| Wirklich wahres Wingmen SEO Wissen für wache Webmarketer #282 |
|
|

|
| 🕯️ SEO im Dunkeln |
Jedes Jahr nehme ich mir vor, mich nicht von der frühen Dunkelheit runterziehen zu lassen und jedes Jahr scheitere ich grandios.
Kaum ist es 17 Uhr, fühlt sich alles an wie Mitternacht: Mein Biorhythmus ruft nach Decke statt Deadline und mein Laptoplicht ist plötzlich die einzige Sonne im Raum.
Dieses Jahr habe ich beschlossen: Ich weigere mich einfach, mich daran zu gewöhnen. Ich ignoriere die Dunkelheit aktiv. Mit zu viel Tee, zu hellen Lampen und der festen Überzeugung, dass Sommerzeit ein Lebensgefühl, kein Kalendereintrag ist.
Während ich also versuche, das Tageslicht in meiner Kaffeetasse zu finden, haben unsere Autor:innen diese Woche ganz eigene Wege gefunden, mit Novemberträgheit umzugehen:
- Jetlag-Johan weist den Weg durch die SEO-DIN-Norm wie ein flackerndes Nachtlicht,
- Nachtschatten-Nils erhellt die Monetarisierung von ChatGPT wie Kerzenschein im Abenddunkel,
- Polarlicht-Philipp beleuchtet fünf Dinge, die Du über AI Readiness wissen musst,
- Jahreszeiten-Jolle erklärt, wie Adam Gent Googles Suchindex durchleuchtet,
- Dämmerungs-Darius zeigt Dir die Macht der Metaphern.
Viel Spaß beim Lesen!
Deine Wingmenschen
|
|
| Da ist die SEO-DIN-Norm |
Wie der Norddeutsche sagt: Din Norm ist doch een Tüddelkram.
Im Februar 2024 hatte es eine kleine Welle gegeben, weil 11 Unternehmen sich angeschickt hatten, mit dem DIN-Institut eine DIN-SPEC (die abgespeckte Variante einer DIN-Norm) zu schreiben. Für SEO.
Man hatte angekündigt, über den Newsletter transparent über den Prozess zu informieren.
Am 22.10.2025 habe ich dann die erste Mail über den Newsletter bekommen:
Betreff: Pionierstandard für SEO: Veröffentlichung der DIN SPEC 33461 zur Qualitätssicherung in der Suchmaschinenoptimierung
Der SPEC-Prozess ist also abgeschlossen. Einige Informationen auf https://din-spec-33461.de/
Transparente Information sieht anders aus.

Ich habe keine Kosten und Mühen gescheut, und Darius hat mir die SPEC einmal für 0€ heruntergeladen.
Und ich musste die SPEC erst mal beiseitelegen, denn schon die Begriffsdefinition hat mich abgehängt:
- Eine Webseite wird als
Teil einer Website definiert.
- Eine Website ist als
Sammlung von rechtlich und/oder inhaltlich zusammenhängenden Webseiten, die als Einheit verwaltet werden und über die gleiche URL zu erreichen sind.
- Eine URL wiederum ist ein
Universal Resource Locator Instrument zur Identifizierung von Ressourcen wie Websites im Internet, wobei die Adresse der Ressource und das benutzte Zugriffsprotokoll angegeben werden.
Das widerspricht massiv meinem bisherigen Verständnis.
Denn bisher dachte ich, dass eine Webseite durch eine URL adressiert wird. Die URL enthält wiederum eine (Sub-)Domain, die eine Sammlung von Webseiten ist und gelegentlich als Website bezeichnet wird.
Damit widerspricht die SPEC zwar etablierten Webstandards, aber vielleicht ist das ja nicht so schlimm, wie wir seit XKCD 927 wissen:

Es werden auch Metriken definiert: als quantitative Daten, die eine Vorstufe von KPIs sein können. Dass es Key Performance Indicator nur im Singular geben sollte, habe ich neulich schon geschrieben.
Die Definitionen der SPEC und ich werden keine Freunde. Nachdem ich das emotional abhaken konnte, habe ich den Rest der Definitionen übersprungen und mir die weiteren Punkte angesehen.
Auch wenn es schwergefallen ist, denn:
- Umsatz wird als KPI-Beispiel gelistet;
- bei Traffic werden Klicks, Besucher und Sessions durcheinandergewürfelt;
- Customer sind nur Menschen, die kaufen (Publisher und Affiliates sehen das anders);
- Strukturierte Daten sind separat von Metadaten, treffen aber explizit auf die Definition von Metadaten zu;
- KI-Suchen sind nicht Teil von Suchmaschinen;
- Klicks finden nur auf Suchergebnisseiten, nicht auf Webseiten statt…
Wie findet also SEO statt?
- Geschäftsmodell verstehen,
- KPI vereinbaren,
- Messwerte vereinbaren,
- Ressourcenlage/Projektumfang definieren. Dabei ist ein Projekt wohl immer gekennzeichnet durch 5 Phasen: Status-Quo-Ermittlung, Maßnahmen-Priorisierung, zeitliche Taktung, Umsetzung, Erfolgsmessung,
- Konkurrenzanalyse (Hier werden 3 Methoden zur Definition von Konkurrenten zugelassen. Dabei wird unter anderem der nicht definierte Begriff der Domäne verwendet),
- Aufwandsermittlung. Dabei müssen Aufwände ermittelt werden. Auch für Leistungen, die vielleicht gar nicht notwendig sind. Außerdem sollen Pufferzeiten eingeplant werden und man darf von der Bezeichnung(!) der Leistungen abweichen, weil SEO ein dynamisches Feld ist
An dieser Stelle zeigt sich: Der Prozess ist zu schematisch für die Praxis.
Es wird ein starrer Prozess definiert, der für alle Projekte passen soll. Oder nur für bestimmte, aber das steht dann nicht da. Gleichzeitig werden Begriffe verwendet, die nicht in den Begriffsdefinitionen stehen (sowas macht mich wahnsinnig und jeden Standard unbrauchbar, weil er sich nicht mal an die eigenen Standards hält) und obwohl die Sprache technisch genau wirken soll, ist alles am Ende unpräzise.
Ich dachte, das Projekt sei zum Scheitern verurteilt, weil SEO individuell ist und es daher schwer ist, einen allgemeinen Prozess zu definieren. Aber das Dokument scheitert schon an der Definition der Begriffe und dem technischen Aufbau des Dokuments.
Aber für Dich beiße ich mich durch:
Wer nach der SPEC arbeitet, der:
- Muss Suchbegriffe immer der Customer Journey zuordnen – in meinen Projekten verzichte ich ja meist auf die Definition von Keywords, weil das oft den Blick viel zu sehr einengt.
- Muss für Suchbegriffe immer die Konkurrenz analysieren (inkl. Linkprofil) – ich mag es ja, wenn man auf eigene Optimierungsmöglichkeiten mehr schaut, als die ganze Zeit zu verschwenden, um die Konkurrenz zu analysieren und zu kopieren.
- Analysiert technische Hürden (Indexsteuerung, Duplicate Content, Seitenladezeit, interne Verlinkung) – abgesehen davon, dass die Probleme nicht nur technisch sein müssen, gibt es noch viel mehr Punkte, beispielsweise die HTML-Struktur.
- Analysiert die Inhalte, indem man Templates (nicht die Inhalte, die auf diesen Templates genutzt werden) für Kategorieseiten, Produktdetailseiten, Landingpages und Informationsseiten analysiert – irrelevante Seiten wie die Startseite, PDFs und vieles andere können wir also nach dieser Liste ignorieren.
- Ermittlung und Bewertung interner Verlinkung,
- Optimiert bestehende Inhalte,
- Zuweisung von Suchbegriffen,
- Entschärfung von Kannibalisierung,
- Entschärfung von inhaltlicher Dopplung
- Umsortierung der Inhalte in Templates und Folder,
Der Anordnung von Informationsteilen, Sektionen und Teilbereichen innerhalb einzelner URLs. – ich erinnere mich kurz an die Definition von URL und vermute daher, es geht hier um die Anordnung der Folder innerhalb der URL-Struktur. Steht aber so nicht hier.- Anzeige und Darstellung von Main Content, Secondary Content und Werbung,
- HTML-Gliederung und Strukturierte Daten,
- Qualität der Inhalte,
- Match mit Search Intent,
- Ermittelt fehlende, noch zu produzierende Inhalte,
- Analysiert ausgehende externe Links.
🌬️ Ich mache nochmal ne Pause mit Atemübungen 🌬️
Es folgen noch Hinweise, wie miteinander zu kommunizieren ist.
Aber weiter komme ich auch wirklich nicht strukturiert. Hier meine größten Lowlights:
- Es wird Crawling beschrieben, ohne JavaScript und Rendering zu erwähnen.
- Es gibt keine Definition, wer an der Seite rumfummelt. SEO oder Auftraggeber. Das ist an sich okay. Aber wenn in den Raum gestellt wird, dass der SEO an der Seite rumfummelt, dann können Backups keine optionale Zusatzleistung sein (ist am Anfang als Beispiel genannt).
- Offpage bekommt mehr Raum als die Erstellung von Inhalten. Gleichzeitig wird auf die Überwachung der Links mittels „Analyse externer Verweise“ aus einem vorigen Abschnitt verwiesen. Externe Verweise sind aber in der Definition ausgehende Links einer Seite. Nicht Backlinks. Die beschriebenen Leistungen passen nicht mit den Definitionen zusammen.
- Und ganz wichtig ist das umfangreiche Erstellen von schriftlichen Reports, damit man viel Zeit mit Auswertung und wenig mit Verbessern verbringt (das steht da so nicht. Das ist meine polemische Ergänzung)
Ich hatte gedacht, dass ich schlimme inhaltliche Kritik an der SPEC haben würde:
- Weil SEO so individuell ist, dass es kaum möglich ist, allgemeingültige Standards zu definieren,
- Weil ein größerer Teil der Ersteller naturgemäß mit einer sehr operativen Kleinprojekte-Brille auf den Standard schauen wird. Aber gerade die kleinsten Unternehmen kaum Ressourcen haben, um sich mit dem Standard zu beschäftigen,
- Weil ich befürchtet habe, dass es schlimmes Linkbuilding wird.
Aber es ist ganz anders gekommen:
- Linkbuilding ist zwar ein großer Abschnitt, aber es wird organisches Linkbuilding statt Kauf betont,
- Ich kann mich mit den Inhalten gar nicht wirklich auseinandersetzen, weil die Formalia nicht passen. Die Begriffe werden teilweise falsch definiert. Dann im Standard anders verwendet, als sie eingangs definiert worden sind,
- Das Dokument ist eine merklich kollaborative Arbeit. Schreibstil und Aufbau sind teilweise komplett unterschiedlich. Teilweise wird der Sinn der Maßnahmen erklärt, teilweise nur die Maßnahme erwähnt.
Ich hätte erwartet, dass die DIN sich darum kümmert und solche Dinge glattbügelt. Schließlich zahlen die mitschreibenden Unternehmen ja eine Eintrittsgebühr.
Was ist, wie ich es erwartet hätte, ist der verengte Blick auf SEO. Manche Dinge werden zur Pflicht erklärt, aber andere Themen komplett ausgeklammert. Und allein schon durch das Wachstum von Gemini, AI Overviews, AI Mode und ChatGPT ist die SPEC schon jetzt völlig veraltet.
Irritierend finde ich auch:
- Die SPEC definiert nicht, für wen sie geschrieben ist – Beratung, Ausführung oder Audit. Sie definiert die Zusammenarbeit zwischen Agentur und Unternehmen. Auf der Website wird angekündigt, dass sie auch für Inhouse gelten können soll. Aber die Punkte von der Website finde ich kaum im PDF wieder. Ohne eindeutigen Adressaten kann es kein Qualitätsstandard sein.
- Die SPEC vermischt Arbeitsprozess (wie man SEO macht) mit Leistungsbeschreibung (was getan wird) und Qualitätskriterien (wann es gut ist). Der Text will gleichzeitig Anleitung, Angebotsvorlage und Prüfkatalog sein und wird keinem Anspruch gerecht.
- Es wird zwar angeregt, KPIs zu definieren, aber um die Operationalisierung von Qualität in der Suchmaschinenoptimierung hat man sich gedrückt. Es gibt keine Prüfmethoden, keine Kriterien, keine Auditmechanismen. Und das, obwohl im Titel Qualitätssicherung steht. Dafür fehlt viel.
- Es wird darauf verzichtet, auf andere Standards zu verweisen. Weder Webstandards wie RFCs werden genutzt (dann wären einem vielleicht auch einige Widersprüche aufgefallen), noch auf die WCAG-Richtlinien zur Barrierefreiheit oder die Webmaster Guidelines von Bing und Google verwiesen. Es muss ja nicht gleich die ISO 9001 (Qualitätsmanagement) sein. Aber ich hätte mir eine Integration in die bestehende Standardlandschaft gewünscht.
- Die SPEC ist meinungsgetrieben, nicht evidenzbasiert. Es gibt nicht nur keine Verweise auf Standards, sondern auch keinerlei Quellenbelege für Behauptungen. So ist sie keine Norm, sondern ein Positionspapier.
- Die SPEC ignoriert ethische Mindeststandards, obwohl SEO längst datengetrieben und KI-gestützt ist. Datenschutzerwägungen (Tracking), Transparenzanforderungen gegenüber dem Kunden, Umgang mit KI-generierten Inhalten, Umgang mit unseriösen SEO-Praktiken. All das habe ich nicht gesehen.
- Die SPEC verfehlt den Sprachstandard einer Norm. Sie liest sich wie ein Whitepaper, nicht wie ein technisches Regelwerk. Von RFCs ist man eine klare Unterscheidung von „kann“, „sollte“ und „muss“ gewohnt. Hier wird vieles austauschbar und unscharf verwendet.
- Die Rollenverteilung und Verantwortlichkeiten bleiben meistens sehr diffus: Ohne klare Rollen und Verantwortlichkeiten ist aber jede Prozessbeschreibung wertlos.
- In der SPEC steht nicht, wie sie fortgeschrieben oder überprüft werden soll. Ein Revisionsmechanismus fehlt. Damit ist unklar, wie der Standard auf technische Entwicklungen reagieren soll.
- Die SPEC beansprucht (implizit) branchenweiten Konsens und dafür repräsentativ zu sein. Zumindest im Subtext:
„Diese DIN SPEC wurde im Konsens von Experten aus Unternehmen, Agenturen und Institutionen der SEO-Branche erarbeitet.“ & Mit der DIN SPEC 33461 liegt erstmals ein einheitlicher Standard für die Qualitätssicherung in der SEO vor. – dieser Standard ist aber mitnichten repräsentativ. Meiner (aus der sehr weiten Entfernung getroffenen) Einschätzung nach noch nicht mal für alle Unternehmen, die an der Gestaltung mitgewirkt haben.
Laut DIN-Regelwerk sind SPECs keine Normen, sondern Schnellverfahren ohne öffentliche Einspruchsphase. Umso irritierender ist der Anspruch, hier einen „einheitlichen Standard“ zu formulieren.
Schade um die Zeit und Energie, die da rein geflossen ist.
Aber vielleicht hilft die SPEC immerhin, zu zeigen, wie schwierig Standardisierung im SEO wirklich ist.
|
|
| Hey ChatGPT, wie sollte OpenAI ChatGPT monetarisieren? |
Mein Kollege Florian Hannemann hatte vor rund einem Jahr bereits über die Wirtschaftlichkeitsprobleme bei OpenAI berichtet. Eigentlich wollte ich hier die Antwort von ChatGPT präsentieren; die war mir dann doch etwas zu ausufernd. Daher bin ich umgestiegen auf die aus meiner Sicht spitzer formulierte Frage: Kann ChatGPT ohne anzeigenbasierte Einnahmen überhaupt profitabel sein? Hier wurde ich von ChatGPT-5 ebenfalls hinsichtlich einer kurzen Antwort enttäuscht; das hätte ich allerdings im Prompt auch formulieren können. Daher die aus meiner Sicht salienten Punkte:
“Die kurze Antwort ist: Ja, aber nur unter bestimmten Bedingungen. [...] Ohne massive Kostensenkung ist der Break-even nicht erreichbar. [...] ChatGPT kann profitabel werden – auch ohne Werbung –, wenn es gelingt, Kosten zu senken und B2B-/Abo-Einnahmen stark auszubauen.”
Angenommen wird vom eigenen Bot ein Verlust von rund 2 Milliarden $ jährlich. Davon ausgehend kommen wir auf eine Halbierung der Kosten oder eine Verdopplung des Umsatzes pro Nutzer, damit man ohne anzeigenbasierte Werbung einen Break-Even erreicht. Ob das realistisch ist, steht in den Sternen. Möglicherweise hat deswegen OpenAI CEO Sam Altman die Stimmung bezüglich staatlicher Unterstützung getestet.
In einem weiteren Interview letzte Woche beantwortete er Fragen zur möglichen Monetarisierung von ChatGPT. Besonders interessant ist dabei folgender Austausch zwischen Altman und dem Interviewer Tyler Cowen.
Altman: “Again, there’s a kind of ad that I think would be really bad, like the one we talked about. There are kinds of ads that I think would be very good or pretty good to do. I expect it’s something we’ll try at some point. I do not think it is our biggest revenue opportunity.”
Cowen: “What will the ad look like on the page?”
Altman: “I have no idea. You asked like a question about productivity earlier. I’m really good about not doing the things I don’t want to do.”
Die “schlechten” Ads, die von Altman benannt werden, sind solche, wie sie von Google genutzt werden. Er beklagt dabei, dass bezahlt werden kann, um ein schlechteres Ergebnis vor ein besseres zu setzen. Außerdem führt er an, dass die Ads von schlechten Suchergebnissen abhängen.
All diese Argumente sprechen laut Altman dagegen, solche Anzeigen zuzulassen. Wie mein Kollege Philipp bereits schrieb, befindet er sich aber schon seit Längerem auf einer Sliding Scale, was die Ads betrifft. Zur Frage, wie man Umsätze generieren möchte, hat er diesmal den Ball sehr flach gehalten.
“There is a question of, should, many people have asked, should OpenAI do ChatGPT at all? Why don’t you just go build AGI? Why don’t you go discover a cure for every disease, nuclear fusion, cheap rockets, the whole thing, and just license that technology? And it is not an unfair question because I believe that is the stuff that we will do that will be most important and make the most money eventually”
In Zukunft verdient OpenAI also einfach an Lizenzen und Patenten für Kernfusion, günstige Raketen und die Heilung jeder Krankheit. Was sonst? Zumindest sagt Sam Altman, dass er glaubt, diese Dinge werden am wichtigsten sein und irgendwann am meisten Geld einbringen.
Da liegt vermutlich die Crux der gesamten Sache. Abgesehen von der Frage, ob ChatGPT diese Dinge wirklich irgendwann können wird, muss man schauen, ob die Investorenkohle nicht vorher schon komplett abgefackelt wird, wonach es derzeit für mich aussieht. Gerade erst berichtete Edward Zitron, dass OpenAI noch mehr Geld verbrannt hat, als bisher bekannt war.
Stand jetzt sieht es für mich zusammengefasst so aus:
- Es ist immer noch umstritten, wie stark die Reasoning-Fähigkeiten der Modelle sind.
- Langsam gehen uns die Trainingsdaten aus.
- Es verdient noch keiner wirklich Geld mit seinen Tools und
- man ist auch noch sehr weit weg davon, das zu tun.
Wenn ich kurz davor wäre, AGI zu erfinden, müsste ich auch keine KI-Sexchatbots ins Rennen schicken. Nun möchte ich niemandem unterstellen, in einem öffentlichen Auftritt nicht die ganze Wahrheit zu sagen. Aber in dieser Lage würde ich mich zumindest dazu hinreißen lassen, Werbung in ChatGPT als ganz attraktiv zu bezeichnen. Andere haben hier weniger Befindlichkeiten als ich, denn der OpenAI-Mitgründer Ilya Sutskever sagte über ihn, Altman “exhibits a consistent pattern of lying, undermining his execs, and pitting his execs against one another.”
Insofern ist zumindest Vorsicht geboten, wenn es um seine Aussagen geht. Daher würde ich auch weiterhin nicht ausschließen, dass Ads in ChatGPT auftauchen könnten. Google wollte auch nie böse sein. Am Ende will aber jeder Geld verdienen. Die Frage ist, ob OpenAI es sich noch lange leisten kann, auf Anzeigen zu verzichten. Ich würde nicht davon ausgehen.
|
|
| 5 Dinge, die Du über AI Readiness wissen musst |
Anstatt in der nicht enden wollenden Diskussion, ob die Optimierung für AI Visibility einen eigenen Namen braucht, zu ersticken, prüfe ich für meine Kund*innen lieber die AI Readiness und Visibility ihrer Domains und passe mich bei der Namensgebung an.
Und weil AI gerade überall ist und alle Nähte sprengt, teile ich 5 Insights aus meiner letzten AI Readiness Analyse mit Dir.
1. Wenig Zitierungen != wenig sichtbar
Vermutlich ist es eine Krankheit der SEO: Wenn ich nicht “ranke”, bin ich unsichtbar. Das stimmt in Zusammenhang mit AI Chatbots aber aus unterschiedlichen Gründen nicht.
- AI Chatbots erwähnen (D)eine Marke, wenn sie andere Domains und nicht Deine Domain zitieren
- AI Chatbots erwähnen (D)eine Marke, auch wenn sie gar keine Quellen im Grounding suchen
Zitierungen < Erwähnungen, wenn ich Hersteller bzw. die Marke bin. AI Chatbots sind nicht dazu gebaut, Traffic zu senden. Das ist ein Nebenprodukt, und die CTR ist gering (laut Tollbit in Q2 2025 weiterhin unter 1% – kommt aber natürlich auf den Prompt an).
Eine Zitierung ist eine Fußnote, fast unsichtbar. Eine Erwähnung ist eine prominente Hervorhebung, hoch sichtbar:

Matt hat über eine AirOps-Studie berichtet, laut der 85% aller Brand Mentions von Third-Party-Domains kommen. Also viel Beeinflussung von “außerhalb”.
In meiner Analyse habe ich festgestellt, dass die untersuchte Domain in “nur” 5% (!) der Antworten zitiert wird, die Marke war aber in 28-57% (je nach Thema) der Prompts sichtbar.
Gleichzeitig war die Domain unter dem Wettbewerb die am häufigsten zitierte Quelle und auf Platz 3 aller Domains (davor nur eine große Vergleichsplattform und ein bekannter Affiliate).
Ist also gar nicht so schlimm, dass es “weniger” Zitierungen gab, weil die Beeinflussung in der Antwort durch die Markennennung stattfindet.
Das Ergebnis: Menschen geben die Marke bei Google ein und das Brand-Suchvolumen steigt (vermutlich). Am wichtigsten wären mir daher Erwähnungen und nicht zitierte URLs.
2. Durchschnitte sind wie immer gefährlich
Die Werte von 28-57% ergeben sich aus unterschiedlichen Themen und Chatbots, die wir analysiert haben. Im Durchschnitt waren es leicht unter 50%. CoPilot hat z. B. weniger Marken pro Antwort erwähnt, weniger Domains zitiert und auch der Wettbewerb hatte deutlich geringere Sichtbarkeitswerte.
Im Durchschnitt würde ich das nicht erkennen.
Was man außerdem häufig beobachten kann: AI Chatbots zitieren zum Prompt passende Inhalte. Wenn jemand nach dem besten” oder etwas “günstigem” sucht, macht es Sinn, dass häufig Vergleiche vorkommen. Teilweise ist das dem Ranking der organischen Suche geschuldet.
In dem gewählten Promptset waren z. B. mehr als ⅓ der Zitierungen Vergleichsinhalte.
Klingt viel, ist es auch. Ich habe tiefer gegraben und mir fiel auf, wie stark sich das pro AI Chatbot unterscheidet:
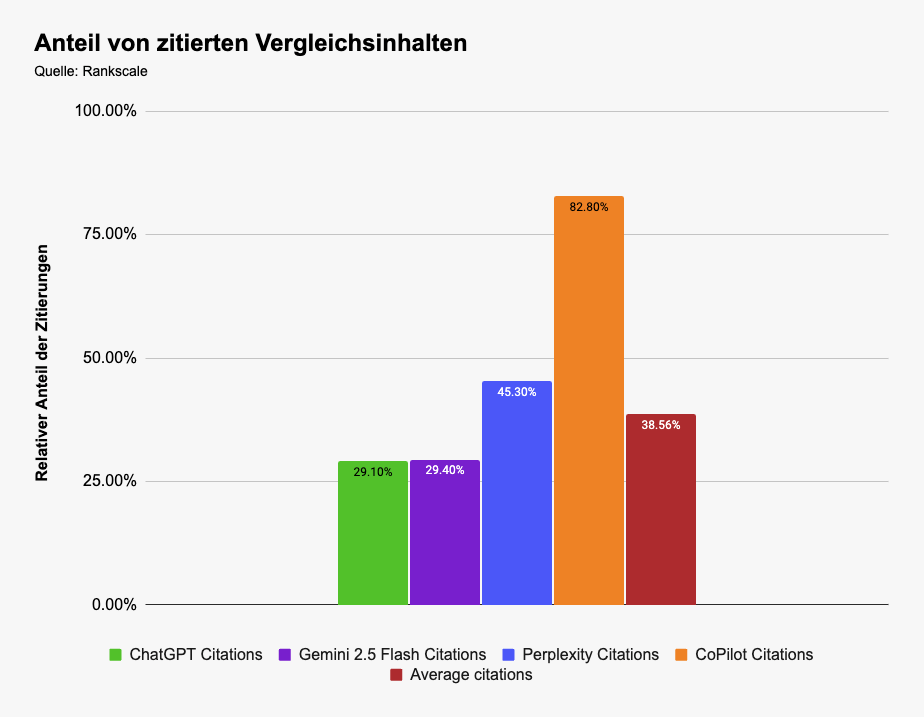
CoPilot zeigte ein deutliches Übergewicht dieser Inhalte. Wäre dieser AI Chatbot für mich wichtig, gäbe es mehr Druck, Teil dieser Inhalte zu sein, als bei den anderen Plattformen.
Wie sichtbar ich bin oder wie häufig ich zitiert werde, hängt oft mit der Funnel-Stufe zusammen, wie XFunnel bereits im Februar 2025 analysiert hat (die Studie flog deutlich unter dem Radar, finde ich):

Je näher jemand an der Conversion ist, desto größer wird der eigene Domain-Anteil in den Zitierungen.
3. Keine große Spur von Reddit
Reddit ist überall, so sagt man immer. Es stimmt, dass Reddit in den SERPs (auch durch automatische Übersetzungen) viel Platz einnimmt. In diesem Projekt hat es Reddit aber nicht einmal unter die Top-200 der am meisten zitierten Domains geschafft.
In anderen Projekten fiel mir auf, dass ChatGPT z. B. Reddit auch bei deutschsprachigen Prompts zitiert, weil es einen englischen Query fan-out gab.
Hier gilt wieder: Nur weil es im Durchschnitt so ist (und dann wieder nicht), dass Reddit (k)eine große Rolle spielt, muss das nicht für Deine Branche, Deine Domain und Deine Prompts gelten. Ich würde mir trotzdem anschauen, wie andere über mich und meine Marke auf Reddit sprechen (siehe Punkt 5).
Wenn Dich das bei Deiner Marke interessiert, probiere den F5Bot aus. Ich würde es mit Google Alerts für Reddit (und andere Foren) vergleichen. Für einen kostenfreien ersten Blick reicht das auf jeden Fall.
4. AI Chatbots sind nicht alles
Was ich nicht mehr hören kann “darüber kommt so wenig Traffic”. Über die Socials kommt auch wenig und gleichzeitig sind wir bemüht, dort präsent und sichtbar zu sein. Es geht um Beeinflussung. Daher erzähle ich Dir jetzt nicht, wie viel mehr Traffic über Google & Co. kommt.
Der Vergleich ist Äpfel mit Birnen und verfehlt das Ziel (was nicht heißen soll, dass es egal ist, wie viel Traffic über AI Chatbots kommt).
Es gibt immer mehr agentische Browser. Unter anderem:
- ChatGPT Atlas
- Perplexity Comet
- Edge
- Dia
- Chrome (Google testet bereits seit langer Zeit)
Atlas und Comet verwenden ARIA, um die Seite zu nutzen. Dass Barrierefreiheit für Menschen mit Einschränkungen wichtig (+ für alle hilfreich) und (inzwischen) gesetzlich vorgeschrieben ist, scheint nicht zu reichen. Spätestens jetzt gibt es aber ein weiteres Argument, sich mit dem Thema zu befassen.
“Ist meine Website für agentische Nutzung tauglich?” Das ist die goldene Frage. Was uns immer wieder auffällt: Probleme gibt es häufig bei Formularfeldern, weil diese stiefmütterlich umgesetzt sind. Wäre doof, wenn sich AI-Agenten daran aufhängen und die Conversion verhindert wird.
P.S. Sandra gibt auf der SMX dazu einen Workshop, in dem sie Dir alles Wichtige erzählt, um Deine Barrierefreiheitsprobleme in den Griff zu kriegen.
P.P.S. Agentische Browser bergen viele Sicherheitsrisiken und Kinderkrankheiten, egal ob Sam Altman und die anderen AI Bros etwas anderes behaupten. Lieber vorsichtig bei der Nutzung sein.
5. Vertrauen und Reputation entscheiden über Empfehlungen und Entscheidungen
Google hebt in EEAT das T für Trust in der grafischen Darstellung der Search Quality Rater Guidelines hervor und betont, wie wichtig Vertrauen ist:

Vertrauen ist die Basis von Beziehungen – unter Menschen und mit Marken.
Was AI Chatbots über Dich sagen, hängt nicht nur davon ab, wie Du über Dich sprichst. Es zählt vor allem, wie andere über Dich sprechen. Vertrauen entsteht unter anderem, wenn das kommunizierte Selbst- und Fremdbild übereinstimmen.
Da sich AI Chatbots auf Suchergebnisse verlassen, kommen hier Quellen wie TrustPilot, TrustedShops und im Shopping-Kontext auch Idealo und Geizhals zum Tragen, wo Bewertungen zu finden sind.
Ob man Dir vertraut und in Deinem Shop kauft, hängt also von Deiner Reputation ab. Robert Greene hat es in 48 Laws of Power schön formuliert:
“Do not leave your reputation to chance or gossip; it is your life's artwork, and you must craft it, hone it, and display it with the care of an artist.”
Reputation Management ist oft eine eigene Disziplin im Unternehmen, genau wie Brand Management.
Wenn es bei Dir ein Reputationsproblem gibt, wäre es jetzt 5 vor 12, mit allen an einem Tisch zu sitzen und zu überlegen, wie Ihr dieses Feuer löschen könnt.
Turbozusammenfassung und abschließende Gedanken
- Erwähnungen > Zitierungen
- Gucke niemals nur auf Durchschnitte
- Reddit ist nicht immer überall
- AI Agents und Browser nicht vergessen
- Vertrauen und Reputation > alles andere
Was AI Readiness konkret bedeutet, hat keine einheitliche Definition. Wir schauen uns gerne möglichst viel an, z. B.
- die technische Grundlage, um potenzielle Sichtbarkeitsblocker zu identifizieren,
- die Aufbereitung der Inhalte, um Inhalte zu liefern, die Menschen und Maschinen lieben,
- die (in)direkte Wettbewerbssituation, um zu wissen, wo wir im Vergleich stehen und
- diskutieren Implikationen für das Geschäftsmodell, denn es geht bei AI nicht nur um das Hier und Jetzt.
Wenn Dich auch interessiert, wie gut Du für AI aufgestellt bist, melde Dich gerne bei uns oder direkt bei mir. Ich schaue mir gerne Deine Domain an!
Wenn Du mehr zu AI von mir lesen magst, findest Du hier weiteren Lesestoff:
- Warum ich weiterhin Content erstellen würde, auch wenn KI ihn auffrisst
- Auf dem Grabstein vom Traffic steht: "Es ging nie um mich"
- 11 Dinge, die Du über AI Overviews und den AI Mode noch nicht wusstest
|
|
| Adam Gent erklärt, “Wie Googles Such-Index funktioniert” |
Auf der Brighton SEO im Oktober hielt Adam Gent einen Vortrag zum Thema “How Google’s Search Index Works”. Den habe ich nur ungern verpasst. Aber zum Glück profitieren wir alle von den veröffentlichten Slides.
Mit seinem Projekt Indexing Insight nimmt Adam den Indexing-Report der Search Console und die URL Inspection API von Google genau in den Blick. Wie Johan hier und Adam dort beschreibt, kommt er zu ganz ähnlichen Erkenntnissen wie wir bei Wingmen:

Einige der für uns spannendsten Erkenntnisse der letzten Jahre:
- Der Google Index ist nicht unendlich groß. Das Limit von 400 Milliarden Dokumenten ist in Relation zum “gesamten Internet” sogar recht überschaubar. Das macht Indexierung zum Nullsummenspiel.
- Indexierte Dokumente können, unabhängig von Sanktionen (Penalties/Manual Actions), die Google für den Verstöße gegen seine Richtlinien verhängt, wieder aus dem Index fliegen.
- Entscheidender Faktor dabei ist die Qualität. Wenn ein besseres Dokument zum Bestand dazukommt, muss ein schlechteres gehen. Wie gesagt: Nullsummenspiel…
Die zentralen Botschaften von Adam in Kürze
Slide 79 übersetzt:
- Der Seiten-Indexierungsbericht zeigt alle verarbeiteten Inhalte an
- „Indexiert“ bedeutet, dass die URL in der Suche erscheinen kann
- Seitenqualität ist ein Hauptgrund dafür, dass Seiten entfernt werden
- Google verwendet die Seitenqualität, um seinen Index zu verwalten
- Qualität wird für die Crawling-Priorisierung von Seiten verwendet
Googles Indexing-Datenbanken umfassen mehr als der öffentliche Google Index
Denn Google speichert auch Informationen zu Dokumenten weg, die es mal verarbeitet, sich aber gegen eine Indexierung entschieden hat (Slide 11). Das ist das, was unsere Neologismus-Freunde drüben bei Jaeckert O’Daniel den “Grauen Index” getauft haben (Slide 13).
Nicht ohne Grund gibt der Screaming Frog in der Spalte “Indexability” an, ob eine URL indexierbar ist oder nicht. Wir erfahren aber – ohne Anschluss an die Indexing API – nichts darüber, ob die URL tatsächlich indexiert und in der Google-Suche auffindbar ist. “Eligible” vs. Not-eligible to be served on Google” ist hier die Frage.
Qualität (vs. Spam) ist der entscheidende Faktor für
- die Aufnahme in den oder den Ausschluss aus dem öffentlichen Google Index
- die Crawl-Rate, in der Googlebot ein Dokument besucht
Wie misst Google gute Qualität? (Slide 54)
- Anhand des Inhalts selbst (Vector Embeddings)
- Links
- User Signals wie Clicks
Zu wissen, welche URLs Spam sind und wie man Spam erkennt, ist ein riesiger Vorteil, den sich Google über die Jahrzehnte aufgebaut hat. LLM-Chatbots stehen im Vergleich dazu oft noch mit runtergelassenen Hosen da, wenn sie Bestenlisten blauäugig wiedergeben, bei denen sich irgendjemand praktischerweise selbst auf Platz 1 gesetzt hat.
Im Antitrust-Trial des DoJ entschied Richter Amit Mehta daher als eine Abhilfe zur missbrauchten Monopolstellung Googles, dass der Suchgigant einmalig Spam-Scores mit Wettbewerbern teilen muss, damit diese eine Chance haben, mit Google zu konkurrieren. Denn so können sie das Netz effizienter crawlen und sich selbst einen hochwertigen Index aufbauen:
Unschärfen im Indexing Report der Search Console
Slide 26:

Im Indexing Report bekommen wir zwei Gründe, die auf schlechte Qualität hinweisen:
- Crawled – currently not indexed
- Discovered – currently not indexed
Das Inspection Tool bzw. die Inspection API gibt uns aber noch einen dritten:
Früher™ sind wir davon ausgegangen, dass solche URLs noch nicht indexiert sind, also von Google noch nicht entsprechend verarbeitet wurden. Heute wissen wir:
- Google kann in der Vergangenheit über URLs gestolpert sein, sie aber für irrelevant halten und wieder “vergessen” – sie also nicht in den Indexing-Datenbanken abspeichern
- URLs können in der Vergangenheit sogar indexiert gewesen und später im dynamischen Wettbewerb wieder aus dem auffindbaren Index aussortiert worden sein
Etwa bei 130 und 190 Tagen (lasst uns nicht zu genau sein) ändert Google den Status im Indexing Report:

"If a page is not crawled in 130 days, it gets actively removed. If a page is not crawled in 190 days, it gets actively forgotten." Adam Gent, Slide 77
Die Größe des Google Index ist ein atmendes System
Vor der Indexierung kommt das Crawling. Google hat eine relativ fixe Zahl an URLs, die es crawlt. Im Patent US7509315B1 beschreibt Google die soften und harten “Importance Thresholds” – also Schwellwerte eines Relevanz-Scorings, die eine URL überschreiten muss, um in den Pool der zu crawlenden Seiten aufgenommen zu werden. Temporär können dann auch zusätzliche Dokumente in den Index wandern.
Übrigens: Bei Themenrelevanz (Topicality) spielt einerseits Information Gain eine Rolle: Kann ich dem Internet neue Erkenntnisse oder eine neue Perspektive liefern, statt nur zu wiederholen, was bereits im Index ist. Andererseits ist inhaltliche Nähe wichtig. Ich darf nicht zu weit vom Kernthema entfernt sein. Sonst sind die Vector Embeddings meiner Inhalte im mathematischen Raum (Topical Map) zu weit entfernt, als dass ich den Wettbewerb aufmischen könnte.
Neben der Qualität und der Anzahl spielt auch eine Rolle, wie groß die Dokumente sind. Denn auch der Speicherplatz bei Google bestimmt, wie viele Dokumente in den Index wandern:
"If we have tons of free space available, we're more likely to index crappier content. If we don't, we might deindex stuff to make space for higher quality docs." Google-Advokat Gary Illyes
Potenzielle Missverständnisse
- Ich hab bei Adam nochmal nachgefragt: Indexing Insight inspiziert 500k (fünfhunderttausend) Seiten täglich, nicht 500,00 (Folie 4).
Adam spricht von “technical errors”, also technischen Fehlern, warum URLs nicht indexiert sind. Das finde ich unglücklich. Google nennt das nicht “Fehler”, sondern “Gründe” – aus Gründen:
Wenn ich URLs weiterleite, ist der Status Code 301 korrekt. Wenn ich Seiten auf noindex setze, ist der Grund für die Nichtindexierung “noindex” korrekt. Wenn ich eine URL kanonisiere und Google das Canonical akzeptiert, ist das korrekt. Das als “Fehler” zu bezeichnen, sabotiert uns auch in der Kommunikation mit unseren Kunden. Ziel ist es hier nicht, das zu reparieren und “alles auf grün” zu stellen. Ganz häufig ist hier alles OK. Ich darf nicht immer davon ausgehen, dass es sich im Indexing Report um das identische URL-Set handelt und sich nur der Indexierungsstatus oder die Gründe für die Nicht-Indexierung ändern. Aber wenn ich meine Sitemaps sinnvoll schneide und in der Search Console eintrage, kann ich mir tatsächlich die Entwicklung und Fluktuationen für ein konstantes URL-Set anschauen – also unbedingt machen!
Ein toller Beitrag für die SEO-Branche
In der Mischung, wie Adam offizielle Quellen mit eigener Forschung zu Erkenntnissen verdichtet, ist wirklich herausragend gut. So stell ich mir den Diskurs in der SEO-Gemeinschaft idealerweise vor. Mehr davon!
|
|
| Die Macht der Metaphern |
Ich geb’s zu: Ich hab eine kleine Schwäche.
Keine für Schokolade (naja… vielleicht auch), sondern für Metaphern.
Schon früher war das so. Zuletzt beim Offsite hab ich den bildlichen Vergleich zwischen guter SEO-Beratung und gutem Essen sehr gefeiert. Auch dass unser Teamevent dann noch ein Kochevent war und wir „SEO-Rezepte“ geschrieben haben – das war eine runde Sache.
Ich mag diese Bilder im Kopf. Vor zwei Jahren habe ich sogar mal eine kleine LinkedIn-Serie gestartet, in der ich SEO mit meinen Hobbys Angeln und Fußball verglichen hab. Das war absolut meins.
Nenn’s ruhig eine Macke.
Ich nenn’s lieber: ein Werkzeug.
Warum Metaphern funktionieren
Ich erinnere mich noch gut an einen Vortrag von Sebastian Adler (Grüße gehen raus!) von vor einigen Jahren. Er hat die Metapher eines Campingplatzes genutzt, um SEO-Prinzipien zu erklären. Es war grandios! Ich weiß ehrlich gesagt nicht mehr, was genau er gesagt hat, aber ich seh den Campingplatz bis heute vor mir.
Und genau das ist der Punkt: Fakten verblassen. Bilder bleiben.
Wolfgang Jung (Grüße Nummer zwei!) sagt ja auch immer: Emotionen schlagen Fakten.
Und Recht hat er damit. Marketing soll Geschichten erzählen.
Johan hat’s bei der letzten SEOkomm ebenfalls wunderbar vorgemacht: Sein Vortrag über Suchmaschinen im weihnachtlichen Storytelling-Gewand hatte Charme. Bleibt in Erinnerung.
Und Julia Weißbach (damit sind wir bei Gruß Nummer drei!) greift in ihren Vorträgen auch gern tief in die Bild- und Giphy-Trickkiste, um die Zuschauer in den Bann zu ziehen.
Und ich frag mich:
Sollten wir das nicht auch in unserer SEO-Kommunikation viel öfter tun?
Ob Du Inhouse arbeitest und Dein Chef oder Deine Chefin endlich verstehen soll, dass SEO kein Plug-in ist, oder Du als Berater:in einem Kunden erklären musst, warum „mehr Blogartikel“ nicht automatisch „mehr Umsatz“ heißt – Metaphern helfen, Brücken zu bauen.
Sie holen Dein Gegenüber dort ab, wo es steht, und machen komplexe Themen leichter verdaulich.
Ein Beispiel aus der Praxis
Ich erinnere mich an einen Vor-Ort-Termin aus meiner Consulting-Praxis, bei dem ich genau das versucht habe.
Der Kunde verstand SEO damals als Add-on. So ein bisschen „machen wir halt mit“.
Wir hatten auditiert, beraten, validiert – alles da. Nur: umgesetzt wurde kaum etwas. Und wenn, dann ohne unsere Einbindung. Leider mit Folgen. Ganz nach dem Motto: „Gut hören kann ich schlecht, aber schlecht sehen kann ich gut.“
Die Consultants unter den Leser:innen denken jetzt sicher: Den Kunden kenn ich auch. 😄
Nach einiger Zeit hatte ich die Möglichkeit, diesen Kunden vor Ort zu besuchen. Es gab Meetings mit der IT, mit dem Produktmanagement und mit dem Marketing-Verantwortlichen.
Und beim letzten Termin hab ich mich gefragt:
Wie schaffe ich es, diesen freundlich an den Karren zu fahren und gleichzeitig zu gewinnen, dass wir endlich die Rahmenbedingungen bekommen, um im SEO Fahrt aufzunehmen?
Meine Idee: Anstatt trocken den Maßnahmenplan runterzubeten, wollte ich ihn über einen metaphorischen Vergleich abholen. Ihn auf eine kleine Reise mitnehmen. Eine Geschichte erzählen.
Mein Bild: Deine Website ist ein Schiff.
Und ohne, dass ich Dir jetzt Details über die Website verrate, wirst Du über die folgende Storyline, denke ich, verstehen, wie der Status quo des Kunden war und wo ich mit ihm strategisch hinwollte.
Das also waren die Überschriften meines Slidedecks:
- Ihr seid ein mittelgroßes Segelschiff.
- Doch Ihr wart in der Vergangenheit schon mal ein größeres Segelschiff. Beim Relaunch habt Ihr Euch entschieden, auf weniger Kajüten zu setzen.
- Beim Umbau des Segelschiffs hat nicht alles funktioniert. Ohne gespannte Segel konnte man nicht genug Fahrt aufnehmen.
- Die Segel sind nun wieder gespannt. Aber eigentlich kommt man mit anderen Schiffstypen viel besser ans Ziel.
- Denn: Der nächste Sturm kommt bestimmt bzw. genau genommen kam er letzte Woche.
- Ihr wollt Euch vom Wind des Google-Algorithmus nicht abhängig machen? Dann ist ein Dampfschiff vielleicht effektiver.
- Doch auch hier gilt: Nur wer viele Kajüten hat, kann viele Insassen beglücken. Skalierung ist der Weg zum Erfolg.
- Und nichts geht ohne einen ordentlichen Schiffsplan und die Beschriftung der Schiffsbereiche. Sonst landen die Passagiere zum Schlafen in der Schiffsküche.
- Aber Eure Zielgruppe überzeugt man heute nicht mehr mit einem Dampfschiff. Einen Motor mit Speed braucht es. Und gut eingerichtet muss es sein.
- Die Frage ist daher: Welches Schiff wollt Ihr sein?
Ich weiß noch, dass dieser Vergleich damals im Meeting eine wunderbare Brücke geschlagen hat, um dann inhaltlich über die konkreten nächsten Schritte für das Folgejahr zu sprechen.
Ob dem Entscheider die Metapher gefallen hat? Keine Ahnung.
Aber ich glaube, sie ist im Gedächtnis geblieben.
Hinkt die Metapher, wenn man es ganz genau nimmt? Ehrlicherweise ja.
Aber das ist bei bildlichen Vergleichen oft so. Interessant ist eher die übergreifende Aussage. Nicht, dass jedes Detail übertragbar ist.
Ob’s auch ohne Metapher geklappt hätte? Sicher.
Aber ich wette, sie hat geholfen, dass der Kunde SEO nicht mehr nur als „Add-on“ gesehen hat.
Natürlich braucht’s Feingefühl
Klar, nicht jede Metapher passt zu jedem Menschen. Wenn Dein Gegenüber gerade erst von einer üblen Bootstour zurückkam, ist das mit dem „Segelschiff“ vielleicht nicht die beste Idee. 😅
Darum: Kenne Dein Publikum.
Und dann trau Dich, bildlich zu werden.
Das geht übrigens auch wunderbar nebenbei im Alltag.
Kleine bildhafte Erklärungen bleiben oft besser hängen als 20 Minuten Tech-Talk.
Zum Beispiel:
Wenn Du jemanden davon überzeugen willst, endlich die SEO-Hygienefaktoren umzusetzen, also das, was einfach sein muss, bevor’s schön wird, dann kam mir auch schon mal folgende ketzerische Frage in den Sinn:
„Sag mal, würdest Du vor einem Date ungeduscht erscheinen?“
Genau. 😄
Solche Mini-Metaphern machen selbst trockene Themen greifbar und sorgen ganz nebenbei dafür, dass Dein Gegenüber sich an Dich erinnert.
Und genau da liegt die wahre Macht der Metaphern. Wenn’s passt.
|
|
|
|
|
Fragen? Immer gerne fragen!
|
Wir sind für Dich da.
Schreib uns gern jederzeit
eine E-Mail an [email protected] oder
ruf uns einfach kurz an: +49 40 22868040
Bis bald,
Deine Wingmenschen
|
|
|
Anckelmannsplatz 1, 20537 Hamburg, Germany
|
|





