| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #193 |

|
| 🎳 SEO NL CXCIII: Amerikaner können super bowlen |
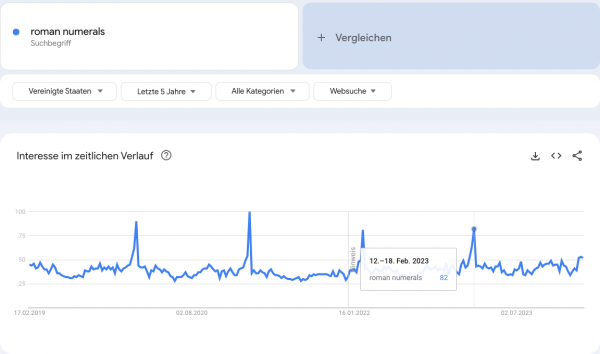
In der Nacht zu gestern auch wieder wegen SB LVIII vor dem Fernseher oder Stream ausgeharrt? Wieso wir ausgerechnet für eine American Football Veranstaltung römische Ziffern verwenden, verstehe ich auch nicht ganz. Zumal SB58 als Abkürzung für Superbowl noch kürzer wäre. Es wird ja auch nicht besser, wenn man in höhere Zahlenbereiche kommt, wie man an unserem Titel sieht.
Hat aber schon etwas Repräsentatives. Vielleicht macht man es deswegen. Der Verständlichkeit halber kann es jedenfalls nicht sein. Zumindest spricht der pünktliche Anstieg der Suche nach römischen Zahlen Mitte Februar jedes Jahr dafür, dass die Super Bowl Fans in den Staaten mit dem arabischen Zahlenformat besser zurecht kämen.
In der Hoffnung, dass die kleinen Zahlen keine Umstände bereiten, haben wir euch wieder ein paar Artikel geschrieben, V an der Zahl:
Behrend steht im Kolosseum der Indexierungsinterpretation Johan gegenüber Johan findet einen neuen Weg zwischen Epikur und Stoa – die Eologie Ich möchte ein wenig über die moderne Cloaca Maxima sprechen – Enshittification außerdem freut Johan sich über Zuspruch im Senat von Kevin Philipp setzt seinen Epos "Google under Pressure" fort
Und wie oft am Tag denkst Du so ans alte Rom? ;)
Wir wünschen Dir viel Spaß beim Lesen!
|
|
| Was heißt hier indexiert? |
Beim Konferenz-Smalltalk, wenn ein abstrakter SEO-Sachverhalt heiß diskutiert wird, heißt es am Ende oft:
Frag 2 SEOs, bekomm 3 Meinungen.
Meistens erklärt die unterschiedliche Gewichtung einzelner Aspekte, wie es zu verschiedenen Meinungen kommen kann, ein klarer Fall von "it depends".
Aber auch wenn Du konkrete Fragen stellst, bei denen die Antwort vermeintlich ein eindeutiges "Ja" oder "Nein" ist, können geübte SEO-Experten problemlos mehrere Meinungen pro Faktenlage generieren.
Hier praktische und hoffentlich lehrreiche Beispiele:
Du fragst 2 SEO-Experten Deinen Vertrauens (nennen wir sie mal Johan und Behrend, Disclaimer: Ähnlichkeiten mit real existierenden Wingmenschen sind rein zufällig):
Wie viele URLs habe ich im Index?
Die Frage klingt erstmal so, als gäbe es dafür eine korrekte Antwort, oder?
Beispiel-Behrend antwortet: Du hast 6 indexiert Beispiel-Johan antwortet: ne das sind 9 im index
Das sieht dann ungefähr so aus wie dieses Meme (kennt jemand die Originalquelle dazu?):

Wer hat jetzt recht? Beide natürlich.
Beispiel-Johan und Beispiel-Behrend legen hier den Indexierungsbegriff unterschiedlich aus.
(Das wissen sie auch beide, aber beide widersprechen gerne, insbesondere für fiktive Newsletterbeispieldiskussionen).
Würdest Du jetzt noch ein wenig nachbohren oder gar einen Dritten Fragen, bekämst Du sicherlich auch noch ne Dritte und vierte Zahl genannt, die, technisch gesehen, auch korrekt sind.
Unterschiedliche Indexierungsdefinitionen?
Behrend, als alter GSC Fan, folgt für dieses Beispiel dem Indexierungsbegriff, den die GSC angibt.
Nach dieser Definition ist nur die kanonische URL indexiert:
Weiterleitungen, HREFLANG-, oder AMP/Mobile-Versionen oder Ähnliches sind nicht indexiert.
Wenn Du so eine Beispiel-URL in der URL Inspection testest, sagt Google, sie ist nicht indexiert, sondern eine andere URL ist das Canonical.
Johan nutzt für seine Antwort als Indexierungsdefinition, ob Google diese in der SERP ausspielen könnte. Denn auch wenn die URL laut GSC nicht die kanonische URL ist, könnte sie ausgespielt werden.
Was ist denn nun wirklich indexiert?
Google hat keine Lust auf Duplicate Content.
Damit der Index möglichst wenig unnötig doppelte Inhalte enthält, indexiert Google genau genommen keine einzelnen URLs, sondern Dokumente.
Und diese Dokumente können dann jeweils eine unendliche Anzahl an URLs haben, auf denen sie zu finden sind. Canonicalization heißt das Zauberwort. Daher werden URLs zu einem Dokument auch häufig als "Canonical Gruppe" bezeichnet, Google spricht meist von "Duplicate URLs" und "Alternate URLs".
Es sind übrigens ca 400 Milliarden Dokumente in Googles Index. Und die meisten davon werden mehrere URLs haben. Die URLs zu einem Dokument können beispielsweise Weiterleitungs-URLs sein, Sortier- oder Trackingvarianten.
Die URLs eines Dokuments müssen dazu auch nicht unbedingt alle auf einer Domain liegen oder auch nur eine ähnliche URL sein (Stichwort Syndizierung von News-Artikeln).
Der Inhalt der URLs kann auch optisch recht unterschiedlich sein, solange sie den gleichen Inhalt haben, kann Google entscheiden URLs als das gleiche Dokument zu sehen. Soweit wir wissen, wird dafür der Simhash eingesetzt.
Aus den URLs zu jedem Dokument wählt Google eine URL als "Canonical" aus, die dann auch in der GSC als indexiert auftaucht. Das ist häufig, aber nicht immer die, die im rel="canonical" angegeben ist. Google spricht von einem Machine Learning aus 20 (gewichteten) Faktoren, die Canonical-URL bestimmen.
Die anderen URLs zu einem Dokument, die Google kennt, werden nicht vergessen. Alle gemeinsam sind relevant für die Indexierung des Dokuments. Sonst könnte eine Weiterleitung beispielsweise auch keine Linkpower vererben. Daher stehen sie ebenfalls als Alias im Index und tauchen in verschiedenen Pages-Berichten der GSC auf (Page with redirect, Alternate page with proper canonical tag, Duplicate without user-selected canonical und der "All time Favorite" Duplicate, Google chose different canonical than user).
Wenn eine Canonical-Gruppe über Domain- und Property Grenzen hinweg besteht, hat die GSC übrigens einige Unwägbarkeiten und die in der GSC kommunizierte Indexierung ist nicht immer eindeutig.
Sicher gehen, dass Dir bei abweichender Domain das abweichende Canonical angezeigt wird, kannst Du eigentlich nur bei Domains, die für denselben User in der GSC freigeschaltet sind.
Gelegentlich wird Dir aber auch das abweichende Canonical für fremde Domains angezeigt. Insbesondere bei PDF-Dateien sieht man das vergleichsweise oft.
Aber dazu könnte man einen eigenen Newsletterartikel schreiben.
Zumal die Informationen des Pages-Berichts immer ein paar Tage hinterher hinken, während URL Inspection die Live-Information angibt.
Lass Dich davon nicht verwirren.
Und nur weil die URL nicht das Canonical ist, heißt es nicht, dass sie nicht auch in der SERP auftaucht. Google zeigt sogar recht häufig andere URLs als das Canonical an.
Beispielsweise:
wenn ein Alias als mobile geführt wird und die Suchanfrage von mobile kommt. Oder HREFLANG. Oder weil die Canonical URL nicht verfügbar ist. Oder weil gerade Wochenende ist. Oder die Weiterleitung noch frisch ist und Google ihr noch nicht traut. Vielleicht auch, weil irgendwo, irgendwann ein kleiner Schmetterling mit dem Flügel schlug...
Machine Learning at it's best also.
Das Problem ist besonders bei HREFLANG, dass es halt so aussieht, als hätte die URL keinen Traffic. Dabei wird der komplette Traffic nur auf die Canonical URL getracked.
Die real dem User angezeigte URL kannst Du nicht in der GSC sehen.
Einige der ca. 20 Faktoren, die dem Machine Learning zur Verfügung stehen und in die Canonical Auswahl gehen:
Canonical (Canonical Ziel wird bevorzugt) Status Code (200er werden bevorzugt) HTTP vs. HTTPS (https wird bevorzugt) Länge der URL (kurze URL wird bevorzugt) Eingehende Links (intern und extern) (mehr und besser wird bevorzugt) Referenzierung in Sitemaps (mehr wird bevorzugt) Datum des letzten Crawls (aktueller wird bevorzugt)
Und all das führt dazu, dass unsere (natürlich nur in der Fiktion diskussions- und widerspruchsfreudigen) Beispiel-Wingmenschen stundenlang über 6 und 9 als korrekte Zahl streiten können.
|
|
| Das sehe ich jetzt ganz eologisch |
Ich bin kein Dogmatiker. Ich habe keine Überzeugungen. Und von Meinungen halte ich mich fern.
Ich bin ein echtes Blatt im Wind. Dafür bin ich bekannt.
Und so hat mich ein Wind letzte Woche nach Würzburg verschlagen. Auf eine kleine Konferenz, den eoSearchSummit.
Dort habe ich nicht nur einige Vorträge gehört und mich lange mit anderen SEOs sehr gut unterhalten (hallo Benedikt, hallo Thorsten, hallo Ihr eo-Logen).
Sehr gut gefallen haben mir die Vorträge von:
Dr. Beatrice Eiring (eology GmbH): Human vs. KI – Wer schreibt die besseren Texte? Chancen, Grenzen & Risiken der KI Content Creation Prof. Dr. Mario Fischer (Herausgeber Website Boosting): Das Low Hanging Fruit Framework – so bekommst du schnell und einfach mehr SEO-Traffic Madeleine Schröter (Deutsche Telekom): SEO Update Recht: Was ihr beachten müsst, damit dem Top-Ranking in der SERPs kein juristischer Ärger folgt
Den letzten Vortrag des Tages durfte ich halten.
Mein persönliches Highlight war dieses Slide, bei dessen Erstellung ich an Stefan denken musste.:
Aber eigentlich bin ich anhand der Funktionsweise Googles einmal durchgegangen, welche Maßnahmen auf Google wirken und wie:
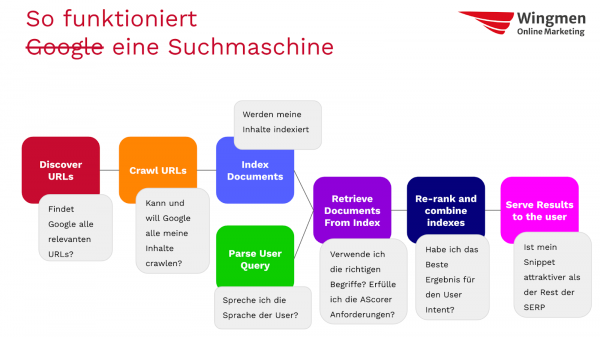
Das Vorgehen hat ganz gut geklappt, auch wenn das mit konkreten Tipps natürlich ein anspruchsvolles Programm für 45 Minuten ist.
Nach dem Vortrag ist aber vor dem nächsten Vortrag. So langsam darf ich die Slides zu „Beyond Crawling: Warum Deine Seiten (nicht) indexiert werden" für die SMX vorbereiten.
Ich freue mich schon sehr auf die SMX. Wenn Du noch kein Ticket für die SMX hast: 15wngmnSMX ist der Rabattcode Deines Vertrauens.
Falls die Gliederung für Dich interessant aussah: So ganz grob wird das auch der Fahrplan für den Technical SEO Workshop (englisch) am Vortag der SMX (11.03.2024) sein. Würde mich freuen Dich da zu sehen (auch wenn der Rabattcode dafür natürlich nicht gilt. ;) )
|
|
| Die Entropie der Enshittification 💩 |
"From en- ("caused") + shittification ("becoming shitty"). As a designation for a particular phenomenon affecting online platforms, coined by Canadian-British blogger, journalist, and science fiction author Cory Doctorow in 2022, but isolated use exists earlier (see quotations below)."
Aus dem Abschnitt zur Etymologie zur Seite des Begriffs Enshittification im englischen Wiktionary. Vor etwas mehr als einem Jahr hat Cory Doctorow diesem Begriff zu großer Aufmerksamkeit verholfen. Er wurde sogar Wort des Jahres der American Dialect Society. Vermutlich in einer Riege zu nennen mit einer Verkündung durch Susanne Daubner in der Tagesschau.
Heute ist das Thema (per Google Trends) scheinbar interessanter denn je.
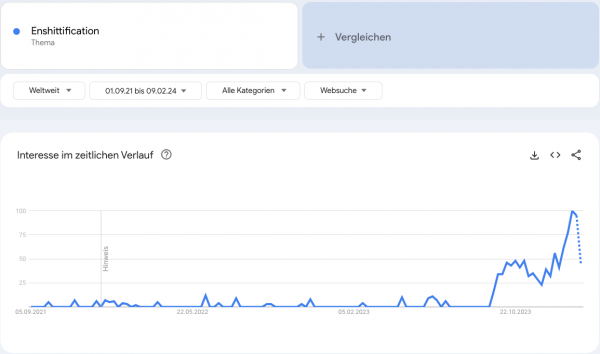
Als Alternativbegriff wird auch "Platform Decay" herangezogen. Laienhaft zusammengefasst beschreibt es den Vorgang, dass sich Plattformen, aber weiter gedacht auch andere Produkte, für ihre Nutzer zum schlechten wandeln, da die dahinterstehenden Unternehmen Entscheidungen nicht im Sinne der Nutzer, sondern nach geschäftlichen Interessen fällen. Beispiele sind seitdem zahlreich genannt worden, eines der bekanntesten dürfte die Kritik an TikTok gewesen sein.
Das Muster ist dabei eigentlich immer gleich. Zuerst wird eine Plattform mit einem guten Service oder Produkt erfolgreich, häufig auch unter finanziellen Verlusten. Mit zunehmender Nutzerzahl gibt es dann eine Honeymoon-Phase für User und Werbetreibende, bis ein Lock-In-Effekt eintritt. Natürlich soll das Geldverdienen weitergehen und weitergehende Maßnahmen werden ergriffen. Durch diese Maßnahmen (bspw. zusätzliche Werbung) beginnt die Abnahme der Qualität und damit des ursprünglichen Erfolgsfaktors. Liest man genug Artikel dazu, wirkt es fast schon wie ein Naturgesetz oder eine kosmische Konstante.
Den Zeitgeist hat Cory damit jedenfalls getroffen. Ich bin zwar kein TikTok-User, aber ob es die "Trending" Videos bei YouTube sind oder "For You"-Tweets auf X, meide ich die in der Regel wie die Pest. Weil sie eben scheinbar nicht für mich zu sein scheinen, sondern etwas, was mir der Algorithmus™ unbedingt reindrücken will. Dieses diffuse Gefühl scheint es bei recht vielen Usern zu geben.
Ich möchte wetten, auf irgendeiner SEO-Konferenz hast Du auch schonmal abends nostalgisch mit anderen über das "Internet von früher" sinniert. Uns als SEOs betrifft das Ganze nochmal ein wenig anders als beim Rest der Plattformen. Denn in nicht wenigen "Geht's nur mir so oder ist Google irgendwie schlecht geworden?"-Diskussionen oder "Schreib 'Reddit' hinter deine Suchanfragen"-Tipps schwingen ja auch die Töne mit, dass diese SEOs das alles verbrochen haben. Noch bevor das Problem mit ChatGPT um den Faktor 100 vergrößert wurde. (Philipp führt das Thema in seinem Artikel diese Woche noch weiter aus.)
Mittlerweile wurden sogar Studien darüber durchgeführt, ob an diesem Gefühl der Verschlechterung etwas dran sein könnte. Seien wir Mal ehrlich: Wenn jeder vor dem Erstellen eines Inhalts eine TF/IDF-Analyse der Top 10 Ergebnisse macht und die Content Features der TOP 3 übernimmt, dann ist es auch wenig überraschend, dass sich die Ergebnisse a) irgendwie alle gleich und b) nicht authentisch anfühlen. Klar, wenn's doch funktioniert.
Das Phänomen, dass sich der Content am Algorithmus der Plattform ausrichtet, ist nicht exklusiv für Google. Vielleicht erinnerst Du dich auch noch daran, als auf YouTube jedes Video plötzlich länger als 10 Minuten sein "musste". Der Unterschied ist aber, dass die Beziehung der Google-Suche zu den Websites eine andere ist. Beide Plattformen könnten zwar ohne ihre Creator nicht existieren, aber während YouTube sein Geld direkt am Video (mit der Werbung) verdient, hat die Google Suche noch keinen Cent gesehen, wenn Du auf ein organisches Ergebnis klickst. Dass beide Services am Ende von Google sind, vernachlässigen wir hier einmal.
Deswegen muss die Google-Suche anderweitig monetarisiert werden und wir landen beim Ausgangspunkt: Enshittification. Wieso denn mühsam einzigartigen Content aufbauen und gegebenenfalls riskieren, nach hunderten KI-generierten und kaputtoptimierten Brand-Inhalten hinten runterzufallen, wenn ich mir den Platz am oberen Ende der SERP auch einfach kaufen könnte? Hat Google überhaupt noch Interesse daran, den besten Content einfach nach oben zu spülen? Ein Schelm, der nun Böses denkt. Weiter gesponnen kommen dabei zwei Gedankenrichtungen heraus:
Die Entropie der Enshittification führt schlussendlich zu einem Niedergang der Google-Suche und eine neue Suchmaschine beginnt den Zyklus von vorne. Werden die Karten irgendwann tatsächlich komplett neu gemischt? Das Ruder wird herumgerissen und eine Entwicklung (vielleicht ja KI-gestützt) führt zu einer Renaissance des inhaltlichen SEOs. Jeder kann dank GPTs einen Basistext zu jedem Thema verfassen. Doch was man darüber hinaus liefert, das einzigartige, gibt am Ende den Ausschlag. Oder wie Jono Alderson fragte: What happens when everybody's website is fixed?
Sicherlich liegt da noch ganz viel zwischen. Ironischerweise würde es sich in beiden Szenarien anbieten, nicht um der Tools und Metriken halber zu optimieren, sondern mit dem Nutzer und dessen Anliegen im Hinterkopf.
|
|
| KeWin liest unseren Newsletter |
Also Wortspiele als Aufmacher sind ja immer blöd. Genauso wie Verallgemeinerungen. Ich hab auch nicht nachgesehen, ob Kevin Indig wirklich unseren Newsletter liest. Wäre ja nicht unwahrscheinlich, dass er große Vermissung Florian und mir gegenüber hat, wo sein Traineeship jetzt über 12 Jahre her ist.
Aber kaum hat Philipp seinen Beitrag über Google under Pressure und Amazon geschrieben, liefert Kevin noch mal weitere Fakten zum Google-/Amazon-Dilemma.
Dabei wirft er einen Blick auf den Earnings-Call, auf den Du nach Philipps Artikel bestimmt ebenso neugierig warst, wie Philipp, Kevin und ich.
Kevin hat diese schöne Grafik gebastelt, die gut zeigt, wie sich der Anteil von Google am Ad Revenue in den letzten 1,5 Jahren im Vergleich zu Meta und Amazon schmälert. Absolut gesehen steigen die Werbeeinnahmen natürlich, aber das Wachstum ist langsamer als bei den anderen.

Kevin macht auch deutlich, dass das an den besonders lukrativen Ads liegt. Er bestätigt also unsere These, dass Google sich das nicht gefallen lassen kann (und wird). Und Google kann auch nicht gefallen, dass Amazon Partnerschaften mit Meta hat und Amazon Prime als Werbefläche anbietet (immerhin hat Google jetzt Pinterest an Bord). Ein Werbe-Euro kann ja nur auf einer Plattform ausgegeben werden.
Im weiteren Teil leitet er über auf Rufus und die Vision von Shopping-Assistenten. Den Teil gehe ich noch nicht mit. Denn nur, weil es den Assistenten gibt, heißt das noch nicht, dass er von Usern anstatt der Suche genutzt werden wird und Werbung darüber funktioniert. Beides ist erstmal eine These.
Egal ob Shopping Assistant oder Suche. Am Ende geht es um User Experience und Nutzung. Nicht zum Selbstzweck, sondern um User zu haben, denen man Werbung ins Gesicht drücken anzeigen kann.
Und natürlich geht es um die bessere Experience für Werbetreibende. Convenience und Steuerbarkeit auf der einen Seite, Effizienz und das Gefühl die richtige Entscheidung zu treffen auf der anderen.
Sehr wichtig finde ich aber den Hinweis, dass Google nicht auf den Ad-Umsatz von News Publishern verzichten kann.
|
|
| Google Under Pressure – Die Qualität der Suchergebnisse wird schlechter und “ohne Reddit finde ich nix mehr” |
Google wird schlechter.
Die SEOs machen das Internet kaputt (oder reparieren es?)
Google hat das Web für sich selbst perfektioniert und für die User kaputt gemacht.
Alles Dinge, die man in den letzten Jahren immer mal wieder hört. Und dann ist da noch das deutsche Paper, das mit dem Titel glänzt: "Is Google getting worse?". Ob man der Meinung ist, dass die Studie valide Ergebnisse liefert oder nicht, steht auf einem anderen Blatt. Aber auch hier zeigt sich das Problem, dass Google gegen ein Narrativ kämpft, unter Druck zu stehen und an Qualität zu verlieren.
Warum ist das ein Problem für Google?
Die Spam-Wellen führen dazu, dass Google viel Energie investieren muss, um die Ergebnisse für Durchschnittsnutzer und -nutzerinnen besser zu machen. Das führt dazu, dass
Menschen, die in einem Thema noch nicht so tief drin sind, bessere Suchergebnisse sehen und Profis, die genau wissen was sie sehen wollen, schlechtere bzw. weniger relevante Ergebnisse erhalten
Johans These dazu ist, dass die Interaktionen durch Nutzersignale von Google übergewichtet werden. Das klingt logisch, denn grundsätzlich muss die breite Masse zufrieden sein und nicht der Super-SEO, der mit fortgeschrittenen Suchoperatoren arbeitet. Die SEOs sind aber häufig die Gruppe, die eine laute Stimme hat, wenn es um die organische Suche geht.
Eine weitere Beobachtung, die Google auf der einen Seite hilft und auf der anderen Seite ein weiteres Narrativ befüttert, ist Reddit. "Ohne Reddit finde ich nichts mehr" heißt es häufig. Zugegeben: Ich habe letzte Woche auch gesagt, dass Reddit eine gerne von mir genutzte Quelle ist, wenn ich dem Affiliate-Zirkus der Google Suche nicht traue.
Kein Wunder, dass es einigen Offiziellen bei Google dann gar nicht geschmeckt hat, als es auf Reddit die Blackouts gab. Dann kommen noch Figuren wie Jeff Bezos dazu, die in andere Suchmaschinen und -systeme (bzw. Antwortmaschinen) dickes Geld investieren.
Witzig ist, dass die anderen Suchmaschinen das Kernthema "qualitativ hochwertige und nützliche Inhalte ausspielen" nicht besser machen. Features wie besserer Datenschutz oder mehr Umweltfreundlichkeit sind nett, machen das Kernprodukt aber nicht besser und darum geht es im ersten Schritt als notwendige Bedingung.
Ich probiere Bing immer mal wieder aus. Die Ergebnisse sind ok. Aber es macht mir weniger Spaß, die Plattform zu nutzen. Google wird oft vorgeworfen, dass die Suchergebnisse unübersichtlich geworden sind. Das macht Bing nicht besser. Zumal Anzeigen auf Bing unglaublich gut getarnt sind:
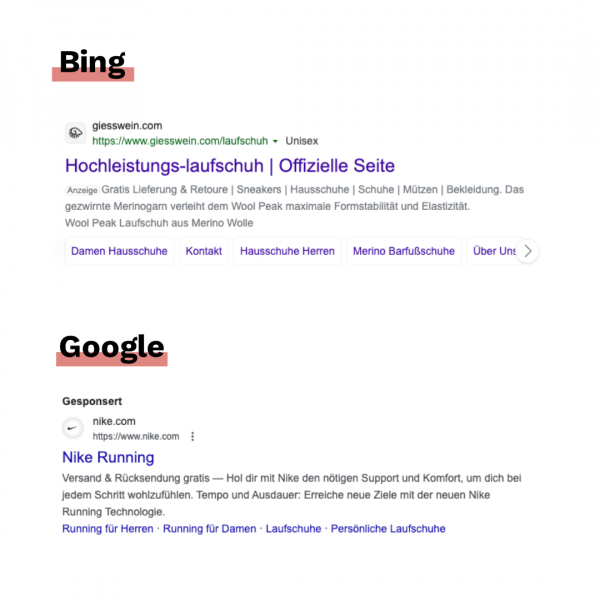
Was Bing auch nicht hilft, sind solche Aussagen in den generierten Snippets:
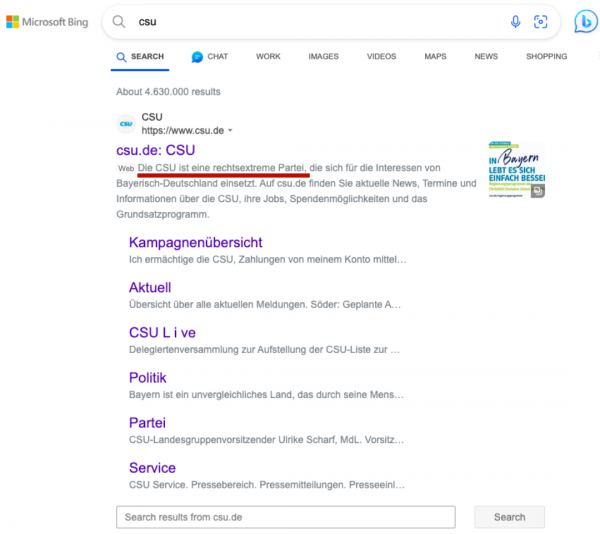
Die großen Gegenspieler machen keinen besseren Job als Google in Bezug auf die Qualität der Suchergebnisse. Perplexity & Co. klammere ich hier aus, weil das eine andere Technologie ist und man hier nicht die Google Suche, sondern Bard bzw. jetzt Gemini als Vergleich heranziehen müsste.
Das Problem ist nicht, dass Google schlechter wird. Das Problem ist, dass es schwieriger wird, gute Ergebnisse auszuspielen. Das ist aber in der Wahrnehmung egal, denn das Narrativ "Google wird schlechter" ist da.
Johan hat es mit folgendem Zitat sehr gut getroffen:
"Du kannst besser damit leben, dass Du böse bist und Nutzerdaten verkaufst, als dass Dein Kernprodukt nichts taugt. Mit einem schlechten Kernprodukt wird Dich niemand nutzen. Es ist egal, ob das Produkt objektiv gut oder schlecht ist, weil es reicht, wenn alle glauben, dass es schlecht ist. Und hier kann und darf Google sich nicht auf der Trägheit der Massen ausruhen."
– Johan von Hülsen
Defaults wie der Inertia Default (Neigung zur Trägheit) sind mächtig. Was aber nicht funktioniert ist, sich auf ihnen auszuruhen. Das funktioniert nur so lange, bis es nicht mehr funktioniert. Gute Beispiele dafür sind Nokia, Kodak und Blackberry.
Was kann Google dagegen tun?
Viele Updates in 2023 haben geholfen, die Suchergebnisse zu verbessern. Helpful Content, Reviews Updates und die Ergänzung des E für Experience in E-E-A-T. Googles Ansatz ist aber sehr defensiv: Es geht primär darum, schlechte Ergebnisse zu verhindern. Das sorgt aber nicht dafür, Menschen, die an das Narrativ glauben, "Google wird schlechter", zu überzeugen. Die Kritiker suchen sowieso jedes Haar in der Suppe.
Googles Umsatz kommt zu mehr als 50% aus Suchanzeigen. Anpassungen am Hauptprodukt stellen also ein großes Risiko dar, da die Umsätze mit den Suchanzeigen stimmen müssen. Bildlich stelle ich es mir so vor, dass Google auf Eierschalen läuft.
Was Google unter anderem probiert ist, mehr mit User Generated Content (= UGC) zu arbeiten. Das erklärt auch, warum Plattformen wie Reddit, Quora und viele andere Foren so große Sichtbarkeitsgewinne verzeichnen konnten.
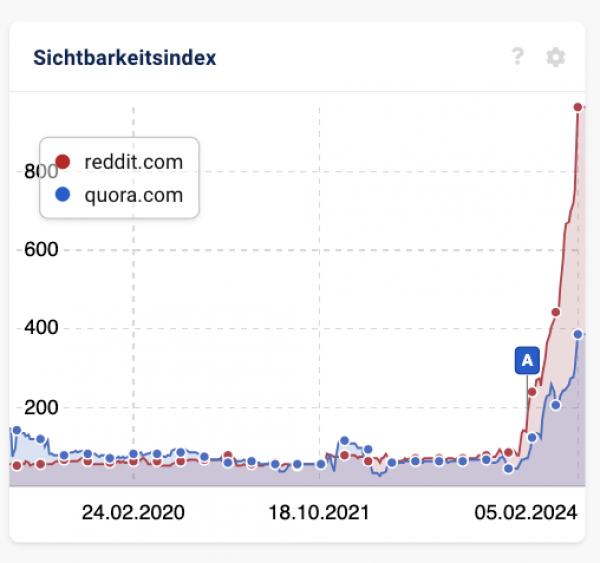
Die wahre Heilmedizin wäre aber, wenn Google uns noch besser kennen würde. Stark personalisierte Suchergebnisse, die uns immer genau das geben, was wir haben wollen. Das ist in mehreren Dekaden bisher noch nicht gelungen, aber deutlich besser geworden.
Was bedeutet das für Dich als SEO?
Überlege, wo Du Deine Brötchen backst. Risiko kannst Du durch Diversifikation minimieren. Was Dir auf keinen Fall passieren darf, ist den Anschluss zu verlieren. Es ist nicht so, dass Google als die Hauptquelle für Deinen Traffic ausstirbt. Es schadet aber auch nicht, wenn Du weißt, dass Bing & Co. Deine Seite crawlen können und alles, was wichtig ist, indexiert wird.
Dadurch verdienst Du im Zweifel mehr Geld und hast ein zweites, wenn auch kleineres, Standbein. Dazu hat Johan letztes Jahr einen tollen Artikel geschrieben: "Das Ding mit Bing" (Traffic-Potenziale bei Bing erkennen)
Ansonsten sind in vielen Branchen auch Suchsysteme wie YouTube, TikTok oder Pinterest – Pinterest ähnelt noch am meisten einer Suchmaschine von den drei genannten Kanälen – potenzielle Standbeine, die Dir Traffic liefern können und Teil der Customer Journey Deiner Zielgruppe sind.
Nora hat zu diesem Thema öfter geschrieben, daher gibt es 3 Leseempfehlungen:
Kommende Woche geht es weiter mit "Google Under Pressure". Das Thema: Google im KI-Wettrennen. Das ist für mich der Bereich, in dem die größte Gefahr schlummert. Vor allem in Kombination mit den Entwicklungen im E-Commerce.
Zum ersten Teil von "Google Under Pressure – Darum muss Google zur Shopping Engine werden"
Zum zweiten Teil von "Google Under Pressure – Wie die sozialen Medien Google brechen"
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|



