Aussage zum Thema JavaScript nicht einfach so aus dem Zusammenhang zu reißen, daher reiße ich dieses Zitat aus dem Zusammenhang (außerdem habe ich mir zwar aufgeschrieben, dass er es gesagt hat, aber vergessen zu notieren, in welchem Kontext der Satz genau gefallen war ¯\_(ツ)_/¯ ).
Abgesehen davon hat Martin Splitt von Google auf dem Tech SEO Summit viele schlaue Dinge über JavaScript-Performance-Optimierung gesagt.
Merkwürdigerweise hat er dabei nicht die krassen JavaScript-SEO-Hacks vorgestellt, sondern wirklich über Performance-Optimierung geredet.
Fast so, als würde Google wollen, dass wir einfach performante Webseiten mit guter UX bauen und darauf dann guten Content darstellen, der die Fragen der Nutzer beantwortet.
Zu Anfang gab es einen kurzen Rant darüber, dass HTML und CSS inzwischen viel mehr können und man nicht mehr für alles JavaScript braucht – und man jQuery, React und Co. nicht einfach nur einbauen soll, weil es gerade alle coolen Kids tun, sondern nur, wenn man JavaScript für die Funktionalität braucht. Dann folgte schicker Deep Dive in ein paar JavaScript-Performance-Untiefen (the_Splitti kennt sich mit dem Tauchen ja auch gut aus).
Neben der einleitenden Tautologie habe ich noch ein paar Punkte notiert, die Dir vielleicht helfen, wenn Du das nächste Mal versuchst, herauszufinden, warum Deine Seite so langsam geworden ist.
Not All Bytes Are Equal
JavaScript braucht die CPU, um kompiliert und ausgeführt zu werden.
Bilder sind zwar häufig größer als JavaScript, aber belasten den Main Thread des Browsers kaum.
Byte für Byte verglichen, hat daher JavaScript einen wesentlich größeren Einfluss auf Ladezeiten als Bilder.
Das bedeutet nicht, dass Du aufhören kannst, Dir über Bildkompression Gedanken zu machen, sondern dass Du bei JavaScript-Code auf mehr gucken musst als nur die Größe der JS-Dateien.
Insbesondere schlecht geschriebenes JavaScript kann – im Zweifel in wenigen Zeilen Code – Deine Website unheimlich verlangsamen. Martin hat das in einigen Beispielen eindrücklich erörtert.
Wenn Deine Website hauptsächlich Text und Bilder darstellt, sollte ein halbwegs modernes Endgerät mit guter Internetverbindung eigentlich kein Problem beim Rendering haben. Wenn Dein Blog auf einem hochgetunten Gaming-PC mit Glasfaserinternet beim Scrollen ruckelt, dann läuft da etwas falsch.
async und defer
Gut, das ist jetzt keine Weltneuheit, aber es kommt doch immer mal wieder vor, dass JavaScripte unnötig das Rendering blockieren.
Nutze für script-Elemente das async- oder das defer-Attribut, um zu verhindern, dass JavaScript das Rendering unnötig blockiert.
Faustregel: Wenn ein Skript im Rendering wichtig wird, async, damit es asynchron geladen und ausgeführt wird, sobald es verfügbar ist. Alternativ defer, um das Skript erst auszuführen, wenn die Seite fertig geladen und gerendert ist. Letzteres ist in der Regel für Tracking-Skripte und einen großen Teil der Nutzerinteraktionen völlig ausreichend.
Es gibt nur seeeehr wenige Ausnahmen, wo ein Skript ohne async oder defer ausgeführt werden sollte. Und ich vermute, in 99,976 % dieser Fälle sollte so ein Skript serverseitig gerendert werden.
Minify und Komprimieren
Es sollte auch 2025 eigentlich selbstverständlich sein, dass darauf geachtet wird, dass Code komprimiert übertragen wird.
Zum Thema Minify weist Martin darauf hin, dass minified JavaScript nicht nur Bytes spart, sondern in der Regel auch die Ausführung beschleunigt. ABER: nicht immer – es gibt Fälle, in denen das Kompilieren und Ausführen des minifizierten JavaScript langsamer ist. Daher: Benchmark your execution times!
Layout Thrashing
Vereinfacht gesagt: Wenn Du Read- und Write-Operationen mischst und voneinander abhängig machst, dann kann der Browser das Layout nicht im Batch verarbeiten, sondern muss jeden Schritt einzeln rendern (und das ist langsam).
Weniger vereinfacht ist Layout Thrashing auf web.dev beschrieben.
Ich bin ehrlich: Ich hab vorher noch nie davon gehört, aber ich bin kein JavaScript-Entwickler.
Ich kann mir aber gut vorstellen, wie das im Entwicklungsprozess mal bei der QS durch die Lappen geht.
Wenn Deine Seite langsam rendert, obwohl eigentlich alle Ressourcen fluffig geladen werden, liegt hier vielleicht der Hase im Pfeffer.
Nächste Woche geht es weiter
Das war schon eine ganze Menge JavaScript für Deine Newsletter-Aufmerksamkeitsspanne. Aber noch lange nicht alles, was Martin auf dem Tech SEO Summit schlaues gesagt hat. Daher habe ich den Bericht aufgesplittet.
Im zweiten Teil, der nächste Woche erscheint, geht’s weiter mit Martins Deep Dive und ich erzähle Dir von Code Splitting, Loadable Components, Web Workern und ihren SEO-Fallstricken
|
|
| Safari sucht Suchmaschine - Trennt sich Apple von Google? |
Google steht weiterhin unter Beschuss durch das US-Justizministerium (DOJ). Erst kürzlich habe ich über die potenziellen Konsequenzen eines erzwungenen Verkaufs von Chrome geschrieben. Doch es gibt noch weitere Maßnahmen, die derzeit im Raum stehen: Google könnte gezwungen werden, den Platz als voreingestellte Suchmaschine gegen Bezahlung in vielen Browsern zu räumen. Allen voran in Apples Safari.
Safari denkt laut über Alternativen nach
Laut Aussagen des Senior Vice President of Services Eddy Cue prüft Apple, KI-Lösungen wie ChatGPT oder Perplexity als alternative Suchmaschinen einzubinden. Damit deuten sie an, sich von ihrem Deal mit Google über die Standard-Browserrechte wegzubewegen.
Apple hat zwar einen 20-Milliarden-Dollar-Deal mit Google über ihre Standard-Positionierung in Safari, den sie nicht verlieren wollen, allerdings müssen sie sich auch auf ein potenzielles DOJ-Urteil vorbereiten.
Grund für das Umdenken ist, dass das erste Mal die Anzahl der Suchanfragen über Safari gefallen ist (Google sagt, das stimme nicht). Apple geht davon aus, dass das auf den KI-Umschwung zurückzuführen ist. Noch sind viele Features der KI-Anbieter nicht ausgereift genug, damit Apple sie als Standardsuchmaschinen in Betracht zieht. Apple ist aber auch nicht abgeneigt.
Eddy Cue kann sich vorstellen, dass KI in naher Zukunft traditionelle Suchmaschinen wie Google ablösen wird. Sam Altman hingegen hat mit der Aussage überrascht, dass er nicht davon ausgehe, ChatGPT würde Google als DIE Suchmaschine ablösen.
Für Apple ist ein Umstieg von Google auch nicht weit hergeholt. Sie haben in der Vergangenheit bereits viel experimentiert, um ihre eigene Suchmaschine zu schaffen. Nachdem ein Forecast aber einen Einbruch von etwa 12 Milliarden USD in den ersten 5 Jahren berichtet hat, sollte sich Apple von Google trennen, haben sie das Thema erstmal auf Eis gelegt.
Mit dem jetzigen KI-Wandel und einem möglicherweise erzwungenen Wechsel von Google, könnten wir hier allerdings weitere Fortschritte sehen. Grundlagen für eine Suchmaschine hat Apple mit Siri und Spotlight bereits.
Wie groß wäre der Schlag für Google?
Safari hat zwar nicht die Reichweite von Chrome, aber dennoch einen plattformübergreifenden Marktanteil von über 17%. Konkurrenz um die Standard-Position in Apples Browser wäre ein empfindlicher Schlag für Google (+ ein Gerichtsurteil, das Apple untersagt, Geschäfte mit Google für den Default machen zu dürfen, wäre auch für Apple finanziell schlecht). Selbst wenn es nicht um einen vollständigen Ausschluss geht, sondern Google nicht mehr voreingestellt bleibt, stellt sich die Frage: Wie viele Nutzer:innen würden sich wirklich aktiv gegen Google entscheiden?
Eine Studie von Anfang des Jahres gibt Hinweise: Teilnehmende wurden dafür bezahlt, zwei Wochen lang Bing statt Google zu nutzen. Etwa 33% Teilnehmer:innen, die bis zum Ende teilnehmen, blieben anschließend freiwillig bei Bing. Zudem gaben 64% an, dass Bing besser sei, als sie erwartet hatten. Die Studie bezog sich allerdings ausschließlich auf etwa 2.500 Desktop-Nutzer:innen. Ein Feld, in dem Bing wesentlich stärker vertreten ist als mobil.
Dennoch zeigt die Studie, dass der wahrgenommene Qualitätsunterschied zwischen den Suchmaschinen nicht so groß ist, wie von vielen angenommen. Laut der Studie basiert Googles Vormachtstellung also nicht allein auf überlegener Qualität, sondern auf ihrer prominenten Positionierung.
Wahlfreiheit ist nicht gleich Wandel
Das Problem liegt aber nicht nur an Googles standardmäßiger Positionierung, sondern daran, dass viele Menschen andere Suchmaschinen nicht kennen und Alternativen keine Chance geben. Nur eine Wahlmöglichkeit beim ersten Öffnen von Safari würde Googles Marktanteil daher nur marginal ändern, da die meisten Nutzer:innen einfach wieder Google wählen würden.
Sollte Apple jedoch in der Zukunft eine KI-Suchmaschine wie Perplexity oder ChatGPT aktiv als neuen Standard einführen, würde das spürbare Auswirkungen haben. Spannend wäre dann zu sehen, wie viele Menschen aktiv zurück zu Google wechseln. Außerhalb des Rahmens einer festgesteckten Studie könnte das weit unter den 66% von Leuten liegen, die zurückwechseln.
Was heißt das für SEO?
Nachdem was wir bisher über SEO für LLMs (oder GEO, wie es einige schimpfen) wissen, funktioniert sie fundamental nicht anders, als normale SEO. Klar findest du dutzende Artikel, die Dir den Trick für easy LLM-Rankings versprechen: Weißer Text auf weißem Hintergrund, Listen, etc. Aber grundlegend sind saubere SEO-Basics immer noch Dein größter Hebel dafür.
Genauso sieht es bei Bing aus. Auch wenn wir manchmal unsere Differenzen mit Bing haben, funktioniert Suchmaschinenoptimierung hier ebenfalls genauso wie bei Google.
Ganz egal also ob:
- Safari als Standard eine KI-Suchmaschine einbaut
- Safari einen anderen Browser (bspw. Bing) wählt
- Safari den Nutzer:innen die Wahl der Suchmaschine gibt
für Dich sollte es weiter SEO as usual heißen, vor allem wenn Du hier viele offene Hausaufgaben hast.
Aktuell passiert so viel rund um Google, dass sich nicht vorhersagen lässt, was die Zukunft bringt. Aber aus genau diesem Grund solltest Du Dich auf das fokussieren, was Du heute kontrollieren kannst. Gute Inhalte auf einer sauberen technischen Grundlage schaffen und Nutzer:innen zufriedenstellen. Ganz einfach, oder?
|
|
| Was ist eine gute Entscheidung? |
Lara hat neulich über Entscheidungsmüdigkeit und möglichen Umgang damit geschrieben.
Die Überschrift hat mich an eine der hilfreichsten Perspektiven, die ich kennengelernt habe, erinnert:
Laras Überschrift war:
Warum Du nachmittags keine guten Entscheidungen mehr triffst (und was Du dagegen tun kannst)
Die für mich entscheidende Frage ist dabei aber nicht, ob ich vormittags oder nachmittags entscheide und auch nicht, was ich dagegen tun kann. Die entscheidende Frage für mich ist:
Was ist eine gute Entscheidung?
Ich glaube fest daran: Bei der Bewertung von Entscheidungen müssen wir unterscheiden:
1. Entscheidungsergebnis
2. Entscheidungsprozess
Das Ergebnis kann rückblickend gut oder schlecht sein. Eine Entscheidung können wir aber nur aus dem Informationsstand bewerten, den wir zum Zeitpunkt der Entscheidung hatten.
Oft steht man vor einer Webseite und fragt sich: „Wer hat denn die Entscheidung getroffen, das so zu bauen?“ Oder der Klassiker: „Wer hat die Entscheidung getroffen, die URLs zu ändern, ohne Redirects zu setzen?“
Was wir bei der Beurteilung von außen aber nicht vergessen dürfen: Wir haben keine Informationen über den Informationsstand und den Prozess, der zu dieser Entscheidung geführt hat. Das Schlimmste aber: Wir wissen nicht, welche Zielprioritäten der Entscheidung zugrunde liegen.
Kurz: Wir wissen nicht, ob die Redirects weggelassen wurden, wegen:
- Unwissenheit („Ich hab noch nie von Redirects gehört“)
- Ignoranz („Hab gelesen, dass Redirects wichtig sein sollen, aber das ist mir egal“)
- Priorisierung („Ich weiß, dass Redirects wichtig sind und dass es Performance kosten kann, sie nicht zu implementieren, aber ich entscheide mich bewusst gegen die Implementierung, weil (Zeitdruck|Dev-Ressourcen|Verschlechterung Server Performance bei gegebenem Aufwand|Umsetzungsaufwand höher als Umsatz durch Implementierung|…)“
Wir wissen außerdem nichts über den Prozess:
- Wer war an der Entscheidung beteiligt?
- Wer ist verantwortlich, die Entscheidung zu treffen?
- Wer hat die Entscheidung wirklich getroffen?
- Wer ist verantwortlich für den Bereich?
- Ist die Ursache für das Fehlen der Redirects eine bewusste Entscheidung? Oder wurde entschieden, dass Redirects da sein sollten, aber aus irgendeinem Grund wurde das nicht (oder fehlerhaft) implementiert und live gestellt.
Wir müssen also vorsichtig bei der Bewertung von Entscheidungen sein, wenn wir keine Kenntnis über Ziele, Informationsstand und Entscheidungsprozess haben. Nur Idioten beurteilen eine Entscheidung allein nach dem Ergebnis (und ja: Auch ich bin regelmäßig ein Idiot. Aber ich bemühe mich, es seltener zu sein).
Wie treffen wir also selbst bessere Entscheidungen?
Wenn es keine perfekten Entscheidungen gibt: Wie treffen wir dann bessere Entscheidungen?
Wie läuft es normalerweise?
Hier steht eine Entscheidung an: Gibt es eine Alternative? Ja, ne. Wir bleiben bei der ersten Option. Meistens sind wir zu diesem Zeitpunkt schon in eine Variante verliebt.
Früher entscheiden
Jede Entscheidung ist aber immer ein Verzicht auf andere (auch abwegige) Optionen.
Je früher wir entscheiden, desto mehr Zeit haben wir, die Entscheidung durchzuziehen. Je länger wir versuchen, mehr Fakten zu sammeln, desto weniger Zeit haben wir für die Umsetzung. Je länger wir warten, desto geringer wird unser Entscheidungsspielraum.
Geschwindigkeit ist aber kein Selbstzweck. Die Priorität der Entscheidung ist entscheidend.
Wir als Consultants kennen das. Denn unsere Aufgabe ist es, mit unseren Kunden bessere Entscheidungen zu treffen. Und gerade im SEO treffen wir Entscheidungen mit einem hohen Maß an Unsicherheit.
Priorität der Entscheidung klären
Es gibt dabei wichtige und unwichtige Entscheidungen. Und es gibt endgültige und reversible Entscheidungen. Amerikaner nennen das one door/two doors decisions.
Wir können uns für unsere (ja, auch SEO-) Entscheidungen eine einfache Matrix bauen:
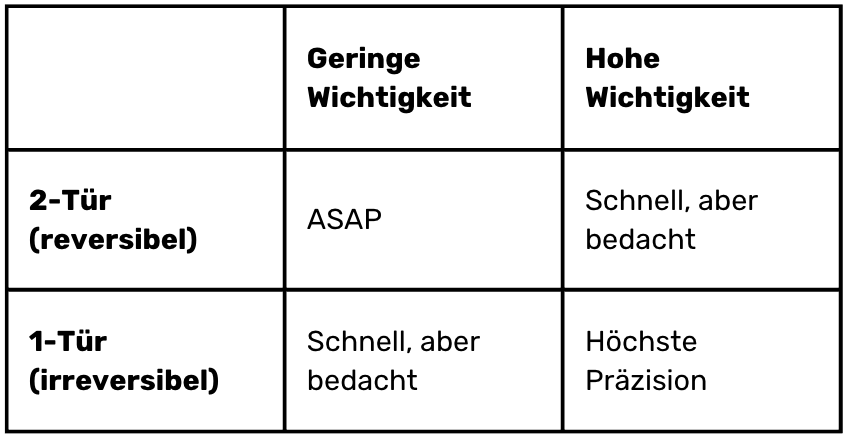
2-Tür + Low Importance: „Löschung Twitter-Cards-Markup“ → ASAP
1-Tür + Low Importance: „Ich gebe mein Restbudget dieses Jahr für $Maßnahme aus“ → Schnell, aber mit Mini-Check
2-Tür + High Importance: „URL-Schema ändern“ → Schnell, aber gut durchdacht
1-Tür + High Importance: „Domain ändern / Migration CMS“ → Tiefgreifende Analyse + Entscheidungsfindung
Wie Du siehst, geht es (mir) bei der Wichtigkeit und „Türigkeit“ nicht darum, ob dabei Kosten entstehen. Natürlich entstehen Kosten dadurch, dass wir das URL-Schema zurückändern und wahrscheinlich wird die Performance etwas geringer sein. Aber bei der Frage nach 1 oder 2 Türen geht es eher darum, ob die Entscheidung prinzipiell reversibel ist. Und das trifft auf fast alle Entscheidungen zu. Wir dürfen also mutiger werden.
Vorgehen bei der Entscheidungsfindung
In Fällen von höchster Präzision, aber auch bei „schnell, aber durchdacht” brauchen wir einen Entscheidungsprozess, der nachvollziehbar ist und der dafür sorgt, dass wir bewusst und reflektiert entscheiden. Vor allem aber, dass wir jederzeit sagen können: Diese Entscheidung haben wir aus diesen Gründen getroffen.
Regel Nummer 1: Schreib mit beim Entscheiden!
- Welche Informationsbasis hat zu der Entscheidung geführt? (Gerne konkrete Datensätze / Rohdaten irgendwo hinlegen)
- Welche Alternativen wurden ausgeschlossen und warum?
- Wann haben wir entschieden/mit der Umsetzung begonnen?
- Wer hat mitentschieden?
Dokumentation hilft Dir / Uns zu einem späteren Zeitpunkt Entscheidungen zurückzuverfolgen und zu klären, warum etwas wie entschieden wurde.
Und Du kannst (wenn Jemand fragt) auf das Memo verweisen und sagen:
Wir haben uns für eine schnelle Entscheidung entschieden, weil wir davon ausgehen mussten, dass 123. Daher haben wir auf tiefergehende Datenerhebung verzichtet und auf Basis von 234 entschieden, dass…
Regel Nummer 2: Keine Entscheidung ohne Ziel
Bevor wir eine Entscheidung treffen können, brauchen wir Klarheit darüber, was entschieden werden soll. Was ist das Ziel der Entscheidung oder das Problem, das gelöst werden soll?
Vergegenwärtige Dir noch einmal die Problemstellung:
- Worum geht es konkret?
- Wie kam es zu diesem Punkt?
- Bis wann musst Du eine Entscheidung treffen?
Was sind die Risiken?
- Ist die Entscheidung endgültig oder können wir sie (mit vertretbaren Kosten) überarbeiten?
- Was passiert, wenn wir uns entscheiden, nichts zu entscheiden?
- Was passiert Worst Case?
Lohnt der Aufwand?
- Wie viel Aufwand ist in diese Entscheidung sinnvoll investiert?
Danach wissen wir, wer entscheiden kann und beteiligt werden sollte.
Für den letzten Punkt gibt es ein schönes „Gesetz“: Fredkins Paradox besagt:
The more equally attractive two alternatives seem, the harder it can be to choose between them—no matter that, to the same degree, the choice can only matter less.
Wir dürfen also kritisch hinterfragen, wie viel Aufwand wir investieren wollen.
Außerdem müssen wir uns immer fragen:
Wird die Entscheidungsfindung teurer, als der Schaden, den wir abwenden, oder der Nutzen, den wir generieren wollen?
Wenn die Entscheidungsfindung teurer wird, als der Nutzen, dann sollten wir eine Münze werfen und uns um Entscheidungen kümmern, die uns wirklich weiterbringen.
Regel Nummer 3: Was sind die Alternativen?
Welche Handlungsalternativen haben wir? Es gibt immer Alternativen. Vielleicht erscheinen sie im ersten Moment teuer, absurd oder trivial. Aber wenn wir Entscheidungen treffen wollen, dann brauchen wir Alternativen. Wenn wir keine unterscheidbaren Alternativen haben, können wir keine Entscheidungen treffen.
Wir müssen mindestens drei Alternativen haben:
1. Nichts ändern
2. Alternative A
3. Alternative B
Warum 3? Weil wir sicherstellen wollen, dass wir unsere Liebe in die erste Idee mit Fakten hinterfragen. Im Entscheidungsprozess sorgen alle möglichen Biases für Probleme. Die Liebe für die erste Idee und die Tendenz zu Handlung sind zwei davon. Mindestens 3 Alternativen zu haben gibt uns das Gefühl von echter Auswahl. Deswegen ist „Bewahrung des Status Quo“ Nichtstun auch immer eine Alternative. Auch die Entscheidung zu einem späteren Zeitpunkt (= temporäres Nichtstun) sollte eine Option sein.
Wenn Wingmenschen Entscheidungen von mir wollen, dann erwarte ich immer drei Alternativ-Vorschläge. Die billigste Variante, die beste Variante und den Preis-Leistungssieger.
Wenn wir unsere Alternativen mindestens grob gegenübergestellt haben, müssen wir sie bewerten. Bei 1-Tür-Entscheidungen sollten wir diese Kriterien vor der Ausarbeitung der Alternativen festlegen. Bei 2-Tür-Entscheidungen schadet das sicherlich auch nicht.
Regel Nummer 4: Aufwand und Folgen unbiased betrachten
Man kann nicht nicht kommunizieren.
Und man kann auch nicht nicht unbeeinflusst sein.
Aber wir müssen die Beeinflussung im Zaum halten.
Für jede Alternative erstellen wir eine Funktions- und Aufwandsschätzung. Mal kann die eher oberflächlich sein. Manchmal gehen wir hier seitenweise in die Tiefe. Das hängt von der Wichtigkeit und der Komplexität der Entscheidung ab. Wenn wir vor der Entscheidung stehen, wie wir mit der Indexierung unserer Produktseiten in Zeiten von KI umgehen:
- Sperrung/Noindex aller PDP
- Sperrung/Noindex aller Varianten
- Selektive Sperrung/Noindex bestimmter Varianten
- Öffnung aller PDP
… Dann ist die Entscheidung aufwändiger und komplexer als: Wir haben ChatGPT und Perplexity in der Robots.txt gesperrt, um unsere Verhandlungsposition für LLM zu verbessern. Wollen wir das auch für Claude machen?
In der Funktions- und Aufwandsschätzung definieren wir (aber bewerten noch nicht):
- Wie sieht die Lösung aus?
- Wie führt diese Variante zu einer Lösung des Problems? Was ist das Wirkungsprinzip?
- Wie wird sie technisch/inhaltlich umgesetzt?
- Wie teuer wird die Implementierung?
- Wie teuer wird die Wartung?
- Welche Folgekosten entstehen durch die Variante?
- Wie schnell ist eine Implementierung möglich?
Möglicherweise beschreiben wir nicht alle Alternativen gleich intensiv. „Änderung der Robots.txt“ ist wahrscheinlich einfacher zu beschreiben als „Änderung des Geschäftsmodells“.
Regel Nummer 5: Erst am Ende machen wir uns bewusst Gedanken über Vor- und Nachteile
Nachdem wir alle Varianten und ihre Umsetzung entwickelt haben, machen wir uns Gedanken über die Vor- und Nachteile der einzelnen Varianten:
- Auf welcher Ebene ist diese Alternative besonders gut geeignet, das Problem zu lösen und uns in Richtung Ziel zu bewegen?
- Was ist die besondere Stärke dieser Alternative?
- Was sind die Schwächen dieser Variante?
- Was macht diese Lösung einzigartig?
- Wie sicher sind wir, dass diese Lösung das Problem löst?
- Bis zu welchem Grad ist die Alternative in der Lage das Problem zu lösen.
Regel Nummer 6: Wenn Du Deine Entscheidungskriterien nicht vorher festlegst, wirst Du eh die Variante nehmen, die Dir am besten gefällt.
Jetzt kommen wir zur Entscheidung: Welche Alternative ist die beste und warum?
Das Beste ist natürlich immer abhängig von den Rahmenbedingungen und dem Ziel:
Beste kann sein:
- Billig (geringe Kosten und Ertrag niedrig)
- Effizient (die beste Kosten/Nutzen-Lösung; 80/20-Prinzip, Aufwand/Ertrag, Kosten/Nutzen)
- Beste (Ertrag am höchsten, aber Kosten hoch)
Alles keine Wissenschaft, nur Meinung
Weil Entscheidungen wichtig sind, gibt es jede Menge Forschung dazu.
Das hier ist kein Teil der Forschung, sondern ein Einblick in meinen praktischen Umgang mit Entscheidungen. Nicht immer, aber meistens halte ich mich an dieses Framework. Mich daran zu halten, nimmt mir nämlich schon die Entscheidung ab, wie ich zu einer Entscheidung komme.
Aber: Das hier ist mein pragmatischer Ansatz. Dort draußen gibt es tausende Bücher und wissenschaftliche Arbeiten, die jeden Einzelaspekt in der Tiefe belegen (oder widerlegen) und facettenreicher gestalten. Nimm Dir vor der nächsten größeren Entscheidung einmal ein wenig Zeit zu überlegen, wie Du zu einer Entscheidung kommen möchtest, bevor Du zu einer Entscheidung kommst.
Hab Spaß am Entscheiden!
Welche Entscheidung heute die richtige ist unter all diesen Rahmenbedingungen, das können wir uns überlegen. Ob die Entscheidung auch rückblickend in 5 Jahren richtig gewesen sein wird? Das können wir nicht wissen.
Aber wir sollten unseren Entscheidungsmuskel trainieren:
- Welche Entscheidungen haben wir vor 1,2,3 Jahren getroffen?
- Was haben wir uns dabei gedacht?
- War das rückblickend die richtige Entscheidung?
- Was hätten wir auf dem Weg zur Entscheidung besser machen können?
Idealerweise legen wir uns das schon bei der Entscheidung zurecht: Wie wollen wir die Entscheidung rückwirkend bewerten?
Gerade im SEO dürfen wir viel mutiger mit Entscheidungen umgehen.
- Wenn wir etwas indexieren und es war falsch, dann indexieren wir das wieder.
- Wenn wir etwas löschen und es war falsch, dann stellen wir es wieder her.
- Wenn etwas kaputt geht, dann können wir es reparieren.
Ja, Ressourcen sind begrenzt und SEO steht nicht immer ganz oben in der Nahrungskette.
Aber wir dürfen mutiger sein. Die meisten Entscheidungen im SEO sind reversibel. Und wenn Du begründen kannst, warum Du eine Entscheidung so getroffen hast, dann ist es gut möglich herauszufinden, was sich zwischen der Entscheidung und dem Ergebnis geändert hat.
Also:
- Welche Entscheidung steht bei Dir an?
- Welche Entscheidung hast Du vor einem Jahr getroffen und was hättest Du im Prozess besser machen können?
- Hättest Du dann eine andere Entscheidung getroffen und wäre sie aus heutiger Perspektive besser gewesen als die Entscheidung, die Du getroffen hast?
Und vor allem: Wenn Du eine Entscheidung nicht selbst triffst, sondern beraten hast:
Was hättest Du besser machen können, damit eine bessere Entscheidung getroffen worden wäre?
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





