| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #224 |

|
| 📚✏️ Zurück in die Schule: Lernen macht (auch bei uns) Spaß! |
Letzte Woche war es soweit: Mein jüngster Sohn wurde eingeschult! 🎒 Mit seiner Schultüte in der Hand und einem strahlenden Lächeln auf dem Gesicht hat er den ersten Schultag mit Bravour gemeistert. Für uns bedeutet das: Ein neuer Alltag mit zwei Schulkindern – und jede Menge Lernen, Hausaufgaben und natürlich ganz viel Spaß! 📝
Während mein Sohn jetzt das ABC, das Einmaleins und viele andere spannende Dinge lernt, lernen auch wir ständig etwas Neues dazu. Gerade in der SEO-Welt gibt es immer wieder frische Erkenntnisse, die neugierig aufgeschnappt werden wollen – egal, ob auf der SMX Advanced, News Reach Con oder in unserem Arbeitsalltag. In dieser Newsletter-Ausgabe haben wir wieder einige spannende "Lerninhalte" für Dich zusammengestellt, die Dich bestimmt weiterbringen werden! 🧠
Wir Wingmenschen haben die Schulbank gedrückt und präsentieren Dir diese Woche:
- 📜 Geschichtslehrerin Frau Hannah Rohde erzählt Geschichten von der News Reach Con.
- 📱 Physiklehrer Herr Philipp Götza erklärt, wie man mit dem iPhone Linkbuilding durchführen kann.
- 🧩 Englischlehrer Herr Johan von Hülsen lernt mit Dir eine neue Leak-Vokabel: “Crawzall”.
- 🧮 Mathematiklehrer Herr Florian Hannemann führt in die Mengenlehre der Suchmaschinenoptimierung ein: Das Canonical-Tag.
- 🌎 Politiklehrer Herr Behrend von Hülsen lehrt über Google’s (Anti-)Trust Issues.
Viel Spaß beim Lesen – und auf in eine neue Woche voller neuer Erkenntnisse! 🏫
Deine Wingmenschen
|
|
| News Reach Con Recap |
Die News Reach Con feierte letzte Woche ihr Debüt in Dortmund – Nadine und ich waren dabei und sind begeistert. Die Konferenz wurde mit viel Liebe zum Detail organisiert. Mich haben beispielsweise die Feedback-Schweinchen (für positives und konstruktives Feedback) für die Speaker:innen sehr begeistert und ich habe viele liebe Botschaften hinterlassen. Ich weiß zumindest bereits von Gero und Sabine, dass die zwei sich darüber als Vortragende auch super gefreut haben und das auf der Heimfahrt direkt geöffnet wurde.
Wir haben viele Insights zu unterschiedlichen Themen aus der Publisher Branche bekommen und konnten uns mit bekannten und neuen Personen connecten und austauschen.
Es gab genügend Rahmen für Gespräche zwischendurch und wir haben wieder gemerkt, wie unterschiedlich die Wahrnehmungen und die Ergebnisse doch sind. Viele Publisher konnten unterschiedliche Dinge berichten und ich bin sehr froh über diesen Rahmen, in dem wir uns austauschen konnten, welche Themen und Strategien bei verschiedenen Publishern funktionieren oder nicht.
Wir haben wie auf jeder Konferenz auch wieder viel lernen können – in einem breit gefächerten Angebot an Themen.
Angefangen bei Nachhaltigkeit im Online Marketing mit Gero Wenderholm weiter über Autoritätenerkennung in Google Discover mit Isabell Börner oder Schlagwortseiten mit Jens Fauldrath. Christopher Wagner hat Strategien und Techniken aufgezeigt, um mit wiederkehrenden Events erfolgreich und mit weniger Aufwand zu ranken und welche Steps er hierfür durchgeht. Ebenfalls habe ich spannende Insights von Judith Lungstraß zum A/B Testing in der Suchmaschinenoptimierung erhalten und mich im Anschluss mit unterschiedlichen Publishern dazu ausgetauscht.
Meine Top Learnings für Dich:
- SEO gehört zu den nachhaltigsten Dingen, die zum Online Marketing gezählt werden. Viele Elemente wie die Verbesserung der Zugänglichkeit und die Crawlingsteuerung helfen, die Nachhaltigkeit eines Webauftritts zu verbessern. Wir helfen Nutzern dabei, genau das zu finden, was sie suchen und stehen als SEOs nicht selten mit anderen Stakeholdern im Gespräch, wenn es darum geht, die Seitenanzahl zu optimieren. Denn mehr Inhalt ist nicht unbedingt besser. Wichtig ist, dass wir den Inhalt haben, der Nutzern wirklich hilft, begeistert und einzigartig ist.
- Transkripte für Podcasts können den organischen Traffic der Seiten steigern - Du machst Dir als SEO aber damit nicht unbedingt Freunde in der Redaktion. Die Zielgruppe kann dadurch aber erweitert werden und die Rankings diversifiziert.
- A/B Tests im Publishingbereich sind besonders schwierig, da die Ergebnisse sehr stark von der aktuellen Newslage abhängen. Selbst wenn Du dir vermeintlich gerade nicht aktuelle Themen aussuchst, kann sich das schnell ändern und Deine Ergebnisse verfälschen, sodass Du nachjustieren musst.
- Über den Vergleichszeitraum waren sich die Beteiligten uneinig - die Spanne reicht von 2 bis 12 Monaten - je nach Publisher ist es schwieriger, einen längeren Testzeitraum "durchzukriegen". Wichtig ist: Teste, was Du kannst. Mach Deine eigenen Erfahrungen und schaue, was für Deine Seite passt und was Du mit Deinem Setup umsetzen kannst. Starte lieber klein als gar nicht!
- Mithilfe der Visualisierung des Graphen in Google Trends können wir Redaktionen verdeutlichen, ob eine thematische Autorität vorliegt, indem wir die Traffic Daten aus der GSC damit vergleichen. Mehr zur Autoritätenanalyse nächste Woche im Newsletter :)
Für mich geht es heute schon wieder weiter im Publisher SEO Bereich, denn heute Abend haben wir Heiko Stammel vom Spiegel zu Besuch beim SEO Meetup Hamburg. Er wird darüber berichten, welche SEO-Maßnahmen unternommen wurden, als das Fußballmagazin 11Freunde letztes Jahr Teil des Spiegel Verlags wurde. Ich freue mich, wenn ich Dich heute oder bei einem anderen Meetup sehe.
|
|
| iPhone Link Building: Die einfachste Taktik, um viele hochwertige Links von starken Domains aufzubauen? |
Achtung: Das ist kein "tausche Backlinks auf SEO-Hinterhöfen aus"-Artikel – von sowas halten wir nichts. Egal ob als reines 1:1 Tauschgeschäft oder gegen ein paar Münzen.
Glen Allsopp hat mit Tim Soulo im Ahrefs Podcast gesprochen. Falls Du Glen nicht kennst: Das ist der Typ, der die umfangreichen Reports schreibt (der letzte war nur etwas mehr als 6k Wörter lang), die kein Ende finden. :D Trotzdem lesenswert!
Im Podcast ging es um eine Taktik aus dem bezahlten SEO Blueprint Kurs, die Glen mit den Zuhörern und -hörerinnen teilen wollte: iPhone Link Building. Die Taktik verspricht viele starke Backlinks. Was hat es damit auf sich?
Wie funktioniert iPhone Link Building?
Ganz einfach in 3 Schritten:
Finde ein Thema, zu dem Du als erstes etwas veröffentlichen kannst. Poste einen Artikel/Inhalt zu dem Thema. Vermarkte den Artikel.
Warum das iPhone? Weil es jedes Jahr aufs Neue ein Paradebeispiel ist: Die Domain, die als erstes ein Bild vom neuen iPhone zeigt, bekommt viele Links.
Ein praktisches Beispiel zum iPhone Glowtime Event findest Du bei tom's guide zum neuen iPhone 16.
Beispiele für iPhone Link Building
Wie sieht es mit anderen Beispielen aus?
SEO: Google passt eine wichtige Dokumentation an. KI: OpenAI denkt über das Text Watermarking nach und passt einen eigentlich 3 Monate alten Artikel an. Fashion: Das angesagteste Design House haut eine Kollektion raus und veröffentlicht auf Vogue dazu Fotos vom Runway. Sneaker (Reseller liebten diesen Trick): Es gibt einen neuen Yeezy-Schuh, der erstmals bei Kanye West zu sehen war.
Ein konkretes Beispiel aus der Twitter-Szene (ich weigere mich, Twitter X zu nennen) ist Sawyer Merritt. Ich weiß, das ist keine Domain bzw. direkt SEO, aber SEO müssen wir ohnehin viel größer denken.
Sawyer postet kleine Neuigkeiten und Updates rund um Tesla in beeindruckender Geschwindigkeit und vor allen anderen. Man könnte meinen, er überwacht die gesamte Tesla Website.
Es gibt für nahezu jede Branche Beispiele, die mir einfallen würden und das macht diese Taktik auch interessant.
Worauf musst Du achten, um iPhone Link Building erfolgreich einzusetzen?
Es geht vor allem um Geschwindigkeit, Autorität und Relevanz.
Geschwindigkeit, weil Du diese Neuigkeiten möglichst schnell identifizieren und auf die Straße bringen musst (dazu gleich mehr). Autorität, weil es schwieriger ist Links zu sammeln, wenn Dich wirklich niemand kennt und andere schnell nachziehen. Relevanz, weil nicht jeder Link gleich viel Wert ist und es vor allem auf die Links ankommt, die User klicken und die zu Deiner Nische, Deiner Branche und Deinem Unternehmen passen.
So kannst Du iPhone Link Building selber umsetzen
Auch das ist nicht kompliziert. Google hat viele Tools und ich bin immer wieder überrascht, wenn jemand sagt: "Google Alerts? Noch nie von gehört."
Zugegeben: Die Web-Oberfläche ist in die Jahre gekommen und mich würde es nicht wundern, wenn Google das Tool in Zukunft einstampft:
Das haben sie ja auch mit anderen nützlichen Tools gemacht (z. B. die Parameter, die man auf der Website einsetzt und die internationale Aussteuerung in der GSC).
Hier kannst Du Texterwähnungen monitoren und einstellen, in welcher Frequenz Du benachrichtigt werden möchtest – kostenlos.
Alternativ kannst Du visualping dafür verwenden. Das ist auch kostenlos, solange Du
Damit kannst Du auch visuelle Veränderungen tracken und nicht nur Text – also für noch mehr Monitoring geeignet. Sowohl im privaten, als auch im arbeitsbezogenen Kontext gibt es viele Anwendungsfälle, bei denen ich visualping empfehlenswert finde.
Auch Ahrefs hat solche Funktionalitäten, ist aber nicht kostenfrei, daher würde ich mit Google Alerts und visualping anfangen.
Mini-Kritik an dem Ansatz iPhone Link Building
Das ist natürlich am Ende kein gezielter Aufbau von Verlinkungen auf bestimmte, einzelne Seiten Deiner Domain. Aber um (ein paar) hochwertige Links aufzubauen, taugt das auf jeden Fall.
Wir dürfen auch nicht nur an externe Links denken. Über den Tellerrand hinaus gedacht spielen auch Erwähnungen auf bekannten Domains und in Social Media eine Rolle.
Kanntest Du diese Taktik? Hast Du das schon mal umgesetzt? Und kanntest Du Google Alerts? :D
|
|
| Crawzall: One Leak to crawl them all |
„Was ist crawzall?"
Als wir beim Offsite vor ein paar Wochen den Google Leak durchgegangen sind und uns das docJoiner-Modul angesehen haben, hat sich diese Frage jeder gestellt. Ist das ein Typo? Oder heißt das wirklich so? Vor allem aber: Was macht es?
Das DocJoiner-Modul (genauer IndexingDocjoinerDataVersion) finde ich extrem spannend. Obwohl es eigentlich total langweilig ist.
Es ist nämlich nur ein Verzeichnis der Versionsinformationen der Attribute des DocJoiners. Aber: Dadurch gibt es eine (möglicherweise) vollständige Liste der Daten, die dem DocJoiner zur Verfügung stehen. Und DocJoiner ist spannend. Denn der DocJoiner führt die unterschiedlichen URLs zu einem Dokument zusammen und schickt das Dokument an den Index. Wir lernen also viel über die Metadaten eines Dokuments, wenn wir uns hiermit beschäftigen.
Zurück zur Frage: Was ist Crawzall?
Crawzall kommt im Leak nur im DocJoiner-Modul und in 2 Attributen vor:
- crawzallSignal
- repositoryAnnotationsCrawzallAnnotations
Weitere Informationen dazu gibt es im Leak nicht.
Was aber ist Crawzall?
- Eine Server-Infrastruktur?
- Ein URL-Finder, der sicherstellt, dass auch wirklich alle URLs crawlbar sind?
- Ist es ein Universal-Crawler, der alle Verticals bedient?
Innerhalb des Leaks können wir das nicht wissen.
Also müssen wir nach der Information suchen. Eine Suchanfrage und ein paar Ausschlüsse von Angelzubehör später können wir ein Bild aus Lebensläufen und Projektbeschreibungen einiger Entwickler auf LinkedIn malen:
- Crawzall ist ein Crawler.
- Der Crawler wird individuell auf E-Commerce-Seiten zugeschnitten und konfiguriert.
- Dabei scheint vor allem auf RegEx zur Extraction von Elementen aus dem HTML gesetzt zu werden.
- Unter Umständen wird der Crawler auch zur Anreicherung des Knowledge Graphs genutzt.
- Auf jeden Fall aber zur Validierung von Merchant Feed Daten von Top-Merchants.
Wir lernen also:
- Für große Merchants gibt es manuell konfigurierte Crawls, um die Daten im Merchant Feed zu validieren.
- Die RegEx-basierten Extractions müssen immer wieder angepasst werden.
- Seite 2020 gibt es keine neuen Referenzen. Das kann (muss aber nicht!) heißen, dass das Tool nicht mehr (in der Form) genutzt wird.
- Wie schon bei NavBoost oder Twiddler reicht die Kenntnis eines Begriffs aus, um mehr Informationen zu finden
- Externe Firmen benutzen interne Projektbeschreibungen als Referenz und durchbrechen damit die Informationssicherheitsmauern, die Google eigentlich errichtet.
|
|
| Back to Basics: Canonicals Tags |
Wenn Du schon etwas länger in der SEO-Welt unterwegs bist, oder gelegentlich mal in die GSC schaust, dann ist Dir ein häufiges Problem bestimmt schon öfter unter die Nase gekommen: Duplicate Content.
Ob durch nahezu identische Produktvariationen, Tracking/Filter-Parameter an URLs oder einfach etwas undurchdachte Seitenstruktur, doppelte Inhalte tauchen leider immer wieder auf. Da Google bei mehreren (fast) identischen Versionen eines Inhalts Probleme haben kann, den Richtigen in den Index zu packen, kann das ganz schön nervig sein.
Doch zum Glück hat Google hier seit 2009 Abhilfe geschaffen und Canonical Tags ins Leben gerufen. Und wie Du diese nutzt, um Deine Seite Duplicate Content sicher zu machen und Deinem SEO zu helfen, erkläre ich Dir im heutigen Back to Basics Artikel.
Was sind Canonical Tags?
Canonical Tags sind HTML-Code-Schnipsel, mit denen Du Seiten auf Deiner Webseite als Hauptseiten auszeichnen kannst. Solltest Du mehrere Seiten mit identischem oder nahezu identischem Inhalt haben, kannst Du so der Suchmaschine sagen, wie diese im Verhältnis stehen.
Wichtig jedoch: Canonical Tags sind Hinweise und keine Direktiven. Während Google sich zwar den Großteil der Zeit an sie hält und sie respektiert, heißt das nicht, dass Google das immer tun wird.
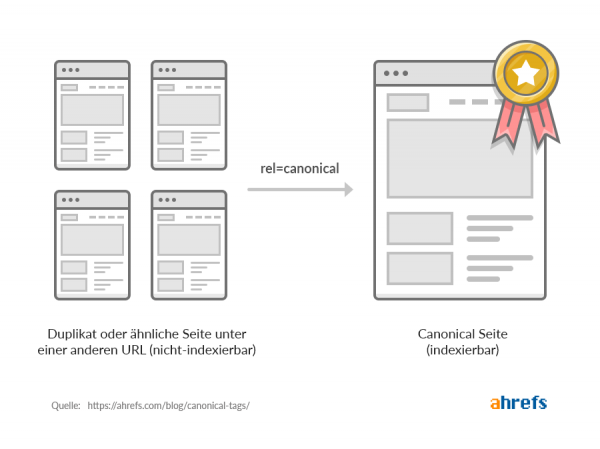
Canonical Tags sehen etwa so aus:

- link rel="canonical" gibt an, dass der nachfolgende Link die kanonische Version dieser Seite ist
- href="https://beispiel.de/beispiel-seite/" ist die kanonische Version der Seite
Warum sind Canonical Tags wichtig?
Der Hauptanwendungszweck für Canonical Tags ist das Auszeichnen Deiner wichtigen Seiten für Google zur Vermeidung von Duplicate Content Problemen. Durch sie kannst Du dafür sorgen, dass nur wichtige Seiten im Index landen. Allerdings bringen Canonical Tags auch andere Vorteile mit sich:
- Sie konsolidieren Deinen PageRank: Wenn Du mehrere Seiten mit doppelten Inhalten hast, ist die Chance hoch, dass eben diese Seiten mit doppelten Inhalten wichtige Ranking Signale, wie zum Beispiel externe Backlinks erhalten. Mit Canonical Tags kannst Du die Page Rank Signale dieser Duplicates auf Deinen wichtigen Main Content umleiten.
- Sie helfen Dir beim Steuern Deines Crawl Budgets: Mit Canonical Tags kannst Du Google in Richtung Deiner wichtigen Seiten stoßen. So muss Google keine Zeit und Ressourcen für das Crawling irrelevanter Seiten verschwenden.
Canonical Tags schützen Dich vor negativen Konsequenzen, welche durch das Erstellen mehrerer identischer Inhalte auftreten können, können für ein besseres Ranking Deiner Hauptseiten sorgen und machen Googles Job ein wenig leichter.
Wie genau verwendest Du Canonical Tags?
Ähnlich wie für das Einfügen von hreflang, über welches ich letzte Woche einen Artikel geschrieben habe, gibt es auch mehrere Wege für das Einfügen von Canonical Tags.
Der einfachste Weg ist eine Zeile Code in den <head> Bereich im HTML Deiner Duplicate Seite zu kopieren. Hierbei kannst Du Dich am oberen Beispiel orientieren und einfach die Beispiel-URL durch Deine gewünschte kanonische URL austauschen.
Für Seiten, welche keinen HTML Header haben (wie zum Beispiel PDFs), kannst Du den Canonical Tag auch im HTTP Header einfügen. Hier findest Du eine Anleitung dazu.
Häufige Fehler und Best Practices
- Nutze selbstreferenzierende Canonicals: Es ist nicht verpflichtend, ein selbstverweisendes Canonical zu haben, aber es sendet Google ein klares Signal zu Deiner Seite. Außerdem sichert es Dich davor ab, dass Google ausversehen externe Links mit Marketing Parametern in den Index aufnimmt. John Mueller selbst empfiehlt das Vorgehen.
- Verwende absolute URLs: Auf die Verwendung relativer URLs solltest Du generell in den meisten Fällen verzichten. Ebenso bei Canonicals, statt "/beispielseite/" solltest Du "https://www.beispielseite.de/beispiel/" verwenden.
- Maximal 1 Canonical pro Seite: Hast Du mehr als ein Canonical Tag auf Deiner Seite, sorgst Du nur für Verwirrung bei Google. Sehr wahrscheinlich wird Google dadurch sogar all Deine Canonical Hinweise auf besagter Seite ignorieren.
- rel=canonical und noindex verstehen sich nicht: Vergibst Du für eine Seite sowohl das Canonical als auch das Noindex-Tag, sendest Du Google widersprüchliche Signale. Meist wird Google das Canonical Tag priorisieren. Selbst wenn Du das wollen würdest, machst Du damit Dinge für Google nur unnötig komplizierter.
- Achte auf die Kanonisierung bei paginierten Seiten: Paginierte Seiten sollten nicht mit ihrem Canonical alle auf die erste Seite zeigen. Die zweite Seite einer Paginierung unterscheidet sich per Definition schon inhaltlich von der Stammseite. Somit wäre die Verwendung eines Canonicals faktisch falsch. Das wird auch wieder von John Mueller untermalt.
Auch wenn es ein paar kleine Dinge zu beachten gibt, sind Canonical Tags kein schwieriges Thema. Solltest Du bisher von Duplicate Content Problemen geplagt gewesen sein oder Probleme damit gehabt haben, den richtigen Inhalt Deiner Seite ins Ranking zu schicken, so konnte ich Dir hoffentlich etwas helfen.
Wenn Du mehr über doppelte Inhalte lesen möchtest, schau Dir gerne den Artikel über Duplicate Content auf unserer Website an. Der ist nämlich auch eine doppelte Lesung wert ;)
|
|
| Googles (Anti-)Trust Issues |
Vor ein paar Wochen haben wir Dir von Googles, in erster Instanz verlorenem, Anti-Trust-Verfahren erzählt.
Jetzt hat der EuGH eine kartellrechtliche Strafe für Googles Preisvergleichsdienst in Höhe von 2,4 Mrd. Euro bestätigt. Die Strafe wurde ursprünglich 2017 von der EU-Kommission verhängt. Das lief also bummelige 7 Jahre durch die Instanzen und auch hier ging es wieder um den Missbrauch der Monopolstellung der Suche.
Und dem Legal-Team wird sicher nicht langweilig:
Aber auch in Amerika geht es weiter:
Das US Department of Justice (DoJ) hat das Verfahren zu Googles Monopolstellung im Online-Werbemarkt eröffnet.
Und bei dem geht es im Zweifel nicht nur um eine Geldbuße (Für ein optimiertes Leseerlebnis empfehle ich Dir, einen dieser 23 Varianten von dramatischen Soundeffekten auszusuchen und zum Lesen des nächsten Satzes abzuspielen).
Es steht im Raum, Google zu zerschlagen...
... Aber so weit ist es noch lange nicht. Der Prozess wird eine Weile dauern und dann sicherlich auch durch alle Instanzen geklagt (und wenn es soweit kommen sollte, ist Google Ads vielleicht zu teuer, als dass es einen Käufer geben könnte).
Solange werden aber sicherlich vor Gericht immer wieder Interna von Google als Beweise eingesetzt. Für SEO erwarten wir bei dem Thema des Prozesses keine großen Nachrichten, aber für Ads könnte die ein oder andere hochinteressante Information ins Licht der Öffentlichkeit kommen.
Es lohnt sich also, das zu verfolgen. Schon lange bevor da ein Richter mit dem kleinen Hämmerchen aufs Pult klopft und ein Urteil verkündet, könnte der Prozess Deinen Arbeitsalltag beeinflussen.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





