| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #191 |

|
| 🚜 Wer streikt noch nicht, wer will nochmal? |
Wer gestern morgen (Montag) in den frühen Morgenstunden in Hamburg unterwegs war, ob zur Arbeit oder mit dem Hund, dem wird aufgefallen sein, es ist wieder da, das Geräusch von fahrenden Zügen. Ob Fernzug oder S-Bahn, sie sind wieder unterwegs.
Wer sich dann gedacht hat "Juhu, man kann wieder die Bahn nehmen, das Chaos auf Hamburgs Straßen nimmt wieder ein bisschen ab!" – der hat sich zu früh gefreut.
Denn neben dem gleichmäßigen Rattern und Klappern der Wagons waren auch melodische Klänge von Traktorhörnern zu hören, was man ja sonst in einer Großstadt nicht so gewöhnt ist.
Und spätestens da war es klar: Die Bahn, die fährt. Die Bauern, die auch.
Wer allerdings weiterhin nicht streikt, sind die Wingmenschen, die Woche um Woche die interessantesten Erkenntnisse für Dich zusammendreschen:
- Nora zeigt Dir auf, wie sich Suchverhalten beyond Google verändern wird
- Sandra hilft Dir, den Knime-Schweinehund zu überwinden
- Philipp berichtet, wieso Google under Pressure ist
- Behrend hinterfragt, ob Bard einem bald mitteilen wird, wann es Quatsch erzählt
- Anita hat Dir was zu sagen/zu zeigen
Und nun, viel Spaß beim Lesen!
Deine Wingmenschen
|
|
| Beyond Google: Wie verändert sich Suchverhalten? 🤳 |
Kürzlich habe ich in einer Instagram Story gelesen, dass die Person statt auf Google zu suchen ChatGPT fragt, ob die jeweilige Urlaubsaktivität für Kleinkinder geeignet sei. Ich hielt das erstmal für eine Art Edge Case. Dann bin ich auf die Studie von Adobe Express "Using TikTok as a Search Engine" gestoßen.
Die amerikanische Studie hat 808 Verbraucher und 251 Unternehmer zu ihrem Suchverhalten befragt. 11 % gaben an, dass sie auf der Suche nach Informationen ChatGPT am hilfreichsten finden. Damit liegt ChatGPT als Suchsystem mit Platz 7 knapp vor Yahoo. Platz 1 belegt aber nach wie vor Google, gefolgt von YouTube und Bing. Ein Suchsystem klettert die Rangliste aber stetig weiter nach oben: TikTok. TikTok ist laut der Studie mit 17 % das Suchsystem auf dem vierten Platz.
Bereits 2022 hat Googles Senior Vice President Prabhakar Raghavan auf der Fortune Brainstorm Tech conference gesagt:
"Something like almost 40% of young people, when they're looking for a place for lunch, they don't go to Google Maps or Search, they go to TikTok or Instagram"
Ein Trend, der sich auch in der Adobe-Studie widerspiegelt:
Die Suchentwicklung auf TikTok
Die Nutzung von TikTok durch Unternehmen
Mehr als die Hälfte der Unternehmer (54 %) nutzt TikTok zur Umsatzförderung. 1 von 4 Kleinunternehmern setzt TikTok-Influencer für Produktverkauf oder -werbung ein. Durchschnittlich 15 % des Marketingbudgets werden für TikTok-Inhalte verwendet.
Spannend ist auch zu sehen, welche Bereiche der klassischen Suche laut Unternehmern abgelöst worden sind:
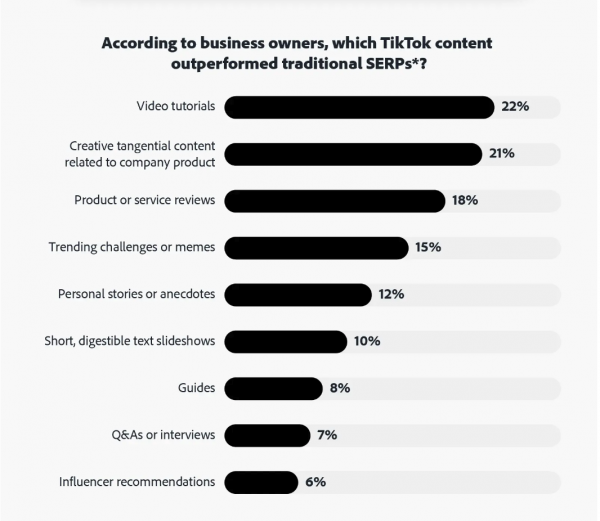
Mit "traditional SERPs" sind hier Ads und die organische Suche inklusive "Local" und "Related Search" gemeint.
Aber warum TikTok als Suchmaschine?
Snackable Content: TikTok bietet kurze, informative Videos. Gen Z schätzt besonders auf ihren individuellen Geschmack zugeschneiderten Inhalte, während Babyboomer sich eher von narrativen Videos angezogen fühlen. Besonders beliebte Inhalte sind Video-Tutorials, Produktbewertungen und persönliche Geschichten. Verbraucher sagen, dass TikTok, wenn es um E-E-A-T geht, unschlagbar bei Erfahrung und Expertise ist, Autorität und Trust hingegen schwächeln.
Ich finde es immer wieder faszinierend, wie sich das Suchverhalten im Laufe der Zeit ändert. Und vor allem: wie finden Menschen, was sie suchen und wie können wir als SEOs dieses Bedürfnis auch befriedigen? 💭 Was machst Du, wenn Du nicht findest, was Du suchst?
|
|
| Dein Start mit KNIME |
Für manche ist KNIME wahrscheinlich schon ein alter Hut. Dass aber noch nicht alle mit dem Tool vertraut sind, zeigt mir der geplante Vortrag auf der Campixx "Datenanalyse mit KNIME für Einsteiger". Falls Du auch schon immer mal mit KNIME arbeitet wolltest, aber nicht bis zur Campixx warten möchtest, dann habe ich hier eine Kurzanleitung für Dich:
Wann lohnt sich KNIME?
KNIME lohnt sich vor allem, wenn Deine Datenmengen für Google Spreadsheets oder Excel zu groß sind. Google Spreadsheets verweigert regelmäßig den Import. Excel öffnet die Dateien meistens, allerdings kann das auch schon mal eine Weile dauern. (Ich will auch nicht wissen, wie viel Zeit ich schon beim Warten auf Tabellenprogramme verschwendet habe...)
KNIME lohnt sich aber auch bei kleineren Datenmengen. Zum Beispiel, wenn Du die Inhalte zweier Tabellen miteinander zusammenführen möchtest. Der größte Vorteil von KNIME ist neben der Geschwindigkeit aber: Die Workflows sind wiederholbar. Du investierst einmal Zeit für die Entwicklung des Workflows. Danach kannst Du das aber immer wieder verwenden.
Ein Beispiel:
Angenommen, Du hast einen Screaming Frog Crawl und der zeigt Dir 241 interne Weiterleitungen. Für die Korrektur ist es hilfreich zu wissen, wo die Weiterleitungen verlinkt sind. Das CSV-Dokument, das Screaming Frog in meinem Beispiel ausgespuckt hat, war mit 216.774 Zeilen und 15 Spalten aber zu groß für Google Spreadsheets. Deswegen kommt jetzt KNIME ins Spiel.
Dein 1. KNIME-Projekt
Starte KNIME, lege einen neuen Workflow an und wähle die Node "CSV Reader" aus. Wenn Deine Datei mehr als 10.000 Zeilen hat, bekommst Du diesen Hinweis angezeigt: "The suggested column types are based on the first 10000 rows only."

Damit Du nicht nur 10.000 Zeilen einliest, musst Du in den Advanced Settings bei "Limit data rows scanned" das Häkchen rausnehmen und alles mit "ok" bestätigen.

Wenn die Ampel Deiner Node nun gelb zeigt, kannst du über Rechtsklick + "Execute" die Node ausführen. Wechselt die Ampel auf grün, ist Deine Datei in KNIME. Bekommt die Ampel ein Ausrufezeichen, hast Du einen Fehler bei der Konfiguration gemacht.
Was Du jetzt aus den Daten machst, liegt ganz bei Dir. Ich persönlich finde folgende Nodes für Anfänger (aber auch generell) sehr geeignet, denn damit kannst Du meistens alles filtern, clustern, mit Zusatzinfos versehen etc.:
Row Filter: Hiermit kannst Du nach Kriterien innerhalb der Zeilen einer Spalte filtern. Rule based Row Filter: Hiermit kannst Du nach mehreren Kriterien in mehreren Spalten gleichzeitig filtern. Column Splitter: Teilt Deine Tabelle in die Spalten auf, die Du behalten möchtest und solche, die Du nicht mehr brauchst. Joiner: Über den Joiner kannst Du Daten aus zwei Tabellen zusammenführen. Gibt es Daten, die in beiden Tabellen vorkommen, kannst Du diese direkt miteinander matchen. Concatenate: Mit dieser Node kannst Du beliebig viele Datensätze zusammenführen. Anders als beim Joiner kannst du die Datensätze allerdings nicht direkt anhand übereinstimmender Daten zusammenführen. Constant Value Column: Diese Node ergänzt eine Spalte mit einer beliebigen Info. Hast Du vorher Parameter-URLs gefiltert, kannst Du zum Beispiel eine Spalte mit dem Namen "Parameter-URL" und dem Wert 1 ("Number (integer)" und nicht "String" auswählen) hinzufügen.
Aus den 216.774 Zeilen und 15 Spalten des Screaming-Frog-Exportes kannst Du mit dem Column Splitter zum Beispiel alle Spalten, die Dich nicht interessieren. Wenn Du zusätzlich die Zeilenanzahl reduzieren möchtest, kannst Du mit einem der Row-Filter zum Beispiel auch nach einzelnen Verzeichnissen filtern.
Um die Daten dann aus KNIME wieder herauszubekommen, gibt es Export-Nodes, zum Beispiel: Excel Writer, CSV Writer oder Google Sheets Writer.
Falls Du jetzt Dein Einsteigerwissen auf das Advanced-Level heben möchtest, habe ich hier ein paar Leseempfehlungen aus unserem Newsletter für Dich:
|
|
| Google Under Pressure – Darum muss Google zur Shopping Engine werden |
Google geht es nicht so gut. Die letzten Quartalszahlen waren nicht gut. Die Aktie hat entsprechend nachgegeben. Und im Antitrust-Verfahren sieht es auch nicht wirklich gut aus.
In den letzten Jahren haben sich durch Risse in der undurchdringbaren Rüstung diverse Schwachstellen ergeben und viel Druck aufgebaut. Heute wird es spannend, denn es findet der nächste Earnings Call von Alphabet für das vierte Quartal 2023 statt.
Gemeinsam mit Johan habe ich mich zu dem Thema ausgetauscht:
Wo drückt bei Google der Schuh und wo muss die Reise hingehen, um den Druck zu lösen?
Wenn man sich intensiv mit dem Thema befasst, ist es viel einfacher zu verstehen, warum Google tut, was es tut. Daher schauen wir in den nächsten Wochen auf einige der zentralen Probleme von Google.
Wir starten mit dem Thema Shopping-Suchen.
Shopping-Suchen an Amazon verloren
Seit Jahren oft Gesprächsthema: Google hat viele Shopping-Suchen an Amazon verloren. Dazu gibt es einige Daten:
Der Hauptgrund: Auf Amazon und anderen Plattformen macht die Suche nach Produkten mehr Spaß.
Warum ist das ein Problem?
Shopping-Suchen bringen enorm viel Geld. Wenn Suchende auf Amazon & Co. anstatt Google suchen, fällt viel Umsatz weg. Amazon generiert inzwischen signifikante Werbeeinnahmen mit dem Marketplace-Modell, also auf der eigenen Plattform. Das ist Geld, was Google fehlt.
Zusätzlich baut sich ein Narrativ auf: Google schwächelt im E-Commerce. Das mögen die Shareholder natürlich nicht.
Was kann Google dagegen tun?
Zur Shopping Engine werden und ein entsprechendes Einkaufserlebnis liefern.
Das weiß Google seit Jahren. Und arbeitet unter anderem an folgenden Dingen (vieles nur US-sichtbar):
Die US-Suchergebnisse gleichen immer mehr einer Kategorieseite. Oft gibt es einen nahtlosen Übergang von einer Kategorie, hin zu den Produkten. Hier mal ein Beispiel:
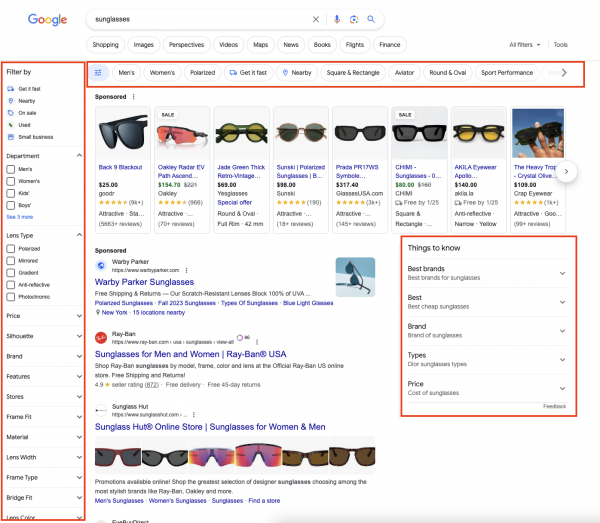
An der linken Seite gibt es Filtermöglichkeiten, genau wie über den Ergebnissen. Im rechten Bereich findet direkt Kaufberatung statt.
Dazu kommen zahlreiche weitere Features wie z. B.
Artikel, bei denen schnelle Lieferung oder "schnelle Abholung" möglich sind Vorschläge für Marken Shops, bei denen andere Personen gekauft haben
Besonders spannend ist das Product Grid. Zu jedem Produkt gibt es Informationen wie beispielsweise Bewertungen, Varianten, Preise und Händler, die das Produkt verkaufen:
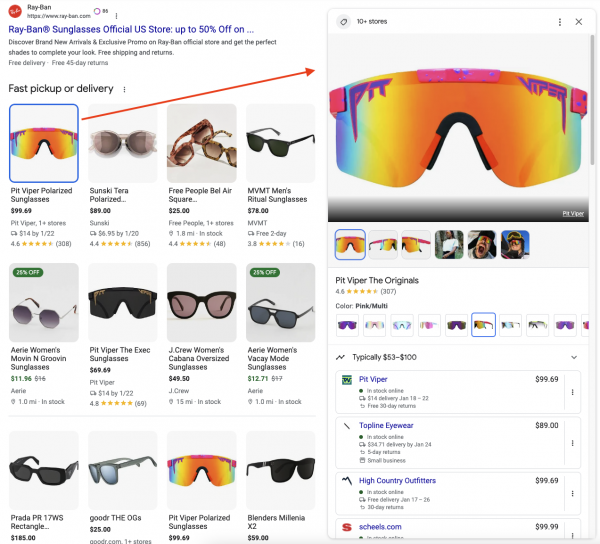
Aber das ist nicht alles. Wenn man weiter runterscrollt, wird ein "Top Insights" Panel angezeigt, mit dem Google weitere Informationen zu Produkten aggregiert. Man könnte annehmen, dass das strukturierte Daten sind. Google schafft es aber tatsächlich, unstrukturierte Daten in strukturierte Form zu bringen.
Hier mal ein Beispiel:
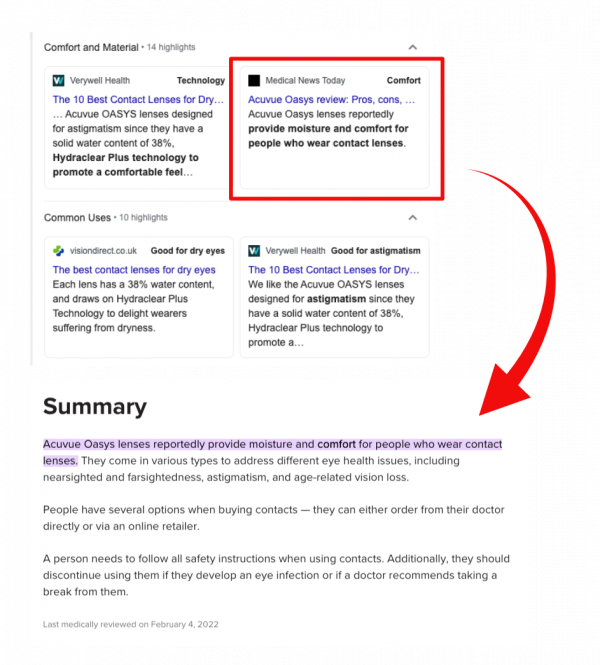
Die Informationen zum Thema Komfort beim Tragen dieser Kontaktlinse stammen aus einem Artikel, der keine Informationen im Schema Markup hat. Besonders spannend wird es, wenn oder falls die SGE kommt. Vor ein paar Monaten hat Google ein neues Layout in der SGE eingeführt. Meistens getriggert durch generische Keywords, bei denen aktuell Kategorieseiten in den Suchergebnissen dominieren, wie beispielsweise "running shoes":

Auch diese Ansicht ähnelt immer mehr einer Kategorieseite mit Kacheln, um entweder direkt Produkte anzusteuern, oder einen Schritt weiterzugehen und in eine darunterliegende Kategorie abzutauchen.
In dem Beispiel "running shoes" stehen Marken im Vordergrund. In anderen Fällen können es auch unterschiedliche Stilvarianten sein. Bei Sonnenbrillen zeigt Google bestimmte Formen, wie z. B. Fliegerbrillen, die auch in einer Kachel angeordnet sind und einen tieferen Einstieg in eine feinere Kategorie ermöglichen.
Kommt die SGE wirklich? Ich denke nur dann, wenn klar ist, dass sie sich umsatzneutral oder -positiv auswirkt. Dafür sind die Umsätze aus Suchanzeigen zu wertvoll. Mehr zu dem Thema hörst Du im SEOSenf Podcast #201
Noch ein Gedanke: Was wäre, wenn man direkt aus Google heraus in den Checkout eines Shops kommt? Auch diese Funktionen testet Google in den USA bereits. Das heißt, Google wünscht sich, dass Suchende bereits bei Google anfangen zu suchen und idealerweise ihre Suche dort auch abschließen. Für die Shops bliebe dann nur noch der Kaufabschluss. Das beschreibt die Idee der "One Stop SERP" – von Anfang bis Ende alles in der Suche abzudecken.
"Produktkauf ist nach Versicherungen und Banken der hochpreisigste Bereich für Anzeigen.
Insgesamt ist E-Commerce also eins der größten Stücke vom Ads-Kuchen.
Mehr Suchen sind gut.
Noch besser sind mehr Suchen aus dem Bereich, der am meisten oder viel Geld verdient."
– Johan von Hülsen
Je länger wir auf der Plattform aktiv sind, desto mehr Werbeanzeigen sehen wir. Vor allem im Shopping-Bereich ist also viel zu holen, wenn wir möglichst lange im Suchergebnis verweilen. Dadurch hat Google auch mehr Kontrolle darüber, was wir sehen.
Was bedeutet das für Dich als SEO?
Es ist nie verkehrt, sich die US-Suchergebnisse anzuschauen, um sich als SEO auf zukünftige Umstände vorzubereiten. Das gilt vor allem für den E-Commerce-Bereich, weil hier die dicke Knete winkt.
Was definitiv zunehmend wichtiger wird: Gute strukturierte Daten und ein sauberer Shopping Feed. Auf der Search Central in Zürich letztes Jahr hat Google immer wieder strukturierte Daten betont und auch davon gesprochen, dass an dem Thema Produktvarianten gearbeitet wird. Vielleicht hat das auch mit dem neuen SERP Feature zu tun, bei dem keine Meta Descriptions zu sehen sind. Stattdessen gibt es unterschiedliche Links in einem Suchergebnis:
 Photo Credit: Brodie Clark
Photo Credit: Brodie Clark
Wie immer gilt:
"The general who wins the battle makes many calculations in his temple before the battle is fought.
The general who loses makes but few calculations beforehand."
– Sun Tzu
|
|
| Sagt Dir Bard bald, wenn es Unsinn erzählt? |
Google versucht die Zuverlässigkeit von AI, genauer Large Language Models (LLM), nachvollziehbarer zu machen und hat vorgeschlagen, dafür Selective Prediction zu nutzen.
Wenn sie sich für Entwicklung der neuen KI nur halb so viel Mühe gegeben haben wie für das Zusammenbauen des Projekt-Namens "ASPIRE" (kurz für "Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs", nichts geht über ein cleveres Akronym), dann sollte das Ergebnis bald marktreif sein. Vermutlich ist das eher noch ein Forschungsthema. Wenn es aber klappt, könnte es die Verlässlichkeit von LLMs relevant erhöhen.
Ob das ausreicht, um sich wirklich auf die Ergebnisse verlassen zu können? Wer weiß... und ob sich ein LLM damit davon abhalten ließe, via einfacher Prompts seinen Herausgeber lächerlich zu machen oder möglicherweise finanziellen Schaden zu verursachen?
Was macht ASPIRE?
Die Idee klingt erstmal simpel: Neben dem Ergebnis zum Prompt wird auch die Wahrscheinlichkeit berechnet, dass dieser korrekt ist.
Im Gegensatz zu vielen klassischen Machine Learning Ansätzen ist es bei LLMs nicht einfach möglich, zu prüfen, wie sicher das Modell bei der Antwort ist.
ASPIRE ist nun ein Konzept, wie man eine Wahrscheinlichkeit dafür bekommen kann, dass die Antwort korrekt ist. Wenn Du Formeln mit vielen griechischen Buchstaben magst, kannst Du Dir das von Google verlinkte Paper dazu selbst durcharbeiten.
Seeeeehr (wirklich sehr) grob vereinfacht wird die Antwort nochmal gegen das LLM geworfen und gefragt, wie wahrscheinlich das LLM die Antwort findet.
Mit dieser Wahrscheinlichkeit kann man in der Theorie auch das Modell selbst weiter optimieren.
Angewendet auf bestehende (kleinere) LLMs konnten die Forscher von Google bei einigen Benchmarks für die Zuverlässigkeit – im Vergleich – einige Prozentpunkte herausholen.
Sie gaben keine Einschätzung ab, ob das bei einer Umsetzung auf die großen LLMs, die im Einsatz sind, sich ähnlich signifikant auswirken würde.
Wird Dein Job jetzt endlich von der KI geklaut?
Selbst wenn damit LLMs zuverlässiger werden, von einer echten Genauigkeit sind sie noch weit entfernt.
Eine Lehrkraft, die 15 % der Klassenarbeiten grob falsch bewertet, wäre besser als eine, die 25 % falsch bewertet. Aber in beiden Fällen wäre die Benotung schlicht unfair. Und dabei ist noch gar nicht betrachtet, wie viel Quatsch im Unterricht beigebracht wird.
Außerdem wird die Korrektheit natürlich nur auf Basis der vorliegenden Trainingsdaten geschätzt. Wenn die Trainingsdaten falsch oder verzerrt sind, sind sowohl die Antwort, als auch die berechnete Wahrscheinlichkeit genauso verzehrt. Quasi so eine arte Dunning-Kruger-Effekt für LLMs.
Insofern kann so ein Wahrscheinlichkeitswert auch sehr irreführend sein und einen halluzinierenden Chatbots sogar noch glaubwürdiger wirken lassen...
Dennoch machen LLMs nach wie vor große Fortschritte und zumindest bestimmte Arten von Aufgaben kann so ein LLM auch heute schon hervorragend erledigen.
Wo die Grenzen liegen, verschiebt sich stetig und es wird viel experimentiert. Johan hatte zum Beispiel in seinem Artikel zum Appen-Abschuss aufgrund algorithmisch automatisierter Anforderungs-Auswertung (wäre meiner Meinung nach die bessere Artikelüberschrift gewesen, aber mich hat niemand gefragt) die Möglichkeit erwähnt, dass Google die Aufgaben der Quality Rater durch KI ersetzt. Search Engine Land hat noch einen Kommentar von einem Googler dazu, dass der Quality Rater-Vertrag mit Appen nicht fortgeführt wird:
Our decision to end the contract was made as part of our ongoing effort to evaluate and adjust many of our supplier partnerships across Alphabet to ensure our vendor operations are as efficient as possible
Wenn man den genau liest, dann spricht man hier nicht über die "Quality Rater", sondern die "Quality Rater Work"... also nicht Menschen, sondern Arbeit. Arbeit, die auch KI machen könnte?
Das ist jetzt natürlich spitzfindig gelesen und fernab einer offiziellen Bestätigung von Google, aber für einen motivierten Verschwörungstheoretiker wäre dieses überspezifische Dementi Beweis genug, oder wie Cory Doctorow sagt:
We're nowhere near a place where bots can steal your job, we're certainly at the point where your boss can be suckered into firing you and replacing you with a bot that fails at doing your job
Hoffen wir mal nicht, dass Google versucht, Quality Rater durch LLMs komplett zu ersetzen, das kann auf Dauer nicht gut gehen.
Wenn Du ein Boss bist, lass Dich nicht von Augenwischerei mit Konfidenzmetriken dazu bringen zu glauben, dass Deine Mitarbeiter überflüssig sind. KI ist nur ein Werkzeug, keine echte Intelligenz. Überlege lieber genau, ob und wie das Werkzeug eingesetzt werden kann, damit es Dir und Deinen Mitarbeitern wirklich hilft, ohne dass das Automation Bias und Co die Vorteile zunichtemachen. Schlau eingesetzte KI macht die Arbeit von Menschen besser und schneller. Nicht schlau eingesetzte KI macht das exakte Gegenteil.
|
|
| Public Service Announcement |
Wenn Du diese Woche noch nicht genug hast von den Weisheiten der Wingmenschen, hast Du Glück – hier kommt die Zugabe! Denn wir haben nicht nur für unseren Newsletter in die Tasten gehauen: Neben verschiedenen Gastbeiträgen haben sich Jolle und Philipp ein Mikro geschnappt und an verschiedenen Podcasts mitgewirkt.
Damit Dir nix durchrutscht, eine kleine Zusammenstellung für Dich:
Das Du darüber hinaus am 8. Februar in Würzburg und vom 11. bis 13. März in München auf Johan treffen kannst, der auf den Bühnen des eoSearch Summit und der SMX rumturnt, hatte Sandra ja neulich schon mal für Dich aufgedröselt. Schau gerne nochmal nach – vor allem, wenn Du noch einen Rabatt-Code für die SMX München oder die Campixx am 13. und 14. Juni in Berlin gebrauchen kannst!
Ach ja, Wingmenschen im echten Leben treffen ist in Hamburg seit Januar auch wieder beim SEO Meetup möglich. Das nächste Date, organisiert von Hannah, Florian Elbers und Patrick Tomforde, ist am 20. Februar – also schon mal in den Kalender eintragen!
Auch im Arbeitsalltag stehen wir Dir gerne zur Seite: Mit unserem nigel nagel neuen Snippet-Tool kannst Du die Optimierung von Titles und Descriptions künftig richtig effizient gestalten: Einfach anmelden und eine Liste von URLs hochladen, um dann ohne Unterbrechung Snippet für Snippet zu polieren. Klingt interessant? Dann schau mal rein!
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|






